基于區域注意力機制的有噪樣本下中醫舌色分類算法研究*
2024-01-22 08:16:08李艷萍李曉光
世界科學技術-中醫藥現代化 2023年8期
卓 力,李艷萍,張 輝,李曉光,楊 洋,魏 瑋
(1.北京工業大學信息學部 北京 100124;2.北京工業大學計算智能與智能系統北京重點實驗室 北京 100124;3.中國中醫科學院望京醫院功能性胃腸病中醫診治北京市重點實驗室 北京 100102)
舌診是中醫區別于其他醫療體系的最具特色的一種診法。醫生通過觀察舌質和舌苔等的各種表現,如舌色、苔色、厚度、質地、濕度、舌形、舌態等來診察病癥[1]。舌色是其中最為直觀且最重要的一種診察特征,常見的舌色可以分為淡紅、紅、暗紅、紫等4類。因此,在中醫客觀化研究中,中醫舌色分析可以看作是一個分類問題,利用機器學習的方法來解決。
近年來,以卷積神經網絡(Convolutional Neural Network,CNN)為代表的深度學習發展迅猛,研究者們開展了基于深度學習的中醫舌色分類研究,利用CNN強大的特征提取和語義表達能力,取得了遠超過傳統方法的分類性能[2]。Hou 等[3]構建了舌圖像數據庫,使用修改后的CaffeNet 網絡對舌色進行分類。徐雍欽等[4]采用深度學習方法,提取舌象深層特征并融合舌象邊緣特征、紋理特征等進行綜合分析人體臟器病理變化。Lu 等[5]從顏色校正的角度出發,提出了一個深度色彩校正網絡,消除因光照條件導致的顏色失真。Qu 等[6]對舌體區域進行分割,分離舌質區域和舌苔區域,用稀疏編碼表示舌圖像的特征向量,通過計算重建特征向量時的殘差來確定舌色類別。
總的來看,與傳統“人工特征+分類器”的分類方法相比,基于深度學習的中醫舌色分類方法采用端到端的框架,可以獲得性能上的極大提升。但是現有的這些研究工作還無法獲得令人滿意的分類結果,主要原因在于:
①中醫醫生在判斷舌色時,往往以觀察舌尖和舌兩側為主。然而,現有的方法往往是將整幅舌圖像作為網絡的輸入,忽略了醫生的診斷習慣,導致網絡無法很好地關注舌色區域,對分類結果造成不利影響。如何有針對性地設計深度網絡模型,提升舌色分類的準確性,還需要進行深入的研究。
②CNN 需要以高質量、大規模的標注數據作為支撐,才能獲得理想的訓練性能。但是受醫生的知識水平、思維方式及診斷經驗的限制,也因為光線、環境等外界因素的影響,以及部分舌象樣本顏色類別的視覺界限不明顯等原因,導致醫生標注的舌象樣本中經常會出現錯誤的標簽,形成噪聲樣本。噪聲樣本的存在會導致網絡在訓練過程中難以收斂,分類模型的泛化能力差。針對有噪聲標注樣本情況下的分類問題,研究者們提出了各種不同的方法,用來提升有噪聲樣本情況下的網絡訓練性能,已經成為目前機器學習領域的研究熱點。這些方法大致可以分為3 類:噪聲樣本篩選和標簽校正;基于損失函數的噪聲樣本抑制;精細化的訓練策略。
