知識與數據混合驅動的高速飛行控制方法綜述
2023-09-22 12:56:16柳嘉潤張華明賈晨輝劉曉東
宇航學報 2023年8期
黃 旭,柳嘉潤,張 遠,張華明,賈晨輝,劉曉東
(1. 北京航天自動控制研究所,北京 100854;2. 宇航智能控制技術全國重點實驗室,北京 100854)
0 引 言
隨著飛行器任務多樣性不斷提高,擁有寬速域和跨空域等特點的高速飛行器成為了21世紀航空航天領域的前沿研究熱點之一。相比于傳統飛行器,高速飛行器的寬飛行包線、非常規先進布局/變體布局、復合材料和靈巧材料結構、多元混合控制效應、容錯/可重構的控制需求等新技術特征不斷涌現[1],發動機與動力學的耦合、氣動熱彈性力、動力學耦合等特性更加顯著[2],意味著其控制難度上升,對先進控制方法的需求更為迫切。一般地,高速飛行器的控制器設計需考慮以下幾個關鍵問題[3-9]:
1) 不確定性
該類飛行器的實際飛行數據相比于常規航空飛行器較少,且空氣動力學數據庫中的數據值與實際值的差異不易評估與修正,從而產生參數不確定性。建模及設計控制器時對模型進行了簡化,可能會忽略一些高階模態,產生未建模動態。馬赫數(Ma)大于6時會產生真實氣體效應影響飛行器表面壓力分布從而改變氣動力與力矩系數,產生氣動不確定性。機體彈性特性顯著時產生的形變使飛行器表面受力不均,帶來的機體不確定性。發動機和機體,以及非常規布局等,產生耦合不確定性。測量誤差和噪聲等,產生狀態不確定性。
2) 伺服特性和控制分配
工程應用中需充分考慮伺服特性,如舵面飽和、延遲和死區等,這些特性的影響在高速飛行器這類具有較快動態響應的對象中更加顯著。且單一的控制形式可能在某些飛行段受限,需要進行復合控制。如再入過程中大氣稀薄、動壓較小的階段,氣動舵面控制能力不足,需要設計分配方法實現其與反作用控制系統(Reaction control system, RCS)的復合控制。這類具有異類操縱機構配置的飛行器必然存在異構伺服特性問題。
3) 變外形/組合構型的控制
首先該類飛行器飛行速域寬且飛行空域大,固定布局難以滿足要求,其次不同的構型可以靈活分配飛行任務。飛行器擁有變外形能力時,需要考慮構型間的切換控制以及變外形過程的穩定控制。在將變形量作為控制輸入進行研究時,則進一步增加了系統復雜度,需考慮控制分配等問題。傳統基于線性模型的增益預置控制等方法難以滿足此類飛行器的高品質控制需求。
4) 容錯控制與安全控制
該類飛行器的飛行環境復雜且惡劣,控制系統需要具備一定的容錯控制能力以應對執行機構和傳感器故障等。提高控制系統的魯棒性和自適應性,或者建立故障診斷與控制器重構的機制,都是有效的容錯控制思路。此外,飛行過程中存在超燃沖壓發動機狀態邊界在內的安全邊界,設計控制器時也需要充分考慮這類約束,在保證安全的前提下盡量提高控制器的性能。
針對上述關鍵問題,當前主要手段是基于建立的飛行器模型進行控制器的設計工作。飛行器模型、控制理論以及控制器的設計經驗等均屬于本文中定義的“知識”范疇,是對原始數據等進行人為提煉和總結后的產物。知識驅動的控制方法應用于高速飛行器時,一方面,模型過于復雜時,以小偏差線性化和線性控制理論為基礎的傳統工程設計方法面臨嚴峻挑戰,可靠控制系統的設計難度劇增;另一方面,模型不匹配、測量手段不足和建模成本高等問題導致難以對被控對象進行較為精確的建模甚至無法建模,依賴模型的非線性控制方法能力受到限制。相比于知識驅動的控制方法,數據驅動的方法則直接通過數據構建相應的映射關系,具有對精確建模依賴弱、算法通用性強和算法庫豐富等特點[10]。其中以深度強化學習(Deep reinforcement learning, DRL)為代表的數據驅動方法已在行星探測[11]、空間操控[12]、飛行決策[13]和目標打擊[14]等領域得到了研究與應用。然而當前數據驅動方法存在物理意義不夠清晰和對高質量數據需求大等問題,對于高速飛行器這類歷史數據不豐富且需要保證飛行安全性的對象而言,其工程應用相對困難。
隨著人工智能技術的發展,知識與數據結合相關的人工智能思路不斷被提出,如知識、數據、算法和算力四要素驅動的第三代人工智能[15]以及知識/數據算法級組件化協同控制[10]等。在航空航天領域中,諸多學者也都提出了關于知識與數據結合的控制觀點[16-17]以應對飛行器發展所帶來的新的控制問題。
本文將從知識與數據混合驅動的不同控制框架出發,對此類方法在高速飛行控制中的應用進行總結、分析和展望。文中所涉及的數據驅動方法以機器學習方法為主,且主要著眼于高速飛行器的在線姿態控制問題。值得注意的是,由于智能控制發展過程中所涉及的理論和應用場景十分廣泛[18],文中并沒有以“智能控制方法”來表述所提及的數據驅動和混合驅動控制方法。
