基于深度學(xué)習(xí)的炸點(diǎn)圖像識別與處理方法
2024-03-11 11:11:38劉佳音李翰山張曉倩
探測與控制學(xué)報 2024年1期
劉佳音,李翰山,張曉倩
(1.西安工業(yè)大學(xué)兵器科學(xué)與技術(shù)學(xué)院,陜西 西安 710021;2.西安工業(yè)大學(xué)電子信息工程學(xué)院,陜西 西安 710021)
0 引言
隨著實戰(zhàn)化訓(xùn)練的不斷深入,實彈射擊訓(xùn)練不斷貼近實戰(zhàn),其形成的炸點(diǎn)可用于估計擊中敵方火力位置和評估炮兵射擊訓(xùn)練效果等[1],因此,尋找一種可以實時準(zhǔn)確識別炸點(diǎn)的方法,有助于驗證武器系統(tǒng)的整體性能,而且對現(xiàn)代數(shù)字化戰(zhàn)爭具有重要意義。
當(dāng)前炸點(diǎn)識別方法常用的有聲測法、激光掃描法、雷達(dá)探測法和圖像識別法。文獻(xiàn)[2]利用聲學(xué)測量設(shè)備求解連發(fā)彈丸落炸點(diǎn),采用空域搜索算法求解彈丸的炸落點(diǎn)三維坐標(biāo),具有較好的求解效果。文獻(xiàn)[3]針對聲源被動測向的傳統(tǒng)方法存在精度低和結(jié)構(gòu)單一的問題,利用不規(guī)則排列聲傳感器接收到聲信號的時間差,采用最小二乘原理計算聲源方位。文獻(xiàn)[4]針對彈目交會過程中難以精確控制炸點(diǎn)的問題,采用置于彈丸頭部橫向旋轉(zhuǎn)掃描的線陣激光引信作為探測裝置,并利用Monte-Carlo算法對彈目交會過程進(jìn)行數(shù)學(xué)統(tǒng)計,計算分析破片數(shù)目和目標(biāo)有效交會面積對目標(biāo)毀傷的影響,最終確定引信最佳炸點(diǎn)。文獻(xiàn)[5]研究了炸點(diǎn)和普通目標(biāo)回波信號經(jīng)動目標(biāo)檢測(MTD)處理后的特征,利用炸點(diǎn)目標(biāo)與普通目標(biāo)的多普勒分布差的區(qū)別進(jìn)行目標(biāo)識別,并取得了很好的效果。文獻(xiàn)[6]提出采用基于定目標(biāo)為參照的雙面陣相機(jī)交匯攝像法來測量近炸引信對空中目標(biāo)引炸的炸點(diǎn)位置,利用交匯相機(jī)的空間幾何關(guān)系、圖像處理技術(shù)與模擬目標(biāo)實際尺寸,計算彈丸炸點(diǎn)相對模擬目標(biāo)的空間三維坐標(biāo)。文獻(xiàn)[7]利用高速相機(jī)幀頻高、布站方便、多鏡頭靈活更換的優(yōu)點(diǎn),提出基于高速相機(jī)的近地炸點(diǎn)三維坐標(biāo)測試方法,利用萊卡定位系統(tǒng)實際測量炸點(diǎn)坐標(biāo)進(jìn)行誤差分析。
聲測法測試精度較低且易受噪聲影響;激光掃描法投入成本較高且實時性差;雷達(dá)探測法耗費(fèi)巨大且需要搭建龐大系統(tǒng)。而圖像識別技術(shù)投入成本低,定位準(zhǔn)確度高,且不受風(fēng)力、風(fēng)向、溫度、地質(zhì)條件等影響,因此利用圖像識別技術(shù)準(zhǔn)確捕捉炸點(diǎn)爆炸產(chǎn)生的火焰,從而準(zhǔn)確識別炸點(diǎn)位置成為目前的研究熱點(diǎn)。由于圖像識別技術(shù)針對炸點(diǎn)位置的識別主要依賴于所檢測到的炸點(diǎn)輪廓精確度,所以需要對爆炸火焰的外部輪廓進(jìn)行高精度分割。