噪聲樣本篩選和標簽校正的目的是為了篩選出有噪樣本,并對錯誤的標簽進行校正,提高標注樣本的質量。一種簡單的思路就是利用一個訓練好的網絡模型進行推理,挑選出預測結果與標簽不一致的噪聲樣本,并對其原有的標簽進行校正[7]。Veit 等[8]提出了一個新的網絡框架,通過引入有噪標簽的殘差,學習精確標簽與有噪標簽之間的差別,而不是擬合精確標簽,使得模型更容易學習。PENCIL框架[9]采用梯度下降和反向傳播對標簽進行更新和校正。Northcutt 等[10]提出置信學習,通過計算噪聲聯合概率轉移矩陣來估計噪聲標簽。但是這類方法往往需要一個復雜的推理步驟來將錯誤的標簽糾正,這個推理過程的建立依賴于一個復雜的噪聲模型,而噪聲模型的建立往往代價較高,或者需要一個精確的無噪聲數據集。
基于損失函數的噪聲樣本抑制方法是通過設計損失函數,在網絡訓練過程中對噪聲樣本進行有效抑制。Label Smoothing 方法以soft-one-hot代替one-hot,避免過擬合的同時,也緩解了錯誤標簽帶來的影響[11]。Bootstrapping 把模型的預測加入到真實標簽中,從而降低模型對噪聲樣本的關注度[12]。GCE(Generalized Cross Entropy)[13]將Box-Cox 變換引入到概率中,結合CE(Cross Entropy)和MAE(Mean Absolute Error)[14],達到了噪聲抑制的效果。SCE(Symmetric Cross Entropy)[15]則是將RCE(Reverse Cross Entropy)與CE 結合,構成了對稱的噪聲魯棒損失函數,也可以對噪聲樣本進行有效抑制。
精細化訓練策略依賴于對訓練過程的高度干預或者對訓練過程中超參數的精確控制,為標簽噪聲設計全新的學習模式。Decoupling 訓練策略[16]同時訓練兩個網絡,當預測結果不一致時,則更新參數。Coteaching 方法采用雙網絡協同學習的思想,抑制噪聲樣本的影響[17]。聯合優化框架通過交替更新DNN 參數和標簽,來提升噪聲樣本下的網絡訓練性能[18]。除此之外,教師-學生網絡[19-20]、迭代學習框架[21-22]等也是有效的噪聲樣本訓練策略。這類方法由于對訓練過程高度依賴,往往具有很強的局限性。
以上研究結果表明,噪聲樣本學習方法有助于提升分類性能,噪聲魯棒的損失函數不僅在抗噪聲方面擁有顯著的效果,而且應用方便。但是目前針對有噪樣本下的舌色分類工作很少,當前舌色分類的準確性還難以滿足臨床需求,這嚴重阻礙了舌診客觀化研究的進展。