1 知識驅動和數據驅動方法的界定及分析
1.1 知識驅動方法的界定及分析
本文所提到的知識,側重于在執行具體飛行任務之前通過各種手段所掌握的先驗知識,如飛行器模型。飛行器模型的內涵包括模型的形式以及模型的參數。對于飛行器運動學/動力學模型,常基于牛頓歐拉方程或拉格朗日方程進行建立(對于變外形飛行器還可能涉及如凱恩法在內的多體動力學建模方法),常用微分方程組的形式進行描述;氣動模型則常以插值表或多項式等形式描述;除此之外,地球引力模型、風模型、溫度模型和大氣密度模型等均有不同的描述形式。模型參數是依賴于模型形式的具體數據,可通過不同手段進行測量或估算。如飛行器轉動慣量和彈性模態參數可分別通過工程估算和振動實驗等方式獲得;氣動參數可依靠風洞實驗、計算流體力學方法(Computational fluid dynamics, CFD)和工程估算等手段獲得;風場模型參數則可通過統計風速/風向數據或飛行前測量等方式獲得。若飛行器可重復使用或飛行架次較多,則可基于已完成的飛行控制任務中所收集的數據對知識進行修正,從而形成新的先驗知識。除此之外,控制領域的相關理論,如Lyapunov穩定性理論和Bellman最優原理等,以及控制器設計經驗如參數的選取和性能指標的設定等,也都屬于知識的范疇。
基于以上知識,形成了各類知識驅動的控制方法,如PID控制、動態逆、反步法、滑模控制、自抗擾控制和預設性能控制等。知識驅動的控制方法理論體系完備,具有較清晰的物理意義,且運算效率較高。但對于高速飛行器所面臨的控制問題,工程中常用的基于經典控制理論的增益預置PID控制方法由于依賴小偏差線性化等理論,對強非線性和強耦合特點的被控對象適應能力差,且大飛行包線也會大大增加特征工作點的數量從而增加設計成本。其他方法除了依賴較為精確的模型外,存在動態逆的逆誤差、反步法的“計算膨脹”、滑模控制抖振抑制與高精度控制的矛盾、自抗擾控制魯棒性和抗噪性的矛盾以及預設性能控制的脆弱性等問題。相關方法已在許多文獻[4,19]中進行了總結,本文不再進一步說明。以上提到的部分控制方法還常與干擾觀測技術、指令濾波技術等配合使用,以進一步提升性能,但這類技術本質上也都基于模型進行設計。
綜上,在飛行任務復雜程度加劇,強干擾、強非線性、強不確定等問題更加突出等背景下,知識驅動方法在保證穩定性和魯棒性方面面臨更大挑戰。
1.2 數據驅動方法的界定及分析
本文定義的數據包括離線數據和在線數據,前者指通過各類地面實驗獲得的原始數據以及歷史飛行數據等,后者指在執行具體飛行任務過程中通過各種實時測量手段所獲得并在線進行處理和運用的數據。知識驅動和數據驅動的本質區別在于前者通過某些技術手段對原始數據進行了人為提煉,如簡化、歸納和特征提取等,形成了以模型和經驗等表現形式的抽象知識,并基于抽象知識實現控制目標。而后者則是基于較為原始的數據通過學習等方式完成控制任務。當前飛行器控制中常用具有強非線性和強決策能力等特點的機器學習方法完成包括系統辨識、不確定性補償以及系統控制在內的各類任務,本文所述的“數據驅動方法”即主要討論這些機器學習方法。
神經網絡(Neural network, NN)、模糊邏輯系統(Fuzzy logic system, FLS)、支持向量機(Support vector machines, SVM)以及高斯過程回歸(Gaussian process regression, GPR)等機器學習方法均具有高精度非線性逼近能力,且研究人員可以根據具體問題選擇和設計相應的模型。控制領域中常用的神經網絡經典拓撲結構包括全連接神經網絡、徑向基神經網絡(Radial basis function neural network, RBFNN)和循環神經網絡(Recurrent neural network, RNN)等。隨著深度學習技術的發展,包括深度神經網絡(Deep neural network, DNN)、長短記憶(Long short-term me-mory, LSTM)神經網絡和深度貝葉斯神經網絡在內的新拓撲結構被提出并用于解決更加復雜的分類和回歸等問題。不同于NN,SVM基于不同的核函數處理各類線性和非線性問題,在解決小樣本問題時具有一定優勢。GPR則基于嚴格的統計學習理論,可有效處理具有高維和小樣本特點的復雜問題,在解決回歸問題時與NN和SVM相比具有易于實現、超參數自適應獲取以及輸出量的概率意義明確等優點[20]。對于FLS,本文討論其中具有自適應逼近能力的相關方法,可通過模糊推理以任意精度逼近任意連續光滑函數。雖然上述方法均具有良好的性能,但實際應用時還需考慮飛行器控制系統的在線計算資源分配問題。常用思路是降低算法的在線計算復雜度并將學習形式從批量改進為增量以優化在線問題的求解,如增量支持向量機[21]、增量稀疏譜高斯過程回歸[22]和增量集成高斯過程回歸[23]等。除此之外。部分模型如DNN和LSTM在線時僅進行前向計算,對其自身的泛化能力和離線訓練時樣本的質量/數量提出了更高的要求。
