
基于深度學習的海面垃圾檢測系統(tǒng)
2023-10-16 19:12:26杜葉挺應澤光馬賽男卓宏明顧欣
計算技術與自動化 2023年3期
杜葉挺 應澤光 馬賽男 卓宏明 顧欣

關鍵詞:深度學習;語義分割;機器視覺;目標檢測
近年來,海洋垃圾污染問題受到國際廣泛關注,2021年第五屆聯合國環(huán)境大會旨在建立結束海洋垃圾和塑料污染的勢頭和政治意愿,從而確保一個擁有清潔海洋的未來。海洋垃圾一般指海洋和海岸環(huán)境中具有持久性的、人造的或經加工的固體廢棄物,其典型代表為漂浮在海面的塑料垃圾。根據聯合國環(huán)境規(guī)劃署(UNEP)估計,每天約8.0×106件垃圾進入海洋,每平方千米海洋表面漂浮著超過13000件塑料垃圾,另海洋保護組織Oceans Asia近日發(fā)布的研究報告表明,由于新冠肺炎疫情的暴發(fā),僅2020年至少就有16億只口罩被丟棄人海洋,它們中大部分都是一次性難降解口罩,在海洋中需要400到500年才能降解。由于這類海面漂浮垃圾的持久性和普遍性,海洋垃圾正在破壞、威脅著海洋環(huán)境,更為嚴重的是海洋垃圾已經逐漸進入食物鏈,危害到海洋生態(tài)系統(tǒng)的健康和可持續(xù)發(fā)展[2-3]。
中國大陸海岸線約1.8×104km,浙江作為海洋大省,隨著沿海工農業(yè)迅猛發(fā)展以及濱海旅游業(yè)的興起,近海海域同樣面臨巨大的海洋垃圾污染壓力。研究海洋環(huán)境污染的快速檢測手段非常有必要,在經濟發(fā)展的同時丞須解決日益嚴峻的海面漂浮垃圾污染問題。海面漂浮垃圾的檢測,容易受到海浪、倒影、海岸線等干擾因素的影響,傳統(tǒng)雷達等主動檢測方式存在精度低、無法有效識別等問題。本文提出了一種基于深度學習的海面垃圾識別檢測系統(tǒng),應用機器視覺與深度學習算法,能夠從復雜的環(huán)境中分割海面目標,實時檢測近海漂浮垃圾的區(qū)域、大小、位置等信息,并反饋給檢測中心,通過與電子海圖(ECDIS)系統(tǒng)融合,為政府海洋環(huán)境部門提供可靠有效的決策數據。
1系統(tǒng)設計與實現
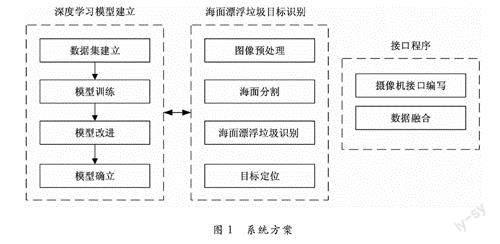
針對海面垃圾檢測應用需求,系統(tǒng)需要完成數據采集、圖像預處理、目標分割、目標檢測與定位、海圖數據融合5個功能,系統(tǒng)方案如圖1所示。數據采集依靠攝像機完成,選用海康威視監(jiān)控攝像機,提供二次開發(fā)SDK,能夠從視頻流中直接獲得圖像數據。圖像數據訓練在Ubuntu16.04版本,64位操作系統(tǒng),GTX1070,i7-8700,32G內存的電腦上完成,訓練平臺為Tensor Flow2.1,部署端在嵌入式平臺NVIDIA TX2上。
1.1海面分割
傳統(tǒng)的分割算法一般采用邊緣分割的方法,尋找到水面與岸邊特征變化劇烈的區(qū)域,然后進行邊緣檢測,最終提取出海岸線。利用圖像紋理特征和歸一化水體指數將輸入圖像分為水面和非水面區(qū)域兩類。這種方法容易受到光照、倒影等的影響,對圖像采集的環(huán)境要求較高。因此,本文針對海面分割任務需求,采用語義分割技術,可以有效劃分海面、天空、陸地、船只這些海上最常見的目標類別,從而為下一步海面垃圾的檢測識別打下基礎。
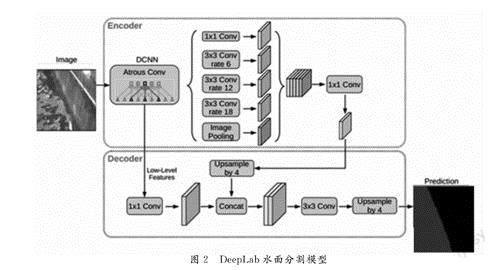
