fMRI 揭示日中雙語(yǔ)者的語(yǔ)義和讀音加工腦機(jī)制
2023-10-21 09:01:16李修軍劉小迪楊菁菁
李修軍,劉小迪,楊菁菁
(長(zhǎng)春理工大學(xué) 計(jì)算機(jī)科學(xué)技術(shù)學(xué)院,長(zhǎng)春 130022)
雙語(yǔ)者是指掌握兩種語(yǔ)言的人,在語(yǔ)言處理的過(guò)程中,雙語(yǔ)者通常先對(duì)詞匯進(jìn)行處理,然后再對(duì)整體句子進(jìn)行判斷。整個(gè)過(guò)程涉及正字法(文字符號(hào)的使用規(guī)則)的使用,以及對(duì)讀音(聲音)和語(yǔ)義(意思)的加工處理[1]。每種語(yǔ)言都具有其獨(dú)特的正字法,研究發(fā)現(xiàn)正字法距離(兩種語(yǔ)言之間的正字法相似性)會(huì)影響大腦神經(jīng)表征的激活模式[2-3]。具有不同正字法距離的雙語(yǔ)受試者在進(jìn)行相同的語(yǔ)義判斷時(shí),可能導(dǎo)致不同的大腦激活表征[4]。而且在實(shí)驗(yàn)過(guò)程中即使對(duì)于同一種第二外語(yǔ)(L2),兩組雙語(yǔ)者不同的母語(yǔ)(L1)正字法,也會(huì)使其表現(xiàn)出不同的激活模式[5]。雙語(yǔ)者在進(jìn)行不同的語(yǔ)言加工處理時(shí),呈現(xiàn)出的激活表征會(huì)有所不同,特別是在讀音和語(yǔ)義兩種加工任務(wù)上[6-9]。對(duì)于雙語(yǔ)者語(yǔ)言產(chǎn)生過(guò)程中的語(yǔ)義或讀音的共同神經(jīng)表征,之前的一些神經(jīng)影像學(xué)研究表明,讀音加工相關(guān)的大腦區(qū)域主要涉及梭狀回(Fusiform Gyrus,F(xiàn)FG)、顳頂葉和額下回等,語(yǔ)義加工相關(guān)的大腦區(qū)域主要分布在FFG、顳中回(Superior Temporal Gyrus,STG)、顳上回(Middle Temporal Gyrus,MTG)等[10-11]。漢語(yǔ)和日語(yǔ)盡管在日常書(shū)寫(xiě)中存在相似的正字法(字形相似),但在讀音和語(yǔ)義上卻不盡相同,這就可能導(dǎo)致大腦的不同區(qū)域被激活。
功能磁共振成像(functional Magnetic Resonance Imaging,fMRI)技術(shù)因其具有高空間分辨率和無(wú)創(chuàng)性等優(yōu)點(diǎn)被廣泛應(yīng)用于認(rèn)知科學(xué)領(lǐng)域的研究當(dāng)中,為研究者能夠更直接地分析大腦語(yǔ)言區(qū)域提供了有力途徑[12-13]。通過(guò)對(duì)fMRI 數(shù)據(jù)的統(tǒng)計(jì)分析能夠得到大腦表征的相關(guān)信息,進(jìn)而解碼大腦的語(yǔ)言機(jī)制。多體素模式分析(Multi-Voxel Pattern Analysis,MVPA)作為一種大腦解碼分析方法,可以精確地定位在每個(gè)體素上,在單變量分析的基礎(chǔ)上,能夠更準(zhǔn)確地分析出不同任務(wù)條件下的大腦活動(dòng)模式[14-15]。然而,目前使用MVPA 方法的研究大多將句子任務(wù)作為實(shí)驗(yàn)刺激[16],并且很少有人使用MVPA 研究讀音的相關(guān)大腦區(qū)域。對(duì)于使用MVPA 在詞匯任務(wù)條件下分析以及對(duì)讀音加工的相關(guān)研究都還需要更多的理論支撐,所以需要研究者在這兩個(gè)方面進(jìn)行更深層次的探討。