基于深度學(xué)習(xí)的語義分割算法主要采用深度神經(jīng)網(wǎng)絡(luò)對圖像進(jìn)行細(xì)粒度特征提取,并標(biāo)記圖像中每個像素點(diǎn),分割出目標(biāo)區(qū)域[8]。文獻(xiàn)[8]針對炮兵對抗訓(xùn)練系統(tǒng)中炸點(diǎn)圖像目標(biāo)捕捉的問題,提出一種基于YOLACT 的炸點(diǎn)區(qū)域快速識別及分割方法,根據(jù)區(qū)域信息得到炸點(diǎn)中心坐標(biāo)。文獻(xiàn)[9]針對目前靶場炮彈火焰圖像分割算法對火焰邊界分割效果差而導(dǎo)致定位精度下降的問題,提出改進(jìn)PSPNet的炮彈火焰分割PSP_FPT算法,實現(xiàn)對炮彈火焰目標(biāo)的高精度分割。文獻(xiàn)[10]為了實現(xiàn)炮口火焰與復(fù)雜背景環(huán)境的分離,引入深度可分卷積與殘差結(jié)構(gòu),對U-Net語義分割模型進(jìn)行優(yōu)化。
上述基于深度學(xué)習(xí)的語義分割網(wǎng)絡(luò)相較于傳統(tǒng)方法具有更好的魯棒性與泛化性,能夠克服目標(biāo)周圍復(fù)雜環(huán)境以及光照強(qiáng)度的影響,但分割效果依賴網(wǎng)絡(luò)層數(shù)。若層數(shù)過少,無法提取到更深層、更關(guān)鍵的分割特征信息;若層數(shù)過多,則容易增大網(wǎng)絡(luò)運(yùn)算量,造成過擬合。
因此提出一種改進(jìn)的U-Net網(wǎng)絡(luò)。將主干特征提取網(wǎng)絡(luò)換為層數(shù)更深的ResNet50,且為了解決前景與背景類別不平衡問題,結(jié)合FocalLoss與DiceLoss函數(shù),并采用自適應(yīng)矩估計函數(shù)增加標(biāo)簽圖像與分割圖像之間的相似度,最終對改進(jìn)U-Net網(wǎng)絡(luò)進(jìn)行訓(xùn)練和測試,獲取最佳的網(wǎng)絡(luò)性能,實現(xiàn)炸點(diǎn)圖像分割及后續(xù)圖像處理。
1 炸點(diǎn)圖像獲取及位置信息分析
本文采用高速攝像機(jī)對炸點(diǎn)爆炸過程進(jìn)行拍攝,獲得起爆時刻至爆炸結(jié)束的圖像全過程,由于最終要獲取炸點(diǎn)位置,而爆炸瞬間與爆炸后期所拍攝到的炸點(diǎn)圖像對炸點(diǎn)位置的獲取影響很大,因此要對拍攝的爆炸圖像進(jìn)行分類篩選。將炸點(diǎn)爆炸瞬間的幾幀圖像作為選取的目標(biāo),因為此刻拍攝的炸點(diǎn)圖像受周圍環(huán)境干擾較小,且炸點(diǎn)形狀一般呈現(xiàn)扇形或不規(guī)則圓形,特征較為一致,能夠準(zhǔn)確地反映炸點(diǎn)位置;而當(dāng)炸點(diǎn)爆炸一段時間后,由于受風(fēng)向及炸點(diǎn)擴(kuò)散等影響,相機(jī)拍攝的炸點(diǎn)圖像會發(fā)生很大變化,若對此刻的炸點(diǎn)圖像作后續(xù)圖像處理,其獲取的炸點(diǎn)位置偏差較大。GoogLeNet是基于Inception模塊的深度神經(jīng)網(wǎng)絡(luò)模型,Inception模塊將多個卷積與池化操作并列組成網(wǎng)絡(luò)結(jié)構(gòu),在相同的計算量下提取更多的特征,提高網(wǎng)絡(luò)訓(xùn)練效果。