
基于文本挖掘的社交網絡用戶精神疾病篩查
2023-09-18 21:42:26張鑫衍
現代信息科技 2023年15期
關鍵詞:文本挖掘
張鑫衍


摘? 要:隨著移動互聯網的普及,公眾更加頻繁地使用社交網絡分享生活并表達思想和感情。推特作為擁有全球最大用戶基數的社交平臺,沉淀了非常豐富的用戶和文本信息。文章使用Sentiment140數據集對推特文本信息進行分析,從不同角度對數據集進行探索性數據分析,并通過F1值評估對比不同的特征提取方法和分類算法,最終確定了最佳的特征提取和分類參數。文章使用的分析流程和分析結果可作為文本情感挖掘的參考,為基于文本信息的情感分類任務以及精神疾病如抑郁癥等的診斷提供助力。
關鍵詞:社交網絡;文本挖掘;自然語言處理;數字療法;精神疾病篩查
中圖分類號:TP391.1 文獻標識碼:A? 文章編號:2096-4706(2023)15-0157-05
Mental illness screening of social network users based on text mining
ZHANG Xinyan
(Yangtze River Delta Center for Medical Device Evaluation and Inspection of National Medical Products Administration, Shanghai? 200135, China)
Abstract: With the popularity of mobile internet, the public is more frequent to use social networks to share their lives and express their thoughts and feelings. As a social platform with the world's largest user base, Twitter has accumulated a wealth of user and text information. This paper uses the Sentiment140 dataset to analyze the Twitter text information, analyzes the exploratory data of dataset from different aspects, and evaluates and compares the different feature extraction methods and classification algorithms by F1 value, and determines the best feature extraction and classification parameters finally. The analysis process and analysis results used in this paper can be used as a reference for text sentiment mining, and provide assistance for the task of sentiment classification based on text information and the diagnosis of mental diseases such as depression.
Keywords: social network; text mining; Digital Therapeutics(DTx); Mental illness screening; Natural language processing
0? 引? 言
