基于跨通道融合與注意力機(jī)制的輕量化目標(biāo)檢測(cè)模型*
2024-04-16 12:18:54曹瑞穎趙志誠(chéng)謝新林
火力與指揮控制 2024年3期
曹瑞穎,趙志誠(chéng),謝新林,劉 寧
(1.太原科技大學(xué)電子信息工程學(xué)院,太原 030024;2.山西省信息產(chǎn)業(yè)技術(shù)研究院有限公司,太原 030012)
0 引言
目標(biāo)檢測(cè)技術(shù)在交通、工業(yè)和軍事領(lǐng)域一直有廣泛的需求,例如自動(dòng)駕駛、移動(dòng)機(jī)器人視覺(jué)處理和大數(shù)據(jù)監(jiān)控等場(chǎng)景[1-2]。但是模型復(fù)雜度高極大地限制了算法部署,因此,如何平衡精度和模型參數(shù)量成為一個(gè)重要的研究方向。早期的目標(biāo)檢測(cè)使用傳統(tǒng)圖像處理方法,多在支持向量機(jī)(support vector machine,SVM)和方向梯度直方圖(histogram of oriented gradient,HOG)的基礎(chǔ)上改進(jìn),易于部署,但面對(duì)小目標(biāo)和復(fù)雜背景難以達(dá)到良好的效果檢測(cè)。文獻(xiàn)[3]首先對(duì)圖像進(jìn)行去噪、形態(tài)學(xué)處理等預(yù)處理操作后,對(duì)二值圖像進(jìn)行分析法特征提取,再利用灰狼算法優(yōu)化后的SVM 分類器識(shí)別圖像。該過(guò)程需要進(jìn)行大量的數(shù)據(jù)預(yù)處理,識(shí)別速率慢,不滿足實(shí)時(shí)性要求。
近十年來(lái),由于計(jì)算機(jī)視覺(jué)發(fā)展迅速,研究人員將目光放在融合數(shù)字信息處理、計(jì)算機(jī)視覺(jué)和人工智能為一體的目標(biāo)檢測(cè)算法上[4]。基于深度學(xué)習(xí)的識(shí)別方式一般可分為兩類:基于回歸的一階段方式和基于區(qū)域候選的二階段方式。其中,二階段算法被較早地提出,最具代表性的有R-CNN(re gion-conventional neural network)、Fast R-CNN、Faster R-CNN 和Mask R-CNN[5-8]。該類算法將回歸和分類任務(wù)分開(kāi)進(jìn)行,需要提前產(chǎn)生區(qū)域候選框,精度較高但檢測(cè)速度慢,難以滿足實(shí)時(shí)性要求。而一階段算法跳過(guò)區(qū)域候選,直接得到目標(biāo)的位置概率和坐標(biāo)值,有著較快的檢測(cè)速度,容易訓(xùn)練,因此,更適合移動(dòng)端的部署。代表算法如YOLO(you only look once)系列和SSD(single shot multi-box detector)[9-10]。