本文利用GoogLeNet對所拍攝的近景及遠(yuǎn)景多序列爆炸圖像進(jìn)行分類,首先將拍攝的炸點(diǎn)爆炸過程分為多幀圖像處理;其次根據(jù)炸點(diǎn)爆炸瞬間形成的炸點(diǎn)形狀特征進(jìn)行圖像分類,即將不包含炸點(diǎn)形狀特征的圖像定義為“未起爆”,將包含炸點(diǎn)形狀特征的圖像定義為“爆炸瞬間”,將包含炸點(diǎn)形狀特征及煙塵特征的圖像定義為“爆炸后期”;然后將已定義的多幀圖像作為GoogLeNet網(wǎng)絡(luò)的輸入,對其訓(xùn)練并測試,最后得出分類結(jié)果。分類結(jié)果如圖1、圖2所示,網(wǎng)絡(luò)訓(xùn)練后的分類準(zhǔn)確率及損失如圖3所示。

圖1 近景場景下炸點(diǎn)圖像分類結(jié)果Fig.1 Classification results of fried point images in close-up scenes

圖2 遠(yuǎn)景場景下炸點(diǎn)圖像分類結(jié)果Fig.2 Classification results of fried point images in long-range scenes
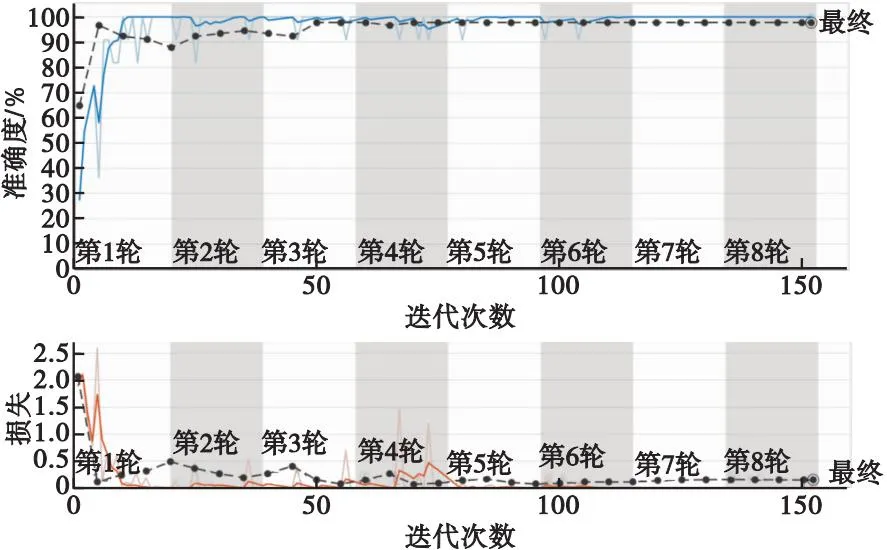
圖3 網(wǎng)絡(luò)分類準(zhǔn)確率及損失Fig.3 Network classification accuracy and loss
根據(jù)GoogLeNet網(wǎng)絡(luò)分類結(jié)果,提取“爆炸瞬間”炸點(diǎn)圖像作為炸點(diǎn)位置信息獲取的樣本數(shù)據(jù)集。基于樣本數(shù)據(jù)集,先利用改進(jìn)U-Net分割網(wǎng)絡(luò)對炸點(diǎn)圖像進(jìn)行分割,再采用邊緣提取算法對分割出的炸點(diǎn)圖像進(jìn)行輪廓提取及最小二乘法輪廓擬合,獲取圖像中的炸點(diǎn)位置信息,最后采用攝像機(jī)成像原理將二維炸點(diǎn)坐標(biāo)信息轉(zhuǎn)換為三維炸點(diǎn)位置信息。假設(shè)圖像中炸點(diǎn)的像素坐標(biāo)為(u,v),圖像坐標(biāo)為(x,y),相機(jī)坐標(biāo)為(X,Y,Z),空間坐標(biāo)為(U,V,W),利用二維至三維坐標(biāo)轉(zhuǎn)換公式,將獲取到的炸點(diǎn)圖像二維坐標(biāo)計算得出炸點(diǎn)空間坐標(biāo)。
(1)
(2)
(3)
(4)
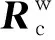

f=185 mm,Z=20 000 mm。
為了更加接近炸點(diǎn)空間真實坐標(biāo)值,利用改進(jìn)U-Net網(wǎng)絡(luò)對樣本數(shù)據(jù)集訓(xùn)練測試,提高炸點(diǎn)分割精度,獲取更為準(zhǔn)確的炸點(diǎn)二維坐標(biāo)。
2 改進(jìn)U-Net網(wǎng)絡(luò)分割炸點(diǎn)圖像模型的構(gòu)建