不同于以上主要基于監督學習機制進行參數更新的方法,強化學習(Reinforcement learning, RL)則是一類基于增強學習機制通過交互進行策略學習的方法。其中自適應動態規劃(Adaptive dynamic programming, ADP)方法基于Bellman最優控制原理通過行動者-評論家(Actor-Critic)架構求解控制問題的哈密頓-雅克比-貝爾曼方程,從而得到近似最優控制策略。ADP又可分為啟發式動態規劃(Heuristic dynamic programming, HDP)以及二次啟發式動態規劃(Dual heuristic dynamic programming, DHP)等,DHP通過將價值函數對狀態的導數作為Critic的輸出來提高收斂性,但增加了對系統動力學信息的依賴。動作依賴(Action dependent, AD)型ADP方法如動作依賴型啟發式動態規劃(Action dependent HDP, ADHDP)則通過引入狀態行為值函數的方式隱式獲取系統的動力學信息,但同時也提高了方法對數據量的要求[24]。近年興起的深度強化學習(Deep reinforcement learning, DRL)方法則是結合了深度學習和強化學習的優點,多用于解決復雜環境下高維系統的決策控制問題。無模型(model-free)的DRL方法開源算法庫豐富且拓展性強,基于其獲得的飛行控制策略常具有強泛化能力和魯棒性等特點,但其實際控制效果也一定程度上依賴于地面飛行模擬器搭建的充分程度[25]。當前常用的無模型DRL算法包括深度確定性策略梯度(Deep deterministic policy gradient, DDPG)、隨機策略優化(Proximal policy optimization, PPO)以及軟行動者-評論家(Soft actor-critic, SAC)等,且算法的發展迭代十分迅速。
雖然數據驅動方法擁有弱模型依賴和強自適應能力等優點,但其物理意義并不清晰且對數據要求較高。應對復雜的飛行控制問題時相比于知識驅動方法的分析難度更大,且穩定性和收斂性不易保證。部分數據驅動方法無法獨立完成控制任務,需要與知識驅動方法配合使用。表1從內涵、特征、優缺點等方面對知識驅動方法和數據驅動方法進行了總結和對比。

表1 知識驅動與數據驅動方法對比Table 1 Comparison between knowledge-based and data-driven methodologies
2 知識與數據混合驅動的控制方法分類與進展
結合本文第一節,無論是數據驅動還是知識驅動方法均有其不足與局限性,而將兩者結合運用則可使其優勢互補,進一步增強方法的性能。數據驅動方法具有非線性表達能力和離線/在線學習等特點,可一定程度上彌補模型復雜、無精確建模和環境不確定性下知識驅動方法的局限性。而基于知識可對復雜問題進行分解降維,或對數據驅動方法的參數初值和學習架構等進行優化,以利于數據驅動方法的收斂。圖1總結了高速飛行器控制中數據驅動方法和知識驅動方法的具體作用形式以及多類混合驅動方法思路。混合驅動方法中除了智能觀測器外,還有通過模仿學習、設計啟發式目標函數以及知識化機器學習模型結構等方式對數據驅動方法進行增強的思路[10],對此本文不再展開。文中主要討論混合驅動的控制方法框架,依據(知識增強的)數據驅動方法在框架中的重要程度以及知識和數據的結合形式將其分為三大類:1)基于數據修正的知識驅動控制框架;2)基于知識補償的數據驅動控制框架;3)知識與數據并聯型控制框架。
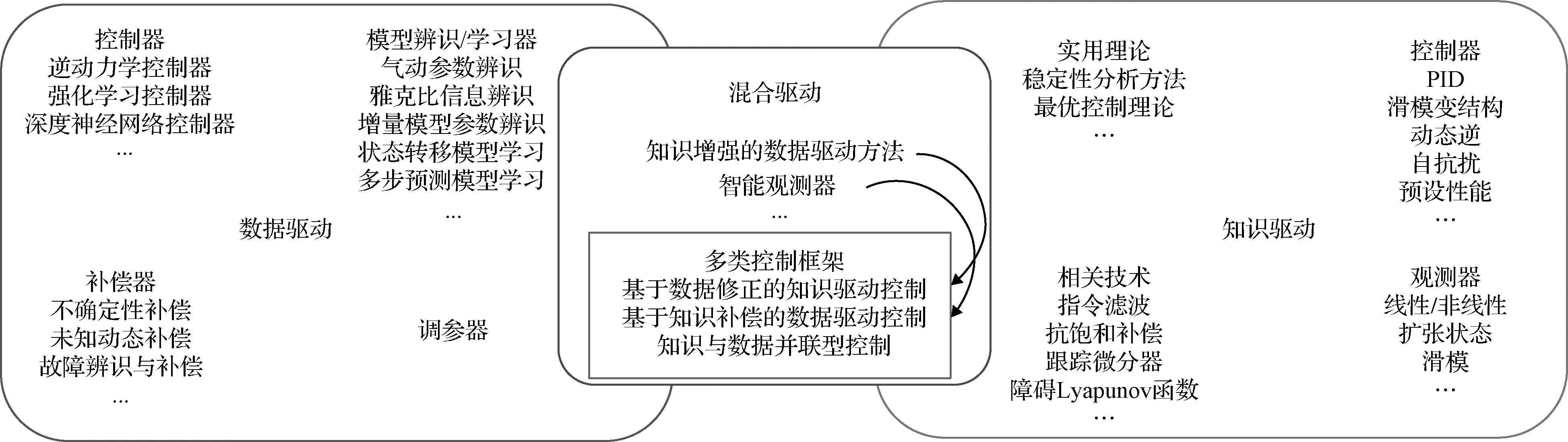
圖1 高速飛行器控制中的知識、數據及混合驅動方法Fig.1 Knowledge-based, data-driven and cooperating methods in high-speed vehicle control
2.1 基于數據修正的知識驅動控制框架
