基于LightGBM算法的機場聚合離場延誤預測
2024-02-06 04:11:28王笑天
西安航空學院學報 2024年1期
劉 博,王笑天,徐 晨
(民航中南空管設備工程(廣州)有限公司,廣州 51000)
0 引言
航班延誤是未來一段時間民航業所面臨的重要挑戰。空管因素、航空公司運營因素、空域容量供需不平衡等因素都有可能導致航班延誤。航班延誤可明顯影響民航系統的運行效率,所造成的經濟損失與社會影響不容忽視,因此,對航班延誤進行預測具有重要意義。
目前,航班延誤預測的研究方法主要有基于延誤傳播的方法和基于數據驅動的方法兩類。基于延誤傳播的方法側重于研究航空運輸網絡中的航班延誤傳播現象,并試圖基于該網絡的潛在機制來預測航班延誤。Beatty等[1]通過檢查初始延誤、延誤頻率和航班時刻表連通性來研究延誤的傳播。Xu及合作者[2-3]提出使用貝葉斯網絡對延誤的產生及機場緩解延誤的程序進行建模。Pyrgiotis等[4]開發排隊網絡模型來研究航班延誤的傳播。
近年來,基于數據驅動的方法成為相關研究的常用方法。該方法采用數據挖掘、統計分析或機器學習技術直接預測航班延誤,不需要探索延誤傳播機制。數據驅動的諸多相關模型及算法已被用于預測航班延誤,其中包括隨機森林算法、極端隨機樹和支持向量機等。Rebollo等[5]提出了基于網絡的空中交通延誤預測模型,該模型將時間和空間延誤狀態作為解釋變量,并使用隨機森林算法來預測離場延誤。羅赟騫等[6]建立了基于支持向量機回歸的航班到達延誤預測模型,并發現了到達延誤時間序列具有混沌特性。Khanmohammadi等[7]引入了多級輸入層人工神經網絡來預測進港航班的延誤。模型中使用了日期(包括月份和星期)、出發機場、計劃起飛時間和實際起飛時間等特征作為輸入變量。Belcastro等[8]使用并行算法預測航班進港延誤,同時考慮了航班信息(計劃起飛和到達時間)以及起飛和到達機場的天氣條件。徐海文等[9]利用深度神經網絡模型并結合時效信息,建立了離場航班延誤預測模型。陳昱君等[10]則利用自動編碼器改進了基本BP神經網絡算法,以進行離港航班延誤時間預測。
目前的研究大部分著眼于個體航班的延誤程度,對于旅客而言,關注個體航班的延誤程度便于對行程做出預先規劃,對于航司而言,單個航班的延誤程度對后續運行的經濟收益、公司信譽等都會有重要影響。而對于空中交通管理者而言,以機場、機場對乃至整個空中交通系統為統計對象的聚合延誤則更容易幫助其了解系統性延誤演化趨勢,以幫助做出科學決策[11]。
區別于以往重點將航班個體作為主體對象的延誤研究,本文將機場的航班聚合離場延誤作為預測研究的主體,并采用機器學習的方法進行分析,以期為空中交通管理者的流量管理決策提供依據。LightGBM算法是一種高效高性能分布式的基于決策樹算法的梯度提升框架,可用于排序、分類、回歸等多種機器學習任務中。本文以機場為統計對象,基于LightGBM算法建立了航班聚合離場延誤預測模型,并利用廣州白云機場(ZGGG)的歷史運行數據,將該模型與其他常用算法模型的預測結果進行對比,驗證模型的可靠性和有效性。
1 預測指標
本文聚焦于機場航班聚合離場延誤時間的預測,是對延誤持續時長的回歸(定量)預測,不是對延誤是否發生的分類(定性)預測。
預測指標Y為航班聚合離場延誤,即為每個預測時段內機場所有離場航班的平均延誤時間。本研究選取1 h為預測時段的時長,即Y為未來1小時內該機場所有離場航班預計離場延誤的平均值。為了使預測結果更具直觀性,將每個航班的離場延誤時長定為實際起飛時間晚于預計起飛時間的時長,不考慮航班延誤分類預測中定性判定延誤的15 min閾值。
2 數據預處理及特征選取
航班起降數據選取2017年3月1日—2018年2月28日廣州白云機場的歷史運行數據,共494 135條,其中,航班返航、備降及字段缺失嚴重等數據共8 567條,占總量的1.7%左右,這部分數據直接做刪除處理。
通過對選取數據的分析處理,結合以往關于航班離場延誤的研究,對一線人員的咨詢,提取出時間特征、航班計劃特征及延誤特征3類共14條與機場延誤相關的聚合特征,如表1所示。

