新能源場站風功率曲線異常數(shù)據(jù)處理算法
2023-12-30 01:57:56李宣諭
安徽電氣工程職業(yè)技術(shù)學院學報 2023年4期
關(guān)鍵詞:風速
李宣諭
(大唐東北電力試驗研究院有限公司,吉林 長春 130102)
0 引言
近年來,隨著國家能源政策調(diào)整,我國風力發(fā)電規(guī)模逐年增長,已在整體能源布局中占據(jù)著重要地位。風功率曲線作為重要性能指標,是開展風電機組數(shù)據(jù)分析的基礎(chǔ)[1],相關(guān)分析研究工作隨著新能源發(fā)展逐年推進。風電企業(yè)在日常運行過程中,受外部環(huán)境干擾、風機運行故障、棄風限電等因素影響[2],風電場數(shù)據(jù)采集與監(jiān)視控制(supervisory control and data acquisition,SCADA)系統(tǒng)存在大量的異常數(shù)據(jù)[3]。如果這些數(shù)據(jù)不加以處理直接應用,較差的數(shù)據(jù)質(zhì)量會造成擬合的風機實際功率曲線發(fā)生畸變,干擾機組運行特性分析,影響風電機組生產(chǎn)經(jīng)濟性與運行狀態(tài)評估結(jié)果[4]。因此,對風電機組功率數(shù)據(jù)進行異常數(shù)據(jù)識別與清洗,提取高質(zhì)量數(shù)據(jù)是不可缺少的環(huán)節(jié)[5-6]。
現(xiàn)階段常用的風電機組功率數(shù)據(jù)識別方法可分為以下幾類:(1)基于統(tǒng)計分析的異常數(shù)據(jù)識別方法,主要有3sigma法[7]、四分位法[8]、組內(nèi)最優(yōu)方差[9]、變點分組[10]、Thompson tau[11]、云分段最優(yōu)熵[12]和Copula理論[13]等算法;(2)基于機器學習的異常數(shù)據(jù)識別方法,主要有k-means算法[14]、基于密度的空間聚類DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法[15];(3)基于圖像的異常數(shù)據(jù)識別方法,主要有基于圖像邊緣識別的技術(shù)[16]、基于圖像分割技術(shù)[17]與基于圖像像素技術(shù)[18]三種方法。