雙語(yǔ)者大腦加工機(jī)制的實(shí)驗(yàn)研究通常是將句子或詞匯作為實(shí)驗(yàn)刺激,想要更好地從源頭分析雙語(yǔ)者的大腦表征,詞匯任務(wù)更為合適。決策任務(wù)比簡(jiǎn)單的公開(kāi)命名任務(wù)涉及更多的認(rèn)知[17]。所以為了更好地探索大腦認(rèn)知區(qū)域,本研究對(duì)15 名以日語(yǔ)為L(zhǎng)1,漢語(yǔ)為L(zhǎng)2 的日中雙語(yǔ)受試者進(jìn)行視覺(jué)詞匯的語(yǔ)義和讀音判斷任務(wù)。使用基于一般線性模型(General Linear Model,GLM)的單變量分析簡(jiǎn)要?jiǎng)澐执竽X不同任務(wù)的不同激活區(qū)域,然后再采用MVPA 方法進(jìn)行更深層次的分析,以解碼在兩種任務(wù)條件(語(yǔ)義和讀音)下,日語(yǔ)和漢語(yǔ)在實(shí)驗(yàn)過(guò)程中產(chǎn)生的不同大腦神經(jīng)激活模式。這種對(duì)于具有特殊正字法的雙語(yǔ)者大腦加工機(jī)制的研究,不僅能夠?yàn)槿罩须p語(yǔ)者的大腦加工機(jī)制帶來(lái)新的證據(jù),還為雙語(yǔ)教學(xué)、失語(yǔ)癥患者的治療以及新型人工智能的研發(fā)帶來(lái)新的幫助與啟示。
1 材料與方法
1.1 數(shù)據(jù)收集
(1)受試者
本實(shí)驗(yàn)在沈陽(yáng)醫(yī)科大學(xué)附屬盛京醫(yī)院進(jìn)行,招募了15 名(7 名女性,8 名男性)沈陽(yáng)中國(guó)醫(yī)科大學(xué)的日本籍留學(xué)生,他們的平均年齡是22.9歲。所有受試者均以日語(yǔ)為L(zhǎng)1,漢語(yǔ)為L(zhǎng)2,且均為身體健康的右利手。受試者的具體情況如表1 所示,其中L2 熟練程度反映了第二語(yǔ)言熟練程度測(cè)試的正確率。他們?cè)谠敿?xì)了解知情同意書(shū)的情況下簽字。該研究經(jīng)中國(guó)醫(yī)科大學(xué)盛京醫(yī)院倫理委員會(huì)批準(zhǔn)。

表1 受試者個(gè)體特征
(2)數(shù)據(jù)掃描
(3)實(shí)驗(yàn)刺激
每個(gè)受試者都需要進(jìn)行日語(yǔ)和漢語(yǔ)的視覺(jué)詞匯語(yǔ)義判斷任務(wù)、讀音判斷任務(wù)和字號(hào)判斷任務(wù)。實(shí)驗(yàn)刺激包括日文漢字和中文漢字各96個(gè)詞,具體以日語(yǔ)為例,將日語(yǔ)的96 個(gè)詞打亂,每?jī)蓚€(gè)詞組成一個(gè)視覺(jué)圖片刺激。每個(gè)任務(wù)(語(yǔ)義判斷、讀音判斷和字號(hào)判斷)都由這96 個(gè)詞組成且各生成一個(gè)刺激集(S、P和O),每個(gè)刺激集包含48 張圖片(24 張正向判斷,24 張反向判斷)。
不同的詞匯刺激代表著不同的實(shí)驗(yàn)任務(wù),以漢語(yǔ)任務(wù)為例,如圖1 所示。對(duì)于語(yǔ)義詞匯判斷任務(wù),圖片包括兩個(gè)相同含義的詞(包庇和偏袒),以及兩個(gè)相反意義的詞(精華和糟粕);對(duì)于讀音詞匯判斷任務(wù),例如,成功和進(jìn)攻為讀音押韻詞匯,立刻和油膩為非讀音押韻詞匯;對(duì)于字號(hào)判斷任務(wù),判斷無(wú)意義詞匯的字符大小是否相同。

圖1 實(shí)驗(yàn)刺激