基于數據調優的控制框架中,常利用RL類方法通過自適應調節知識驅動控制器的增益等手段優化控制品質。文獻[26]針對具有未知不確定性和外部干擾的變外形近空間飛行器提出了一種切換自適應自抗擾控制律,利用角度和角速度兩類誤差設計ADHDP的代價函數在線調節自抗擾控制器的增益以提升變形過程中的姿態控制品質。文獻[27]基于DDPG算法根據穩定性和魯棒性指標設計獎勵函數,訓練智能體進行魯棒控制器的參數調優,實現了含有氣動伺服彈性的飛行器系統(系統狀態除了位置姿態外還包括氣動力滯后項和伺服機構的狀態)的控制,且控制效果優于手動調參的魯棒控制器。相比于上文,文獻[28]還設計了含有控制輸入約束的分段獎勵函數,基于DDPG算法學習反步法設計的控制器的參數調節策略,在無抗飽和輔助結構和障礙Lyapunov函數(Barrier Lyapunov function, BLF)設計等條件下取得了較好的考慮狀態約束下的抗飽和控制效果。該框架中知識驅動控制器需要根據系統知識進行設計,控制器參數范圍可以事先設定,有較高的安全性。
基于數據補償的控制框架中,數據驅動方法的使用形式靈活,既能夠根據需求補償系統的建模不確定項、干擾和難以建模的部分動態等,也能進一步設計混合驅動觀測器以增強知識驅動觀測器的性能。文獻[29]針對非仿射飛行器模型使用模糊神經網絡估計飛行器的未知動態并設計了新型魯棒控制器,并基于Lyapunov理論推導了神經網絡參數變化律,仿真結果表明該方法能夠有效處理參數不確定性。文獻[30]使用雙RBFNN分別逼近高速飛行器高度和速度通道的不確定性,并基于高階跟蹤微分器設計了神經動態逆控制器,實現了高速飛行器的自適應高度與速度控制。文獻[31]同樣通過RBFNN對嚴格反饋多入多出非線性系統的不確定性動態進行逼近,利用誤差動態和歷史數據構造了新型臨界預測誤差增強了神經網絡的非線性逼近能力,并將該方法用于高速飛行器再入控制中。不同于以上文獻中考慮的標準飛行器模型形式,文獻[32]對系統的全狀態量進行非線性映射以處理狀態約束并針對映射后的多變量系統使用多個RBFNN逼近未知動態,值得注意的是該文獻引入了自適應界估計(Adaptive bound estimation)方法,減小了控制框架對多重隨機不確定性先驗上界信息的依賴。除了神經網絡外,相關研究中還使用SVM和RL等數據驅動方法作為補償器。文獻[33]使用最小二乘SVM方法逼近高速飛行器高度和速度子系統的動態,該思路只需更新兩個自適應標量,可有效減小在線計算量。文獻[34]采用在線SVM擬合基于高速飛行器模型設計的理想非線性廣義預測控制器中的不確定項,與使用RBFNN進行不確定性補償的仿真結果對比表明該方法具有良好的魯棒性和抗干擾能力。文獻[35]使用RL方法離線訓練并在線估計飛行控制系統中的總擾動,其中actor網絡用于產生總擾動的估計,而critic網絡則對估計精度進行評價。數據驅動方法還可與知識驅動觀測器結合以提升觀測器的狀態估計和不確定性補償等性能。文獻[36]針對高速飛行器在各種擾動情況下的高精度姿態跟蹤問題提出了一種基于極限學習機神經網絡擾動觀測器(ELM-NNDO)的滑模控制策略,并基于Lyapunov綜合方法推導出神經網絡權值更新律。文獻[37]提出了一種由基于神經網絡的Luenberger型觀測器和同步擾動觀測器組合而成的復合觀測器,實現了未知非線性動力學和未知擾動同時存在時系統狀態的估計。文獻[38]利用區間II型FLS構造函數逼近器來逼近飛行器的未知動態,在此基礎上設計了固定時間收斂的自適應模糊觀測器用于估計未測航跡角以及攻角。文獻[39]利用FLS逼近角度環的參數不確定性以及角速度環的綜合擾動,并在此基礎上設計了模糊擾動觀測器。此外,數據驅動補償器也常用于故障的辨識和補償。文獻[40]使用改進的RBFNN和自適應方法設計了一種容錯滑模控制器,其中神經網絡作為自適應律的一部分對故障值進行估計,該方法可以快速處理執行器的效益損失故障以及卡死故障。文獻[41]設計了障礙Lyapunov函數處理攻角約束并使用魯棒自適應分配律對已知形式但數值未知的執行機構失效故障進行補償。文獻[42]通過結合FLS和一種界估計方法處理與系統狀態相關的時變執行機構故障。文獻[43]針對具有初始系統故障和含非高斯噪聲輸出的高速飛行器系統,通過有理平方根B樣條方法將測量的姿態角轉化為相應的概率密度函數從而通過自適應模糊觀測器估計干擾和故障。文獻[44]設計了自適應觀測器和SVM自適應補償器以分別補償瞬時故障和慢時變故障。