表1 選取數據特征
其中,本時段累計需要進場/離場航班數,指的是機場本時段需滿足進場/離場航班的數量,是本時段計劃進場/離場航班的數量與本時段之前因延誤未完成進場/離場航班的數量之和。前一時段進場/離場航班的延誤數量,指的是前一時段實際進/離場時間減去計劃進/離場時間不小于15 min的航班數量。
將收集的數據分時段(1 h),按如上特征進行整合,得到結構為8 760×14的特征數據集。此外,考慮到機場00:00—06:00起降航班量較少,故選取06:00—24:00的航班起降數據作為樣本,最終得到6 570×14的特征數據集。預測指標為本時段離場航班的平均延誤時間,處理得到6 570×1的標簽數據集。由于各變量的量綱數據跨度較大,故對特征數據集及標簽數據集進行歸一化處理,目的是使各特征數據處于相同的數量級,消除它們之間的量綱差異對預測結果產生的影響。標準化處理公式為
(1)

3 預測模型建立
3.1 LightGBM算法原理
LightGBM算法是基于梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)的算法框架,GBDT與目前流行的Xgboost(eXtreme Gradient Boosting)算法相比,訓練速度更快,內存消耗更低,準確率更高[12]。LightGBM原理與Xgboost類似,通過損失函數的泰勒展開式來近似的表達殘差,并利用正則化項控制模型的復雜度
(2)