不同的異常數(shù)據(jù)識別方法在實際應用過程中具有各自的特點,其中,四分位法異常數(shù)據(jù)識別速度較快,對離散型數(shù)據(jù)識別效果較好,通用性強,穩(wěn)定性好,但在異常數(shù)據(jù)占比較大時,辨識效果不佳[19]。DBSCAN算法可有效實現(xiàn)分散型數(shù)據(jù)的識別,并可用于一維或多維特征空間,但對堆積型數(shù)據(jù)識別能力較差[20],圖像處理技術(shù)對異常數(shù)據(jù)識別較慢,對各類異常數(shù)據(jù)識別效果相對較好,但技術(shù)實現(xiàn)難度較高,無法區(qū)分出切出風速附近的虛假異常數(shù)據(jù)[21]。
針對以上問題,本文提出將DBSCAN算法與四分位法進行優(yōu)勢結(jié)合,構(gòu)建基于DBSCAN-分段四分位的組合算法,通過DBSCAN算法對風功率樣本數(shù)據(jù)聚類分析,將異常數(shù)據(jù)簇類別與特征進行區(qū)分,再利用四分位法把離散的堆積型異常數(shù)據(jù)剔除,完成風速-功率數(shù)據(jù)處理。經(jīng)過代入某風電機組實測數(shù)據(jù),比較分析組合算法、標準DBSCAN算法與四分位法對樣本數(shù)據(jù)異常識別與清洗的效果,驗證了所提方法的可行性及在數(shù)據(jù)處理方面的優(yōu)勢。
1 算法介紹
1.1 DBSCAN算法
DBSCAN算法是一種基于空間數(shù)據(jù)密度的聚類算法[22]。該算法的優(yōu)勢是不需要預先約定分類的數(shù)量,完全依靠數(shù)據(jù)本身質(zhì)量進行分類,可對任意形狀分布的稠密數(shù)據(jù)進行聚類,聚類結(jié)果沒有偏倚。缺點是聚類結(jié)果受兩個參數(shù)初值影響較大[23],在樣本數(shù)據(jù)密度分布不均勻或聚類間距差距較大時,聚類質(zhì)量較差[24]。計算流程如下:
