改進DBNet的電商圖像文字檢測算法研究
2023-11-17 13:15:26李卓璇周亞同
計算機工程與科學 2023年11期
李卓璇,周亞同
(河北工業大學電子信息工程學院,天津 300401)
1 引言
近年來,電商平臺的出現極大地滿足了人們的消費需求[1]。但與此同時,很多不法分子將敏感信息放入商戶的宣傳圖像中進行傳播,給電商平臺的監管帶來了極大的困擾。因此,如何對種類繁多、數量龐大的商品圖像進行高效的合法性驗證成為了當前的熱點問題[2]。采用文字識別技術對商品的宣傳圖像進行檢測與識別,再將識別到的文字進行語義分析可有效地對圖像進行篩選驗證。
目前,圖像中文字的檢測方法可以分為2大類:基于人為選擇特征的傳統文字檢測法[3]和基于深度學習的文字檢測法[4]。基于人為選擇特征的文字檢測法又可以分為3類:滑動窗口法[5]、連通成分分析法[6]和混合方法[7]。滑動窗口法通常使用多尺度滑動窗口在圖像上掃描來獲得文字候選區域,隨后使用分類器判斷候選區域是否包含文字區域。連通成分分析法會根據像素點在空間上的近鄰性和像素點在顏色、紋理等方面的相似性過濾大部分背景像素,隨后將字符中的像素聚合為連通成分進行過濾,接著依據規則對候選連通成分進行過濾,得到文本位置。混合方法在充分吸收了上述2類方法的優點后,能夠更精確地檢測文字。傳統的文字檢測法存在人為選擇特征在區分背景與目標文字特征時檢測能力不強、分類器應對復雜背景檢測效果不佳等問題。
隨著深度學習的蓬勃發展,研究人員嘗試使用深度學習來解決傳統文字檢測法中遇到的問題[8]。在早期的嘗試中,Huang等[9]將連通區域法和滑動窗口法結合起來提取文字候選區域,并使用卷積神經網絡CNN(Convolutional Neural Network)提取更高層的特征完成文字區域檢測,其本質上是對局部的圖像斑塊進行特征挖掘并完成分類任務。后來,CNN網絡被逐漸用于檢測整個圖像。Fast R-CNN(Fast Region-CNN)[10]、Faster R-CNN[11]、SSD(Single Shot multibox Detector)[12]等對文字的檢測效果都比較理想。Tian等[13]充分考慮了文本檢測的難點——文本行的長度不固定,提出了CTPN(Connectionist Text Proposal Network),該網絡使用較深的VGG(Visual Geometry Group)模型提取特征,同時開發了垂直錨點機制,預測固定寬度的小文本候選框,大幅提升了檢測的精度。Ma等[14]沿用了Faster R-CNN檢測候選區域的思想,提出了RRPN(Rotation Region Proposal Network),該網絡可以生成帶旋轉角的候選區域,通過旋轉的矩形框可以標記任意方向的文本。Liu等[15]提出了一個可訓練、端到端的多方向文本檢測識別算法FOTS(Fast Oriented Text Spotting),在檢測與識別任務中共享了卷積特征層。Liao等[16]基于SSD提出了TextBoxes網絡,設計了多個不同比例的候選框并為每個候選框添加了垂直偏移量,但是該網絡僅能檢測水平方向的文字。為此,文獻[17]做出了進一步改進,提出了TextBoxes++網絡,該網絡在SSD網絡的輸出層后面通過預測回歸,以四邊形或傾斜的矩形來框出任意方向的文本。