(3)
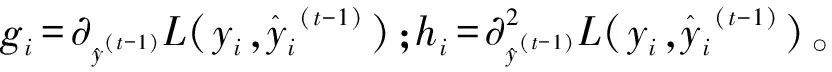
LightGBM算法采用leaf-wise節點分裂策略,只選擇分裂增益最大的結點,從而避免部分結點增益較小所帶來的損耗。同時在選擇增益最大結點進行分裂時,進行最大深度的約束,從而防止過擬合。二叉樹的分裂增益為
(4)
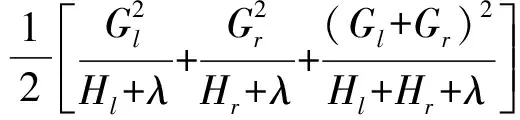
LightGBM算法采用基于直方圖的排序算法,將特征進行離散化處理,可減少占用內存,加快模型的訓練速度。其基本流程為:將數據集中的連續浮點數據進行統計,得到寬度為k的直方圖,根據直方圖各部分的統計區間將連續值離散化為k個離散值;分別以各離散值為索引遍歷直方圖中的數據,并累計統計量,尋找離散值中的最優分割點(圖1)。
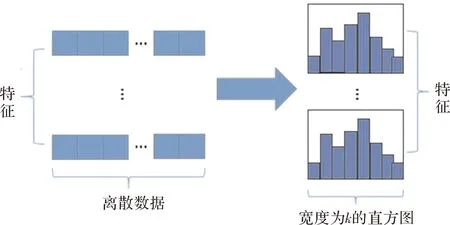
圖1 直方圖算法示意圖
3.2 建模方法
基于上述多類聚合特征數據,將機場的聚合離場延誤預測問題轉換為數據驅動的機器學習回歸預測問題。根據LightGBM算法,將表1中的14個特征數據輸入模型,以機場每小時的預計離場延誤時間作為標簽與預測指標,建立機場的聚合離場延誤預測模型,并對模型的預測結果進行測試與分析。
標準化處理之后所得數據用于模型的構建,采用10-折交叉驗證與網格搜索方法相結合的方式進行模型的訓練與調參工作。建模時將數據集合劃分為訓練集、驗證集和測試集三類。其中,訓練集用于訓練機器學習模型的參數,驗證集用于無偏的評估模型性能和調節超參數,測試集用于測試最終的模型性能。數據集劃分如圖2所示:隨機劃設20%原始數據為測試集,剩余的數據采用10-折交叉驗證的方法,90%為訓練集,10%為驗證集。
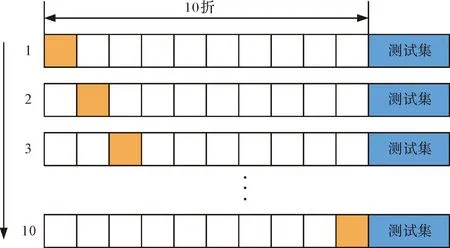
圖2 數據集劃分方式
在10-折交叉驗證的基礎上,利用網格搜索方式進行模型的超參數優化。此方法是將各個參數取值進行排列組合,然后將各組合用于模型訓練,并對模型結果進行評估的方法,嘗試所有的參數組合后,最優評估結果對應的參數即為最優參數。
4 實例分析
本研究以廣州白云機場為例,選取合適的預測指標,評估所建立模型的預測性能。
4.1 指標選取
選擇決定系數(R2)、均方誤差(MSE)和平均絕對值誤差(MAE)作為評價模型預測結果的性能指標。決定系數(R2),又稱擬合優度,是對模型解釋程度的度量,值越大表明自變量對因變量的解釋程度越高。MSE是估計值和實際值之間的偏差的平方和的比率。它可以測量誤差平方的平均值。MSE值越小表示預測精度越高。MAE是絕對誤差的平均值,可以更好地反映預測值誤差的實際情況。
(5)
(6)
(7)
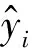
4.2 預測結果分析
將所收集的廣州白云機場2017年3月1日—2018年2月28日的歷史航班數據經預處理與特征提取,最終得到6 570×14的特征數據集與6 570×1的標簽數據集。根據圖2進行數據集的劃分,對廣州白云機場的航班聚合離場延誤進行回歸預測。
根據網格搜索超參數優化結果,模型的主要參數迭代次數為500次,學習率learning_rate為0.1,單棵決策樹上的葉子數量num_leaves=27,最大深度max_depth=10,其他參數均取默認參數。最終預測結果的決定系數R2值為0.866 7,均方誤差MSE為53.93,平均絕對值誤差MAE為4.77 min。
預測結果可視化。為保證結果的可靠性,選取建模中未用到的數據進行預測,并對結果進行可視化分析。選取2018年3月31日的航班數據,經處理后進行預測,預測結果如下圖3所示。圖中縱軸表示每個時段內機場所有離場航班的平均延誤時間。由圖3可見,預測值與實際值的波動走向基本一致,當天大部分時段的預測誤差均保持在7 min以內。

圖3 2018年3月31日延誤時間預測和實際結果
提取在預測過程中不同特征體現出的特征重要度示于圖4。由圖4可知,“本時段累計需要離場航班數”約占總重要特征的20%,占比最大,說明機場的離場航班滯留情況是對離場延誤影響最大的因素。

圖4 不同特征的重要性
4.3 與其他算法對比
為進一步對本模型的預測性能進行評估,選取較為常用的支持向量機、隨機森林、極端隨機樹算法進行比較,不同算法均按照相同的方法流程進行了數據處理與建模。各算法在測試集上的表現如表2所示。由對比結果可知,本文算法在決定系數R2、均方誤差MSE和平均絕對值誤差MAE三個指標的表現上均是最優的,且在保持良好性能的同時,具有更高的運行效率。LightGBM算法對6 570條數據進行處理,只花費了0.76 s時間,這一速度比支持向量機算法快17倍,比隨機森林算法快33倍,比極端隨機樹算法快20倍。

表2 不同算法的實驗結果對比
5 結論
本文以機場為研究對象,提出了一種預測機場聚合離場延誤的方法,基于時間特征、飛行計劃特征和延誤特征三類與機場相關的聚合特征建模。結合實際航班數據,基于LightGBM算法進行對延誤時間進行預測,結果表明:
(1)在1 h的時間窗口內,模型預測準確度可以達到0.866 7,平均絕對值誤差僅為4.77 min,且相較于其他算法而言,本文所提模型運行效率明顯提升;
(2)預測模型從機場角度預測航班的離場延誤,可提醒機場管理人員、空中交通管制員和乘客有效應對機場及附近空域系統的擁堵情況。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