近年來(lái),目標(biāo)檢測(cè)算法更加關(guān)注功能模塊的使用[11],在增加少量推理成本的基礎(chǔ)上優(yōu)化模型結(jié)構(gòu)。文獻(xiàn)[12]使用深度攝像頭進(jìn)行障礙物檢測(cè)和工件檢測(cè)。首先采用超寬帶(ultra wide band,UWB)將自動(dòng)導(dǎo)引車導(dǎo)航到工作位置附近,將基于TensorFlow框架的改進(jìn)YOLOv3 模型與深度攝像機(jī)應(yīng)用程序界面相結(jié)合,得到目標(biāo)的位置,從而建立一種高精度的自定位方法。文獻(xiàn)[13]將研究重點(diǎn)放在了重疊物體上,配備EMD Loss(earth mover’s distance loss)和非極大值抑制等技術(shù),該檢測(cè)器更適用于復(fù)雜背景下多物體重疊的情況,尤其大物體更容易重疊的情況,但實(shí)驗(yàn)不能反映對(duì)小物體的檢測(cè)效果。文獻(xiàn)[14]提出廣義焦點(diǎn)損失函數(shù)(generalized focal loss),通過(guò)對(duì)損失函數(shù)的修改,將焦點(diǎn)損失從離散形式推廣到連續(xù)版本,實(shí)現(xiàn)損失函數(shù)的優(yōu)化,但模型參數(shù)量并未減小,不適合移動(dòng)端的部署。綜上所述,一階段YOLO 系列的檢測(cè)速度還有待提高,通過(guò)模型的輕量化,在不影響小目標(biāo)和遮擋問(wèn)題的情況下優(yōu)化模型。
因此,針對(duì)以上不足,本文提出一種基于YOLOv4 的跳躍連接擴(kuò)尺度特征融合模型,主要貢獻(xiàn)如下:首先,原YOLOv4 的主干網(wǎng)絡(luò)采用CSPDarkNet53,模型參數(shù)量大。為了提升檢測(cè)速度,本文利用MobileNet 模塊改造主干特征,提取網(wǎng)絡(luò)命名為MV1,同時(shí)借鑒MobileNet 骨架的思想,重新構(gòu)建網(wǎng)絡(luò)中所有3 次卷積塊和5 次卷積塊,提出一種基于深度可分離卷積的輕量化目標(biāo)檢測(cè)模型,實(shí)驗(yàn)結(jié)果表明整體參數(shù)量降低了80.8%。其次,模型壓縮很可能導(dǎo)致精度下降,為了提升網(wǎng)絡(luò)的檢測(cè)能力,在網(wǎng)絡(luò)的頸部構(gòu)建了跨通道跳躍連接特征融合結(jié)構(gòu)。一方面將原來(lái)的3 尺度改為4 尺度,額外融合一層淺層信息,相應(yīng)的上采樣、下采樣環(huán)節(jié)也增加一次;另一方面增加兩層跨通道路徑融合深淺層信息,以此提高模型識(shí)別多尺度目標(biāo)的性能。最后為了進(jìn)一步提升改進(jìn)算法應(yīng)對(duì)復(fù)雜背景和小目標(biāo)的特征提取能力,引入ECA 注意力機(jī)制,通過(guò)實(shí)驗(yàn)證明ECA的提取能力要優(yōu)于CBAM、SE 和CA 機(jī)制,算法更關(guān)注圖像中的目標(biāo)信息。
1 相關(guān)背景
1.1 YOLOv4 目標(biāo)檢測(cè)算法