(1)預先確定參數(shù)鄰域半徑Eps與最小數(shù)據(jù)點集合個數(shù)Minpts;
(2)以樣本數(shù)據(jù)中任意一個從未訪問點開始,以Eps為半徑距離,如果在這個鄰域半徑范圍內(nèi)分布的其它數(shù)據(jù)點個數(shù)大于或等于集合個數(shù)Minpts,則標記為正常數(shù)據(jù),如小于Minpts,則標記為異常數(shù)據(jù);
(3)返回上一步,代入新的數(shù)據(jù)點進行計算,直到所有數(shù)據(jù)計算完畢;
(4)剔除異常數(shù)據(jù)集,將正常功率數(shù)據(jù)保留。
1.2 四分位算法
四分位法是一種通過度量數(shù)據(jù)分布位置進行異常數(shù)據(jù)識別的方法。在對離群數(shù)據(jù)點分析處理時,不需要事先假設(shè)數(shù)據(jù)服從某種分布,可有效分析數(shù)據(jù)集群體分布特征,去除數(shù)據(jù)中離群值的影響,數(shù)據(jù)處理效果較為穩(wěn)定[10]。計算方法如下:
(1)風功率樣本數(shù)據(jù)集中,功率的個數(shù)記為n,并按功率從小到大排列。
(2)當(n+1)/4可以整除時,如式(1)所示。
(1)
式中:Q1為第0.25(n+1)位的功率數(shù)值;Q2為第0.5(n+1)位的功率數(shù)值;Q3為第0.75(n+1)位的功率數(shù)值。
(3)當(n+1)/4不能整除,且n=4k+4,(k=1,2,3,…)時,如式(2)所示。
(2)
式中:Q1為第0.25n位功率數(shù)值的0.75倍與第(0.25n+1)位功率數(shù)值的0.25倍之和;Q2為第0.5n位功率數(shù)值與第(0.5n+1)位功率數(shù)值平均值;Q3為第0.75n位功率數(shù)值的0.25倍與第(0.75n+1)位功率數(shù)值的0.75倍之和。
(4)當(n+1)/4不能整除,且n=4k+6,(k=1,2,3,…)時,如式(3)所示。
(3)