面對炸點(diǎn)的復(fù)雜環(huán)境,本文利用ResNet50代替原網(wǎng)絡(luò)中的特征提取網(wǎng)絡(luò),通過增加網(wǎng)絡(luò)層數(shù)來提取更多的目標(biāo)特征信息;為了解決圖像分割中前景與背景類別不平衡問題,本文采用以焦點(diǎn)損失函數(shù)FocalLoss為主函數(shù),DiceLoss為輔函數(shù)的多重?fù)p失函數(shù)優(yōu)化網(wǎng)絡(luò)模型;同時為了縮小實際輸出值與樣本真實值的差距,增加分割標(biāo)簽圖像與分割圖像之間的相似度,在反向傳播更新權(quán)值參數(shù)階段,選用自適應(yīng)矩估計函數(shù)作為優(yōu)化函數(shù)[11],動態(tài)地調(diào)整學(xué)習(xí)率,尋找最優(yōu)權(quán)重參數(shù)。改進(jìn)U-Net網(wǎng)絡(luò)結(jié)構(gòu)如圖4所示。
2.1 改進(jìn)主干特征提取網(wǎng)絡(luò)
ResNet網(wǎng)絡(luò)被廣泛應(yīng)用于各種特征提取場合中,深度學(xué)習(xí)網(wǎng)絡(luò)層數(shù)越深,特征表達(dá)能力越強(qiáng),但當(dāng)深度達(dá)到一定程度后,分類性能不但不會提高,還會導(dǎo)致網(wǎng)絡(luò)收斂更加緩慢,準(zhǔn)確率也會降低,即使把數(shù)據(jù)集擴(kuò)增,解決過擬合問題,網(wǎng)絡(luò)的分類性能和準(zhǔn)確度也不會提高[12],ResNet50網(wǎng)絡(luò)層次結(jié)構(gòu)如表1表示。

表1 ResNet50網(wǎng)絡(luò)層次結(jié)構(gòu)Tab.1 ResNet50 network hierarchy
由表1可知,ResNet50經(jīng)過了4個Block,每一個Block中分別有3,4,6三個Bottleneck模塊,每一個Bottleneck模塊里包含兩種Block。第一種是Conv Block,如圖5(a)所示,通過1×1卷積核對特征圖像先進(jìn)行降維操作,再用3×3卷積核做一次卷積操作,最后通過1×1卷積核恢復(fù)圖像維度,后續(xù)傳入BN層與ReLu層,虛線處采用256個1×1的卷積網(wǎng)絡(luò),將maxpool的輸出降維;另一種是Identity Block,如圖5(b)所示,即用實線連接,不經(jīng)過卷積網(wǎng)絡(luò)降維操作,直接將輸入加到最后的1×1卷積輸出上,再經(jīng)過后續(xù)的Block,進(jìn)行平均池化操作和全連接操作,用Softmax實現(xiàn)回歸。圖像降維卷積處理過程如圖6所示。
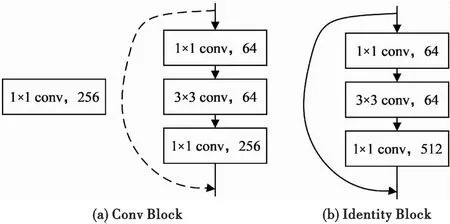
圖5 結(jié)構(gòu)圖Fig.5 Structure diagram

圖6 圖像降維卷積處理過程Fig.6 Image dimensionality reduction convolution processing
2.2 優(yōu)化損失函數(shù)
在語義分割中存在大量前景與背景類別不平衡問題,使用單一損失函數(shù)往往趨向于捕捉炸點(diǎn)占比更大的樣本,而炸點(diǎn)占比小、背景占比大的樣本容易被損失函數(shù)過濾掉,為解決該問題,本文采用以焦點(diǎn)損失函數(shù)FocalLoss為主函數(shù),DiceLoss為輔函數(shù)的多重?fù)p失函數(shù)優(yōu)化網(wǎng)絡(luò)模型。