YOLOv4 網(wǎng)絡(luò)是Alexey Bochkovskiy 等提出的典型一階段目標(biāo)檢測(cè)算法[15],在原有YOLOv3 的基礎(chǔ)上,從骨干網(wǎng)絡(luò)架構(gòu)、激活函數(shù)、損失函數(shù)和訓(xùn)練方式等方面進(jìn)行優(yōu)化[16]。運(yùn)行速度明顯加快,但并沒(méi)有給網(wǎng)絡(luò)帶來(lái)太多計(jì)算量,精度也有一定提升,在速度和精度的平衡上表現(xiàn)良好。YOLOv4 的網(wǎng)絡(luò)結(jié)構(gòu)大致可分為4 個(gè)部分:輸入端、主干Backbone、頸部Neck 和輸出端(預(yù)測(cè)端Prediction),圖像分成不同尺度的網(wǎng)格進(jìn)行特征提取,通過(guò)回歸預(yù)測(cè)框?qū)崿F(xiàn)目標(biāo)的位置定位和分類。YOLOv4 最大的貢獻(xiàn)在于構(gòu)建了一個(gè)高效的目標(biāo)檢測(cè)模型,降低了訓(xùn)練門(mén)檻,使普通研究人員也可以用1080Ti 或2080Ti 的GPU 來(lái)訓(xùn)練模型,推動(dòng)了目標(biāo)檢測(cè)算法的進(jìn)步。
1.2 深度可分離卷積
深度可分離卷積(depthwise separable convolution,DSC)是由CHOLLET 等提出的一種卷積塊[17],被人們熟知主要是因?yàn)閮蓚€(gè)著名模型Xception 和MobileNet[18],在這兩個(gè)模型結(jié)構(gòu)中均起到關(guān)鍵作用。DSC 由逐通道卷積(depthwise convolution)和逐點(diǎn)卷積(pointwise convolution)兩部分構(gòu)成,在保留卷積操作的基本表征學(xué)習(xí)能力的同時(shí)減少權(quán)重系數(shù)的個(gè)數(shù),相比普通卷積,運(yùn)算量和運(yùn)算成本要小很多。卷積主要是用來(lái)提取特征,普通的卷積會(huì)實(shí)現(xiàn)通道和空間的聯(lián)合關(guān)系,而DSC 則先執(zhí)行空間方向的卷積,保持通道分離的狀態(tài),隨后進(jìn)行1*1 的逐點(diǎn)卷積。
若對(duì)于某個(gè)卷積層而言,輸入的張量深度為Cin,輸出的張量深度為Cout,則對(duì)于高寬為h、w 的卷積來(lái)說(shuō),逐通道卷積后的尺寸為h*w*Cin,接著用尺寸為1*1*Cin*Cout的卷積核進(jìn)行逐點(diǎn)卷積,卷積步長(zhǎng)Stride 為1,則深度可分離卷積的參數(shù)量為:
同樣的卷積核大小采用標(biāo)準(zhǔn)卷積的參數(shù)量為:
因此,兩者的參數(shù)量比值為:
2 改進(jìn)的輕量化目標(biāo)檢測(cè)模型
2.1 整體結(jié)構(gòu)
改進(jìn)后的整體網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示,y1~y4分別為4 尺度特征提取的輸出端。CBL 模塊為YOLOv4的基本模塊,由標(biāo)準(zhǔn)卷積層(CONV)、批量標(biāo)準(zhǔn)化層(Batch_Normalization)和ReLU 激活函數(shù)組成。