式中:Q1為第(0.25n-0.5)位功率數(shù)值的0.25倍與第(0.25n+0.5)位功率數(shù)值的0.75倍之和;Q2為第0.5n位功率數(shù)值與第(0.5n+1)位功率數(shù)值平均值;Q3為第(0.75n+0.5)位功率數(shù)值的0.75倍與第(0.75n+1.5)位功率數(shù)值的0.25倍之和。
(5)剔除異常值。
下邊緣限值Llow如式(4)所示。
Llow=Q1-1.5(Q3-Q1)
(4)
上邊緣限值Lhigh如式(5)所示。
Lhigh=Q3+1.5(Q3-Q1)
(5)
對每個風速段區(qū)間數(shù)據(jù)進行計算,將數(shù)據(jù)位置處于Llow~Lhigh范圍之外的數(shù)據(jù)視為異常數(shù)據(jù),將其剔除,保留下的數(shù)據(jù)則為風功率正常數(shù)據(jù)。
1.3 DBSCAN-分段四分位法
首先采用DBSCAN算法,根據(jù)樣本數(shù)據(jù)特征劃分數(shù)據(jù)簇類別,剔除部分異常數(shù)據(jù)簇。然后,將樣本數(shù)據(jù)以風速分布為基準等間隔劃分,分段使用四分位法,進一步識別少部分堆積型異常數(shù)據(jù)與離群數(shù)據(jù)特征不明顯的異常點。計算流程如圖1所示。
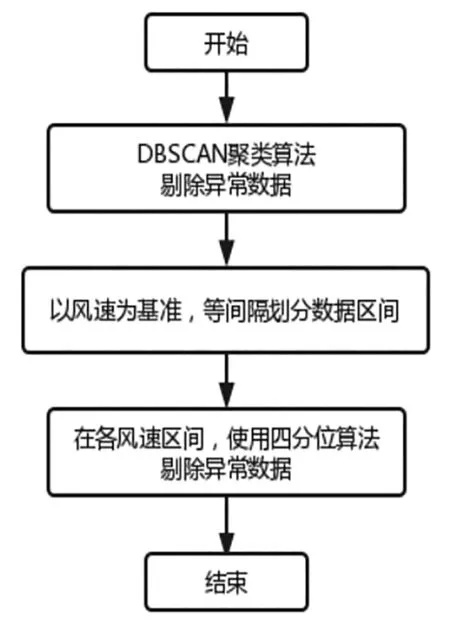
圖1 DBSCAN-分段四分位算法流程圖
2 風電數(shù)據(jù)實例分析
2.1 算法應用流程介紹
以國內(nèi)云南某風電場20號風機實測運行數(shù)據(jù)為例,如表1所示。選取2021年9月1日至2022年9月1日的實測數(shù)據(jù),采樣間隔10 min,共計47 837組數(shù)據(jù)作為樣本數(shù)據(jù)。分別采用DBSCAN法、四分位法和DBSCAN-分段四分位法進行異常數(shù)據(jù)處理,對比分析異常數(shù)據(jù)清洗效果,驗證算法性能。
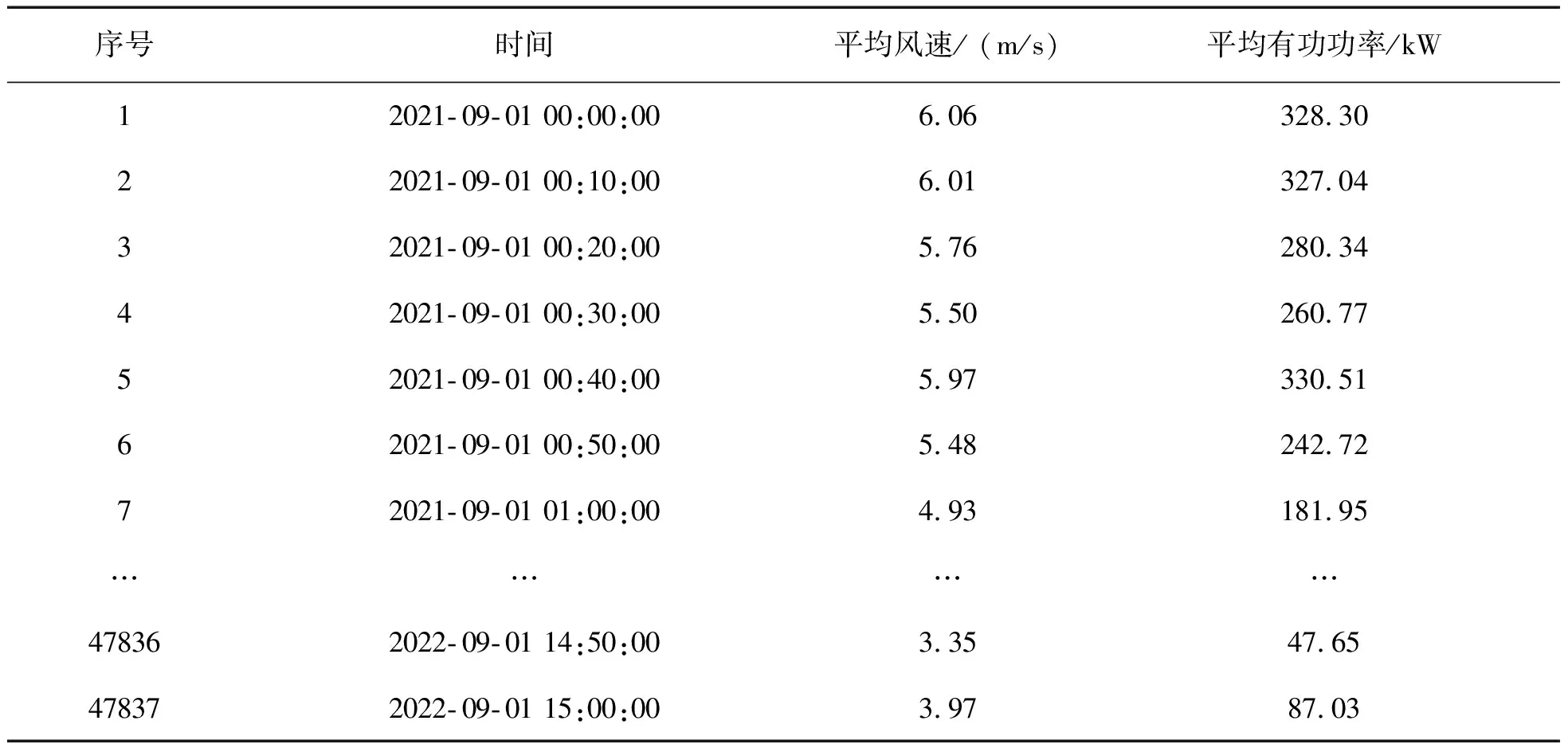
表1 某風場20號風機風速-功率數(shù)據(jù)