近幾年基于全卷積神經網絡的模型在語義分割任務上的成功表現,如SegNet、FCNN。有幾種變體模型提出利用上下文信息包括多尺度輸入在內做分割,也有采用概率圖模型細化分割結果。本文采用DeepLabv3+模型,通過空間金字塔模塊在輸入feature上應用多采樣率卷積、多接收野卷積或池化,探索多尺度上下文信息,同時通過En-coder-Decoder結構逐漸恢復空間信息來捕捉清晰的目標邊界。具體來說,DeepLabv3+以Deep-Labv3為encoder架構,在此基礎上添加了簡單卻有效的decoder模塊用于細化分割結果。海面分割網絡在經過大量訓練數據集訓練學習后,其泛化能力和抗干擾能力相比傳統(tǒng)的水面分割算法也更強,DeepLab模型算法結構如圖2。
通過人工采集、爬蟲、數據集增強等多種方式獲得訓練樣本,并通過Labelme標注為四大類,經過數據清理后搭建了5000余張的海上目標語義分割圖像數據庫,其中涵蓋了各類船只類型,常見的海岸場景及不同天氣下的海面情況。
DeepLab模型在經過海洋環(huán)境數據樣本的反復迭代訓練之后,逐步調整DeepLab模型中的神經網絡結構與神經網絡參數,最終得到適用于近海負載環(huán)境的語義分割模型,測試效果如圖3。圖a為原始圖像,圖b為語義分割的結果。
模型分割類別為船、海洋、天空、陸地四大語義類別。測試樣本中圖像分割的平均像素精度(PA)為81.03%,圖像分割的平均交并比(MIoU)為68.41%。
1.2海面垃圾檢測
在獲得海面目標之后,為了從海面上獲取海面垃圾漂浮物,需要進行海面垃圾的識別,海面漂浮垃圾的視覺特征通常表現為目標尺寸較小,貼近水面,分辨率較低且語義特征不完整,難以滿足傳統(tǒng)計算機視覺算法的識別要求。基于YOLOv5s深度學習模型,同時進行樣本訓練和評價,以適應實際海上檢測應用場景的需求。
YOLO(You Only Look Once)模型使用深度神經網絡對圖像位置進行快速的檢測與分類,得益于其將基于候選區(qū)域的兩階段算法改為合二為一的單階段算法,即將候選區(qū)域和對象識別進行同步,不再進行傳統(tǒng)滑移窗口操作,將輸入圖片劃分為不同區(qū)域,通過卷積生成特征圖,從而直接預測目標對象的邊界框,有效節(jié)省時間和空間成本,繼而成為現在目標檢測算法的主流選擇。
YOLOv5s網絡可以分為輸入圖像Input、Backbone主干網絡、Head檢測頭,Neck頸部網絡4部分。而這4部分由幾個不同的模塊堆疊得到,具體網絡結構如圖4所示:
1)YOLOv5s網絡輸入端主要實現Mosiac數據增強、自適應圖片縮放等功能。Mosiac數據增強能夠擴大微小對象數量,提高模型的小目標檢測效率。
2)Backbone主干網絡的主要功能為提取圖像中一系列不同尺度的特征圖,有CBS模塊、C3模塊、SPP模塊、Focus模塊。
CBS為卷積模塊,YOLOv5s主干網絡中的CBS模塊以Convolution+Batch Normalization+Activation的形式,對輸入數據進行卷積計算、批標準化計算和經過一個激活函數Silu,加快網絡的收斂速度。Silu激活函數定義為式(1),其中,Sigmoid(x)是標準的Sigmoid函數,它的值在0和1之間。
Focus模塊是對圖片進行切片操作,通過在圖片中每間隔1個像素取值,得到4張圖片,使得圖片的長和寬分別減半,通道數擴展為原來的4倍,保證了圖片信息沒有丟失,640×640×3的原始圖像通過Focus模塊,輸出得到320×320×12的特征圖。