全程使用Concat 向量拼接操作,將MobileNet 模塊的中間層和深層網(wǎng)絡(luò)的上采樣特征向量進(jìn)行拼接,下采樣得到的特征向量與深層特征向量同樣使用Concat堆疊。圖像尺寸固定為416*416,輸入Backbone 先經(jīng)過(guò)普通卷積CBR,由標(biāo)準(zhǔn)卷積層(CONV)、批量標(biāo)準(zhǔn)化層(Batch_Normalization)和ReLU6 激活函數(shù)組成。改良后的MobileNet 模塊MV1 其基本組件是DW 深度可分離卷積,由3×3 逐通道卷積和1×1逐點(diǎn)卷積組成,步長(zhǎng)stride 為1、2 交替連接。借鑒MobileNet 的思想,在原來(lái)YOLOv4 的基礎(chǔ)上,將所有3*3 卷積塊和5*5 卷積塊改造成含DW 卷積的“夾心”形式,如下頁(yè)圖2 所示,將3*3 卷積的第2層替換為DW 卷積,命名為CDC 模塊;將5*5 卷積的第2、4 層替換為DW 卷積,命名為CDCDC 模塊。下采樣是卷積核為3 的普通卷積CBL。
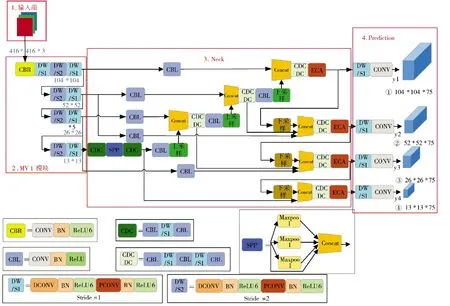
圖1 改進(jìn)后的整體結(jié)構(gòu)Fig.1 Improved overall structure
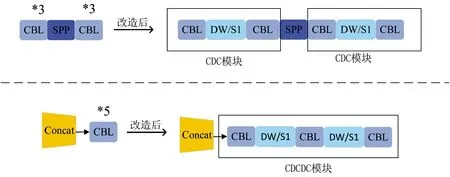
圖2 改造3*3 卷積塊和5*5 卷積塊Fig.2 Transformed 3*3 convolution block and 5*5 convolution block
2.2 MV1 模塊構(gòu)建的主干特征提取網(wǎng)絡(luò)
雖然YOLOv4 在精度和速度上都達(dá)到一個(gè)很好的平衡,但不適用于算力有限的移動(dòng)端部署,所以本文借鑒MobileNet 的思想設(shè)計(jì)了新的主干網(wǎng)絡(luò)來(lái)壓縮模型,命名為MV1。MobileNet 模塊是Google 團(tuán)隊(duì)提出的輕量級(jí)深度神經(jīng)網(wǎng)絡(luò),它的核心思想是深度可分離卷積,這一改進(jìn)有效地減少了模型參數(shù)量,便于移動(dòng)設(shè)備或嵌入式設(shè)備的算法快速部署和實(shí)時(shí)運(yùn)行。
本文算法設(shè)計(jì)了一種基于深度可分離卷積的主干特征提取網(wǎng)絡(luò),不同于原MobileNet 結(jié)構(gòu),第1層設(shè)置一個(gè)步長(zhǎng)為2 的普通卷積,中間層去掉普通卷積,只保留DW 卷積,尾端使用自適應(yīng)平均池化(adaptive avg pool)和一個(gè)全連接層(linear)。最后為了配合頸部的擴(kuò)尺度改造,MobileNet 模塊的Stage層需要加一,保持原本的模型深度不變。如圖3 所示,基礎(chǔ)卷積conv_bn 即CBL 模塊,conv_dw 即深度可分離卷積塊DW。實(shí)驗(yàn)結(jié)果表明這一改進(jìn)有效降低了網(wǎng)絡(luò)參數(shù)量,但精度會(huì)有所下降,在后續(xù)的加強(qiáng)特征提取部分彌補(bǔ)。