雖然上述部分模型已經在一般文字檢測領域表現出良好的性能,但是在場景文字檢測領域的效果不佳,尤其是在電商宣傳文字檢測方面。這主要是由于電商圖像背景復雜,且存在文字不規則、文字排列方向多變的現象。而曲折的文本排列難以使用矩形框覆蓋。由此可見,使用預設形狀的候選框無法很好地描述某些特殊形狀的文本。相比之下,基于分割的文字檢測法從像素層面進行分類,判別每一個像素點是否屬于某一個文本目標以及它與周圍像素的關系,最后將相鄰像素聚合為一個文本框。此方法可以適應任意角度和形狀的文本[18]。
針對電商宣傳圖像中存在的背景復雜、文字排列方向多變等問題,本文選擇了基于分割的文字檢測法,以DBNet(Differentiable Binarization Network)[19]作為基礎模型,可以處理包括橫向、縱向和卷曲排列的任意方向文字,即使使用輕量級的主干網絡,檢測性能也十分優秀。為了使特征金字塔能夠更好地對不同尺度的特征圖進行特征融合,本文提出了更為復雜的特征融合機制,能夠有效融合高層次和低層次的信息。此外,為了使網絡能夠更加關注圖像中的關鍵區域,引入了SimAM(Simple Attention Module)注意力模塊,最后添加了雙邊上采樣模塊來提高可微分二值化DB(Differenti- able Binarization)模塊的自適應性能。本文的主要工作如下:
(1)提出了一個迭代的自選擇特征融合模塊,該模塊可以更好地融合語義和尺度不一致的特征,同時提取具有代表性的局部信息。
(2)引入了SimAM注意力模塊,該模塊能夠為特征圖推導出3D注意力權值且無需額外參數,同時還關注了通道和空間注意力,提高了模型對關鍵區域的聚焦程度。
(3)為了進一步優化二值化過程的自適應性能,降低復雜背景對文字檢測的干擾,引入了雙邊上采樣模塊來提取易于被誤判的背景特征,通過二值化計算來更精確地檢測文字位置。
2 DBNet模型原理
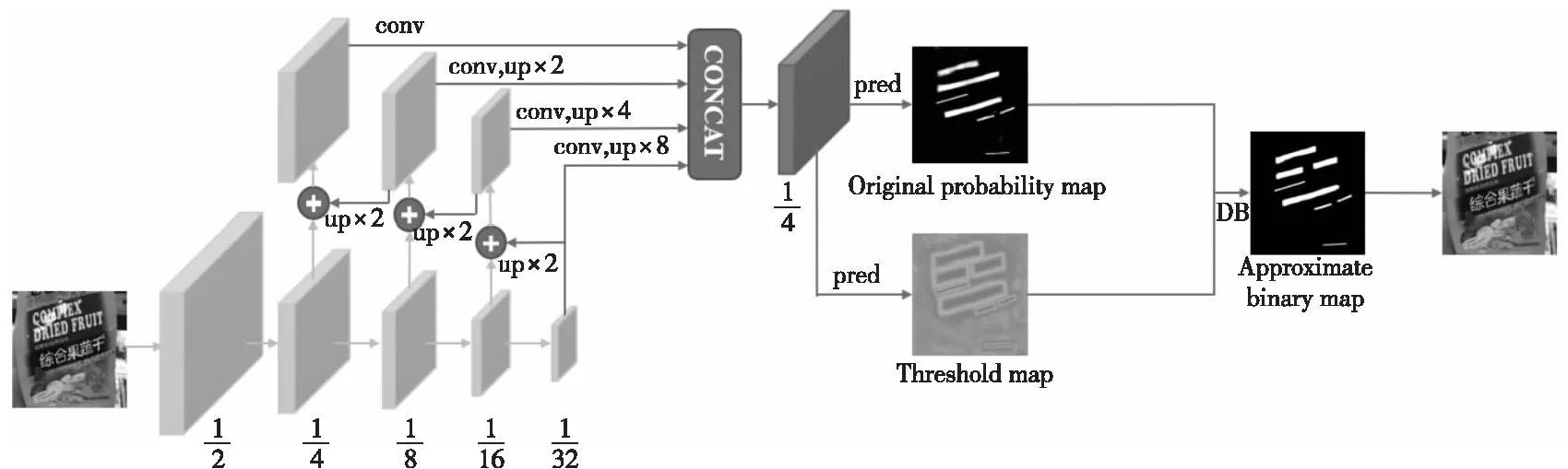
Figure 1 Structure of DBNet圖1 DBNet結構
DBNet結構如圖1所示,輸入圖像經ResNet提取特征后會獲得不同層次的特征圖,為了充分利用低層特征的高分辨率和高層特征的高語義信息,將特征圖送入到特征金字塔網絡FPN(Feature Pyramid Network)[20]中進行特征融合。使用融合后的特征圖預測概率圖(Probability Map)和閾值圖(Threshold Map),最后利用概率圖和閾值圖計算近似二元映射。在訓練階段,對概率圖、閾值圖和近似二進制圖進行監督。在推理階段,從近似二元映射或概率映射中獲得文本框,完成文字檢測任務。
2.1 FPN結構
CNN網絡[21]已被證明可以將大量的參數降維成少量參數后再進行處理,其使用類似視覺機制保留了圖像的特征。即使對圖像進行翻轉、旋轉或變換位置等操作,CNN網絡也可以進行有效識別。深度神經殘差網絡ResNet(Deep Residual Network)成功解決了網絡“退化”問題,使得更深層次網絡的訓練變得可行。
常規的FPN結構一般采用特征圖相加的方式對不同層次的特征圖進行融合。不同尺度的特征圖經上采樣后與經過1×1卷積降維后的特征圖相加,這種方法雖然增強了目標特征信息,但同時也引入了背景的特征信息。在DBNet網絡中,還將4組不同尺度的特征圖上采樣至相同尺度并進行特征級聯,這種原始特征直接拼接的方式是為了讓網絡學習到如何進行特征融合,避免出現信息損失。
2.2 可微分二值化結構
基于分割的文字檢測法后處理過程,通常都是設定固定的閾值將分割模型得到的概率圖轉化為二值化圖,標準的二值化式如式(1)所示:
(1)
其中,P是概率圖,(i,j)是圖中的像素坐標,th是固定的閾值,B為輸出的二值圖。
傳統的二值化方法設置一個閾值th,大于這個閾值則判定為目標區域,概率值為1,代表像素為正樣本即屬于文字區域,否則為背景區域。傳統的二值化函數曲線實際上是一個不可微的階躍信號,這使分割算法無法在訓練過程中優化。研究人員針對這個問題提出了一個DB(Differentiable Binarization)模塊,實現了可微分二值化。具體來說,是使用近似階躍函數執行二值化,如式(2)所示:
(2)

DBNet文字檢測算法的損失函數由概率映射損失Ls、二進制映射損失Lb和閾值映射損失Lt加權求和取得,如式(3)所示:
L=Ls+α×Lb+β×Lt
(3)
其中,α和β分別設置為1.0和10;Ls與Lb都應用了二進制交叉熵損失,具體如式(4)所示:
(4)
其中,Sl表示正樣本與負樣本比例為1∶3的被采樣的數據集,xi表示預測為文字區域的概率值,yi則表示實際的標簽值。
閾值圖的損失Lt采用平均絕對誤差損失,其計算如式(5)所示:
(5)
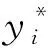
實際上,在模型的訓練過程中會對概率圖、近似二值圖和閾值圖進行監督,其中概率圖和近似二值圖共享相同的監督。而在模型預測過程中,可以從概率圖預測獲得邊界框。
3 改進iSFF-DBNet模型
電商宣傳圖像背景復雜,內部的文字方向具有任意性,且字體多變。即使經過FPN特征融合,特征圖中仍然存在大量誤判的背景特征,在應用到文字檢測任務時會導致產生大量的漏檢和誤檢。針對上述問題,為進一步增強模型對局部特征的提取能力,本文進行了如下改進:(1)引入注意力模塊SimAM[22]關注文字區域;(2)為了幫助模型有選擇性地融合不同尺度特征圖的顯著區域,提出迭代自選擇特征融合模塊iSFF(iterative Selective Feature Fusion);(3)為消除概率圖中與文字特征近似的非文字特征區域,使用雙邊采樣器提取特征并計算新的概率圖,稱之為迭代自選擇特征融合DBNet 模型iSFF-DBNet,其結構如圖2所示。

Figure 2 Structure of iSFF-DBNet圖2 iSFF-DBNet結構
3.1 SimAM注意力模塊
為了使模型能夠捕獲更多文字相關特征并抑制背景特征,本文引入了注意力模塊SimAM。現有的注意力模塊普遍存在2個問題:一個是只能沿空間或通道維度細化特征,限制了它們學習跨空間和跨通道變化的注意力權重的能力;另一個是結構過于復雜,給模型增加了極大的運算量。
SimAM是一個具有完整三維權重的注意力模塊。不同于現有的通道、空間注意力模塊,該模塊無需額外參數即可直接在網絡層中推理出三維的注意力權重。具體來說,SimAM模塊能夠同時考慮空間和通道維度并細化這些神經元。SimAM模塊的另一個優點在于大部分操作均基于已定義的能量函數,避免了過多的結構調整。模塊的推理過程如圖3所示,其中,H、W和C分別表示特征圖高度、寬度和通道數,不同灰度填充的多邊形代表特征圖中不同通道和空間位置的元素。
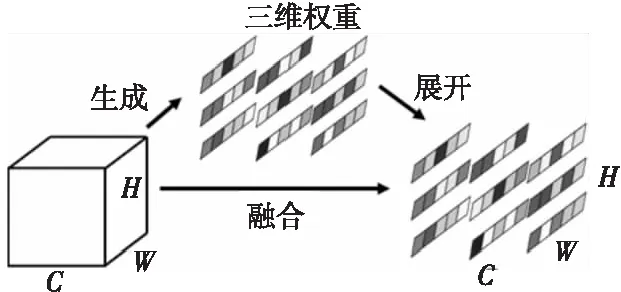
Figure 3 Process of attention ratiocinate圖3 注意力推理過程
具體來講,通過測量目標元素和其他元素之間的線性可分性,可挖掘出特征向量中每個元素的重要性。為每一個神經元定義的能量函數如式(6)所示:
(6)
其中,t表示輸入特征圖上的目標神經元編號,xi表示特征圖上的其它神經元,wt和bt分別表示上述神經元進行線性變換時的權重和偏移值,M表示特征圖上所有元素的個數。理論中,激活神經元通常會抑制周圍神經元,換句話說,具有抑制效應的神經元應當賦予更高的重要性。因此,能量越低,神經元t與周圍神經元的區別越大,重要性越高。
3.2 迭代的選擇性特征融合模塊
DBNet網絡對4個不同層次的特征圖進行了拼接操作,以融合不同尺度的特征。CONCAT層以原始特征圖直接拼接方式,讓網絡去學習如何融合特征。但是,不同層次的特征圖所包含的有用信息不同,為此本文提出了一種選擇性特征融合SFF(Selective Feature Fusion)模塊,可以通過獲得每個特征圖信息的權重,自適應地選擇和集成不同模塊的局部和全局特征。為了解決初始輸入特征問題,本文進一步提出了迭代自選擇特征融合模塊iSFF。
SFF模塊結構如圖4所示。首先,將4個不同層次的特征圖上采樣至相同的維度,接著將這些特征按通道維度連接,并通過2個3×3的Conv、BatchNorm和ReLU層以達到降維目的并進一步提取特征。特征圖經過Sigmoid函數輸出值為0/1,相當于獲得特征圖信息的權重。最后的卷積層和Sigmoid層用于生成一個4通道權重矩陣,將不同層次的特征圖與對應的各個通道逐元素相乘,以聚焦于重要位置。然后,將這些相乘的特征按元素相加,構建出混合特征圖。
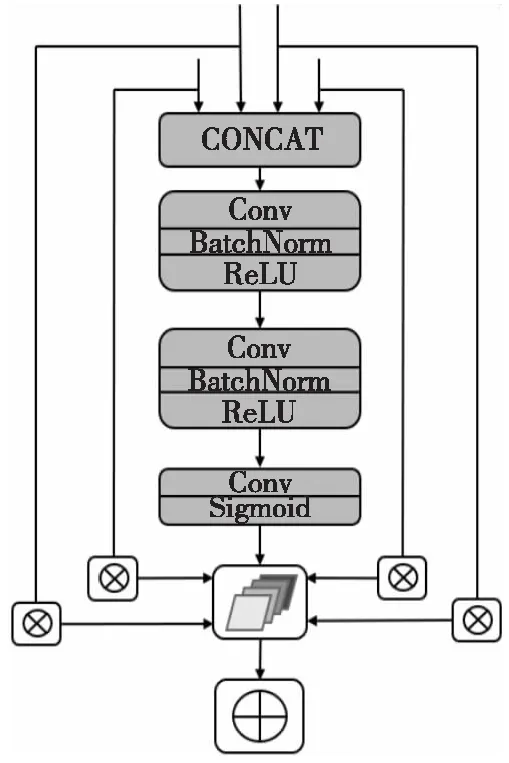
Figure 4 Schematic diagram of selective feature fusion圖4 選擇性特征融合示意圖
實際上,選擇性特征融合模塊有一個不可避免的問題,即如何集成初始的輸入特征。模塊中以CONCAT的方式提供初始的輸入特征,但這些特征在規模和語義上可能存在很大的不一致性,從而對權重融合的質量產生很大的影響,使得模型表現受限。實際上這仍然是一個特征融合問題,一種直觀的方法是使用另一個選擇性特征融合模塊來融合輸入特征。這種2階段的方法被稱為迭代自選擇特征融合模塊,其結構示意圖如圖5所示,其中,E、F、G和H分別表示輸入特征圖,Z表示輸出特征圖。2個不同層次的特征圖先經過一個SFF模塊,各個特征圖與對應的權重通道相乘后加在一起,集成了初始的輸入特征,之后再進行一次選擇性特征融合,得到更優的模型結果。
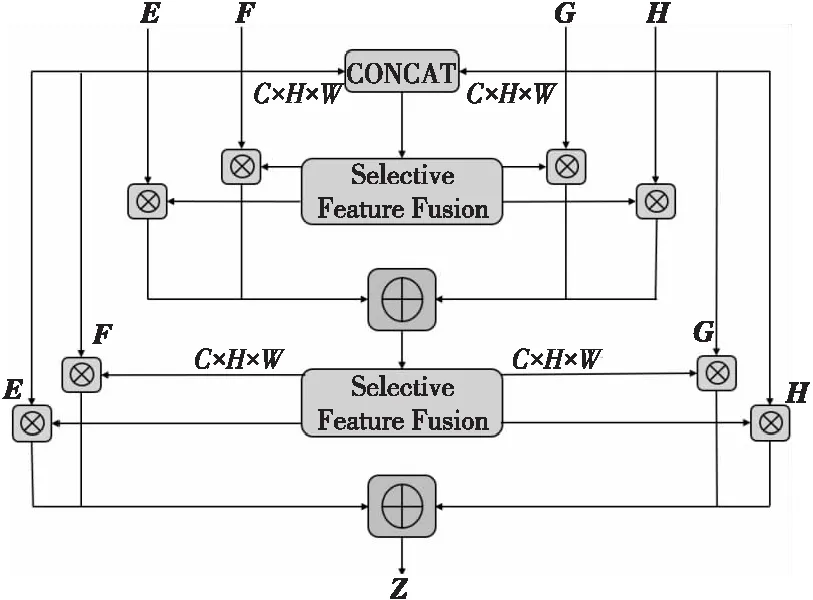
Figure 5 Iterative selective feature fusion圖5 迭代自選擇特征融合
3.3 雙邊上采樣模塊
對于背景簡單的電商宣傳圖像,DBNet模型的檢測效果非常理想。但是,在某些背景復雜的電商宣傳圖像中,即使引入了特征融合模塊抑制背景特征,還是會出現“誤檢”情況。為了進一步優化二值化過程的自適應性能,本文在DB模塊中添加雙邊上采樣(Bilateral up-sampling)模塊來提供穩定的二值化映射。
大多數解碼器利用雙線性上采樣過程來恢復最終的像素級預測,但此時獲得的預測圖往往是粗略的結果,通常會丟失一些細節。雙邊上采樣模塊由2個分支組成:一個用來恢復粗粒度特征,另一個用來修復精細的細節丟失特征。其結構如圖6所示,特征融合模塊的輸出通過2個分支,最終生成的特征圖將恢復到與輸入圖像相同的大小。
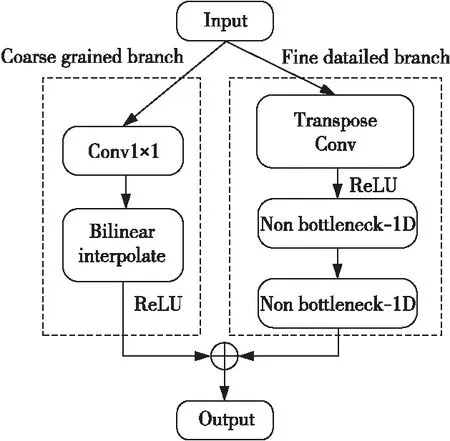