DiceLoss是計算集合的相似度函數(shù)[13],用于監(jiān)督實際輸出值與樣本真實值之間的相似度,數(shù)值越小越相似,預(yù)測效果越理想,使用 DiceLoss 可以在初期加快收斂,提升模型訓(xùn)練效率。同時采用以上兩種損失函數(shù)監(jiān)督網(wǎng)絡(luò),可以從不同角度捕捉預(yù)測過程中的不足和損失,在定位全局最優(yōu)的結(jié)果下得到局部最優(yōu),提高泛化性。損失函數(shù)計算公式為
(5)
LFocal(pj)=-a(1-pj)γlog(pj),
(6)
LALL=LFocal(pj)+λ×LDice,
(7)
式中:|X|表示其標(biāo)簽值像素個數(shù);|Y|表示預(yù)測值像素個數(shù);|X∩Y|表示標(biāo)簽值和預(yù)測值交集的像素數(shù);-log(pj)為初始交叉熵?fù)p失函數(shù);a為類別區(qū)間(0或1二分類)的權(quán)重參數(shù);(1-pj)γ為簡單/困難樣本調(diào)節(jié)因子;γ為聚焦參數(shù)[14];λ為經(jīng)驗參數(shù),用于調(diào)節(jié)兩個損失函數(shù)之間的權(quán)重。
為了減小損失函數(shù)數(shù)值,縮小實際輸出值與樣本真實值的差距,增加分割標(biāo)簽圖像與分割圖像之間的相似度,在反向傳播更新權(quán)值參數(shù)階段,選用自適應(yīng)矩估計函數(shù)作為優(yōu)化函數(shù),利用梯度的一階矩估計和二階矩估計,動態(tài)地調(diào)整學(xué)習(xí)率,尋找到最優(yōu)的權(quán)重參數(shù),公式如式(8)—式(12)所示。
mt=μ×mt-1+(1-μ)×gt,
(8)
(9)
(10)
(11)
(12)
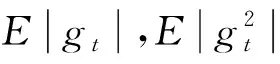
3 實驗結(jié)果與分析
3.1 實驗環(huán)境與參數(shù)設(shè)置
本文實驗操作環(huán)境為Windows10系統(tǒng),CPU參數(shù)為16 vCPU Intel(R) Xeon(R) Platinum 8350C CPU @ 2.60 GHz,42 GB內(nèi)存,RTX 3080 Ti(12 GB)×1。網(wǎng)絡(luò)框架基于PyTorch 1.10.0,Cuda 11.3,使用Python 3.8版本進(jìn)行編程實現(xiàn),網(wǎng)絡(luò)初始參數(shù)設(shè)置如表2所示。

表2 網(wǎng)絡(luò)初始參數(shù)Tab.2 Network initial parameters
3.2 炸點(diǎn)圖像標(biāo)簽數(shù)據(jù)集的構(gòu)建
本文利用Labelme軟件對數(shù)據(jù)集進(jìn)行輪廓標(biāo)注,形成名稱為boom的標(biāo)簽,并保存成json格式。以VOC2007數(shù)據(jù)集為格式標(biāo)準(zhǔn),將json格式的數(shù)據(jù)轉(zhuǎn)換為png格式的圖片,單獨(dú)保存至名為“SegmentationClass”的文件夾,同時將原始炸點(diǎn)數(shù)據(jù)集保存至名為“JPEGImages”的文件夾,確保后續(xù)進(jìn)行網(wǎng)絡(luò)訓(xùn)練的文件路徑統(tǒng)一。利用Labelme軟件標(biāo)注標(biāo)簽示例圖如圖7所示。

圖7 炸點(diǎn)標(biāo)簽圖Fig.7 Fried point label
