基于醫院電子病歷數據構建風險預測模型的研究進展*
2023-11-24 10:51:40許來雨彭伶麗周芳意
現代醫院管理 2023年5期
許來雨,彭伶麗,周芳意
(中南大學湘雅醫院臨床護理學教研室,長沙市 410008)
電子病歷是一種醫學專用軟件,由一系列個人健康資料組成[1],包括文字、符號、圖標、數據以及影像等醫療服務工作記錄[2]。隨著網絡技術和信息技術的發展,電子病歷系統順應醫院計算機網絡化管理的發展趨勢,被廣泛應用。2017年12月,國家衛健委指出醫療機構應加強以門診及住院病歷為核心的綜合信息系統建設,利用大數據信息技術為醫療質量控制、規范診療行為、調配醫療資源等提供支撐[3]。基于電子病歷系統的風險預測模型是臨床決策支持系統的基礎,可以針對給定的一組患者特征快速計算其發生某種結局的風險[4],幫助醫護人員及時發現病情變化,采取針對性措施,改善患者結局[5]。筆者從使用電子病歷構建風險預測模型的研究設計、優勢及不足三個方面進行綜述,為未來醫療領域風險預測模型的構建提供參考。
1 研究方法
目前大多數風險預測模型以一個電子病歷數據集為基礎,回顧性納入病歷資料進行對比分析,前瞻性研究相對較少。
1.1 數據收集及數據預處理
根據研究目標,在數據集中尋找需要的數據,并對原始數據進行嚴格清洗、結構化、標準化、質量檢查。變量的缺失值會增加數據分析的難度,也可能會使最終結果存在偏差[6]。數據缺失的處理有多種方法,包括均值填補法、期望值最大化法、回歸填補法、多重填補法等,研究者根據不同的數據缺失特點具體選擇[7]。自然語言處理信息抽取技術是處理電子病歷的關鍵技術,有助于充分利用電子病歷中的非結構化數據[8]。必要時進行人工分析和質量控制,以保證最終數據質量。
1.2 確立模型指標
建立風險預測模型,需要確立風險因子和結局指標。識別風險因子主要有3種基本方法:(1)查閱相關文獻選取重要特征;(2)對數據集中的特征進行初步統計分析,確定與結局具有明顯相關性的特征;(3)由專家給出一些高度懷疑的特征。實踐過程中以三種方法結合使用多見[9]。近年來,基因信息也被應用到構建風險預測模型中,并且被證明對許多常見疾病具有預測價值[10]。
1.3 構建模型
1.3.1 數據劃分。 一般分為訓練集、測試集,部分研究增設驗證集[11]。訓練集主要用于擬合模型;驗證集用于對模型的能力進行初步的評估;測試集用于評估模型最終的泛化能力。