采用DBSCAN法對樣本數(shù)據(jù)進行異常數(shù)據(jù)識別,其中核函數(shù)鄰域半徑Eps與最小數(shù)據(jù)點集合個數(shù)Minpts可通過k-distance方法確定,如表2所示。

表2 k-distance對核函數(shù)尋優(yōu)結(jié)果
將參數(shù)尋優(yōu)結(jié)果代入標準DBSCAN法,經(jīng)測試,核函數(shù)Minpts=19,Eps=0.006對異常數(shù)據(jù)識別效果最好,標準DBSCAN法對異常數(shù)據(jù)識別結(jié)果如圖2所示。其中,藍色數(shù)據(jù)點為正常數(shù)據(jù),紅色數(shù)據(jù)點為異常數(shù)據(jù)。由圖中可以看出,在機組進入切入風速以后,少部分零功率異常數(shù)據(jù)點未能辨別。其原因是由于算法自身的局限性,滿足算法規(guī)則的少量的堆積型異常數(shù)據(jù)未能有效識別。

圖2 DBSCAN法對異常數(shù)據(jù)識別結(jié)果
運用四分位法進行數(shù)據(jù)處理時,不建議直接進行異常數(shù)據(jù)清洗。當部分區(qū)間數(shù)據(jù)占比較小時,少部分正常數(shù)據(jù)可能被認為異常數(shù)據(jù)刪除,導致清洗后的數(shù)據(jù)不完整,擬合功率曲線后初始值不是從0開始,如圖3所示。

圖3 四分位法對異常數(shù)據(jù)識別結(jié)果
本文建議以風速為基準,將樣本數(shù)據(jù)等間隔劃分40組數(shù)據(jù)段或60組數(shù)據(jù)段,每段數(shù)據(jù)區(qū)間的風速-功率數(shù)據(jù)采用四分位法進行異常數(shù)據(jù)識別,剔除異常數(shù)據(jù)后再將各區(qū)間的正常數(shù)據(jù)重新組合,采用分段四分位法效果如圖4、圖5所示。

圖4 四分位法(劃分40組數(shù)據(jù))對異常數(shù)據(jù)識別結(jié)果
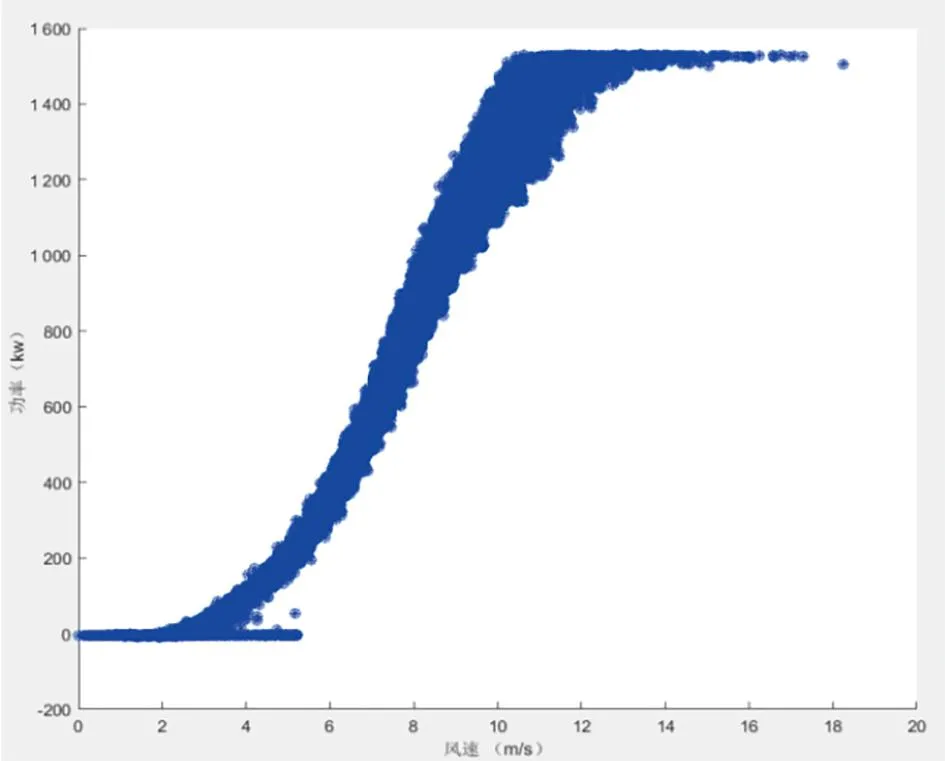
圖5 四分位法(劃分60組數(shù)據(jù))對異常數(shù)據(jù)識別結(jié)果