3.3 實驗結(jié)果分析
3.3.1基于改進(jìn)U-Net網(wǎng)絡(luò)的圖像分割結(jié)果評價指標(biāo)
本文選用PA,MPA,MIOU三個評價指標(biāo)來評估改進(jìn)U-Net網(wǎng)絡(luò)模型的性能。PA表示分類正確的像素占總像素的比例,PA值越高,說明分割結(jié)果越精確。MPA表示圖像整體分割效果,MPA值越高,說明模型對所有類別的分割效果越好。MIOU表示整個圖像中所有類別分割結(jié)果的平均質(zhì)量,MIOU值越高,說明分割結(jié)果越準(zhǔn)確。其計算公式為
(13)
(14)
(15)
式中:Nij代表真實值為i,被預(yù)測為j的數(shù)量;k代表分割類別數(shù);Nii為真正,代表正確分為該類的像素數(shù)量;Nij為假正,表示他類被分為該類的像素數(shù);Nji為假負(fù),表示該類被誤分為他類的像素數(shù)。式中先將背景和炸點(diǎn)分別作為正樣本求出評價指標(biāo),再取平均值便可得到所有類的平均評價指標(biāo),式中正樣本為炸點(diǎn)[15]。
3.3.2基于改進(jìn)U-Net網(wǎng)絡(luò)的圖像分割結(jié)果
為了驗證本文提出的改進(jìn)U-Net分割網(wǎng)絡(luò)在圖像分割精度上有一定的提升,本文選用原始U-Net分割網(wǎng)絡(luò)與U-Net+ResNet50,U-Net+優(yōu)化函數(shù)以及改進(jìn)U-Net網(wǎng)絡(luò)進(jìn)行測試,使用相同的炸點(diǎn)數(shù)據(jù)集和初始網(wǎng)絡(luò)權(quán)重參數(shù)進(jìn)行訓(xùn)練,然后對訓(xùn)練好的網(wǎng)絡(luò)模型,用炸點(diǎn)原始圖像進(jìn)行對比驗證,實驗結(jié)果如圖8所示。

圖8 實驗結(jié)果對比圖Fig.8 Comparison of experimental results
由圖8可以看出:原始U-Net網(wǎng)絡(luò)對炸點(diǎn)的分割效果不夠理想,對比標(biāo)簽圖像會有毛刺出現(xiàn);特征提取主干為ResNet50的U-Net網(wǎng)絡(luò),由于增加了網(wǎng)絡(luò)層數(shù),因此可以獲得炸點(diǎn)更深層的細(xì)節(jié)信息,但對比標(biāo)簽圖像,其相似度有所下降;加入優(yōu)化函數(shù)后的U-Net網(wǎng)絡(luò),對比標(biāo)簽圖像其分割效果相對較好,但所提取的圖像信息仍有不足;改進(jìn)U-Net網(wǎng)絡(luò)融合上述兩個改進(jìn)點(diǎn),對比標(biāo)簽圖像,分割效果更好,有利于后續(xù)的目標(biāo)邊緣提取。其實驗結(jié)果對比如表3所示。
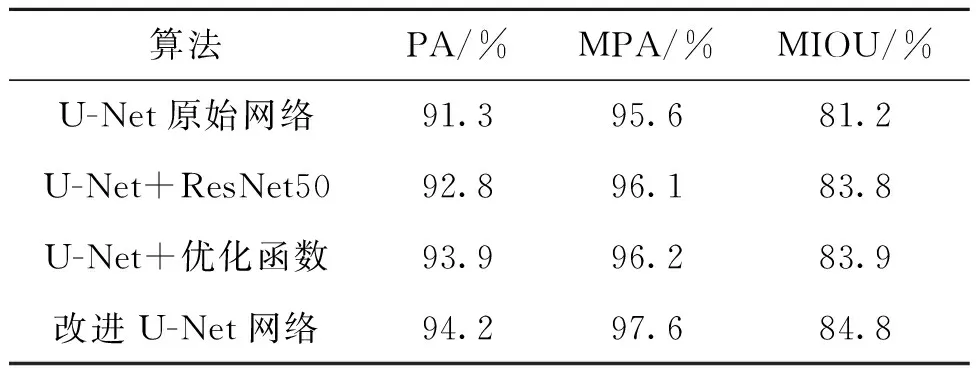
表3 改進(jìn)U-Net分割算法評價指標(biāo)結(jié)果對比Tab.3 Comparison of evaluation indicators of improved U-Net segmentation algorithm
