基于灰色關聯規則算法的電力營銷信息多標簽分類方法研究
2024-02-09 00:00:00趙琪鄭欣桐
消費電子 2024年11期
關鍵詞:電力營銷
【關鍵詞】灰色關聯規則算法;電力營銷;營銷信息;多標簽分類;分類方法
引言
大數據時代的來臨,使得我國電力企業的營銷信息呈現出爆炸式增長態勢。多標簽分類是處理具有多個標簽的樣本數據的重要技術,可以對電力營銷信息進行更細致、更全面的分析,為電力企業的市場策略制定和優化提供有力支持。近年來,隨著人工智能和機器學習技術的不斷發展,越來越多研究者開始關注如何將這些先進技術應用于多標簽分類領域。楊峰等(2023)提出了一種基于量子競爭決策算法的電力營銷信息多標簽分類方法,旨在提高分類的穩定性和效率,但是該方法涉及量子計算和深度學習的技術,需要專業的知識和經驗。[1]任彥凝等(2024)對一種融合標簽信息的多標簽文本分類方法進行研究,但是在處理多個標簽之間的關系和語義信息時,該方法的計算復雜度相對較高。[2]這可能導致在處理大規模文本數據集時,訓練和預測的速度較慢,需要更多的計算資源和時間。因此,本文設計了一種基于灰色關聯規則算法的電力營銷信息多標簽分類方法,期望能夠解決傳統分類方法在處理高維度、非線性的電力營銷信息時存在的問題,促進電力行業的可持續發展。
一、電力營銷信息文本數據預處理
實際采集過程中,電力營銷數據的質量往往難以得到完全保障。本文首要任務就是對電力營銷信息文本數據進行預處理[3]。首先,為消除原始電力營銷信息文本數據中的噪聲,本文引入詞頻—逆文檔頻率(Term Frequency-Inverse Document Frequency,TF-IDF)算法對數據進行清洗處理。該算法先通過計算每個詞在文檔中的出現頻率以及在整個語料庫中的稀有程度,來衡量一個詞在文檔中的重要性,如式(1)所示。
式中,P0(Ci)表示電力營銷信息文檔C中第i個詞的TF-IDF值,P1(Ci)表示電力營銷信息文檔C中第i個詞的詞頻,P2(C)表示電力營銷信息文檔C的逆文檔頻率,iCn表示電力營銷信息文檔C中第i個詞出現的次數,NC表示電力營銷信息文檔C中詞的數量,M表示語料庫中電力營銷信息文檔的數量,iCm表示語料庫中包含詞i的電力營銷信息文檔數量。技術人員根據電力營銷信息文本數據的實際情況,設定一個合理閾值對式(1)所求TF-IDF值進行過濾,將低于閾值的詞(噪聲詞)去除,以此提高電力營銷信息文本數據的純凈度。
此外,由于我國電力企業的營銷數據可能來源于多個系統或部門,如客戶管理系統、交易記錄系統、服務反饋系統等,這些數據在格式、單位和量綱上存在一定差異,所以還需要對原始不同源頭的電力營銷信息文本數據進行集成處理[4]。本文先通過數據映射來建立各數據源之間的連接關系,映射時主要采用XSLT語言編寫數據源代碼,并利用XML文檔翻譯代碼,然后按照上述映射關系進行不同來源數據的連接整合,形成一個統一的數據集。總之,通過數據清洗與數據集成,電力營銷信息文本數據的質量得到顯著提升,為后續多標簽分類提供堅實的數據基礎。
二、通過灰色關聯規則算法提取數據關鍵特征
灰色關聯規則算法作為一種基于灰色系統理論的數據分析方法,在電力營銷中,引入該算法可以識別并提取出與電力營銷信息最為相關的特征[5],有助于從海量文本信息數據中篩選出對分類結果更具決定性影響的特征。
首先,技術人員需要確定電力營銷信息數據的參考序列和比較序列。其中,參考序列通常是反映系統行為特征的數據序列,所以本文將電力營銷文本信息的標簽當作參考序列,設為(){}001,2,XxttT==???,其中t為時刻,T為序列個數;比較序列則是影響系統行為的因素序列,所以本文將電力營銷文本信息的關鍵特征當作比較序列,設為(){}1,2,iiXxttT==???。