(4)實(shí)驗(yàn)過(guò)程
受試者進(jìn)行任務(wù)態(tài)(詞匯決策任務(wù))的fMRI掃描。他們需要分別進(jìn)行漢語(yǔ)和日語(yǔ)詞匯任務(wù),每種語(yǔ)言的任務(wù)分為三個(gè)會(huì)話,每個(gè)會(huì)話都包含刺激集S、P和O的16 張圖片刺激,共48 次實(shí)驗(yàn)。實(shí)驗(yàn)任務(wù)是偽隨機(jī)的,以保證每個(gè)會(huì)話中的實(shí)驗(yàn)任務(wù)的個(gè)數(shù)是相同且平衡的。
在實(shí)驗(yàn)過(guò)程中,首先會(huì)提示受試者下一個(gè)是什么判斷任務(wù),顯示4 s。每個(gè)實(shí)驗(yàn)包括兩部分,均以黑底白字的方式呈現(xiàn),第一部分是呈現(xiàn)2.5 s的詞匯刺激,兩個(gè)詞匯通過(guò)白色十字加號(hào)固視點(diǎn)并排連接;第二部分是顯示1.5 s 的固視點(diǎn),要求受試者在這個(gè)時(shí)間內(nèi)盡快按下按鈕進(jìn)行詞匯決策(圖2)。連續(xù)進(jìn)行8 次實(shí)驗(yàn)后,會(huì)有24 s 的休息時(shí)間,期間顯示固視點(diǎn)。每個(gè)會(huì)話有6 個(gè)塊大約需要6 min,每個(gè)受試者需要進(jìn)行約40 min的實(shí)驗(yàn)。
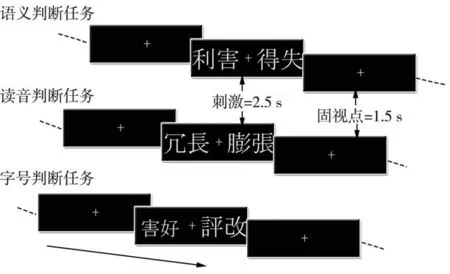
圖2 詞匯決策實(shí)驗(yàn)過(guò)程
1.2 數(shù)據(jù)分析
(1)fMRI 數(shù)據(jù)預(yù)處理
佛經(jīng)翻譯、《圣經(jīng)》翻譯、西學(xué)翻譯合作模式譯者構(gòu)成的歷時(shí)變遷為當(dāng)前中國(guó)文化經(jīng)典英譯合作模式譯者構(gòu)成建構(gòu)提供了諸多啟示。
在進(jìn)行預(yù)處理之前需要對(duì)采集到的Dicom 圖像進(jìn)行格式轉(zhuǎn)換,使用MRIconvert 軟件將其轉(zhuǎn)換成NIFTI 格式。圖像的預(yù)處理使用Matlab 軟件下的SPM12 工具箱(www.fil.ion.ucl.ac.uk)。首先,對(duì)轉(zhuǎn)換完成的圖像進(jìn)行時(shí)間切片校正和頭部運(yùn)動(dòng)校正。然后使用工具箱中提供的由蒙特利爾神經(jīng)研究所研制的標(biāo)準(zhǔn)模板(MNI)對(duì)圖像進(jìn)行空間標(biāo)準(zhǔn)化。最后,采用8 mm×8 mm×8 mm 的全寬各向同性高斯核進(jìn)行空間平滑。在執(zhí)行MVPA 時(shí)使用未平滑的數(shù)據(jù),以防止單個(gè)體素的激活不明顯。
(2)單變量分析
為了探討日中雙語(yǔ)者在進(jìn)行詞匯語(yǔ)義判斷任務(wù)、詞匯讀音判斷任務(wù)和字號(hào)判斷任務(wù)時(shí)有關(guān)語(yǔ)義和讀音的神經(jīng)表征區(qū)域,采用基于GLM的單變量分析方法對(duì)其進(jìn)行分析。三種不同的任務(wù)模式被建模為三個(gè)獨(dú)立的回歸模型,并與每個(gè)受試者的標(biāo)準(zhǔn)血流動(dòng)力學(xué)響應(yīng)函數(shù)進(jìn)行卷積。以往的經(jīng)驗(yàn)將視覺(jué)刺激通過(guò)字符特定表征轉(zhuǎn)換為整體的語(yǔ)義或讀音表征,所以這里的字號(hào)判斷是一種基線。語(yǔ)義和讀音任務(wù)與基線進(jìn)行比較,使用隨機(jī)效應(yīng)模型對(duì)受試者進(jìn)行組分析,并采用單樣本T檢驗(yàn)進(jìn)行分析。閾值設(shè)定為P<0.05(Uncorrected)和P<0.001(Uncorrected)。