Figure 6 Bilateral up-sampling圖6 雙邊上采樣
在粗粒度分支(Coarse grained branch)中,快速輸出最后一層的粗采樣特征,但是這可能會導致其忽略細節特征。在這條路徑中,首先通過卷積核為1×1的卷積層減少輸入特征圖的通道數,隨后使用雙線性插值法對輸入特征圖進行上采樣,最后經過ReLU函數。
而在精細細節分支(Fine detailed branch)中,會微調輸入數據中的細微信息。在這條路徑中,使用轉置卷積對特征圖進行上采樣的同時減少通道數。在上采樣完成以后堆疊了2個非瓶頸模塊(Non-bottleneck-1D block)對特征進行精細提取,它由4個3×1和1×3的卷積、ReLU函數、BN函數組成。其不僅可以保持特征圖的形狀,同時還以因式分解的方式高效地提取特征。
在近似二值化映射的計算中,概率圖中會存在較少的背景特征最終被判斷為文字區域,相較于概率圖中被正確判斷為文字的區域,這些背景特征區域在概率圖中都表現地相對較小且較為灰暗,這也側面印證了雖然被誤判為文字區域,但是背景區域學習到的特征并不充足。為了降低誤檢的概率,本文提出了新的近似二值化映射,如式(7)所示:
(7)
其中Bi,j為雙邊映射,它會與概率映射Pi,j計算一起生成新的概率圖。事實上,雙邊映射偏移了概率值,其主要是修改文本和非文本區域中被判定為文字區域的分數。在新的概率映射中,文字區域仍然可以被正確地識別,但是被“誤判”的背景區域已經消失不見。新概率映射如式(8)所示:
P′i,j=Pi,j-Bi,j,0≤Bi,j≤0.2
(8)
模型可以充分提取文字區域的特征,所以實際上式(2)中Pi,j-Ti,j對文字區域值的變化并不敏感,此時通過Bi,j偏移Pi,j,并不會對最終文字區域的檢測結果有較大影響。結果表明,雙邊上采樣模塊側重于非文本區域分數的負偏移。訓練過程中,在損失函數的約束下,雙邊上采樣模塊將抑制非文本區域的分數。
4 文字檢測實驗設置
4.1 實驗環境
本文實驗基于PyTorch深度學習框架,以Python 3.7作為編程語言。本地計算機的基本配置如下:Intel?CoreTMi7-10870H的處理器,頻率為2.20 GHz的CPU,內存為8 GB,NVIDIA?GeForce?RTXTM3060 的GPU,顯存為4 GB,操作系統為Windows 10。
4.2 數據集
為了驗證本文所提出的改進模型的有效性,采用ICPR MTWI 2018(International Conference on Pattern Recognition Multi-Type Web Image 2018)網絡圖像數據集進行實驗。該數據集是由華南理工大學聯合阿里巴巴共同收集和標注的淘寶商品類圖像,其關注的是多方向文字的檢測問題。數據集圖像主要包括中文和英文文本,少量圖像中包含韓文和日文文本。如圖7所示,該數據集的特點是所包含的文字在字號、字體、排版上均有較大變化,且背景復雜、顏色多變。文本區域的標注是以文本間的間隔進行劃分的,圖像中文本之間間隔大于一定的閾值即劃分為不同的文本區域。本文將10 000幅含有標注的圖像以8∶1∶1的比例隨機劃分為訓練集、驗證集和測試集。為了加速訓練過程,訓練樣本大小均調整為640×640。

Figure 7 Samples of ICPR MTWI 2018 network image dataset圖7 ICPR MTWI 2018 網絡圖像數據集示例