然后,技術人員需要進行參考與比較序列之間關聯度的計算,主要用于衡量二者之間的關聯程度。本文采用灰色關聯規則算法中的鄧氏關聯度計算方法,如式(4)所示。
式中,η(t)表示電力營銷文本信息數據特征和電力營銷文本信息標簽之間的灰色關聯系數;μ表示分辨系數,一般取值為0.5。在根據式(4)計算出每一個比較序列與參考序列在各個時刻點的關聯度之后,按從大到小順序排序,即可得到電力營銷信息的灰色關聯序列,再根據以下相應決策規則確定關鍵特征:提取的關鍵特征而具有最大灰色關聯度的規則;提取的關鍵特征需和其他特征的灰色關聯度差值大于設定閾值的規則。因此,根據實際情況選擇合適閾值,基于上述規則進行電力營銷信息文本數據關鍵特征的判定與提取,作為后續多標簽分類模型的輸入。
三、基于關鍵特征的信息多標簽分類
在根據上述步驟提取出電力營銷信息文本數據的關鍵特征后,技術人員即可根據該特征進行信息的多標簽分類[6]。綜合考慮電力營銷信息的特點,本文構建了一個結合Transformer模型與生成式主題模型(Latent Dirichlet Allocation,LDA)主題模型的TRM-LDA多標簽分類模型[7]。首先,技術人員把提取的關鍵特征輸入TRM-LDA模型,LDA模塊會通過分析文本中詞的共現關系,發現潛在的主題結構,以此生成待匹配標簽,如式(5)所示:
四、仿真實驗
(一)實驗數據
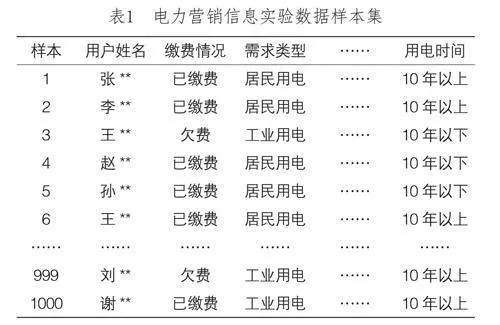
為了對本文提出的電力營銷信息多標簽分類方法進行有效性驗證,以下引入楊峰等(2023)和任彥凝等(2024)的兩種方法,展開仿真對比實驗。本次仿真對比實驗中以某電力企業在2020年期間的電力營銷信息為實驗數據,部分樣本如表1所示。
以表1中的1000組電力營銷信息為實驗數據樣本,分別采用本文方法、楊峰等(2023)方法和任彥凝等(2024)方法對實驗數據樣本進行多標簽分類,對比不同方法所得的分類結果。
(二)仿真結果
在完成三種方法的多標簽分類任務后,為評估各方法在分類中的性能,本文引入宏平均1γ與微平均2γ作為實驗指標,其計算公式如式(7)所示:
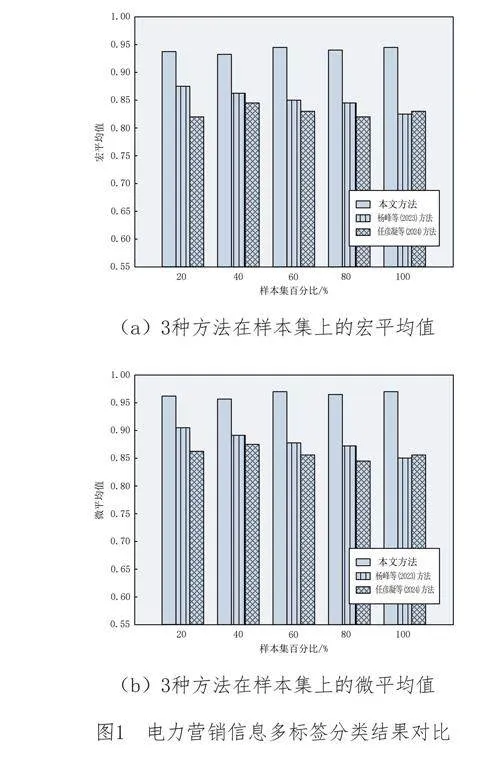
式中,F1(i)表示電力營銷信息標簽i分類結果的F1值,I表示電力營銷信息的整體標簽集合,α表示電力營銷信息多標簽分類結果的準確率,β表示電力營銷信息多標簽分類結果的召回率。在多標簽分類任務中,宏平均和微平均是度量分類性能的關鍵指標,其值越大,則分類性能越優良。為了避免實驗結果的偶然性,實驗從表1所示的樣本集中,隨機抽取不同百分比的數據進行多標簽分類。在經過計算和統計之后,各方法下的分類結果如圖1所示:
結語
本文提出了一種基于灰色關聯規則算法的電力營銷信息多標簽分類方法,文中通過灰色關聯算法提取了預處理后的電力營銷信息文本數據的關鍵特征,并利用TRM-LDA模型實現了對電力營銷信息的有效分類。未來的研究可進一步完善和優化本文提出的分類方法,為電力企業的營銷決策提供更有力的支持。
猜你喜歡
現代營銷·學苑版(2016年10期)2016-12-12 12:52:45
中國科技縱橫(2016年17期)2016-11-30 11:12:37
中國科技縱橫(2016年17期)2016-11-30 11:12:12
中國新技術新產品(2016年22期)2016-11-29 06:28:19
現代經濟信息(2016年25期)2016-11-24 04:41:02
企業技術開發·中旬刊(2016年10期)2016-11-12 15:11:56
中國科技博覽(2016年22期)2016-11-01 17:29:45
中國科技博覽(2016年19期)2016-10-19 15:06:08
中國科技博覽(2016年19期)2016-10-19 12:35:49