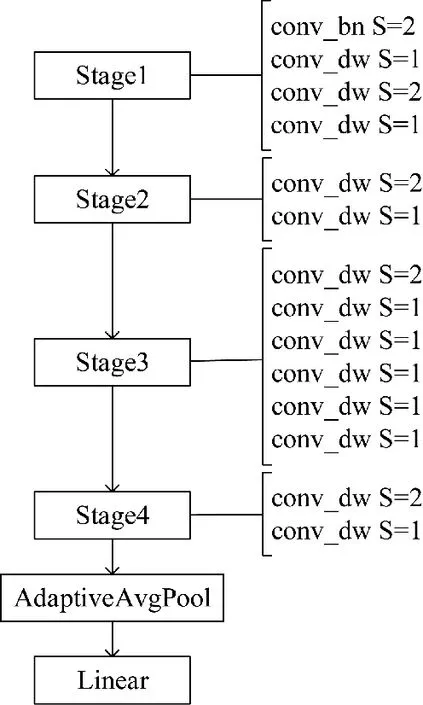
圖3 MV1 模塊的結(jié)構(gòu)示意圖Fig.3 Structure schematic diagram of MV1 module
2.3 Neck 部分的多尺度特征提取
在實(shí)際場(chǎng)景中,為了滿足不同大小物體的檢測(cè)需求,往往需要獲取不同的尺度特征。一般來(lái)說(shuō),大目標(biāo)在圖片中所占面積大,特征較為豐富,所以檢測(cè)較為簡(jiǎn)單。但小目標(biāo)在圖中所含特征信息較少,經(jīng)過(guò)Backbone 的不斷特征提取,導(dǎo)致特征圖丟失信息嚴(yán)重,檢測(cè)難度增大。為了解決小目標(biāo)物體的檢測(cè)難題,通過(guò)利用較大特征圖的輸出特征獲得較小的感受野,來(lái)提高物體檢測(cè)能力。本文算法正是在原有Neck 的基礎(chǔ)上,增加一淺層特征圖,如圖4 的藍(lán)色部分所示,3 尺度擴(kuò)展成4 尺度,同時(shí)配備卷積和上采樣層。在輸入圖像尺寸416*416 的前提下,得到4 種檢測(cè)分支分別為13*13,26*26,52*52,104*104,并將52*52 的特征層2 倍上采樣與新添加的104*104 層堆疊,104*104 的輸出特征下采樣與52*52 層特征進(jìn)行堆疊,以此來(lái)充分利用淺層特征信息。
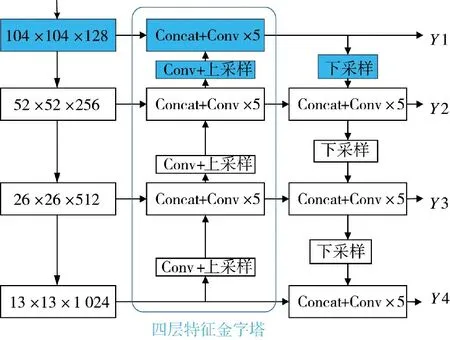
圖4 3 尺度擴(kuò)展為4 尺度的Neck 結(jié)構(gòu)示意圖Fig.4 Schematic diagram of Neck structure with 3 scales expanded to 4 scales
此外在PANet 結(jié)構(gòu)中,下采樣的輸入端是經(jīng)過(guò)FPN 特征金字塔處理的信息,缺少原始主干特征信息,影響檢測(cè)精度。所以本文借鑒加權(quán)特征金字塔網(wǎng)絡(luò)(BiFPN)的思想[19],在特征傳遞過(guò)程中增加兩層普通卷積,改進(jìn)的網(wǎng)絡(luò)結(jié)構(gòu)如下頁(yè)圖5 的紅色部分所示,將Backbone 獲得的原始信息跨層輸出,與4 層特征金字塔得到的特征堆疊,使原始信息持續(xù)參與特征提取過(guò)程。為了匹配額外增加的路徑通道數(shù),需要一個(gè)普通1*1 卷積調(diào)整通道數(shù)。

圖5 Neck 的最終改進(jìn)示意圖Fig.5 Schematic diagram of final improvement of Neck
2.4 融合ECA 通道注意力機(jī)制
近年來(lái),由于注意力機(jī)制具有可操作性強(qiáng),有效聚焦關(guān)鍵信息和自適應(yīng)調(diào)整權(quán)重的優(yōu)良特性,融合注意力機(jī)制在改善深度卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)上展現(xiàn)了很大的潛能。本文為了進(jìn)一步提升算法的特征提取能力,在Neck 加強(qiáng)特征提取部位的最后,即YOLOv4 網(wǎng)絡(luò)的預(yù)測(cè)端之前,將參數(shù)量很小的ECA模塊插在4 層尺度中,不僅能有效增強(qiáng)模型的性能,同時(shí)對(duì)模型大小的影響幾乎可以忽略不計(jì)。