4.3 參數設置
本文算法選用自適應矩估計(Adaptive Moment Estimation)優化器進行訓練,該優化器具有運算高效、所需內存少等優點。此外,實驗中使用指數變換的學習率衰減策略,其表達式如式(9)所示:
(9)
其中,base_lr為初始的學習率,epoch為當前迭代次數,num_epoch為最大迭代次數,power控制著曲線的形狀。實驗中將初始學習率設為0.007,最大迭代次數設為150,power設為0.9。此外,將批量處理大小設為8。指數衰減學習率的優點在于可以先使用較大的學習率,加快模型的訓練速度,然后逐步減小學習率,使模型在訓練后期逐漸穩定。
5 實驗與結果分析
5.1 算法評估標準
文字檢測算法一般以召回率(Recall)、精確率(Precision)以及調和平均數(F1-score)作為評價指標。精確率是指文本區域的預測結果正確預測所占的比例。召回率是指所有標注的文本區域被檢測出來的比例。兩者的計算公式分別如式(10)和式(11)所示:
(10)
(11)
其中,TP表示實例為正例且預測結果為正例的樣本數;TN表示實例為負例且預測結果為負例的樣本數;FP表示實例為負例但預測結果為正例的樣本數;FN表示實例為正例但預測結果為負例的樣本數。
為了綜合評估算法的好壞,避免僅局限于其中一種指標,本文還以調和平均數作為文本檢測算法的綜合指標,該指標越高,代表算法越好,其計算公式如式(12)所示:
(12)
5.2 消融實驗
為了驗證本文算法中各組分模塊對性能的影響,本節在ICPR MTWI 2018數據集上進行了消融實驗,結果如表1所示。本文將DBNet模型作為基礎模型,隨后將SimAM模塊、自選擇特征融合模塊(SFF)、迭代的自選擇特征融合模塊(iSFF)和雙邊上采樣模塊(BU-S)分別添加到基礎模型中。本文選擇Precision、Recall、F1_score、參數量和FLOPs(表示浮點計算數)作為算法的評價指標。

Table 1 Results of ablation experiment表1 消融實驗結果 %
從表1可以看出,SimAM模塊使模型的精確率提高了1.7%;iSFF模塊在召回率和綜合指標F1_score上相比較于SFF模塊取得了更好的效果,驗證了初始特征的輸入確實會對最終的融合權重有較大的影響;BU-S模塊使模型的召回率提升了3.3%,表明優化可微分二值化結構可以降低文字區域的漏檢情況。雖然在添加iSFF與BU-S模塊后Precision沒有提升,但這并不代表模塊在精度提升方面沒有作用。可能的原因之一是在特征提取能力增強以后,很多小的文字被檢測出來,但是這些小文字因為過小并沒有被記錄在數據集標簽當中,從而導致了Precision的下降。
為分析各種改進對模型的影響,設計了消融實驗,結果如表2所示。添加的SimAM模塊對模型的參數量和計算量基本沒有影響,同時還可以使模型的綜合指標略有上升。在特征提取部分添加的iSFF模塊使得模型的計算量增加了11%,但是該模塊可以使模型的召回率與精確率達到平衡,在僅添加少量參數的情況下使得模型的穩定性有了顯著提升。BU-S模塊在計算量與參數量上都沒有明顯變化,但是其對模型的召回率提升是最為明顯的。改進后的DBNet模型雖然在檢測速度上略有降低,但是其檢測效果與原始DBNet模型相比有了較為明顯的提升。

Table 2 Comparison of complexity表2 復雜度對比
5.3 實驗結果對比與分析