為了提高算法對樣本數(shù)據(jù)特征識別準確性,將數(shù)據(jù)按區(qū)間劃分,分段進行四分位法計算,克服局部堆積型數(shù)據(jù)對整體異常數(shù)據(jù)識別效果的影響。由圖4、圖5可以看出,并不是數(shù)據(jù)段劃分越多對異常數(shù)據(jù)識別效果越好,受限于算法規(guī)則,數(shù)據(jù)區(qū)間劃分越多對局部堆積型異常數(shù)據(jù)越敏感,分段四分位法也無法完全識別局部占比較高的異常數(shù)據(jù)。因此,劃分數(shù)據(jù)段區(qū)間個數(shù)應選擇較為適合的值。
根據(jù)本文所提方法,先通過DBSCAN法剔除大部分異常數(shù)據(jù),再通過分段四分位法(劃分40組數(shù)據(jù))將少部分堆積型異常數(shù)據(jù)剔除,結(jié)果如圖6所示。
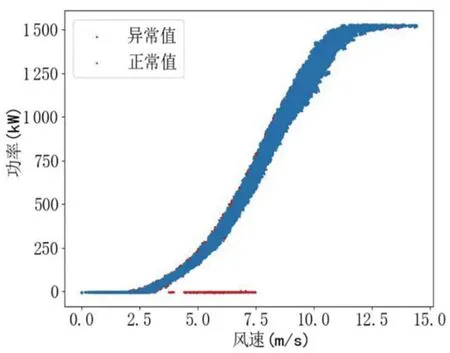
圖6 分段四分位法對異常數(shù)據(jù)處理效果
數(shù)據(jù)處理結(jié)果如圖7所示。

圖7 DBSCAN-分段四分位算法對異常數(shù)據(jù)清洗效果
經(jīng)數(shù)據(jù)處理后,保留正常數(shù)據(jù)47 693組,異常數(shù)據(jù)剔除率為0.3%,被清洗的異常數(shù)據(jù)集中存在少量被誤刪的正常數(shù)據(jù),對原始數(shù)據(jù)的完整性和充裕度造成了一定影響,但這部分占比不高,清洗后的正常數(shù)據(jù)仍可完全表征風功率曲線全行程特性。此外,由圖7可以看出,通過DBSCAN-分段四分位算法對樣本數(shù)據(jù)處理,已將離散、橫向分布的異常數(shù)據(jù)完全剔除,提取的風速-功率數(shù)據(jù)質(zhì)量較好,數(shù)據(jù)清洗效果優(yōu)于標準DBSCAN法和四分位法。
2.2 算法實例應用驗證