(3)多體素模式分析
使用PRoNTo 工具箱(www.mlnl.cs.ucl.ac.uk)進(jìn)行多體素模式分析,研究?jī)煞N語(yǔ)言分別在語(yǔ)義和讀音上的大腦激活差異。首先,使用未平滑的fMRI 數(shù)據(jù),以單個(gè)塊為獨(dú)立事件定義GLM的設(shè)計(jì)矩陣以計(jì)算大腦活動(dòng)的激活情況。然后,基于前人的研究和單變量分析得到的結(jié)果繪制感興趣區(qū)域(Region Of Interest,ROI),使用WFUpickatlas 工具箱構(gòu)建掩碼,并在固定區(qū)域的體素中分析大腦的激活模式。再使用線性支持向量機(jī)(Linear Support Vector Machine,LSVM)分類(lèi)器對(duì)語(yǔ)義和讀音任務(wù)條件下的兩種語(yǔ)言(日語(yǔ)和漢語(yǔ))進(jìn)行分類(lèi),并使用留一法(Leave one block out)訓(xùn)練模型。最后,通過(guò)置換檢驗(yàn)來(lái)檢驗(yàn)?zāi)P偷挠行院涂煽啃浴?/p>
2 實(shí)驗(yàn)結(jié)果
2.1 行為學(xué)結(jié)果
fMRI 掃描所有受試者在執(zhí)行詞匯決策任務(wù)時(shí)的大腦,行為學(xué)分析結(jié)果如圖3 所示。


圖3 兩種語(yǔ)言的行為學(xué)分析結(jié)果
圖3中CS 為漢語(yǔ)語(yǔ)義任務(wù);JS 為日語(yǔ)語(yǔ)義任務(wù);CP 為漢語(yǔ)讀音任務(wù);JP 為日語(yǔ)讀音任務(wù);**P<0.01;***P<0.001。圖3(a)、圖3(b)分別表示語(yǔ)義和讀音任務(wù)的平均反應(yīng)時(shí)間,圖3(c)、圖3(d)分別表示語(yǔ)義和讀音任務(wù)的平均正確率。在平均反應(yīng)時(shí)間上,日語(yǔ)和漢語(yǔ)在語(yǔ)義和讀音的任務(wù)條件下均無(wú)顯著差異;而在平均正確率上,日語(yǔ)和漢語(yǔ)在語(yǔ)義和讀音任務(wù)條件下均存在顯著差異。
2.2 單變量分析結(jié)果
日語(yǔ)和漢語(yǔ)在語(yǔ)義和讀音判斷任務(wù)中激活的大腦區(qū)域如圖4 所示,其中圖4(a)、圖4(b)顯示漢語(yǔ)和日語(yǔ)在語(yǔ)義任務(wù)下的激活腦區(qū)(P<0.05,Uncorrected),選取大于5 的所有體素;圖4(c)、圖4(d)顯示漢語(yǔ)和日語(yǔ)在讀音任務(wù)下的激活腦區(qū)(P<0.001,Uncorrected),選取大于5 的所有體素。CS 為漢語(yǔ)語(yǔ)義任務(wù);CP 為漢語(yǔ)讀音任務(wù);CO 為漢語(yǔ)字號(hào)任務(wù);JS 為日語(yǔ)語(yǔ)義任務(wù);JP 為日語(yǔ)讀音任務(wù);JO 為日語(yǔ)字號(hào)任務(wù);R 為右腦。
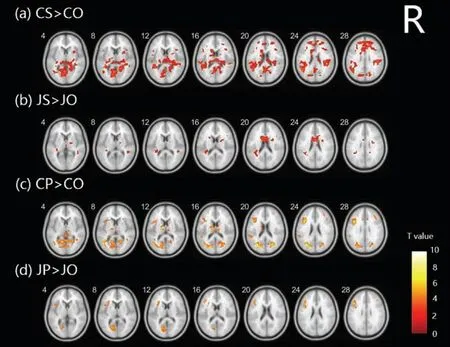
圖4 兩種語(yǔ)言在語(yǔ)義和讀音判斷任務(wù)下的大腦激活圖