5.3.1 引入注意力模塊SimAM檢測結果對比
為了驗證注意力模塊SimAM對文字檢測能力的提升,在僅加入SimAM的情況下對基礎模型DBNet進行檢測,檢測結果如圖8所示。在引入SimAM模塊后,圖像右側腿部方框中預測錯誤的文字區域明顯減少,同時左上角相鄰的單詞也被完整預測。實驗結果表明,注意力模塊SimAM可以增強模型對文字區域的關注程度。

Figure 8 Comparison of detection results before and after adding SimAM圖8 引入SimAM前后檢測結果對比
5.3.2 引入迭代自選擇特征融合模塊檢測結果對比
引入迭代自選擇特征融合(iSFF)模塊,可以提升模型對于文字特征的提取能力,同時抑制背景特征對檢測的影響,使得模型檢測復雜背景圖像的能力大幅增強。在引入iSFF模塊后,不同尺度的特征圖輸入iSFF模塊進行特征融合,融合后的結果用于預測概率圖與閾值圖,可以從預測的概率圖中直觀地感受到iSFF模塊對檢測結果的影響,如圖9所示。

Figure 9 Probability map comparison before and after adding iSFF圖9 引入iSFF前后概率圖對比
引入iSFF模塊以后,概率圖中部分背景區域被預測為文字區域的概率值明顯下降。最終檢測結果如圖10所示。在輸入圖像中,手套上的皺紋結構與“三”“川”等文字結構十分相似,所以在預測階段,模型十分容易出現誤判現象,如圖10a中,在圖像中心被方框標記的手套區域上有大量細長的文字框,這些都是被誤檢的區域。引入特征融合結構后,模型有了一定的抑制背景特征能力,如圖10b 中,手套區域上的文字誤檢框已經基本消失。這表明當遇到復雜背景時,改進后的模型能夠充分提取文字特征,更精確地完成檢測任務。同時,這些誤檢文字框的消除可以提升Precision值,也就是說雖然在消融實驗中添加iSFF模塊使得Precision下降,但是模塊并非對精度的提升沒有作用。

Figure 10 Comparison of detection results before and after adding iSFF圖10 引入iSFF前后檢測效果對比
5.3.3 引入雙邊上采樣模塊檢測結果對比
在近似二值化映射的計算中,概率圖中會存在較少的背景特征最終被判斷為文字區域。為了盡可能消除背景區域特征影響,本文引入了雙邊采樣模塊偏移背景區域概率值,概率圖前后的變化如圖11所示。從圖11可以看到,在原模型的概率映射中有少量較暗淡的白色區域,這些是被誤判為文字的背景區域,與其它背景區域相比,誤判區域有著與文字類似的特征,但是其“概率”相較于真正的“文字區域”的又比較小,因此顯示得較為暗淡,但這些區域在檢測過程中仍然會對檢測結果產生影響。而在雙邊上采樣模塊偏移了非文本區域的概率值以后,圖像的檢測結果更為精準,如圖12所示。在圖12a中,圖像的左上角以及中間部分的背景區域中均有被誤檢的情況,而在引入了雙邊上采樣模塊以后,僅僅只檢測出了應被正確檢測的文字區域,檢測效果更佳。

Figure 11 Probability map comparison before and after adding BU-S圖11 引入BU-S前后概率圖對比

Figure 12 Comparison of detection results before and after adding BU-S圖12 引入BU-S前后檢測效果對比
5.4 對比實驗