抑郁癥是現在最常見的一種心理疾病,以連續且長期的心情低落為主要的臨床特征,是現代人心理疾病中最重要的類型。抑郁癥的臨床表現為心情低落和現實過得不開心,情緒長時間的低落消沉,從一開始的悶悶不樂到最后的悲痛欲絕,自卑、痛苦、悲觀、厭世,感覺活著的每一天都是在折磨自己,消極,逃避,最后甚至有自殺傾向和行為。患者患有軀體化癥狀。胸悶,氣短。根據世界衛生組織2019年底發布的報告,抑郁癥的發病率僅次于世界第一大嚴重的缺血性心臟病,在世界排名前十位的使人喪失勞動能力的疾病中,抑郁癥甚至名列首位,這無疑成為社會安定的巨大隱患。目前全世界抑郁癥患者人數為3.22億人,患病率為4.4%。據不完全統計,我國抑郁癥患者超過9 000萬人,同時,抑郁癥患者人數也在逐年攀升。由于多種社會因素的影響,抑郁癥的確診率低,很多患者罹患抑郁癥后并未及時進行檢查和診斷,即使進行了檢查和診斷,由于病恥感和公眾對該疾病的誤解等因素,對抑郁癥的干預和治療也往往并不及時有效。同時,抑郁癥的確診也存在一些困難。抑郁癥的診斷主要應根據病史、臨床癥狀、病程及體格檢查和實驗室檢查,典型病例診斷一般不困難,一般采用ICD-10和DSM-IV診斷標準進行判別,但抑郁癥存在諸多分型,同時由于抑郁癥的臨床表現容易和其他類型的精神疾病混淆,這些因素都給確診抑郁癥帶來了困難。
隨著社交網絡的蓬勃發展,現代人越來越依賴數字世界。同時,海量的線上文本信息為多種基于文本信息的應用提供了可能,如網絡輿情分析、精神疾病輔助診斷等。近年來越來越多的研究聚焦于使用社交網絡信息對用戶的情感和精神狀態進行判斷。從來源上看,社交網絡的來源豐富,如微博[1-5]、
推特[6-11],及其他來源如雅虎[12]等。從研究的具體問題看,研究的問題多樣,包括情感分析[13,14]、精神疾病如抑郁癥的診斷[1-4,7,15,16]及多任務(multi-task, MT)(如文獻[6]設計了一個多任務分類器同時對文本的情感和抑郁狀態進行判別、文獻[17]中對圖像和文本數據進行多模態融合,并設計了一個同時判別用戶性別和情感狀態的多任務分類器)。此外,特征提取和分類的算法也多種多樣,主要分為兩類,一類基于傳統機器學習方法如支持向量機(support vector machines, SVM)應用非常廣泛[1,2,9,16],此外,隨著大數據時代的來臨,深度學習方法也得到越來越多的使用,如文獻[1,3,16]等使用Word2Vec生成詞向量[15],使用長短期記憶網絡(Long short-term memory, LSTM)進行分類任務[6],利用雙向門控循環單元(Bidirectional gated recurrent unit, BiGRU)和注意力機制(Attention Mechanism)進行分類任務[17],
利用門控循環單元(Gated recurrent unit, GRU)和殘差網絡(Residual Network, ResNet)進行分類任務。目前索引到的文章中使用的推特數據集普遍在萬條數據的級別,如文獻[6]中采集了10 659條推特文本[18],文獻[18]中采集了90 000條推特數據,文獻[9]中采集了12 741條數據,只有文獻[8]中采集了94 707 264條數據達到千萬級別。一般而言,數據量越大,所蘊含的信息就越豐富,因此本文中采用Sentiment140數據集,該數據集含有160萬條數據集,為文本挖掘提供了豐富的素材。
1? 實驗方法
1.1? 數據集
本文中采用Sentiment140數據集,包含2009年4月6日到2009年6月25日共659 775位推特用戶發表的160萬條推特數據,語言為英語。該數據集包含6個字段,分別是標簽(也稱極性,Polarity)、推特ID、發表時間戳、標示、用戶名、推特文本。標簽分為正向標簽(Positive)和負向標簽(Negative),表示本條推特文本的情感狀態。數據集中共有80萬條正向數據和80萬條負向數據,分類均衡。
1.2? 預處理
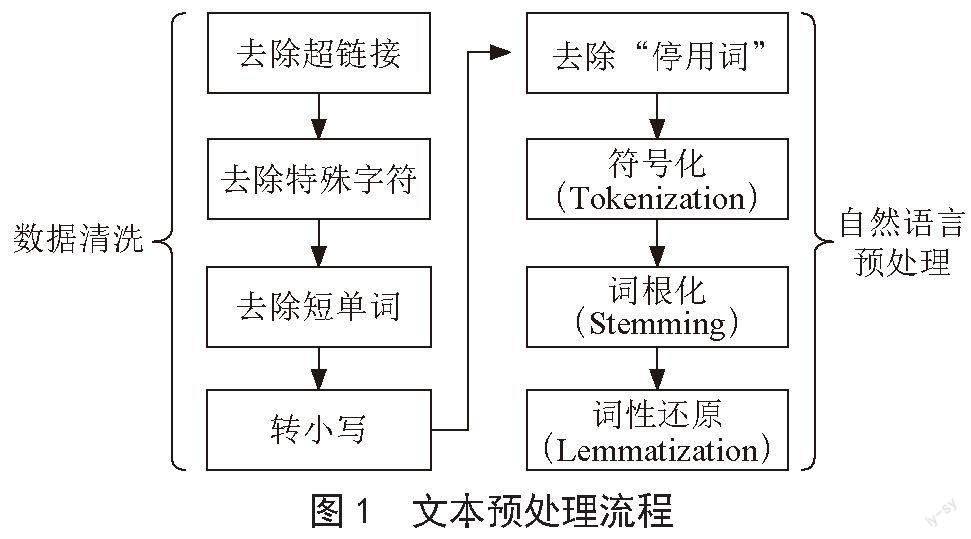