1.3.2 選擇相對成熟的預測方法。 數據挖掘又稱“數據庫中的知識發現”[12],指從大量不完全、有噪聲的隨機數據中提取隱含及事先不知道的潛在有用信息,統計學在其中占有重要地位[13]。應用于風險預測的傳統統計學習模型以logistic回歸模型和比例風險回歸模型為經典。常用的機器學習算法包括貝葉斯、決策樹模型、隨機森林、人工神經網絡和支持向量機等[14],詳見表1。通過將機器學習建立模型與獨特的診療知識相結合,可以更好地確定患者診治工作的重點,增強醫療活動科學依據性[15]。
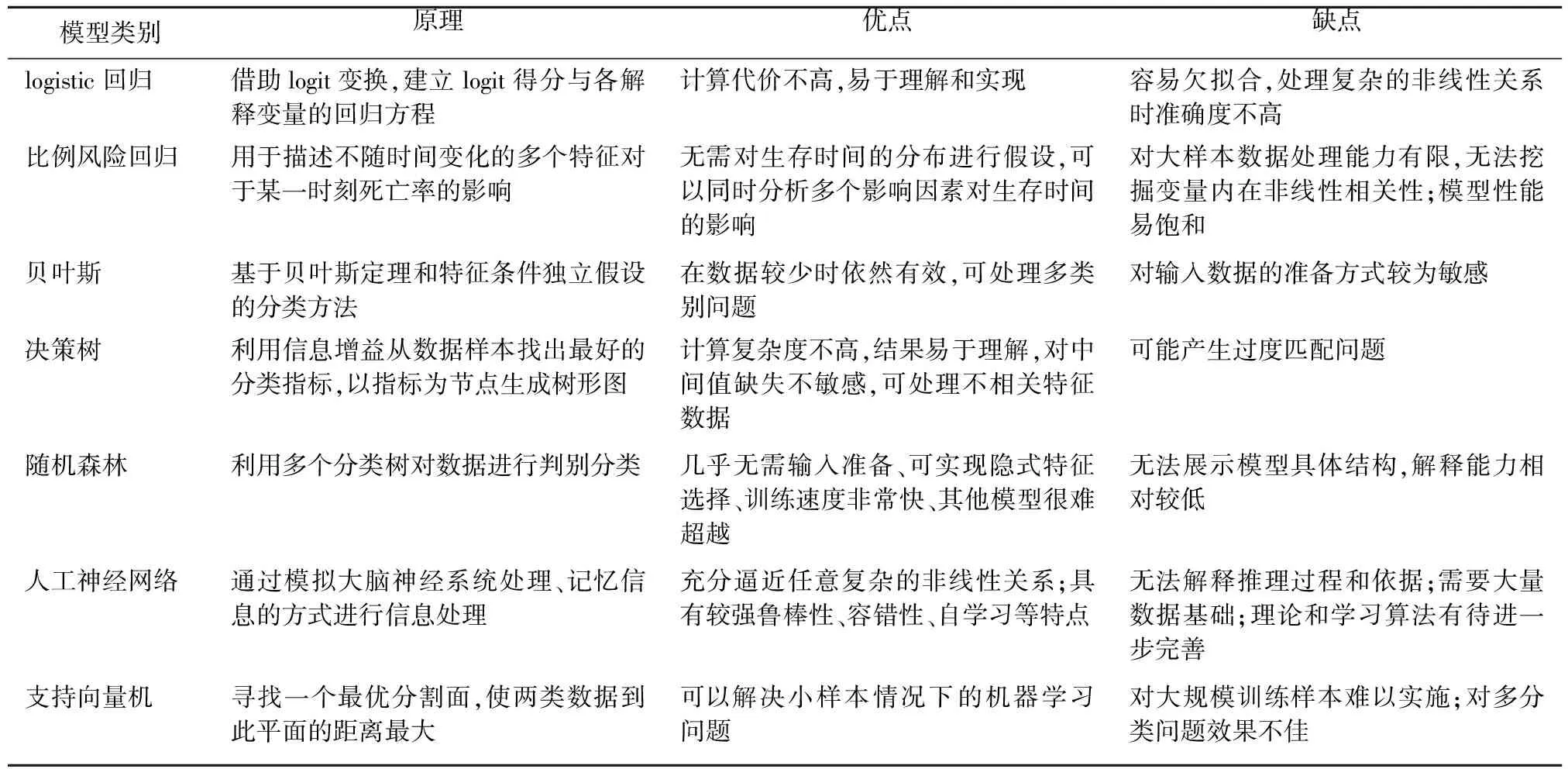
表1 基于電子病歷數據構建風險預測模型的常用方法及特點
近年來,深度學習方法在處理大量多元數據時取得了良好性能,特別是在計算機視覺、語音識別、自然語言處理等方面[16]。陳雯等[17]對深度學習在癌癥預后中的應用綜述得出深度學習對癌癥患者預后預測有良好的指示能力。
1.4 模型驗證及評價
模型驗證分為內部驗證和外部驗證。內部驗證是使用與訓練集相同的人群對模型進行評估,主要包括隨機拆分驗證、K折交叉驗證、Bootstrap等方法;外部驗證是使用其他數據來源的同類數據對模型進行驗證。評價模型預測性能最常用的指標有區分度和校準度。區分度是指模型區分研究中陽性個體和陰性個體的能力;校準度是指訓練集人群平均預測概率與實際發病概率的一致性。另外,評價預測模型的好壞不僅需要評估其預測性能,還需考慮數據采集成本、開發難易度及應用便利性,研究者應努力實現成本和效能之間的平衡。
2 優勢
在醫療信息化建設中,電子病歷因其具有快速全面準確地采集、存儲、處理和傳輸醫療信息的能力,成為醫療信息化的核心建設內容。使用電子病歷系統建立風險預測模型的具體優勢如下。
2.1 樣本數據充實
使用電子病歷系統建立風險預測模型的首要優勢即患者數據量大。基于電子病歷系統的風險預測模型與傳統風險預測研究不同,傳統風險預測研究收集數據前,需要明確參與者納入排除標準、定期隨訪等方法。而電子病歷對患者的就診和治療信息全面記錄[18],包括患者所有的健康信息,這一特點從本質上決定了電子病歷數據規模更大。
2.2 信息元素豐富
傳統風險預測研究開始前需明確要收集的特定指標以及相應的預期判定結果。而電子病歷基本覆蓋患者就診的全部過程,支持幾乎所有的實驗室檢驗、臨床醫療、長期醫療甚至家庭醫療中的信息和流程管理,醫療數據資源更豐富[19]。基于電子病歷這一特點,陳漪[20]選取規律腹膜透析治療同時患有糖尿病的患者建立感染風險預測模型,驗證結果顯示模型具有較好的預測性能。Wang等[21]和 Xie等[22]基于瑞典一項病例對照研究采集的電子病歷數據,分別構建了食管鱗癌和食管腺癌患者5年絕對發病風險預測模型,為人群食管癌防控策略的制定提供依據,使用同一組患者數據預測多種臨床結局成為可能。
2.3 采集數據頻率高