漢語(yǔ)詞匯語(yǔ)義判斷任務(wù)的大腦激活涉及大量的左半球區(qū)域。包括舌回、FFG、STG、MTG、角回(Angular Gyrus,AG)、緣上回(Supramarginal Gyrus,SMG)以及部分額葉區(qū)域。右腦也有少量的激活區(qū)域。漢語(yǔ)詞匯讀音判斷任務(wù)激活的腦區(qū)包括枕葉的視覺(jué)皮層、頂葉的SMG 和中央前回,顳葉的MTG、STG 和部分區(qū)域,還有額葉的額下回三角部(Pars Triangularis,PT)和額下回島蓋部(Pars Opercularis,PO),以及扣帶皮層、輔助運(yùn)動(dòng)區(qū)等。
日語(yǔ)在語(yǔ)義和讀音任務(wù)下的激活腦區(qū)相對(duì)較少。語(yǔ)義任務(wù)的主要激活區(qū)域包括雙側(cè)顳葉部分區(qū)域、STG、扣帶回皮層和中央后回。讀音任務(wù)主要激活腦島、PO、PT、頂下緣角回、輔助運(yùn)動(dòng)區(qū)及視覺(jué)相關(guān)區(qū)域等。
圖5(a)代表漢語(yǔ)與日語(yǔ)在語(yǔ)義任務(wù)條件下的差異腦區(qū)(P<0.001,Uncorrected),圖5(b)代表漢語(yǔ)與日語(yǔ)在讀音任務(wù)條件下的差異腦區(qū)(P<0.001,Uncorrected),選取大于5 的所有體素。對(duì)于語(yǔ)義任務(wù),兩種語(yǔ)言的差異腦區(qū)包括額葉部分區(qū)域、中央前回和輔助運(yùn)動(dòng)區(qū)、頂葉的楔前葉、SMG、AG 和中央后回、顳葉的海馬區(qū)和MTG、枕葉部分區(qū)域、扣帶皮層;對(duì)于讀音任務(wù),兩者存在激活差異的區(qū)域在中央旁小葉、中央前回、枕葉的枕上回和舌回、額葉的額中回和額上回、楔前葉、頂上回、扣帶回皮層、MTG。
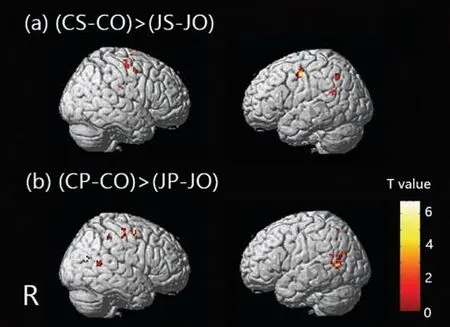
圖5 兩種語(yǔ)言在語(yǔ)義和讀音判斷任務(wù)下的差異腦區(qū)
2.3 多體素模式分析結(jié)果
結(jié)合前人對(duì)語(yǔ)義和讀音任務(wù)的討論以及單變量分析的結(jié)果,最終選取了14 個(gè)大腦經(jīng)典語(yǔ)言加工區(qū)域的ROI,包括雙側(cè)AG、SMG、FFG、PO、PT、STG 和MTG,探討14 個(gè)腦區(qū)在兩種不同任務(wù)(語(yǔ)義和讀音)條件下日語(yǔ)和漢語(yǔ)的分類(lèi)準(zhǔn)確率。通過(guò)使用單樣本T 檢驗(yàn)將每個(gè)ROI 的平均分類(lèi)準(zhǔn)確率與偶然準(zhǔn)確率(50%)進(jìn)行對(duì)比,以此判定是否成功分類(lèi)。如圖6 所示,其分別表示語(yǔ)義和讀音判斷任務(wù)的分類(lèi)準(zhǔn)確率。AG 為角回;SMG 為緣上回;FFG 為梭狀回;PO 為額下回島蓋部;PT 為額下回三角部;STG 為顳上回;MTG為顳中回;L 為左腦;R 為右腦;*P<0.05;**P<0.01;***P<0.001。

圖6 14 個(gè)ROI 在兩種任務(wù)下日語(yǔ)和漢語(yǔ)的分類(lèi)準(zhǔn)確率
在詞匯語(yǔ)義任務(wù)中,雙側(cè)AG、MTG,左側(cè)FFG、PT,右側(cè)SMG、PO 和STG 具有較高的分類(lèi)準(zhǔn)確率,這說(shuō)明兩種語(yǔ)言在右半球的激活差異更明顯。對(duì)于詞匯讀音任務(wù),在雙側(cè)AG、SMG、FFG、PO、PT、MTG 和左側(cè)STG 具有顯著的分類(lèi)準(zhǔn)確率,這表明兩種語(yǔ)言在大部分經(jīng)典語(yǔ)言區(qū)域,特別是左側(cè)SMG,具有較大的激活表征差異;而在右側(cè)STG 可能存在兩種語(yǔ)言的相似激活模式。