ECA 注意力機(jī)制把重點(diǎn)放在跨信道交互上,避免一味地降維壓縮影響學(xué)習(xí)通道間的依賴關(guān)系[20],結(jié)構(gòu)如圖6 所示,H、W 表示通道的高寬。首先在輸入特征圖上進(jìn)行空間特征壓縮,使用全局平均池化得到1*1*C 的特征圖,隨后用動(dòng)態(tài)卷積核1*1 卷積自適應(yīng)學(xué)習(xí)通道特征,并經(jīng)過(guò)Sigmoid 激活函數(shù)處理得到各通道的權(quán)重系數(shù),將權(quán)重與原始輸入圖像的對(duì)應(yīng)元素相乘即可得到最終輸出特征。其中,自適應(yīng)卷積核的計(jì)算公式為:
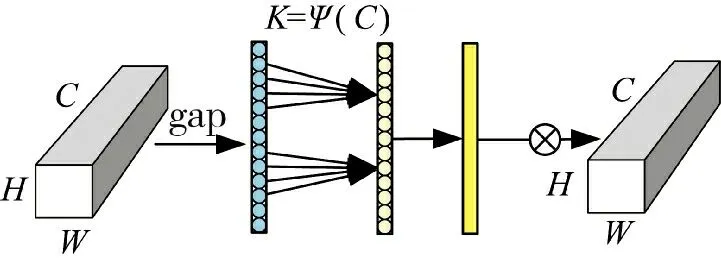
圖6 ECA 模塊示意圖Fig.6 Schematic diagram of ECA module
式中,γ=2,b=1,C 是通道數(shù)。
3 實(shí)驗(yàn)設(shè)計(jì)和結(jié)果分析
3.1 數(shù)據(jù)集
為了驗(yàn)證本文改進(jìn)的目標(biāo)檢測(cè)算法能否滿足復(fù)雜背景下的檢測(cè),采用Pascal VOC 07+12 數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)研究。Pascal VOC 數(shù)據(jù)集是目標(biāo)檢測(cè)領(lǐng)域最常用的標(biāo)準(zhǔn)數(shù)據(jù)集之一,很多優(yōu)秀的計(jì)算機(jī)視覺(jué)模型如分類、定位、檢測(cè)、分割和動(dòng)作識(shí)別都基于Pascal VOC 挑戰(zhàn)賽及其提供的數(shù)據(jù)集推出。本文選擇的數(shù)據(jù)集是Pascal VOC 2007 和Pascal VOC 2012,包含了日常生活場(chǎng)景中最常見(jiàn)的20 個(gè)類別。本文將兩組數(shù)據(jù)集整合得到21 503 張圖片,劃分情況如下:訓(xùn)練和驗(yàn)證占全部數(shù)據(jù)集的90%,共19 352 張,在此基礎(chǔ)上訓(xùn)練集占90%,共17 416 張,測(cè)試占10%,共2 151 張。20 個(gè)類別所含目標(biāo)信息如圖7 所示。

圖7 Pascal VOC 07+12 數(shù)據(jù)集的數(shù)據(jù)分布情況Fig.7 Data distribution status of datasets of Pascal VOC 07+12
3.2 實(shí)驗(yàn)平臺(tái)與環(huán)境配置