在目標檢測中,通常輸入圖像的尺寸大小并不固定,為了得到統(tǒng)一大小的特征圖,從YOLOv3開始引入SPP空間金字塔池化模塊,通過使用CBS模塊使其通道數減半,然后將輸入的圖像經過三個不同尺寸的最大池化層,連同輸入的圖像通過concat級聯在一起,保證不同大小的輸入圖像在池化后,其特征圖長和寬能保持一致。
3)Neck頸部網絡用于進行不同大小特征圖的特征融合。對主干網絡生成的特征圖,進一步強化其特征進行提取。
4)Head用于算法的收尾階段,通過將錨框機制與特征圖數據關聯,生成目標類別、概率輸出窗口。
常見的海面目標大致可以分為礁石、海成漂浮垃圾、航道標志物等。由于現存的海面目標圖像數量稀少,因此無法遵循常見深度學習依托海量圖像數據訓練神經網絡的常規(guī)方式,需要參照小數據集訓練神經網絡的深度學習管道配置方式搭建圖像數據庫,分為島礁、海面漂浮垃圾、航道標志3類,各自收集500張圖像。樣本圖像數量分布如表1所示。
mAP值(平均準確率)常用來評價神經網絡模型的分類或物體檢測性能,主要有兩個組成參數:查準率(Precision),搜索圖像的相關性;查全率(Recall),檢索相關圖像數。代價函數用于表示模型計算結果與預測值之間的差異,是模型訓練程度的主要技術參數。本系統(tǒng)模型所得到的mAP值如表2所示,單幀處理時間可以提高到40ms,
對海面漂浮垃圾進行測試,效果如圖5所示,圖(a)為測試圖像原圖,圖(b)為語義分割后的各目標圖像,圖(C)為海面漂浮垃圾檢測后獲得目標框。
1.3海漂垃圾定位
為了定量獲得海面漂浮垃圾的位置,需要通過機器視覺的方式對海面漂浮垃圾進行定位。本文采用基于逆透視投影變換的單目測距方法,具有結構簡單、操作方便、成本低廉和信息采集迅速的優(yōu)點。單目相機目標定位原理如圖6。已知海面上目標點的三維世界坐標Zw為原點,首先通過張正友的相機標定法獲得相機的內參,并且通過GPS/北斗獲取攝像機的三維坐標,然后采用針孔透視投影模型,將待測目標的二維像素坐標轉化為三維世界坐標。
以測距望遠鏡測量結果表示實測距離,基于逆透視投影變換的單目測距結果如表3、圖7所示,從中可以看出,在一定誤差允許的情況下,單目測距效果可以滿足應用需求。
2結論
基于深度學習的海面漂浮垃圾檢測系統(tǒng),通過結合語義分割、YOLOv5s算法、單目測距技術,首先利用Labelme標注工具對海面上的目標進行分類標注,建立一個小型的數據集;針對海面小目標檢測精度不足的問題,在模型中增加小目標檢測層,修改YOLOv5的模型文件yaml,雖然增加了計算量,但對小目標檢測具有較好的改善效果,與其他檢測方法相比,其目標檢測準確率可達85%以上,能夠滿足一定的工程應用。最后通過視覺定位獲取漂浮垃圾的相對坐標,經過攝像機的經緯度位置換算,進一步獲得海面漂浮垃圾的地理絕對坐標,實現與電子海圖(ECDIS)系統(tǒng)的融合,為海洋、環(huán)境部門提可靠有效的執(zhí)行決策數據。
猜你喜歡
電腦知識與技術(2016年28期)2016-12-21 12:13:14
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
科技視界(2016年26期)2016-12-17 17:31:58
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
科教導刊(2016年25期)2016-11-15 17:53:37
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:55:22
軟件工程(2016年8期)2016-10-25 15:47:34