文獻[45]設計了FLS逼近系統模型并通過設定逼近殘差閾值對傳感器故障進行檢測和隔離,最終基于模糊增強觀測器對故障值進行準確估計。當存在更復雜的故障情況時,則需考慮故障辨識和控制器重構等手段。文獻[46]提出了一種基于長短記憶(LSTM)神經網絡的故障診斷單元實現了多源干擾下的執行機構故障診斷,將執行機構失效故障和偏移故障的信息采用魯棒最小二乘分配方法為執行機構分配控制力矩,并結合擴張狀態觀測器對控制分配誤差進行補償。文獻[47]對故障特征進行了相關性分析、降維和敏感特征提取,并通過含有遺傳算法優化的SVR方法實現了故障模式識別,實現了針對多傳感器融合故障的定位和診斷/單傳感器故障時間判斷。考慮氣動伺服彈性[39,48-49]和執行機構非線性[50]的高速飛行器控制問題也常用該類框架解決。
基于模型辨識/學習的控制框架中,數據驅動方法一般通過辨識系統參數、學習正向模型映射以及預測未來狀態等方式將相關信息提供給知識驅動控制器。文獻[51-52]基于機器學習方法通過跟蹤誤差和系統狀態等信息在線擬合力矩系數在內的氣動參數,從而輔助姿態控制過程。文獻[53]基于GPR辨識系統的增量模型以得到非線性動態逆控制器中的系統控制矩陣,一定程度上解決了帶遺忘因子的遞歸最小二乘方法(RLS)針對快時變系統辨識效果差的問題。文獻[54]使用FLS同時逼近仿射系統的未知動態和輸入動力學,并通過設計非線性觀測器來補償逼近誤差影響,最終得到了基于模糊重構的動態面控制器。文獻[55]使用SVM回歸模型在線擬合含有常數和動態不確定性的系統非線性模型,從而將原飛行控制問題轉化為了二次規劃問題,使用模型預測控制(MPC)方法進行在線求解。除了對模型的部分參數進行辨識或直接擬合飛行器線性/非線性模型外,也可考慮更復雜的數據建模形式,如概率空間下的狀態轉移模型和多步預測模型等,文獻[56]基于LSTM神經網絡設計了多速率采樣器以從非平穩時間序列中更好的進行特征提取,實現了高速飛行器這類高速率系統的建模以及響應預測。該框架中主要關注數據驅動方法的收斂性以及辨識/預測的快速性和準確性等,最終效果除了與各類數據驅動方法的特點相關外,也與系統復雜度和參數的可辨識性等密切聯系,且一般而言在線的辨識/學習過程需要一定的激勵作用。
基于數據修正的知識驅動控制框架中知識驅動控制器的結構并沒有較大改變,大部分情況下工程中相應的設計和分析方法仍然能夠使用,當前該類框架相比于后兩類更易于工程實現。
2.2 基于知識補償的數據驅動控制框架
該類框架中數據驅動控制器一般通過監督學習或強化學習方式獲得飛行器的控制策略。本文按照學習機理將該類框架進一步分為:1)基于逆系統學習的控制框架;2)基于RL理論的控制框架;3)基于人工樣本的控制框架。該大類框架圖如圖3所示,知識驅動方法包括狀態觀測器和抗飽和補償器等,ξ代表抗飽和補償量。知識驅動方法也可輸出不直接作用于系統的參考控制量ukc等,為數據驅動控制器的監督學習過程提供參考輸出。
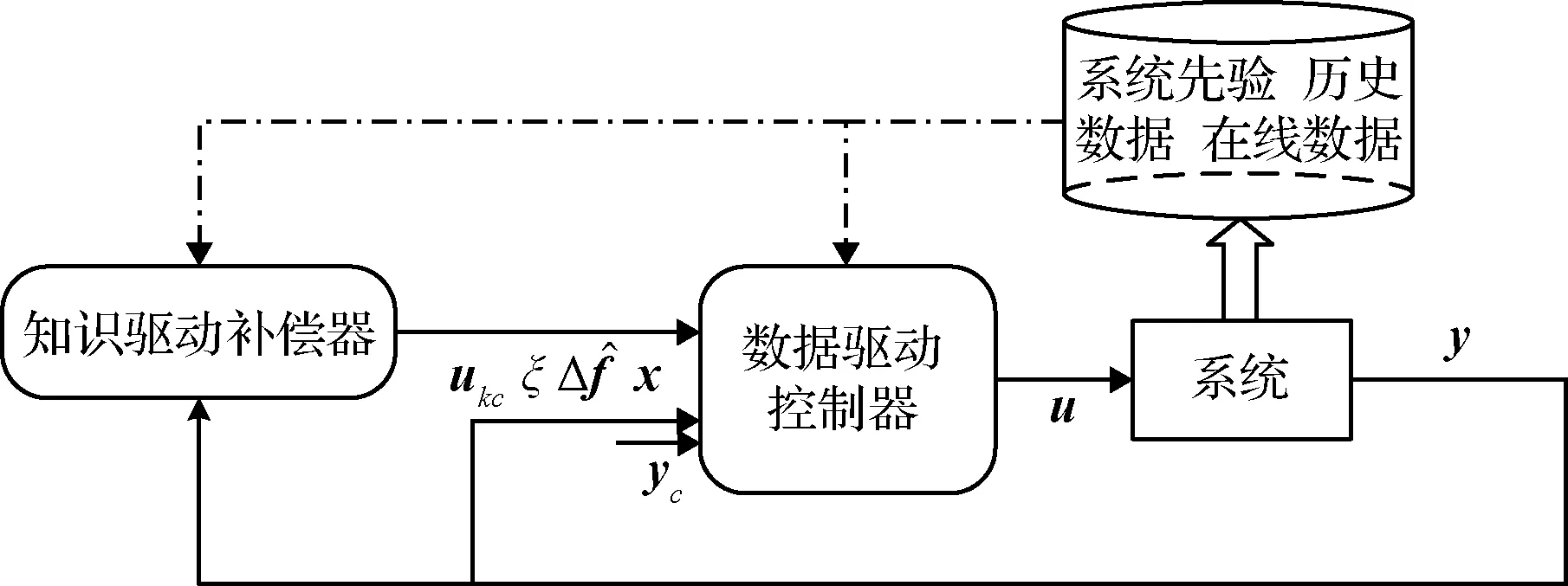
圖3 基于知識補償的數據驅動控制框架Fig.3 Data-driven control framework based on knowledge compensation
基于逆系統學習的控制框架中,數據驅動控制器本質上是在線解決以系統相關狀態作為輸入,系統控制量作為輸出的回歸問題。除了直接基于系統的輸入輸出數據學習前饋控制策略并結合反饋控制律完成控制任務外,還可將知識驅動控制器的輸出作為回歸問題訓練集中的輸出數據引導數據驅動控制器進行在線學習。如文獻[57]設計了一種自適應模糊神經網絡控制器,僅以跟蹤誤差作為控制器輸入并將標稱動態逆控制器的輸出作為參考輸出,基于反向傳播法推導了控制器的自適應律,仿真結果驗證了在大不確定條件下控制器的有效性和魯棒性。當飛行器模型未知或存在不確定性時,還可通過數據驅動方法學習和補償正向模型從而與逆動力學控制器配合使用,如文獻[58]設計了雙神經網絡擬合正逆動力學的控制架構,將用于逆動力學學習的神經網絡與另一個基于神經網絡的正向動力學補償控制器結合,通過飛行數據學習由狀態量和目標狀態到控制量的映射,隨著學習的推進,神經網絡逆動力學控制器的輸出將占主導。