原U-Net的特征提取網(wǎng)絡(luò)為VGG16,提取更深層次的細(xì)節(jié)特征需要增加網(wǎng)絡(luò)層數(shù),這會導(dǎo)致模型計算量大,因此本文選用ResNet50網(wǎng)絡(luò)將其替換,通過加入殘差模塊連接輸入與輸出,緩解網(wǎng)絡(luò)層數(shù)增多過程中的梯度消失問題。圖9為ResNet50與VGG16對同一張圖像分別進(jìn)行特征提取的結(jié)果示意圖。
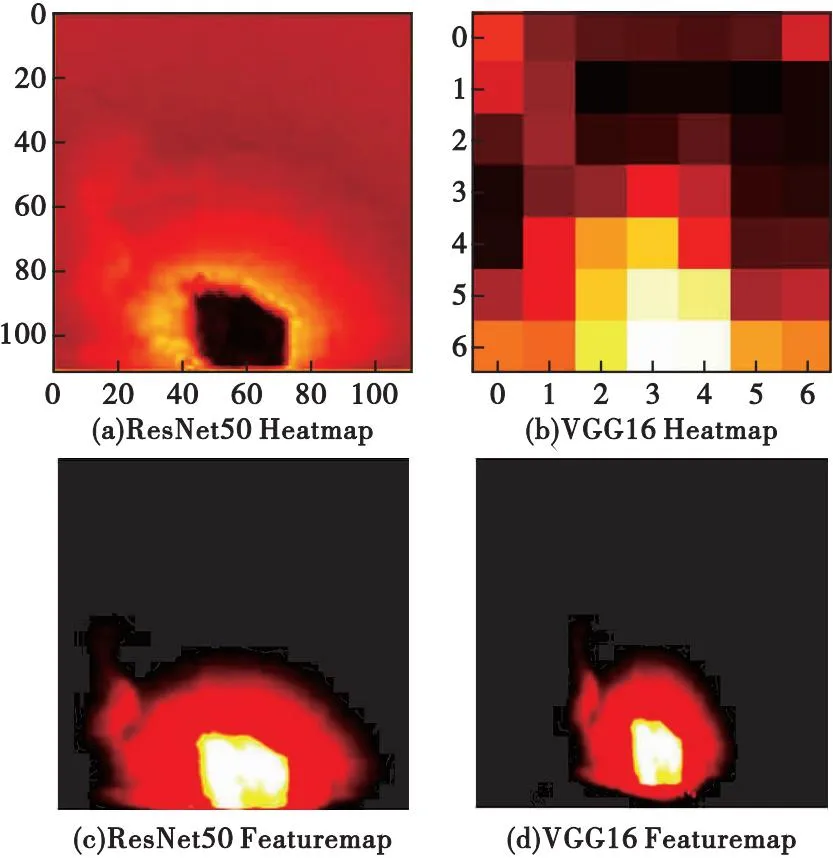
圖9 特征提取示意圖Fig.9 Feature extraction diagram
從圖9可以看出,采用ResNet50主干特征提取網(wǎng)絡(luò)的模型能夠捕捉到更廣泛的圖像信息,提取出更加有細(xì)節(jié)的目標(biāo)特征。
本文選用模型運(yùn)行時間、模型計算量及模型體積大小三個指標(biāo)作為網(wǎng)絡(luò)模型優(yōu)勢評價標(biāo)準(zhǔn),具體數(shù)值如表4所示。由表4分析得出,相比于原始VGG16主干特征提取網(wǎng)絡(luò),本文采用的ResNet50模型體積較大,但運(yùn)行時間更短,計算量更少,同時結(jié)合表3,也可以反映出ResNet50模型的精度更高,因此可以證明ResNet50主干特征提取網(wǎng)絡(luò)在增加網(wǎng)絡(luò)層數(shù)的同時,能夠提取到更深層圖像特征信息,提升模型收斂速度。

表4 不同主干特征提取網(wǎng)絡(luò)參量對比Tab.4 Comparison of networkparameters extracted from different backbone features
為了驗證添加優(yōu)化函數(shù)前后圖像的相似度變化,以標(biāo)簽圖像像素面積為判斷標(biāo)準(zhǔn),分別對U-Net原始網(wǎng)絡(luò)、U-Net+ResNet50和U-Net+優(yōu)化函數(shù)以及改進(jìn)U-Net網(wǎng)絡(luò)的圖像分割結(jié)果與標(biāo)簽圖像進(jìn)行相似度計算,其結(jié)果如表5所示。

表5 各分割圖像與標(biāo)簽圖像相似度計算結(jié)果Tab.5 The similarity calculation result of each segmented image andthe label image
3.3.3炸點(diǎn)圖像二維坐標(biāo)到空間位置的轉(zhuǎn)換
用已訓(xùn)練好的改進(jìn)U-Net分割網(wǎng)絡(luò)模型,對數(shù)據(jù)集中的炸點(diǎn)圖像進(jìn)行分割,采用Canny邊緣輪廓提取算法提取炸點(diǎn)的邊緣輪廓,Canny算法主要利用高斯函數(shù)對炸點(diǎn)圖像進(jìn)行平滑處理,再根據(jù)一階微分處理后的炸點(diǎn)圖像像素點(diǎn)的極大值來確定邊緣點(diǎn),之后使用最小二乘法輪廓擬合,獲得輪廓中心及半徑,根據(jù)攝像機(jī)成像原理求得炸點(diǎn)位置。具體步驟如下:
1) 利用GoogLeNet分類出的炸點(diǎn)圖像數(shù)據(jù)集對改進(jìn)U-Net網(wǎng)絡(luò)進(jìn)行訓(xùn)練并測試,獲得分割圖像;
2) 使用Canny邊緣提取算法,對炸點(diǎn)分割圖像進(jìn)行邊緣檢測,并輸出炸點(diǎn)邊緣輪廓圖像;
3) 使用最小二乘法進(jìn)行輪廓擬合,獲得輪廓中心及半徑,并用輪廓中心y軸數(shù)值與半徑求差,求得炸點(diǎn)像素坐標(biāo);