采用本文所提方法對遼寧某風電場8號風機的運行數(shù)據(jù)進行異常數(shù)據(jù)識別分析。該風機的機組型號為H111-2.0 MW,切入風速3.0 m/s,切出風速25.0 m/s,額定風速11.5 m/s。樣本數(shù)據(jù)選取2022年7月1日至2023年6月30日運行數(shù)據(jù),采樣間隔10 min,共計54 870組數(shù)據(jù)作為樣本數(shù)據(jù),驗證算法實際應用效果,數(shù)據(jù)如表3所示。
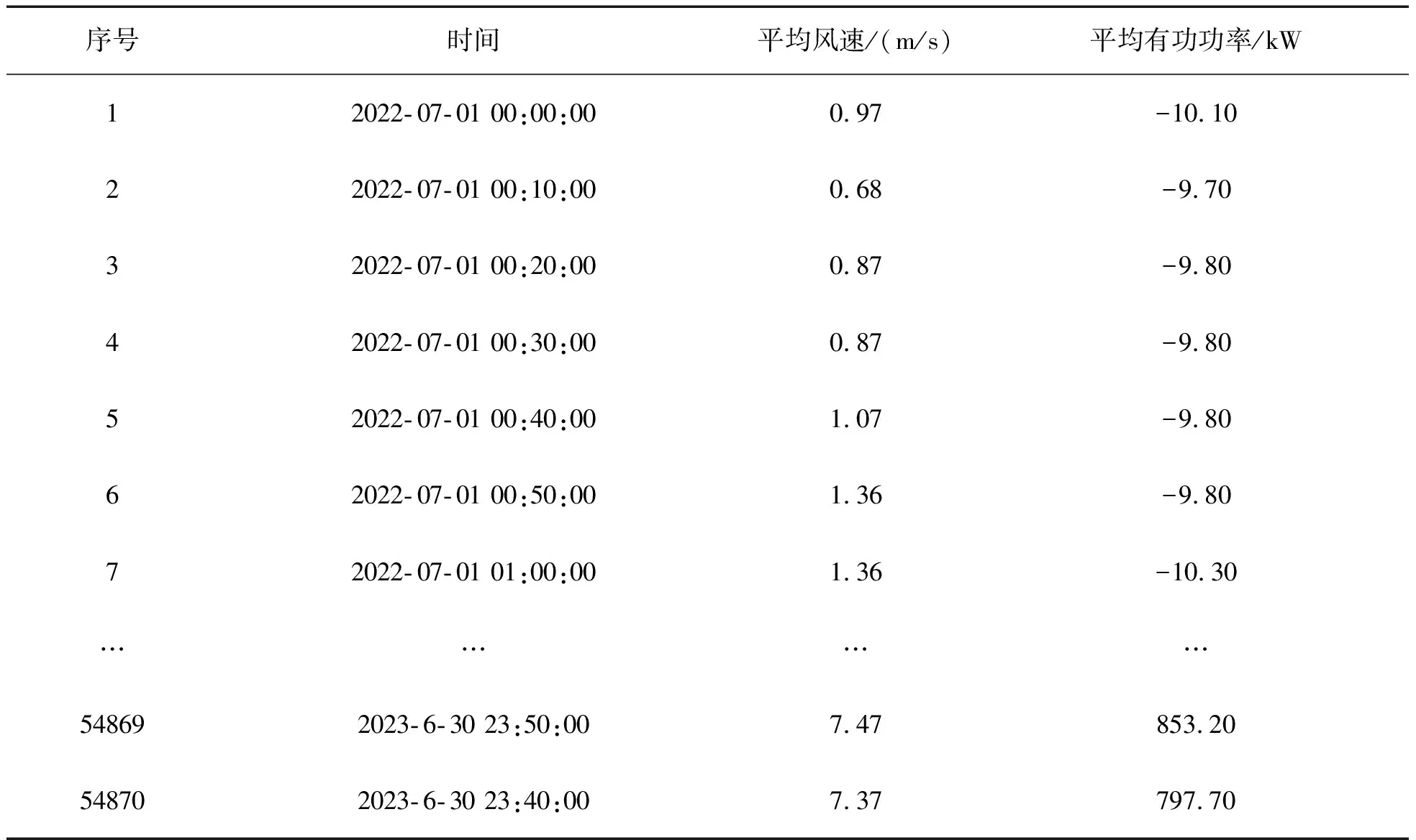
表3 遼寧某風場8號風機風速-功率數(shù)據(jù)
繪制8號風機實測數(shù)據(jù)的散點分布如圖8所示。
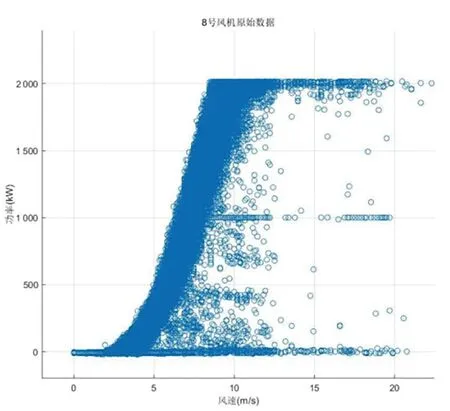
圖8 8號風機實測數(shù)據(jù)散點分布圖
從圖8中可以看出樣本功率數(shù)據(jù)存在大量的橫向分布的堆積型異常數(shù)據(jù)以及曲線周圍的分散型異常數(shù)據(jù),這兩類異常數(shù)據(jù)主要由棄風限電、通信設(shè)備故障、機組計劃外停機檢修等隨機因素造成。該機組理論功率曲線參數(shù)如表4所示。
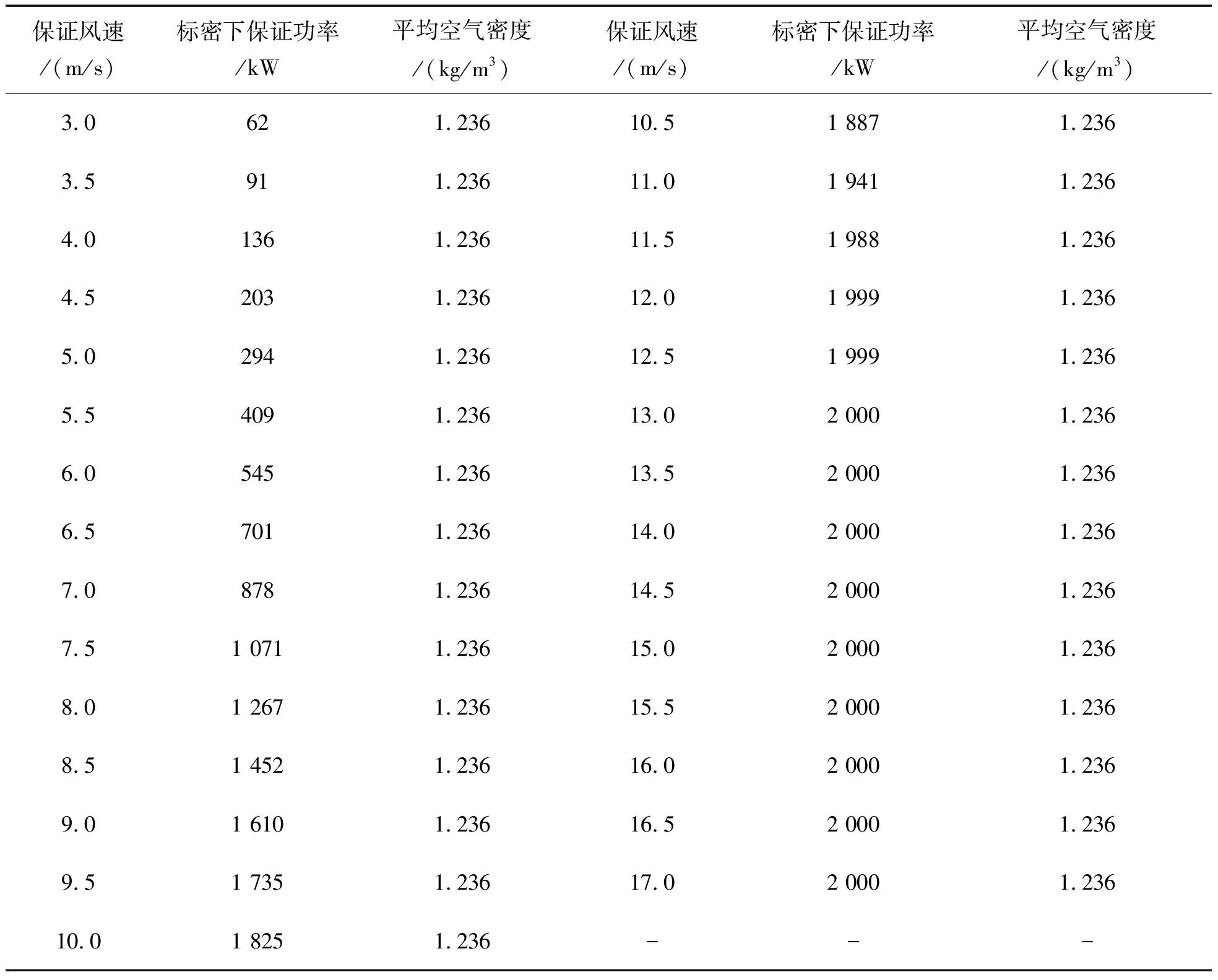
表4 遼寧某風場8號風機理論功率曲線參數(shù)(空氣密度=1.225 kg/m3)
經(jīng)數(shù)據(jù)處理,剔除異常數(shù),篩選正常數(shù)據(jù)51 293組,剔除異常數(shù)據(jù)3 577組,保留正常數(shù)據(jù)占比93.481%,異常數(shù)據(jù)識別占比6.519%,風功率數(shù)據(jù)清洗效果如圖9所示。
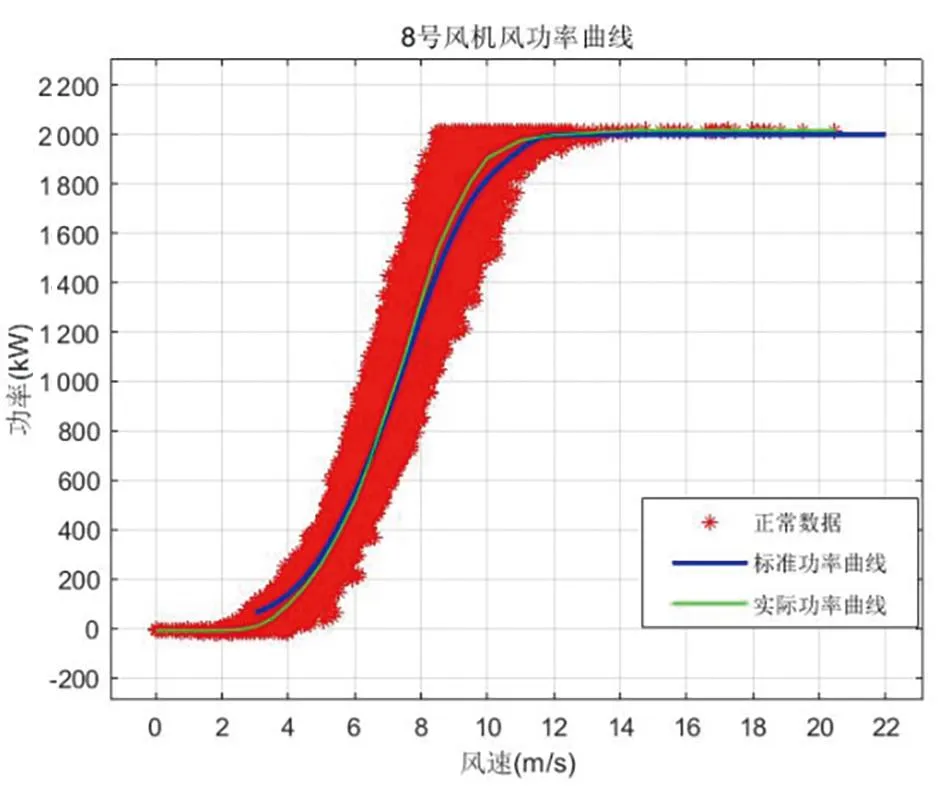
圖9 8號風機功率曲線示意圖
圖9中,紅色散點數(shù)據(jù)為數(shù)據(jù)清洗后的正常數(shù)據(jù),藍色曲線為主機廠家提供的標準功率曲線,綠色曲線為8號風機實際功率曲線。該效果圖可較好地用于風機功率曲線分析,如分析風機功率一致性等。經(jīng)核算,該場8號風機功率一致性系數(shù)在合理范圍內(nèi)。
3 結(jié)束語