基于RL理論的控制框架中,數據驅動控制器通過交互的方式學習控制策略。該框架中可能存在基于知識設計的前饋控制部分,但前饋部分只與參考輸入和系統動態有關,并不能單獨使系統穩定,這里需要注意和下一節的知識與數據并聯型的控制框架進行區別。文獻[59]使用無跡卡爾曼濾波狀態估計器估計了winged-cone飛行器縱平面姿態的不確定性并得到了前饋控制部分,反饋控制策略使用策略迭代(PI)方法自學習得到,且基于Lyapunov理論證明了單次迭代過程中價值函數單調遞減且能收斂到Bellman最優解。文獻[60]在系統模型完全未知的情況下,前饋動態逆控制器和系統模型均由神經網絡學習得到,反饋控制律則由ADHDP方法學習得到。文獻[61]使用神經網絡處理系統的參數不確定性和未建模非線性,并以此優化由離散最小值原理推導的Actor-Critic控制架構的最憂性條件,仿真結果驗證了該設計方法在不確定條件下對吸氣式高速飛行器跟蹤控制的有效性。為了進一步減小ADP類控制方法在在線控制時對全局模型的依賴,Zhou等[62]提出了基于增量模型的自適應動態規劃方法(iADP)以及其改進方法,應用于飛行器的在線自學習控制[63]、故障容錯控制及狀態部分可觀測條件下的飛行控制[64]中,該類方法通過RLS方法在線辨識系統增量模型并預測下一拍狀態,ADP則基于增量模型信息進行策略更新。文獻[65]在iADP的基礎上提出了基于誤差動力學的DHP飛行器自學習控制方法,方法對誤差狀態進行了增廣并基于RLS辨識誤差動力學的控制矩陣和參數不確定性,實現了高速變外形飛行器三通道耦合條件下的姿態跟蹤控制。雖然上述的部分方法對知識的依賴程度不高,但在線學習時當數據多樣性不足時也易影響學習效果,常需通過注入持續激勵和探索量等手段改善學習效果。近期也有將經驗回放等方法代替傳統激勵條件的研究,如文獻[37]提出一種基于復合觀測器的RL跟蹤控制器,推導了含有反饋控制量的誤差動力學形式并采用歷史經驗重放和并行學習代替持續激勵從而實現高速飛行器的最優姿態跟蹤。
基于人工樣本的控制框架中一般基于其他控制/優化方法生成數據集,后使用深度神經網絡等數據驅動方法學習控制策略來達到提高在線計算效率和增強泛化能力等目的。文獻[66]使用粒子群優化方法求解了含輸入飽和及氣動熱等約束的最優控制問題,在不同初始化條件下生成了最優軌跡數據集,使用深度神經網絡學習狀態到動作的映射關系,從而能在線實時計算最優反饋控制量實現飛行器的6自由度控制。文獻[67]通過MPC離線求解含有輸入飽和約束的優化問題生成大量樣本數據,訓練深度神經網絡學習控制分配策略,從而在在線控制時實現高效的優化問題近似求解。當要求初始數據驅動控制器擁有一定的控制能力以保證飛行的安全性或滿足收斂條件時(如策略迭代方法收斂的前提之一是初始控制策略能夠使系統穩定),除了基于RL方法進行離線學習外,基于知識驅動控制器產生的樣本對數據驅動控制器進行預訓練也是途徑之一。相比于姿態控制,此框架更多時候應用于高速飛行器的在線軌跡規劃中[68-70],耗時的優化計算和網絡訓練等過程是離線進行的,在線時僅進行網絡的前向計算,控制器擁有良好的實時性和收斂性。
基于逆系統學習的控制框架和基于RL理論的控制框架均擁有無模型/弱模型依賴條件下的控制策略學習能力,這兩類框架在如機械臂和四旋翼飛行器控制等領域已取得了一定的研究成果,但在高速飛行器這類復雜系統中應用時方法的收斂性和穩定性還有待進一步分析和研究。當前基于人工樣本的控制框架在姿態控制領域的研究較少,更多用于解決更高層次的控制問題如在線軌跡規劃。
2.3 知識與數據并聯型的控制框架
本節將繼續討論數據驅動控制器和知識驅動控制器并聯作用形式,方案框架如圖4所示。此框架中兩類控制器均輸出控制量,常基于知識驅動控制器推導相應的誤差動力學等方程,后使用數據驅動控制器解決最優跟蹤/最優調節等問題。框架中知識驅動控制器單獨作用時能夠使系統保持穩定,數據驅動控制器則根據不同的設計思想完成如誤差修正等任務。此類設計思想能夠降低數據驅動控制器的學習復雜度,也能最大程度上利用知識來保證飛行過程中系統的穩定性等。
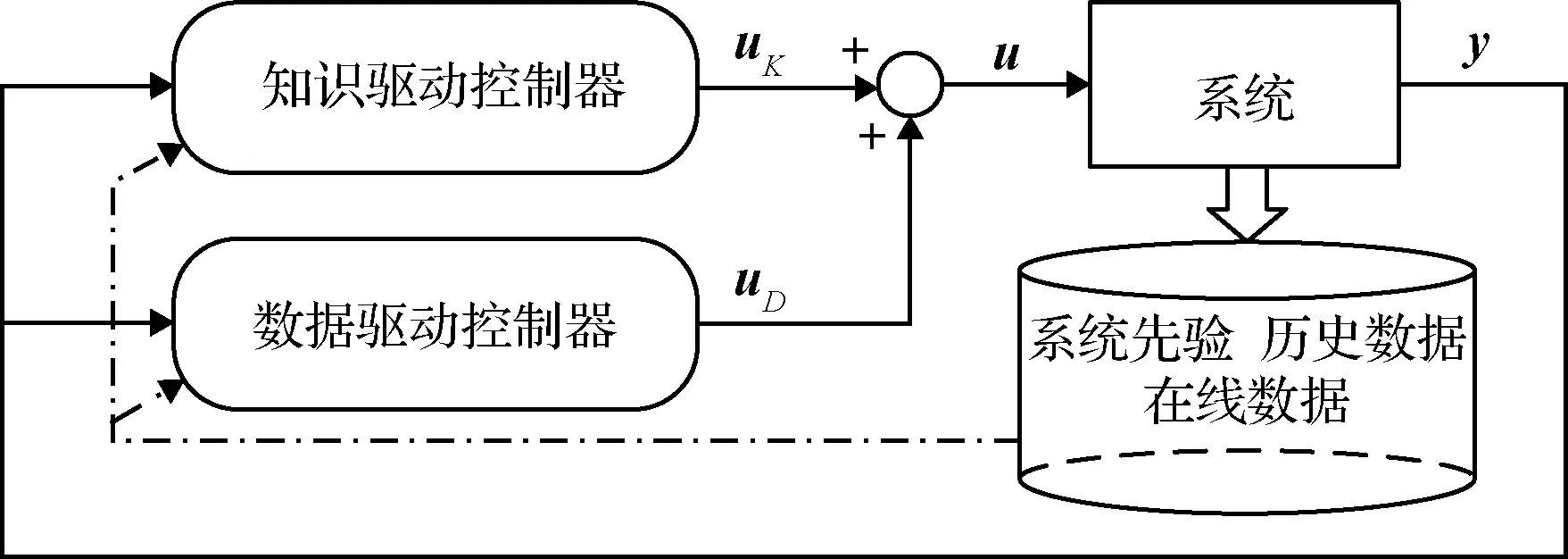
圖4 知識與數據并聯型控制框架Fig.4 Parallel control framework of knowledge and data