針對上述問題,本文從中醫舌色分類的特點出發,提出了一種基于區域注意力機制的有噪樣本下中醫舌色分類方法,以提高舌色分類的魯棒性和準確性。主要的創新點包括:①提出了一種舌色區域注意力機制(Tongue Regional Attention Mechanism,TRAM),將其嵌入到ResNet18[23]中,構建了TRAM-ResNet18 網絡。該網絡可以更好地提取、表達舌色區域的特征,提升舌色分類性能;②設計了一種對稱修正的交叉熵(Symmetric Modified Cross-Entropy,SMCE)損失函數,用于對網絡進行優化訓練,可以在網絡訓練過程對噪聲樣本起到很好的抑制作用,提升分類的魯棒性。
在自建的3個中醫舌色分類數據集上的實驗結果表明,本文提出的舌色分類方法能以較低的模型復雜度,顯著提升分類性能,準確率分別達到了94.96%、93.36%和93.92%,mAP 分別達到了94.53%、93.05%和93.38%,Macro-F1 分別達到了94.67%、93.16%和92.43%。
1 提出的有噪樣本下中醫舌色分類方法
本文提出的有噪樣本下中醫舌色分類方法整體框架如圖1 所示。該方法采用ResNet18 作為骨干網絡。首先,根據中醫醫生主要通過觀察舌尖和舌兩側的顏色進行診斷的習慣,提出了區域注意力機制TRAM,對舌色區域的特征進行增強,抑制非舌色區域的特征,提升特征的表達能力;接下來,設計了一種對稱修正的交叉熵損失函數SMCE,用于在網絡訓練過程中對噪聲樣本進行抑制,提升舌色分類性能。
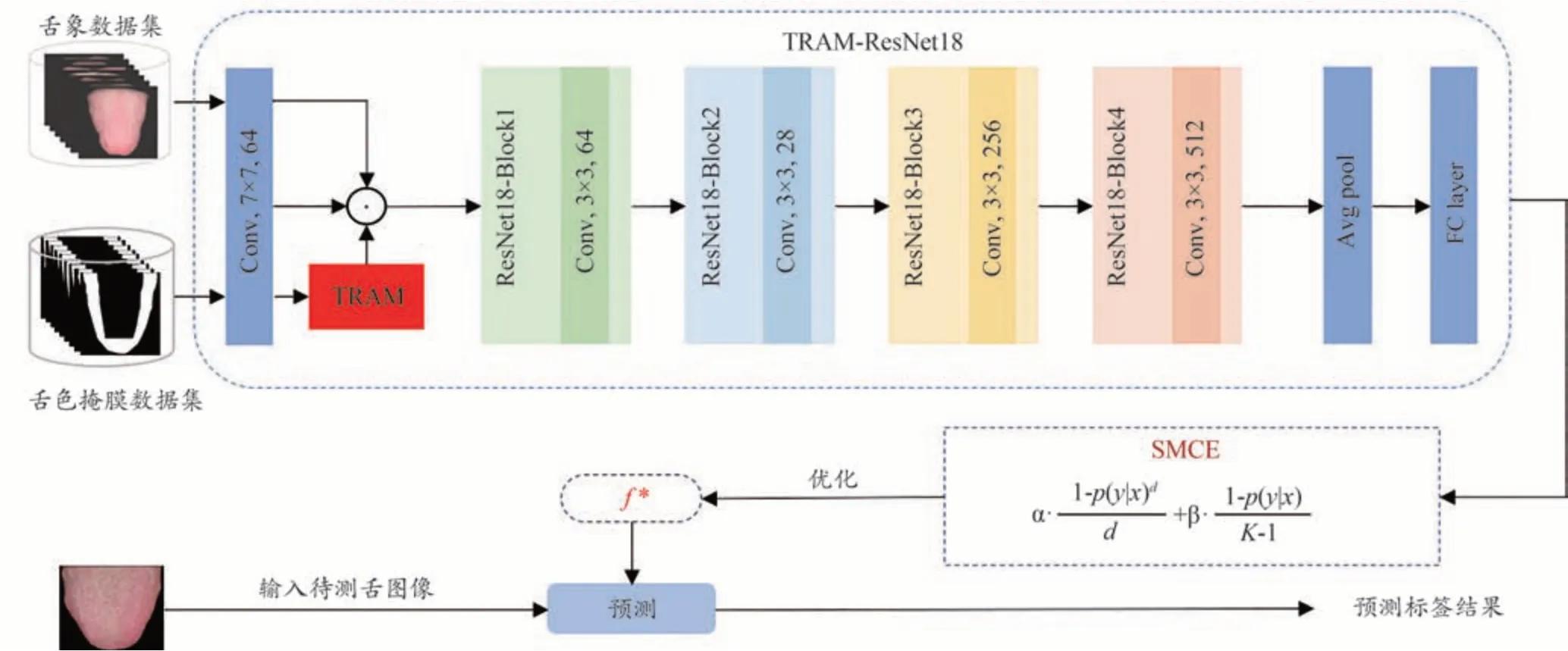
圖1 本文提出的中醫舌色分類整體框圖
1.1 舌色區域注意力機制
舌色區域注意力機制的網絡結構如圖2所示。
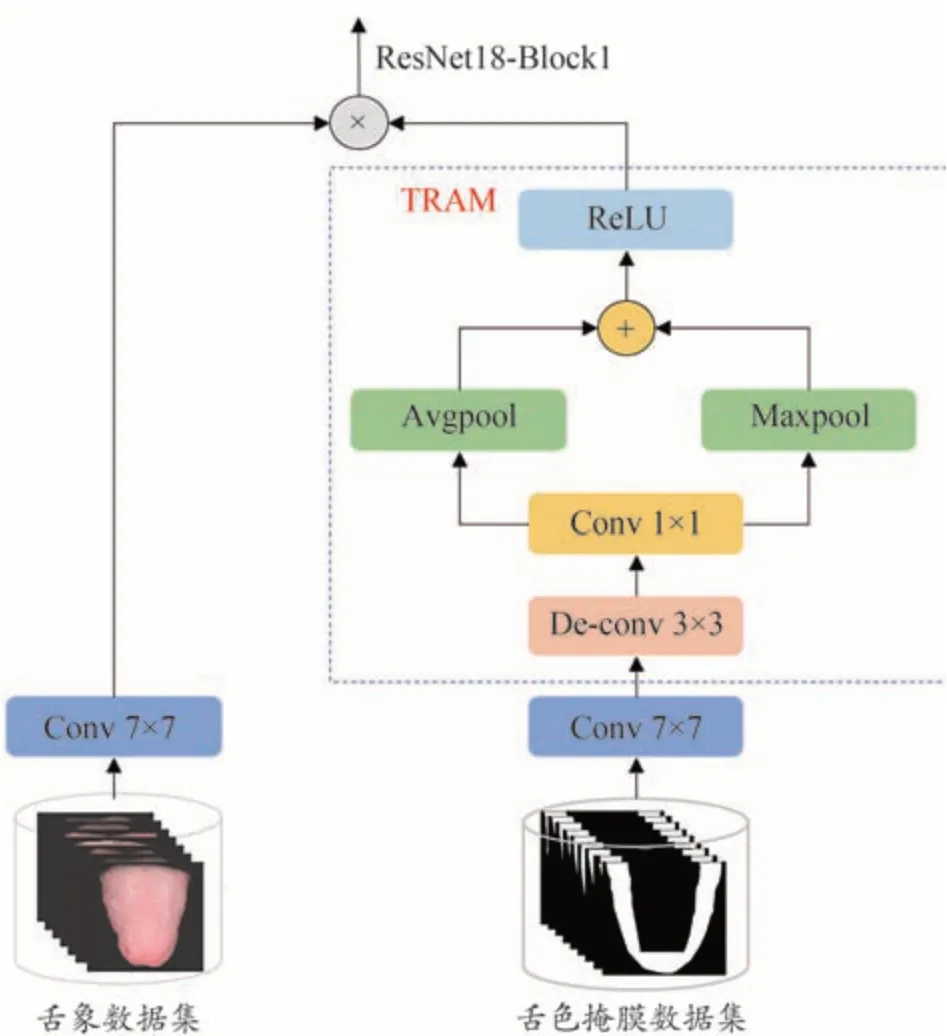
圖2 舌色區域注意力機制
根據舌色區域主要位于舌尖及舌兩側部位的特點,生成舌色區域的掩膜圖。假設輸入為舌圖像TONin,相應的舌色區域掩膜圖為TONmask∈R224×224×3,對TONin和TONmask1進行卷積變換(64@conv7×7),得到特征圖TONin1和TONmask1∈R112×112×64。接著對舌色區域掩膜圖做以下處理:
首 先,對TONmask1做 反 卷 積,生 成TONmask2∈R224×224×64。然后對其進行1×1 卷積,生成TONmask3,目的是在不改變特征圖大小以及特征圖維度的情況下,實現跨通道的線性組合。接著,對TONmask3進行平均池化與最大池化操作,將輸出結果相融合,此時的特征圖大小恢復到112×112。最后采用ReLU 非線性激活函數,得到舌色區域注意力圖TONam。整個過程可以用公式表達如下:
最后,利用舌色區域注意力圖TONam對特征通道逐一進行加權,得到增強后的特征通道TONout,可以用公式表示為:
1.2 對稱修正的交叉熵損失函數
1.2.1 定義