3 討論
本研究采用單變量分析和MVPA 兩種方法探究雙語(yǔ)者在詞匯語(yǔ)義加工和讀音加工過(guò)程中的雙語(yǔ)腦機(jī)制。
單變量分析結(jié)果發(fā)現(xiàn),日中雙語(yǔ)者在執(zhí)行兩種詞匯決策任務(wù)時(shí),表現(xiàn)出同一個(gè)激活特點(diǎn),即漢語(yǔ)加工過(guò)程中產(chǎn)生的大腦神經(jīng)激活表征區(qū)域相比日語(yǔ)加工更為廣泛,而這些區(qū)域主要集中在大腦的認(rèn)知控制區(qū)域,這一發(fā)現(xiàn)與Liu 等人[11]的研究一致。對(duì)于漢語(yǔ)讀音和語(yǔ)義任務(wù)以及日語(yǔ)讀音任務(wù),其腦區(qū)激活情況與Price[18]的研究結(jié)果一致。而日語(yǔ)語(yǔ)義任務(wù)的激活區(qū)域較少且涉及到多個(gè)右腦區(qū)域,這可能與受試者對(duì)日文漢字[19]的語(yǔ)義進(jìn)行識(shí)別有關(guān)。
受試者在觀察呈現(xiàn)出的視覺(jué)詞匯時(shí),首先通過(guò)舌回、距狀裂周?chē)拥纫曈X(jué)皮層進(jìn)行初步的加工,接著會(huì)在FFG 對(duì)詞匯進(jìn)行識(shí)別。如果是語(yǔ)義加工可能會(huì)在左側(cè)AG、左側(cè)MTG 等區(qū)域進(jìn)行語(yǔ)言信息的整合;如果是讀音加工,則可能在SMG、STG 等區(qū)域進(jìn)行詞匯的記憶提取和聽(tīng)覺(jué)轉(zhuǎn)換。接下來(lái)如果將詞匯復(fù)述,不斷地默讀詞匯,則可能激活PO、PT 等區(qū)域。
在本研究中,使用MVPA 方法對(duì)14 個(gè)腦區(qū)在兩種加工任務(wù)下漢語(yǔ)和日語(yǔ)的大腦活動(dòng)模式進(jìn)行分類(lèi),發(fā)現(xiàn)雙側(cè)AG、右側(cè)PO、右側(cè)STG 和右側(cè)MTG 在詞匯語(yǔ)義加工中具有顯著的分類(lèi)準(zhǔn)確率。這些區(qū)域在詞匯語(yǔ)義任務(wù)下表現(xiàn)出兩種語(yǔ)言不同的大腦神經(jīng)激活模式。
AG 具有分析視覺(jué)信息并將分析后的信息傳輸?shù)街袠猩窠?jīng)系統(tǒng)的能力。單變量分析結(jié)果顯示,在漢語(yǔ)語(yǔ)義任務(wù)中,左側(cè)AG 激活明顯。兩種語(yǔ)言在左側(cè)AG 的激活差異或許與雙語(yǔ)者對(duì)L1 更熟悉有關(guān)[20]。雙側(cè)AG 均參與一般視覺(jué)的語(yǔ)義加工[21],而在右側(cè)AG 體現(xiàn)出的兩種語(yǔ)言的激活差異可能與兩種語(yǔ)言表達(dá)能力的強(qiáng)弱有關(guān)。
PO 在復(fù)述或閱讀信息時(shí)非常重要。右側(cè)PO的分類(lèi)準(zhǔn)確率較高,這可能與受試者進(jìn)行不同的詞匯語(yǔ)義決策有關(guān),涉及個(gè)體的大腦變化[22]。右側(cè)STG 在記憶關(guān)聯(lián)中起著重要作用,其在語(yǔ)義判斷過(guò)程中產(chǎn)生的激活差異可能與雙語(yǔ)者兩種語(yǔ)言的不同記憶連接[23]有關(guān)。右側(cè)MTG 是命名語(yǔ)言中心,與語(yǔ)言網(wǎng)絡(luò)密切相關(guān),但這兩種語(yǔ)言之間的具體差異是難以區(qū)分的。