原始文本數據無法直接用于分類任務,因推特文本的多源、異構特征,如推特數據中包含短鏈接、表情、不規范拼寫(如用“yeeeeees”表示“yes”)等,不具有實際含義,需要去除。因此對數據進行預處理,流程如圖1所示。
首先進行數據清洗,去除無語義的信息。去除短單詞是基于這樣一個假設:即過短的單詞(字母個數小于4個)含有有效信息的概率很小,因此去除這些無關信息可以提高分類器的表現。轉小寫是數據清洗必要的一個步驟,在后續特征提取部分,如使用詞袋模型,統一小寫后的文本可以確保相同含義的單詞被視為一個語義單元,如“Monkey”和“monkey”在語義上是一致的,首先需要在形式上將其統一以便后續的特征提取。
僅有數據清洗是遠遠不夠的,還需要使用一些自然語言處理技巧進行進一步的處理,本文使用NLTK[19]工具包對推特文本進行進一步的處理,首先,去除停用詞,英語中的停用詞包含“A”“the”“is”“are”“having”等,這些單詞主要起到承接作用,本身并無語義。然后進行“符號化”,此處使用空格分隔直接將單詞作為元素進行符號化。最后進行詞根化和詞形還原,這兩步的作用和轉小寫類似,將語義相同但形式不同的單詞進行歸一化,如“go”和“went”具有相同的語義,只是因為事態不同而顯示為不同的形式,通過詞形還原可以做到這一點。
1.3? 特征提取
文檔的特征提取是進行情感判別前的關鍵一步,合適的特征提取方法可以很好地提升分類器的表現。文檔是一系列單詞的有序不定長列表。最常見的文檔特征描述方法為詞袋模型(bag of words),詞袋模型的思想是文檔為一個包裹著詞語的容器,通過容器中的詞語的計數等統計量來將文檔向量化(vectorization)。必須說明的一點是,詞袋模型和其他一些文檔模型一樣,是一種有損模型,即建模過程中會丟失一些信息。由于自然語言的特點(非結構化、歧義性、容錯性、易變性、簡略性),無損地對文檔進行建模是不可能的,只能使用合適的建模方式來盡可能地保留文檔的信息。詞袋模型最常用的統計指標為詞頻,即統計一個單詞在文檔中出現的次數,除此之外,還可以選擇布爾詞頻、TF-IDF、詞向量等作為統計指標。一般而言,詞頻向量適合主題較多的數據集;布爾詞頻適合長度較短的數據集;TF-IDF適合主題較少的數據集;詞向量適合處理OOV(Out Of Vocabulary)問題嚴重的數據集。除詞袋模型外,神經網絡模型也能無監督地生成文檔向量,比如AutoEncoder和RBM等。使用深度學習生成地文檔向量一般表現優于詞袋向量,但計算開銷也更大。
特征提取部分分別使用CountVectorizer和TF-IDF(term frequency–inverse document frequency)兩種詞袋模型進行特征提取。其中CountVectorizer即為使用詞頻作為統計指標地詞袋模型,而TF-IDF(詞頻-倒排文檔頻次)除考慮詞頻外,還綜合考慮詞語的稀有程度,因此,TF-IDF屬于多文檔方法。
除使用不同指標的詞袋模型外,同時考慮一元語言(1-gram)模型和二元語言模型(2-gram)對提取效果的影響。基于N-gram的方法是把文檔進行排序,并使用大小為N的窗口對文檔進行分割。簡單地說,基于一元語言模型分割后的元素為單詞,而基于二元語言模型分割后的元素為2個單詞組成的序列,以此類推。
本文使用Scikit-learn庫[20]提供的工具進行特征提取。
1.4? 分類器選擇
分類器對比XGBoost、邏輯斯蒂回歸(Logistic
Regression, LR)和線性SVC(linear support vector classifier)三種算法在不同特征提取參數下的F1值。