電子病歷系統記錄并管理患者片段化或縱向的電子病歷信息,時間序列是其重要特征,采集數據的頻率通常遠高于傳統風險預測,因此預測患者特定事件發生的近期風險也更容易。周彤彤[23]調查發現與傳統的基于特定時間的截面數據相比,使用電子病歷時序數據建立的模型預測精度更高、結果更穩定,有助于實現臨床終點預測任務提前預知。
2.4 結果可信度高
來自電子病歷系統的患者群體涵蓋廣泛患者人群,人工選擇較少,凡就診治療的患者其相關信息均被記錄。電子病歷數據來源于真實臨床,而非設有諸多條件限制的科研場所,樣本信息更具代表性。袁術鵬[9]基于臨床數據建立老年骨科患者術后泌尿系感染的風險預測模型,經驗證有較好的預測能力。
2.5 節省科研資源
電子病歷數據是系統儲存的資料,研究者通過申請可以直接使用。如劉宇英等[24]使用美國前列腺、肺、結直腸及卵巢癌篩查電子數據庫作為數據來源建立結直腸癌發病風險預測模型。相較于傳統風險預測隊列研究,使用電子病歷數據易于進行大樣本研究,節省研究成本的同時,有助于提高研究效率。
3 存在不足
現階段的電子病歷系統仍存在種種不足,需在發展過程中不斷完善。
3.1 數據質量存在問題
目前電子病歷系統仍處于發展初期階段,與手寫病歷相比,電子病歷內容存在重復記錄現象,Benke K等[25]認為是復制粘貼所致;如何處理數據缺失同樣是電子病歷系統研究公認的一大難點[26];另外,電子病歷數據可能存在患者病情嚴重程度分布不均的問題[27],病歷系統賬戶是否為賬戶所有者本人操作存疑[28],可能存在數據輸入錯誤,影響預測模型準確性,有學者調查發現電子病歷書寫缺陷發生率高,需要加強改進病歷記錄質量管理[29]。只有擁有高質量的數據,風險預測模型才具有真正發揮作用的基礎。
3.2 數據獲取困難
3.2.1 數據提取技術仍不成熟。 電子病歷數據包含的特征信息種類繁多、維度龐大,充斥著大量非結構化文本數據,且具有一定的時序性。人工分析法在大樣本研究中效率較低,且受限于研究人員的經驗,只能起到輔助作用。諸多學者對數據提取方法進行不斷優化,自然語言處理技術不斷更新。鄭曉燕[30]對人口學數據進行one-hot編碼,用二位編碼代替原有的一位編碼。沈貝敏等[31]采用深度協同過濾方法對現有精神疾病非結構化數據進行處理,最終模型準確性87.49%,精度51.13%。近年來,卷積神經網絡和循環神經網絡被應用于數據的特征提取,有助于充分利用電子病歷中的時序性數據,但受限于只能捕獲局部特征信息,對數據時序排列要求嚴格,缺少語義特性[32]。如何對電子病歷系統中的大量數據進行表征學習仍是構建風險預測模型的主要挑戰。