為了進一步驗證本文算法的有效性,本節在ICPR MTWI 2018數據集上將其與其它文字檢測算法進行了對比,實驗結果如表3所示。CTPN是復雜場景文字檢測的經典模型,它使用垂直錨框回歸機制,檢測小尺度的文本候選框,然后將屬于同一個標注文本框的小文本框連接成一個文本框區域,形成候選區域,最后對每個候選區域的大小進行微調。但是,CTPN對于非水平文本的檢測效果并不好,實驗結果表明,CTPN在3個評價指標上都表現得不盡如人意。而高效準確場景文本檢測器EAST(Efficient and Accurate Scene Text detector)利用一個全連接模型直接預測單詞或文本行。事實上,EAST和DBNet一樣,都利用了分割思想來完成文字檢測任務,但在實驗中,EAST的召回率偏低,僅有59.2%,表明部分文字區域未能被有效檢測到。下面2篇文獻都使用了ICPR MWTI 2018作為數據集,將10 000幅圖像以8∶1∶1的比例劃分為訓練集、驗證集和測試集,與本文的數據集選用相同。文獻[23]應用了推選出“文字區域候選框”的思想,并在第2階段進行邊框精細化處理,采用實例分割的思想分割出文本框。文獻[24]則提出了一個單元組合的自下而上的文本檢測框架,利用不同的卷積核提取對應的輸出,確定不同文本間的互斥關系,通過閾值確定有效的文字單元之間的聯系,最后從每組文字單元提取文字區域的外接檢測框。該模型相較于之前的模型大幅提升了檢測性能,召回率能夠達到69.7%。
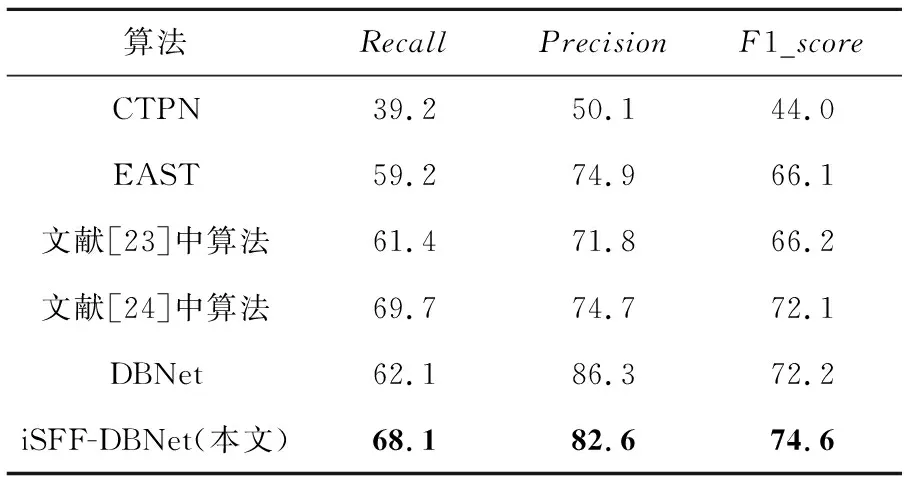
Table 3 Experimental results of different detection algorithms表3 不同檢測算法的實驗結果 %
原DBNet模型相較于其他模型,在精確率方面有著較大的優勢,但是在召回率方面卻不盡人意,這主要是由于ICPR MTWI 2018數據集中圖像背景過于復雜,部分文本區域未被成功地檢測出來。而本文提出的改進模型相比于原DBNet模型雖然精確率方面有所下降,但是在召回率上有6.0%的提升,同時F1_score也有著2.4%的提升,表明改進后的網絡模型更加穩定,在精確率和召回率上取得了平衡。本文算法在保證擁有較高精確率的同時大幅提升召回率,檢測效果明顯優于其它文字檢測算法的,同時在面對復雜的背景時,本文算法也更具競爭力。
6 結束語
本文針對復雜背景的電商圖像文字檢測提出了一種新算法。該算法以DBNet模型為基礎,通過改進FPN網絡中的特征融合模塊,自適應地選擇和集成局部和全局特征。此外,添加了注意力模塊使模型重點關注特征明顯的區域。同時,還在可微分二值化模塊中引入了雙邊上采樣模塊來降低復雜背景對文字區域檢測的影響。實驗結果表明,本文所提算法取得了68.1%的召回率、82.6%的精確率和74.6%的F1_score,優于其它算法。基于該算法,可以高效地對種類繁多、數量龐大的商品圖像進行合法性驗證。在接下來的工作中,將重點對可微分二值化模塊進行處理,研究如何盡可能多地將圖像中的文本區域檢測出來,以進一步提高算法的檢測能力。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
小學教學參考(2015年20期)2016-01-15 08:44:38
電測與儀表(2015年5期)2015-04-09 11:30:52
語文知識(2014年1期)2014-02-28 21:59:13