本文通過分析DBSCAN法與四分位法對異常數(shù)據(jù)的識別效果,提出基于DBSCAN-分段四分位的組合算法對風功率異常數(shù)據(jù)進行辨識。以某風電場實測風功率數(shù)據(jù)為基礎(chǔ),驗證本文所提方法的有效性,結(jié)論如下。
(1)基于DBSCAN-分段四分位的組合算法,可實現(xiàn)對分散型、堆積型異常數(shù)據(jù)的有效識別,在風功率異常數(shù)據(jù)識別與清洗方面有較好應用。且算法原理簡單,易于實現(xiàn),處理速度適中,清洗效果穩(wěn)定、可靠。
(2)基于DBSCAN-分段四分位的組合算法,將DBSCAN的自適應性與四分位法的通用性優(yōu)勢結(jié)合,克服單一算法局限性。通過劃分數(shù)據(jù)區(qū)間分段處理,增強對數(shù)據(jù)局部特征識別準確性,進一步提高算法自身的泛用性能與識別精度,在實際應用中具有一定優(yōu)勢。
(3)通過算例1與算例2分析表明,該組合算法在數(shù)據(jù)處理時,存在將15.0 m/s以上的正常數(shù)據(jù)誤刪的情況,對數(shù)據(jù)完整性有一定影響,但數(shù)據(jù)剔除率占比不高,處理后的數(shù)據(jù)仍可表征風機功率曲線特征,不影響風機功率曲線繪制,滿足實際項目的需要,該缺點可通過數(shù)據(jù)插值法解決。
猜你喜歡
氣象與環(huán)境科學(2021年4期)2021-08-27 02:26:12
電機與控制應用(2021年12期)2021-02-28 07:55:52
海洋通報(2020年5期)2021-01-14 09:26:54
中國電業(yè)與能源(2020年5期)2020-06-16 02:20:00
陜西氣象(2020年2期)2020-06-08 00:54:38
西南交通大學學報(2016年4期)2016-06-15 20:29:37
風能(2016年11期)2016-03-04 05:24:00
電測與儀表(2015年8期)2015-04-09 11:50:06
電機與控制應用(2015年7期)2015-03-01 03:50:15
電網(wǎng)與清潔能源(2015年3期)2015-02-28 16:03:31