3.2.2 數據獲取途徑受限。 醫學信息涉及到隱私保護和倫理問題,大多醫療信息是非公開的,國內各醫院間信息無法共享,數據獲取途徑受限。吉云蘭等[33]對嚴重創傷患者進行譫妄風險預測,但只基于1家醫院ICU電子病歷數據進行研究,可能存在選擇偏移,結論需通過大樣本、多中心研究進行驗證。
3.3 風險因素考慮不足
國內外學者構建的風險評估模型中的風險因素不盡相同。大部分模型考慮影響疾病風險的因素數量單一,限制了判別性能[34]。變量的個數、種類、是否納入了真正有預測作用的變量均有可能影響預測模型的效能。關于老年人跌倒風險因素,不同研究者研究結果不一,覆蓋年齡、性別、疾病、藥物、跌倒史、生活習慣、生理狀態、心理狀態、生化指標、環境因素和社會因素等各個方面[35]。基于電子病歷數據篩選風險因素應綜合應用文獻報道、統計方法和醫學專業知識三種策略,盡可能全面納入。
3.4 模型驗證不足
預測模型應用前,應進行強有力的外部驗證。然而,由于具備完整臨床信息的特定疾病患者數量往往不足、大量數據獲取困難等現實因素制約,大多數研究沒有進行模型驗證,尤其是外部驗證,模型的穩定性和外推性得不到保證,導致許多模型不能用于臨床實踐[36]。如于建發等[37]構建的患者預后風險模型,由于相關疾病患者數量不足,且部分臨床特征無法獲取詳細信息,未能設立驗證集,模型有效性有待進一步驗證。
3.5 電子病歷系統不統一
現階段的電子病歷系統多是中心特定的,尚未形成醫院間整體統一的電子病歷系統模式,預測模型針對特定的電子病歷開發,能否在區域層面推廣有待商榷。大量散在數據資源不能被有效整合利用,現有預測模型效能受到制約。2018年《關于進一步推進以電子病歷為核心的醫療機構信息化建設工作的通知》提出醫療機構應逐步解決電子病歷信息孤島、信息煙囪問題,推進系統整合[38]。美國新一代醫院信息系統實現了1 000多家醫院信息的互聯互通,其建設經驗值得借鑒研究。
隨著信息技術的快速發展,醫療行業全面進入信息化發展時代,電子病歷在患者信息全程留痕化、數據標準化等方面優勢明顯,成為診療數據的重要來源。在亞健康人群和患病人群不斷增多的全球背景下,預測疾病的發生發展及結局采用客觀工具、減少主觀經驗判斷具有重要意義。基于電子病歷系統建立的風險預測模型充分利用病歷數據,結果可信度高,節省資源,可有效幫助醫護人員進行臨床決策,然而在高質量數據獲取、風險因素考慮、模型驗證應用等方面還存在不足,現階段電子病歷仍存在患者數據重復記錄、數據缺失等問題,尚未打破不同醫院電子病歷系統間的信息煙囪,未來構建高性能風險預測模型應注意規避此類問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