文獻[71]針對高速飛行器的高度速度控制問題提出了數據驅動的強化學習輔助控制方法,其中滑模控制器控制飛行器穩定飛行,無模型的ADHDP方法僅通過數據學習跟蹤性能優化策略。值得注意的是由于ADHDP這類方法在學習控制策略時能夠隱式學習系統動態從而無需系統先驗[72],故在設計時除了將飛行器跟蹤誤差和參考作為狀態外,還常以誤差積分等項作為智能體狀態進一步增強控制性能,且知識驅動控制器也能一定程度上減弱此類方法需要數據量大帶來的控制風險。文獻[73]針對高速飛行器三通道姿態控制,快回路使用RBFNN擬合未建模動態并結合自適應積分滑模控制器作為跟蹤器,將問題轉化為最優跟蹤問題后反饋部分利用ADP進行控制策略的學習,前饋控制量則直接由模型信息和參考軌跡得到。文獻[74]基于RNN和反步法設計前饋控制器,將再入飛行器的姿態跟蹤問題轉化為姿態角/角速率跟蹤誤差的最優反饋控制問題,從而引入ADP方案解決。文獻[75]提出了一種由基于DRL的輔助控制器和固定時間抗干擾控制器組成的復合控制框架,抗干擾控制器能夠將部分可觀測馬爾科夫決策過程(POMDP)轉化為馬爾科夫決策過程,進一步由DRL學習輔助控制策略來提高控制性能,該框架可以一定程度上解決高速飛行器的強不確定和非真實環境訓練下的DRL泛化問題。
綜上,對知識與數據混合驅動的飛行控制方法進行了分類,包括3大類與7小類,數據驅動方法可以在不同的框架中完成不同的任務以提高控制方法的魯棒性和自適應性。值得注意的是知識與數據混合驅動的控制方法設計非常靈活,該種分類方法也并非絕對,部分子框架間也可以進行組合,設計的復雜程度和結構形式應依據具體對象以及控制需求而定。下面將針對本節總結的控制框架,討論混合驅動方法在工程應用中的若干關鍵問題。
3 混合驅動方法在工程應用時的若干關鍵問題
3.1 理論可靠性問題
工程應用中為保證飛行任務的成功必須對系統的穩定性/可靠性進行評估,如基于經典控制理論設計控制器時可通過頻域法定量分析開環系統的幅值和相位裕度,基于現代控制理論設計的控制器則多是通過Lyapunov函數進行穩定性分析。而數據驅動方法可解釋性較弱且常涉及在線學習過程,混合驅動方法的收斂性、穩定性以及可靠性分析則成為其能否順利工程應用的關鍵之一。
在當前混合驅動的方法研究中,考慮在線學習時通常是在模型不確定性和擬合誤差有界等假設下開展Lyapunov穩定性證明或學習律的推導等工作,多為證明閉環系統的一致最終有界(UUB)穩定[31-32]和漸近穩定[42]等。證明的復雜度與具體控制框架和系統等相關,如基于數據調優的控制框架可以以滿足穩定性條件的控制參數區間為基礎進行尋優[26],控制框架中含有數據驅動補償器或數據驅動控制器時則常設計含數據驅動方法參數估計誤差在內的Lyapunov函數[37,71,73]。當僅有離線學習時,部分控制框架可對系統進行線性化從而分析穩定性[76]。但對大多數復雜系統而言,蒙特卡洛仿真可能是當前最為有效的間接驗證或分析方式。除了使用控制領域中的穩定性證明工具,部分研究開始借助其他領域的方法對系統的穩定性進行分析,如文獻[77]提出了一種自適應學習率的增量RL控制方法,通過小波分析監測飛行狀態的振蕩情況來間接分析系統的穩定性。
總而言之,當前混合驅動方法的理論性研究主要呈現兩個特征。一是研究模型簡化,其主要集中于飛行器的縱平面高度速度控制或單通道姿態控制,進行多通道姿態控制時也常將角度回路和角速度回路分離處理。而此類方法在高速飛行器的應用時則需要進一步考慮通道耦合,執行機構約束等條件。二是無統一理論支撐,目前知識驅動和數據驅動方法的理論研究處于相對“割裂”的狀態,還未能有效實現混合驅動理論方法的統一和融合。當系統的復雜度進一步提升時,如何設計符合工程應用需求的可靠性、安全性理論分析模式是未來需要重點考慮的問題。
3.2 數據依賴性問題
數據的依賴性問題在混合驅動方法中依然存在。首先,當前的研究中考慮的不確定性并不全面,干擾觀測技術對于傳感器測量噪聲和風干擾產生的狀態不確定性的處理能力有限[5],數據驅動方法對此類不確定性相對敏感,在大增益下控制量易出現飽和或振蕩等影響控制品質的現象,甚至導致系統失穩。其次,高速飛行器的歷史飛行數據有限且在線數據呈現小樣本特性,僅依靠歷史數據和在線數據進行學習,在跨空域等新技術特征下存在一定的局限性。最后,數據驅動方法的參數更新律與擬合誤差或跟蹤誤差等直接相關,當高質量數據不足時,數據驅動方法的參數更新效率降低,故部分方法在學習過程中需要激勵作用或探索量以提高其收斂性,但同時兩者對于系統而言也是額外的干擾,工程應用時需充分考慮這類“探索與利用”的矛盾。
對于混合驅動方法下的數據處理和利用問題,一方面需要從機理上對各類不確定性進行分析和處理,以減少狀態不確定性對混合驅動方法的影響;另一方面可優化知識驅動方法與數據驅動方法間的不同組合形式以減小對數據的依賴,也可考慮基于模型離線產生的豐富低可信度全局數據和少量高保真歷史/在線局部數據的結合處理方式。
3.3 計算高效性問題
混合驅動方法往往具有高于知識驅動方法的算力需求,如何在當前機載算力有限的條件下處理混合驅動方法帶來的控制性能增強和算力需求提高的矛盾也需要重點關注。