XGBoost算法是對GBDT(Gradient Boosting? Decision Tree)算法的優化,兩者都是基于提升(boosting)的方法。其優勢在于高效可拓展和魯棒性強。但其面對高維數據時,無法很好地捕捉其特征,此外,在數據量很大的情況下,深度學習算法相比XGBoost優勢明顯。邏輯斯蒂回歸算法主要用于解決二分類問題,用來表示某件事情發生的可能性。由于本次任務為二分類任務,因此采用邏輯斯蒂回歸作為分類算法之一。邏輯斯蒂回歸算法具有實現簡單、速度快、資源需求低等優勢,其缺點在于容易欠擬合,一般而言模型表現不太佳,只能處理二分類問題且必須線性可分。線性SVC是基于SVM并使用線性核的分類器,SVM通過對特征空間劃分超平面進行分類,其優點在于樣本量要求低,魯棒性強。
2? 探索性數據分析
2.1? 時間分布
首先對數據的時間分布進行可視化,分別從日期和一天中的小時兩個維度進行展示,如圖2所示。
圖2中可發現大量推特數據集中發表于2009-5-29到2009-6-2以及2009-6-5到2009-6-20。此外,
可以發現部分日期沒有或很少有推特發表,如2009-5-23到2009-5-25以及2009-5-27。從情感狀態分布上看,大部分時間正向情感的推特數據量大于負向情感的推特數據量,但從2009-5-17后全部推特數據均為負向數據。
從一天內發表時間點看,正向和負向推特的時間點分布趨于一致,在8—20時之間為下降趨勢并至低估,然后開始上升。值得注意的是,正向推特在8—20時時間范圍內少于負向推特,但在其他時間段尤其是凌晨22至次日5時前,正向推特數量遠高于負向推特。一個可能的猜測是,8—20時為工作時間,負向推特的發出人可能因各種原因無法聚焦個人生活與工作,因此以社交網絡為發泄口表達負面情緒;而在凌晨等休息時間,娛樂活動可以激發人的樂觀情緒,因而此時段發出的推特更傾向于正向情緒。但此猜測并無進一步的依據,如需探究則要有進一步的數據支持。
2.2? 詞云分析
首先對高頻詞進行詞云繪制,詞頻越高的詞語在詞云圖中越大。圖3中可以看到正向推特中“Love”的詞頻很高,而負向推特中“miss”擺在了比較顯眼的位置。
此外,我們對標簽進行分析,推特中標簽指的是以“#”為開頭的單詞,一般推特用戶會以標簽表明推特的主題,因此,標簽對于判斷推特信息的主題或相關的話題十分重要。實際上從圖4的可視化結果看也是如此。在負向推特詞云中,“fail”的詞頻很高,“fail”意為失敗,是一個具有強烈感情色彩的詞語,因此,可以想見,分析標簽中蘊含的信息對文本情感分析至關重要。
3? 實驗結果
我們通過F1值對算法進行評估,并通過10折(10 Fold)交叉驗證抑制隨機因素,確保結果可以反映算法的平均表現。訓練集和測試集的劃分方式為分層隨機劃分,比例為測試集20%,訓練集80%。結果如表1所示。
從表1可以得出結論邏輯斯蒂回歸在各種參數配置下均取得了最佳的效果,且在使用一元TF-IDF方法進行特征提取時取得了最佳的F1值,為76.1%。
4? 結? 論
本文使用百萬級別的推特數據集,對數據集從不同維度開展探索性數據分析,并使用不同特征提取與分類方法對算法進行評估。最終得到最佳的特征提取方法(一元TF-IDF)和最佳的分類器(邏輯斯蒂回歸)。鑒于本次進行實驗的特征提取方法和分類器均為傳統機器學習方法,在將來的工作中擬引入基于深度學習的特征提取方法(如Word2Vec)以及分類方法(如LSTM),進行更加全面的評估。
本文的方法可以用于基于文本信息的用戶情感分析以及精神障礙篩查與輔助診斷,具有廣闊的應用前景。基于社交網絡文本的精神狀態判定是對目前基于量表的精神疾病的診斷方法的很好的補充,同時,社交網絡文本相比量表數據,具有客觀性強、易獲取、成本低等優勢。有理由相信,隨著相關研究的進展,社交網絡文本挖掘精神分析將會對人民精神健康做出更大的貢獻。
參考文獻:
[1] 方振宇.基于抑郁詞典的社交網絡心理障礙檢測方法 [J].電腦知識與技術,2017,13(7):244-247.
[2] 王垚,賈寶龍,杜依寧,等.基于詞向量的多維度正則化SVM社交網絡抑郁傾向檢測方法 [J].計算機應用與軟件,2022,39(3):116-120.