對于一個K類別的分類問題,假設有N個樣本量的訓練數據集D={xi,yi}N i=1,xi表示數據集中第i個訓練樣本,yi∈{1,...,K}表示對應的第i個樣本的標簽。q(k|x)表示樣本x的真實標簽分布,并且q(k|x) =1。本文研究的是每個樣本對應一個標簽的常見分類問題,假設一個樣本x的真實標簽為y,那么q(y|x) = 1,并且在所有其他標簽的條件下,即k≠y時,q(k|x) = 0。分類問題就是學習映射函數f:X→Y,將輸入空間映射到標簽空間。針對每個樣本x,分類器f(x)會計算它在每個標簽下的概率,即k∈{1,..,K}:p(k|x)=ezk/,其中zk指類別為k時的網絡logits層的輸出,p(k|x)表示分類器預測的標簽概率分布。訓練分類器f是為了找到一組最佳參數θ滿足最小化經驗風險,定義為:
其中L(f(x),y)是分類器f在標簽為y時的損失。
本文針對有噪樣本情況下的舌色分類問題,設計了一個噪聲魯棒的損失函數,即對稱修正的交叉熵損失函數,對于一個樣本x,其計算公式如下:
其中p(y|x)代表預測正確時的概率分布,d是GCE 中的動態調節參數,K代表類別數,α和β分別是可調參數,通過調節α和β來搭配,以達到模型性能最好時的損失函數。本文設置α= 1,β= 0.1。
下面對SMCE進行理論分析和說明。
1.2.2 理論分析
2017 年,微軟提出了一個重要的研究發現[24],即,對稱性損失函數具有一定的抗噪能力。通過推導和進一步實驗,證明了MAE就是一種典型的擁有對稱性的損失函數,具體公式為:
而平時最常用的CE 損失函數則是非對稱的,它的公式為:
此外,結合患者的病因構成,對其一般資料與病因構成關聯分析顯示,40歲以下患者13例,約為21.7%;40至60歲患者27例,約為45.0%;60歲以上患者20例,約為33.3%,并且年齡在50歲及以上的中老年患者數量比率達到58.3%,數量比率最多。此外,不同病因患者其年齡分布上也存在一定的差異,P<0.05,具有統計學意義。
因此,MAE 是一種噪聲魯棒的損失函數,而CE 則不是。但由于梯度飽和等原因,使用MAE訓練網絡的速度比較緩慢。基于此,Zhang Z 等[13]利用CE 的快速收斂性,將其與MAE 相結合,提出了一個噪聲魯棒的損失函數GCE。GCE 將Box-Cox 變換應用于概率,可以看作是MAE和CE的廣義混合,具體公式為:
其中d是動態調節參數。當d= 1 時,GCE 相當于MAE;當d= 0 時,GCE 相當于CE,因此GCE 是一種可以動態調節的損失函數。但是,GCE只能保證在部分情況下是噪聲魯棒的,即當d= 1,GCE則變形為MAE。
基于此,本文提出了一種對稱修正的交叉熵損失函數SMCE,使得無論d取何值、GCE 此時是何種變換形式,都有一個對稱的損失函數在發揮著噪聲抑制的作用。SMCE損失函數的公式為:
可以看出,SMCE 包括LGCE和LADD兩個損失函數,通過α和β權重系數來調節兩個損失函數的作用。LADD表達式為:
為了證明LADD是對稱的,將其化簡,可以得到:
可見,LADD是一個對稱的損失函數。這使得SMCE始終具有一定的抗噪能力。
2 實驗結果與分析
2.1 數據和參數設置
2.1.1 數據集
目前,還沒有公開的中醫舌色分類數據集。課題組與國內3 家中醫醫院合作,使用自行研發的中醫舌象分析儀[25]臨床采集舌圖像,通過前期對儀器各項參數的調整和測試,盡可能還原真實舌象,建立了3個舌色分類數據集。本文所用的3 個數據集SIPL-A、SIPL-B 和SIPL-C 是分別與北京市宣武中醫醫院、中國中醫科學院廣安門醫院和南昌市洪都中醫院合作建立的。每幅舌圖像都由經驗豐富的中醫專家手工標注。根據中醫理論和臨床實踐,每個數據集都包括舌色的4個主要類別,即淡紅色、紅色、暗紅色和紫色。每個數據集中的類別和數量如表1所示,3個數據集的部分示例樣本如圖3所示。

表1 三個數據集的類別和數量
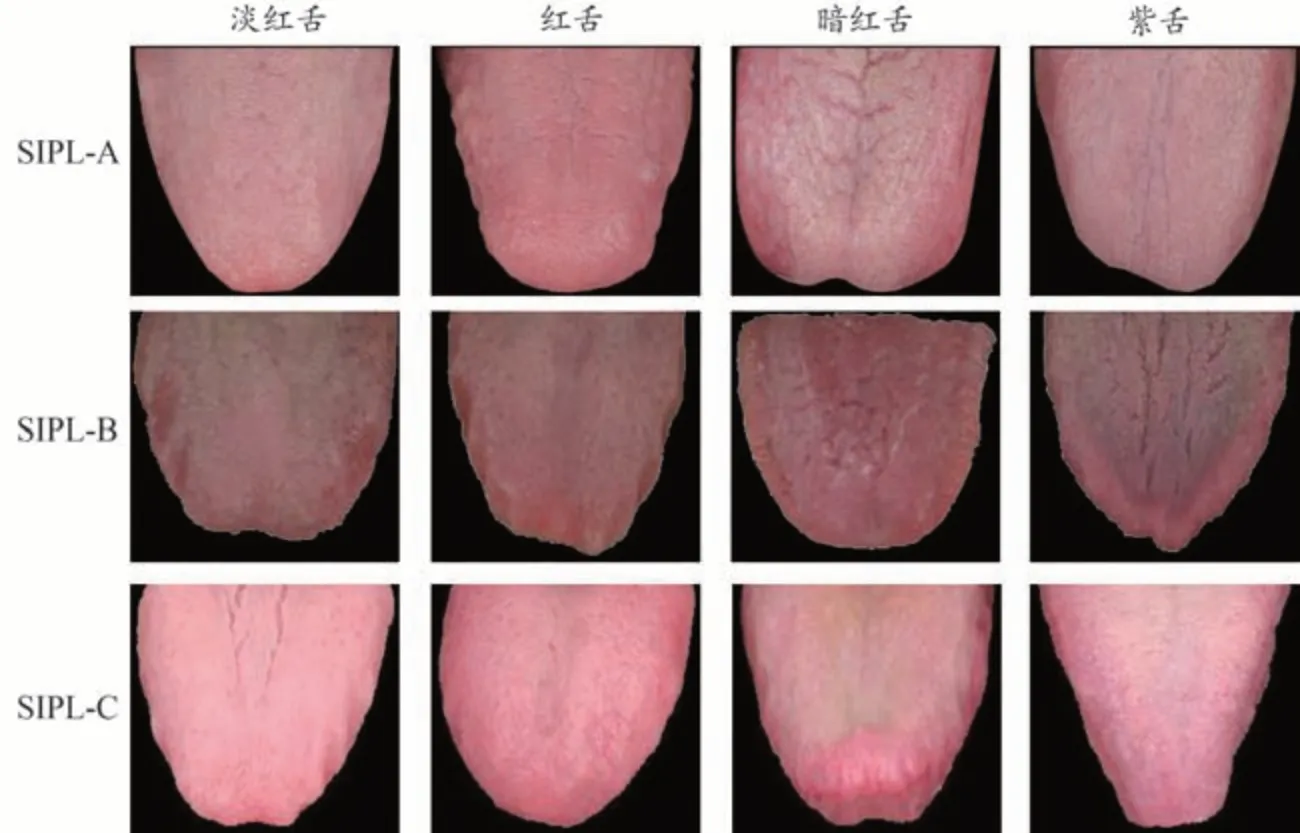
圖3 三個數據集的部分示例舌圖像
2.1.2 數據擴充
在實驗中,按照8∶2 的比例對每個數據集進行劃分,其中80%作為訓練數據,其余20%作為測試數據。此外,由多名中醫專家對測試數據進行重新標注,綜合專家的標注結果作為樣本標簽,以確保測試數據盡可能干凈。為了提高網絡的訓練性能并避免過擬合,進行了數據擴充,包括水平翻轉、隨機旋轉15°和其他幾何變換方式。
2.1.3 參數設置
為了公平比較,將提出的舌色分類網絡結構TRAM-ResNet18在PyTorch 平臺上進行了搭建和訓練測試,硬件配置為NVIDIA GeForce TX 1080 Ti GPU。模型訓練時,采用Adam 梯度下降算法,學習率設為0.001,Batch Size 設置為32,epoch 為200。對輸入的舌圖像進行分割,只保留舌體區域,去除背景干擾,然后將舌體大小統一調整為224×224。
2.2 評價準則
本文采用準確率、mAP(mean Average Precision)和Macro-F1 這3 個指標來評價舌色分類模型性能的好壞。3 個評價指標的取值范圍均為0-1,值越高,表明舌色分類性能越好。
準確率Acc表示所有測試樣本中被正確預測的樣本數量,定義為:
其中NC表示測試集中所有被正確預測分類的樣本數量,N表示測試集中樣本的總數量。
mAP是對所有類別的AP取平均值求得,即:
其中,n表示每一類的樣本個數,m表示類別數。
Macro-F1 是F1 得分在多分類問題的推廣,F1 的核心思想在于,它同時兼顧了精確率和召回率,用于測量不均衡數據的模型精度。Macro-F1 認定每個類別的權重都相同,不受數據不平衡的影響。Macro-F1的計算方式如下所示:
第i類的精確率和召回率分別表示為:
Macro-F1 的計算方式是先對各類別的精確率和召回率分別求平均:
然后根據下式計算得到Macro-F1:
2.3 不同注意力機制對分類結果的影響
為了驗證本文提出的舌色區域注意力機制對舌色分類性能的影響,將其與SENets(Squeeze-andexcitation networks)[26]、CBAM (Convolutional block attention module)[27]、ECA(Efficient channel attention)[28]等代表性的注意力機制進行了比較。所有實驗均以ResNet18 作為骨干網絡,加入各種注意力機制后,采用相同的配置對網絡進行訓練。在3個數據集上的對比結果如表2所示,其中基線表示僅采用ResNet18,未添加任何注意力機制。可以看出,與其他的注意力機制相比,本文針對舌色分類的具體特點設計的區域注意力機制,在準確率、mAP和Macro-F1上均有所提升,在三個數據集上,準確率分別提高了0.82%、0.14%和0.56%以上,mAP 分別提高了0.94%、1.08%和1.25%以上,Macro-F1 分別提高了0.83%、0.7%和0.89%以上,充分證明了舌色區域注意力機制的有效性。

表2 不同注意力機制的分類結果對比
2.4 不同分類網絡的對比結果
為了驗證TRAM-ResNet18網絡的分類性能,本文在SIPL-A 數 據 集 上,將 其 與LeNet[29]、AlexNet[30]、Vgg16[31]、ResNet18 和MobileNetV2[32]等代 表性 的 輕 型CNN 網絡結構進行了性能上的比較。所有網絡均在相同的配置下采用交叉熵損失函數進行訓練。實驗共重復了10次,計算其平均值和標準偏差作為實驗結果,如表3 所示。表中同時列出了每個網絡模型的參數量、準確率、mAP、Macro-F1 和標準偏差。可以看出,與其他輕型CNN 網絡結構相比,TRAM-ResNet18能獲得最高的準確率、mAP、Macro-F1 和最小的標準差。具體來說,與ResNet18 相比,網絡模型參數量僅增加了0.21 M,準確率提升了4.72%,mAP 提升了4.19%,Macro-F1 提升了6.2%。與MobileNet V2 網絡相比,雖然TRAM-ResNet18在模型參數量方面不占優勢,但是mAP 提高了4.74%,標準差也更小。綜合起來看,TRAM-ResNet18 可以在模型復雜度、分類準確性、穩定性和可靠性之間達到很好的折中。

表3 不同輕型網絡的分類精度和參數量的比較結果
2.5 不同損失函數在噪聲樣本下的分類結果對比