在詞匯讀音加工過(guò)程中,除右側(cè)STG 外,其余13 個(gè)區(qū)域均表現(xiàn)出顯著的分類(lèi)準(zhǔn)確率。特別是在左側(cè)SMG 區(qū)域,分類(lèi)精度很高。SMG 是經(jīng)典的聽(tīng)覺(jué)中樞,兩種語(yǔ)言之間發(fā)音的差異可能是分類(lèi)準(zhǔn)確率較高的原因之一。在右側(cè)STG,有研究者發(fā)現(xiàn)其是處理漢字聲調(diào)的特異性區(qū)域[24],但在這里沒(méi)有發(fā)現(xiàn)兩種語(yǔ)言激活差異的可能原因是日中雙語(yǔ)者對(duì)中文漢字的聲調(diào)存在一定的基礎(chǔ)。
盡管本研究得到了日中雙語(yǔ)者在語(yǔ)義和讀音任務(wù)條件下兩種語(yǔ)言的大腦神經(jīng)激活表征差異,并探討了產(chǎn)生這種差異的原因,但仍然存在一些不足之處。首先,在受試者的數(shù)量方面。本文選取了15 名受試者參與了本次實(shí)驗(yàn),受試者的數(shù)量較少可能會(huì)導(dǎo)致實(shí)驗(yàn)結(jié)果受到個(gè)體差異的影響較大;其次,實(shí)驗(yàn)中使用以單個(gè)塊為獨(dú)立事件定義GLM 的設(shè)計(jì)矩陣,這可能導(dǎo)致單個(gè)刺激間的體素值過(guò)于接近,進(jìn)而造成分類(lèi)誤差。所以在未來(lái)的研究當(dāng)中,需要對(duì)實(shí)驗(yàn)進(jìn)行改進(jìn),選取更多的受試者參與實(shí)驗(yàn),并以單個(gè)刺激為獨(dú)立事件定義GLM 設(shè)計(jì)矩陣,完成兩種語(yǔ)言大腦活動(dòng)模式的分類(lèi)。
4 結(jié)論
綜上所述,本研究利用單變量分析和MVPA方法探索日中雙語(yǔ)者的大腦機(jī)制,發(fā)現(xiàn)兩種語(yǔ)言在共同語(yǔ)言處理區(qū)域的激活存在明顯差異以及共同點(diǎn)。結(jié)果表明,無(wú)論是在詞匯語(yǔ)義還是讀音加工任務(wù)條件下,相比于L1、L2 的激活表征更廣泛,涉及大腦的認(rèn)知控制區(qū)域。日語(yǔ)和漢語(yǔ)的詞匯語(yǔ)義加工在雙側(cè)AG、右側(cè)PO、MTG 和STG 的激活上存在較大差異,且右腦的激活差異更為明顯。在詞匯讀音加工中,兩種語(yǔ)言在13個(gè)ROI 中的分類(lèi)準(zhǔn)確率均相對(duì)較高,其中左側(cè)SMG 的差異更明顯,而在右側(cè)STG 可能存在兩種語(yǔ)言共同的神經(jīng)表征區(qū)域。這些結(jié)果為進(jìn)一步理解雙語(yǔ)者的大腦機(jī)制提供了證據(jù),并為雙語(yǔ)教學(xué)、失語(yǔ)癥患者的治療以及新型人工智能技術(shù)的發(fā)展帶來(lái)了新的啟示。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
中國(guó)科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
電測(cè)與儀表(2015年5期)2015-04-09 11:30:52
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