[3] 查國清,胡超然,孫銘濤,等.抑郁癥網絡社交與疑似抑郁微博初步篩選算法 [J].計算機工程與應用,2022,58(1):158-164.
[4] 劉定平,張雪燕.基于社交網絡信息的用戶抑郁癥傾向識別 [J].統計理論與實踐,2021(9):14-21.
[5] LI L,ZHANG Q,WANG X,et al. Characterizing the Propagation of Situational Information in Social Media During COVID-19 Epidemic: A Case Study on Weibo [J].IEEE Transactions on Computational Social Systems,2020,7(2):556-562.
[6] GHOSH S,EKBAL A,BHATTACHARYYA P. What Does Your Bio Say? Inferring Twitter Users Depression Status From Multimodal Profile Information Using Deep Learning [J].IEEE Transactions on Computational Social Systems,2022,9(5):1484-1494.
[7] DE CHOUDHURY M,GAMON M,COUNTS S,et al. Predicting Depression via Social Media [J].Proceedings of the International AAAI Conference on Web and Social Media,2021,7(1):128-137.
[8] ZHOU J,ZOGAN H,YANG S,et al. Detecting Community Depression Dynamics Due to COVID-19 Pandemic in Australia [J].IEEE Transactions on Computational Social Systems,2021,8(4):982-991.
[9] GUPTA P,KUMAR S,SUMAN R R,et al. Sentiment Analysis of Lockdown in India During COVID-19: A Case Study on Twitter [J].IEEE Transactions on Computational Social Systems,2021,8(4):992-1002.
[10] KAUSAR M A,SOOSAIMANICKAM A,NASAR M. Public Sentiment Analysis on Twitter Data during COVID-19 Outbreak [J/OL].International Journal of Advanced Computer Science and Applications,2021,12(2)[2023-02-11].http://thesai.org/Publications/ViewPaper?Volume=12&Issue=2&Code=IJACSA&SerialNo=52.
[11] SHEN G,JIA J,NIE L,et al. Depression detection via harvesting social media: a multimodal dictionary learning solution [C]//IJCAI'17:Proceedings of the 26th International Joint Conference on Artificial Intelligence.Melbourne:AAAI Press,2017:3838-3844.
[12] HIRAGA M. Predicting Depression for Japanese Blog Text [C]//Proceedings of ACL 2017, Student Research Workshop.Vancouver:ACL,2017:107-113.
[13] 周法國,孫冬雪.融入情感和話題信息的中文方面級情感分析 [J].計算機應用研究,2022,39(12):3614-3619+3625.
[14] CAI W,GAO M,JIANG Y,et al. Multi-Source Domain Transfer Discriminative Dictionary Learning Modeling for Electroencephalogram-Based Emotion Recognition [J].IEEE Transactions on Computational Social Systems,2022,9(6):1604-1612.
[15] 張夢娜,王君巖,龍洋,等.基于社交媒體中文本信息的早期抑郁癥檢測 [J].中國生物醫學工程學報,2022,41(1):21-30.
[16] 劉德喜,邱家洪,萬常選,等.利用準私密社交網絡文本數據檢測抑郁用戶的可行性分析 [J].中文信息學報,2018,32(9):93-102.
[17] SUMAN C,CHAUDHARI R,SAHA S,et al. Investigations in Emotion Aware Multimodal Gender Prediction Systems From Social Media Data [J].IEEE Transactions on Computational Social Systems,2022:1-10.
[18] NASEEM U,RAZZAK I,KHUSHI M,et al. COVIDSenti:A Large-Scale Benchmark Twitter Data Set for COVID-19 Sentiment Analysis [J].IEEE Transactions on Computational Social Systems,2021,8(4):1003-1015.
[19] BIRD S,KLEIN E,LOPER E. Natural Language Processing with Python:Analyzing Text with the Natural Language Toolkit [M].OReilly Media,Inc.,2009.
[20] PEDREGOSA F,VAROQUAUX G,GRAMFORT A,et al. Scikit-learn:Machine Learning in Python [J].The Journal of Machine Learning Research,2011,12(1):2825-2830.
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識與技術(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學學報·自然科學版(2016年3期)2016-06-25 06:47:25
語文教學之友(2016年5期)2016-06-15 12:15:44