為了驗證SMCE的抗噪聲性能,本文在3個數據集上,將其分別與6 種代表性的損失函數進行了性能對比,具體包括CE、Label Smoothing、Bootstrapping-hard、Bootstrapping-soft、GCE、SCE 等。對 比 方 法 均 采 用ResNet18作為骨干網絡,訓練參數和設置均按2.1所述。表4列出了使用不同的損失函數得到的分類結果。

表4 不同損失函數在噪聲樣本下的的分類結果對比
從實驗結果中可以看出,采用本文提出的SMCE損失函數在3 個數據集上均取得了最優的分類性能。相比于其他的噪聲魯棒損失函數,本文提出的SMCE損失函數可以將準確率分別提高1.68%、1.26%和1.26以上,達到了94.09%、91.43%和93.22%;將mAP分別提高1.7%、2.26%和1.27%以上,達到了93.37%、90.89%和92.51%;將Macro-F1分別提高1.56%、1.52%和1.19%以上,達到了93.81%、91.26%和92.02%。尤其是與CE 損失函數相比,Macro-F1 指標分別提高了6.99%、5.44%和10.22%。這說明本文設計的SMCE 損失函數可以更有效地對噪聲樣本進行抑制,顯著提升了有噪樣本下的分類性能。
2.6 與其他噪聲樣本學習方法的分類結果對比
為了驗證本文方法在有噪樣本情況下的分類性能,在3 個數據集上,將其分別與4 種代表性的噪聲樣本學習方法進行了對比,包括PENCIL、AFM(Attentive Feature Mixup)[33]、Co-teaching、Co-teaching+等。對比方法的訓練設置均按2.1所述,表5列出了使用不同方法得到的分類結果。

表5 與不同有噪樣本下分類方法的對比
從實驗結果中可以看出,采用本文提出的方法在3 個數據集上均取得了最優的分類性能,與其他方法相比,本文方法可以將準確率分別提高2.59%、2.53%和1.06%以上,達到了94.96%、93.36%和93.92%;將mAP 分別提高2.58%、2.56%和1.54%以上,達到了94.53%、93.05% 和93.38%;將Macro-F1 分 別 提 高2.83%、2.49%和0.89%以上,達到了94.67%、93.16%和92.43%。這是因為本文方法不僅可以對噪聲樣本進行有效抑制,還結合舌色分類任務本身的特點,加強了對舌色區域特征的提取,從而提升了舌色分類性能。
2.7 消融實驗
為了驗證提出方法中各個部分的作用,本文在SIPL-A 數據集上進行消融實驗。基線方法以ResNet18 作為骨干網絡,使用CE 損失函數進行網絡的優化訓練。實驗中將加入TRAM 和SMCE 前后的分類性能做了對比。實驗結果如表6所示。
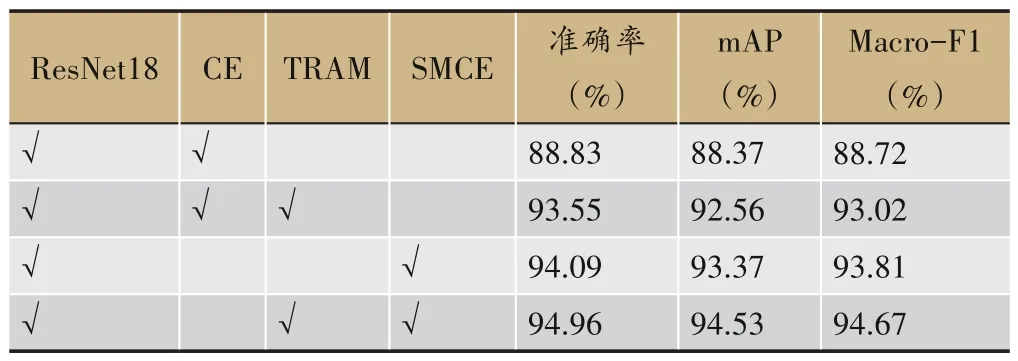