4) 根據(jù)攝像機(jī)成像原理轉(zhuǎn)換炸點(diǎn)像素坐標(biāo),獲取炸點(diǎn)空間坐標(biāo)。
選用多張炸點(diǎn)圖像,對其分別進(jìn)行上述操作處理,處理結(jié)果如圖10所示。

圖10 炸點(diǎn)圖像處理結(jié)果圖Fig.10 Explosion point image processing result
將獲取的像素坐標(biāo)記為(u,v),代入第一章的坐標(biāo)轉(zhuǎn)換公式(1)—(4)中,計算炸點(diǎn)空間坐標(biāo)(U,V,W),如表6所示。

表6 炸點(diǎn)空間坐標(biāo)Tab.6 Bursting point in air coordinates
由圖10可以看出,采用爆炸瞬間的炸點(diǎn)數(shù)據(jù)集訓(xùn)練改進(jìn)U-Net網(wǎng)絡(luò),獲得的分割圖像精度更高,因此獲取的炸點(diǎn)像素坐標(biāo)更為準(zhǔn)確,通過坐標(biāo)轉(zhuǎn)換關(guān)系,求出更加接近真實炸點(diǎn)位置的三維坐標(biāo),由此證明本文基于深度學(xué)習(xí)的炸點(diǎn)圖像識別與處理方法可以對炸點(diǎn)目標(biāo)實現(xiàn)位置獲取及準(zhǔn)確識別。
4 結(jié)論
本文首先利用GoogLeNet對高速攝像機(jī)拍攝的多序列爆炸圖像進(jìn)行分類,提取出爆炸瞬間的多幀圖像,作為獲取炸點(diǎn)位置信息的圖像數(shù)據(jù)集;其次對U-Net分割網(wǎng)絡(luò)進(jìn)行改進(jìn),將特征提取主干網(wǎng)絡(luò)替換為ResNet50,通過與VGG16作為主干特征提取網(wǎng)絡(luò)對比,可知本文采用的ResNet50主干特征提取網(wǎng)絡(luò)模型計算量更少,運(yùn)行速度更快,結(jié)合FocalLoss與DiceLoss函數(shù),并采用自適應(yīng)矩估計函數(shù)作為優(yōu)化函數(shù),增加分割圖像與標(biāo)簽圖像的相似性,由計算結(jié)果可知,采用自適應(yīng)矩估計函數(shù)作為優(yōu)化函數(shù)的相似度結(jié)果為98.67%,比不加該優(yōu)化函數(shù)的U-Net原始網(wǎng)絡(luò)相似度結(jié)果高出1.30%,能夠提高網(wǎng)絡(luò)分割精度;然后采用Canny邊緣提取算法對已分割的炸點(diǎn)圖像進(jìn)行輪廓提取,并采用最小二乘法輪廓擬合,獲得輪廓中心及半徑,對輪廓中心y軸數(shù)值與半徑求差得到炸點(diǎn)像素坐標(biāo);最后利用攝像機(jī)成像原理將炸點(diǎn)二維坐標(biāo)轉(zhuǎn)換為三維坐標(biāo),獲取炸點(diǎn)空間位置信息。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
艦船科學(xué)技術(shù)(2022年15期)2022-09-14 09:21:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學(xué)報(2017年11期)2017-04-04 02:52:58
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