針對該問題,目前主要從方法優化和硬件加速兩個方面著手。在當前姿態控制相關的研究中常使用結構較為簡單的神經網絡等模型以一定程度上減小前向計算和參數更新的計算開銷,但同時也限制了其表達能力。因此,為充分發揮數據驅動方法的優勢,一方面可在算法和模型層面開展優化,如使用增量模式對數據驅動方法的參數進行在線更新;采用自動微分(Automatic differential, AD)技術[78]用于降低基于梯度的優化問題的計算復雜度;引入事件觸發(event-triggered)機制[79]節省在線學習的計算開銷;對復雜神經網絡模型進行剪枝、量化和知識蒸餾以降低其計算功耗。另一方面則是從硬件入手,如設計高算力功耗比的通用型計算框架和專用AI處理器等等。
由于高速飛行器的特殊性,混合驅動方法的計算高效性是必須關注的問題。耗時的學習過程可離線完成,在線控制時的混合驅動方法應盡量簡潔和高效。
除了以上三類關鍵問題外,多性能指標下的代價/獎勵函數設計、充分的地面驗證方法、快時變系統條件下的學習效率等問題也需要重點考慮和研究。
4 方法展望
當前知識與數據混合驅動的控制方法雖然已在高速飛行控制領域取得了一系列成果,但大多數研究均是在一定的簡化條件和假設下完成的,與工程應用還存在一定差距。為了進一步推動該類方法的工程應用,還需充分考慮飛行器這類被控對象的特點,將離線設計/驗證與在線學習/控制過程充分結合,設計出更加高效、穩定且物理意義清晰的混合驅動方法。結合近年相關領域中基于人工智能技術產生的新成果和新思想,未來可從以下三點開展工作:
1) 數據的高效利用
從各類數據的利用上,首先可以通過數據驅動方法獲得更準確的飛行器模型參數以間接提升控制品質,如通過監督學習自動檢測已知數據的潛在不變關系以提高氣動系數的外推準確性[80]。其次可以促進基于模型產生的低可信度全局數據與高保真數據的融合,如文獻[81]提出一種線性動態導數模型與模糊神經網絡相結合的機器學習框架,能夠提升大攻角下非定常氣動參數的預測精度和效率。最后也可充分利用先驗知識提高在線學習速度和穩定性,如文獻[82]將基于名義模型產生的系統軌跡周圍的數據點作為樣本加入RL的更新律中,加快了學習速度并降低了方法對激勵信號的依賴。
2) 拓撲結構設計與優化
從拓撲結構的設計上,可以基于知識直接優化數據驅動方法的結構,將“黑箱”改進成“灰箱”,提高數據驅動方法在對應問題上的表達能力并賦予其更清晰的物理意義[83]。典型的研究如機械臂力學結構化的深度拉格朗日神經網絡實現在線逆動力學學習控制[84];基于動力學神經常微分方程(Dyna-mics neural ordinary differential equation, DyNODE)實現的特定區間長度狀態預測與RL控制[85];基于物理知識神經網絡(Physics-informed neural network, PINN)的飛行器閉環最優制導與控制[86]和最優轉移軌道設計[87]等等。對于具有變外形能力以及需考慮復雜故障的高速飛行器,當前并不能僅基于知識處理其飛行過程中復雜流場和系統耦合等產生的不確定性,可考慮探索拓撲結構更加復雜和專用性更強的混合驅動方法加以解決。
3) 安全飛行與保護
從飛行安全性考慮,除了進一步增強方法的可解釋性外,還可通過切換保護的形式優化在線學習過程。其中安全邊界可用高斯過程在內的貝葉斯類方法進行建模,基于安全邊界設計切換控制策略或獲得安全控制參數組合[88-89]。
5 結 論
高速飛行器是一類多學科交叉的復雜系統,對于其新技術特征下的控制問題,工程中常用的知識驅動方法以及人工智能領域的數據驅動方法均存在一定的局限性。本文在對兩者進行界定與分析的基礎上引出了混合驅動的思想,并對近年提出的相關控制方法進行了分類。知識與數據混合驅動的控制方法以多種組合形式使兩類方法優勢互補,是推進高速飛行器控制技術發展的重要思路。其中數據驅動部分發揮的作用呈現從無到有、比重從小到大的發展趨勢,數據驅動的調參器、補償器、模型學習器以及控制器等基于不同機理增強控制系統的魯棒性和自適應性。然而當前混合驅動方法的相關研究對實際工程問題考慮并不全面,且在理論可靠性、數據依賴性以及計算高效性等關鍵問題上還需重點討論和研究。一方面,設計控制器時需要充分考慮高速飛行器的不確定性、相關約束、容錯和安全控制等問題。另一方面,還需理論研究和應用研究并行,推動針對性出針對性更強、可靠性更高、穩定性更優的混合驅動控制技術發展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