表6 消融實驗
從實驗結果中可以看出,采用基線方法,準確率、mAP 和Macro-F1分別僅為88.83%、88.37%和88.72%。采用TRAM 后,3 個指標分別提升了4.72%、4.19%和4.3%,達到了93.55%、92.56%和93.02%。這說明了針對舌色分類任務的具體特點設計注意力機制,可以顯著提升舌色分類的性能。而使用噪聲魯棒的損失函數SMCE 代替CE 后,3 個指標比基線分別提升了5.26%、5%和5.09%。而TRAM和SMCE同時使用,3個指標進一步提升了0.87%、1.16%和0.86%,達到了94.96%、94.53%和94.67%。這說明本文提出的舌色區域注意力機制和對稱修正交叉熵損失函數,均可以有效提升舌色分類的性能。
2.8 TRAM區域注意力的可視化結果
為了更直觀地展示TRAM 的有效性,本文采用Grad-CAM++類激活圖方法[34]分別對ResNet18 和TRAM-ResNet18網絡提取的特征進行了可視化處理,如圖4 所示。圖中給出了原始的舌圖像,以及分別采用ResNet18 和TRAM-ResNet18 網絡提取的特征可視化結果。從圖4 可以看出,ResNet18 網絡無法有效提取舌色區域的特征,網絡關注點往往集中在非舌色區域。很顯然,這樣的特征會導致舌色分類不夠準確。而TRAM-ResNet18 網絡則可以準確地對舌體區域的特征進行增強,對非舌體區域進行抑制,更符合醫生判定舌色時的診斷習慣,從而可以有效提升舌色分類性能。
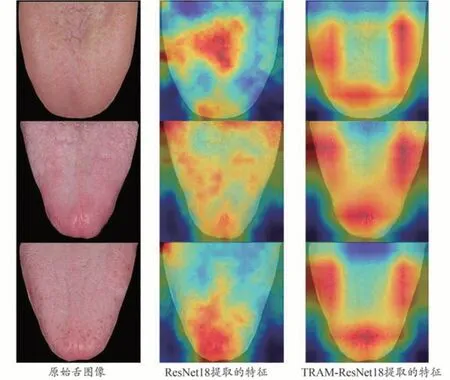
圖4 TRAM-ResNet18網絡特征可視化結果
3 結論
本文針對中醫舌色分類的特點,提出了一種基于區域注意力機制的有噪樣本下中醫舌色分類方法,以提高舌色分類的魯棒性和準確性。通過一系列實驗,可以得到如下結論:①針對舌色分類的具體特點,本文設計了TRAM,可以加強網絡對于舌色區域特征的提取與表達能力,從而有效提升了舌色分類性能;②針對舌色人工標注數據中存在的噪聲問題,本文設計了SMCE 損失函數,可以在網絡訓練過程對噪聲樣本起到很好的抑制作用,提升分類的魯棒性。
在自建的3個中醫舌色分類數據集上的實驗結果表明,本文提出的舌色分類方法能以較低的計算復雜度,顯著提升分類性能,準確率分別達到了94.96%、93.36%和93.92%,mAP 分別達到了94.53%、93.05%和93.38%,Macro-F1 分別達到了94.67%、93.16%和92.43%,可以滿足實際應用的需求。在未來的工作中,將增大數據集的規模,進一步提升分類準確率和模型的泛化能力,真正應用到實際臨床舌診中。
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