本文全部實(shí)驗(yàn)結(jié)果都是基于深度學(xué)習(xí)框架Pytorch 進(jìn)行的,實(shí)驗(yàn)環(huán)境配置如下:操作系統(tǒng)為L(zhǎng)inux,GPU 為GeForce RTX 2080 Ti,16 核處理器,內(nèi)存為64 GB,網(wǎng)絡(luò)鏡像為torch 1.2.0、torchvision0.4.0,數(shù)據(jù)處理為Python 3.7,GPU 加速軟件為CUDA10.1、CUDNN10.1.105。
3.3 訓(xùn)練過(guò)程
在深度學(xué)習(xí)的訓(xùn)練過(guò)程中,從0 開(kāi)始初始權(quán)重過(guò)于隨機(jī)往往效果不好,且耗費(fèi)大量時(shí)間成本。為了節(jié)約計(jì)算機(jī)資源,采用遷移學(xué)習(xí)策略,利用多次迭代獲得的初始權(quán)重進(jìn)行訓(xùn)練,提高模型的泛化能力。圖片輸入尺寸為416*416,將訓(xùn)練過(guò)程分為凍結(jié)和解凍階段,共訓(xùn)練100 輪,前50 輪凍結(jié)主干特征提取網(wǎng)絡(luò)所占顯存較小,批次設(shè)置為16,隨后解凍訓(xùn)練,批次縮小為8。模型最大學(xué)習(xí)率1e-2,最小學(xué)習(xí)率1e-4,使用余弦退火方式調(diào)整,選擇SGD 優(yōu)化器。由于輸出特征圖變成4 尺度,先驗(yàn)框的尺寸和數(shù)量要與之對(duì)應(yīng),使用K-Means 聚類的方式得到4尺度共12 個(gè)Anchor Box[21],聚類結(jié)果如表1 所示,該方法獲得的先驗(yàn)框更接近數(shù)據(jù)集。
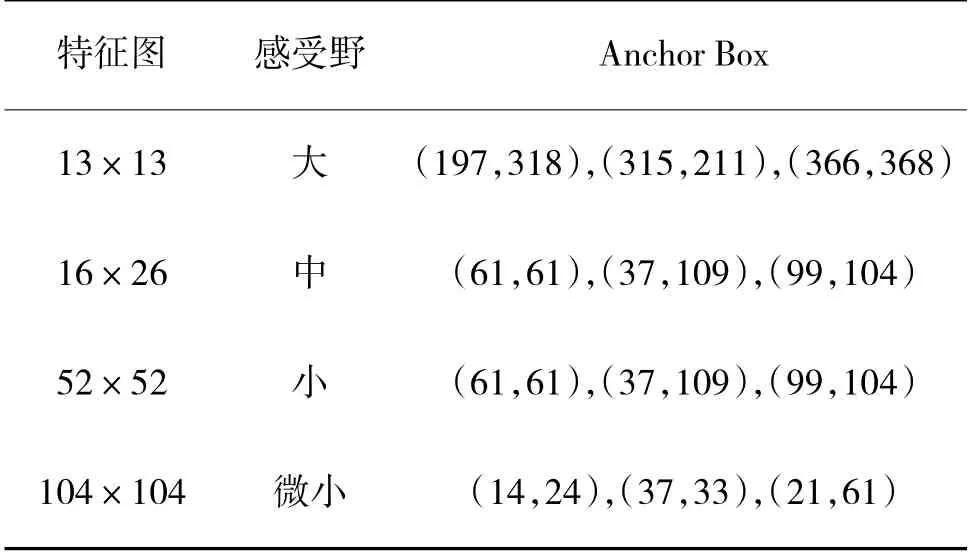
表1 K-Means 聚類結(jié)果Table 1 K-Means clustering results
3.4 評(píng)價(jià)指標(biāo)
評(píng)價(jià)指標(biāo)用來(lái)衡量算法檢測(cè)的好壞,本文主要用到IoU(交并比)、precision(精確度)、recall(召回率)、AP(平均精度)、mAP(平均類別精度),具體計(jì)算方式如下:
其中,TP 表示預(yù)測(cè)為正樣本且實(shí)際為正樣本的數(shù)量,F(xiàn)P 表示預(yù)測(cè)為負(fù)樣本但實(shí)際為正樣本的數(shù)量,F(xiàn)N 表示預(yù)測(cè)為負(fù)樣本實(shí)際也是負(fù)樣本的數(shù)量,precision 為單類別的檢測(cè)精度,recall 為召回率,即全部預(yù)測(cè)正樣本里正確結(jié)果占的比率,N 表示檢測(cè)目標(biāo)的類別數(shù)為20,F(xiàn)rameNum 表示處理的圖像數(shù)量,ElapsedTime 表示處理圖像消耗的時(shí)間。此外,檢測(cè)時(shí)非極大值抑制設(shè)置的iou 為0.5,置信度Confidence 為0.001,只有得分大于置信度的預(yù)測(cè)框才會(huì)被保留。
3.5 結(jié)果分析
3.5.1 改造主干特征提取網(wǎng)絡(luò)的實(shí)驗(yàn)驗(yàn)證
為了選取最合適的主干替換網(wǎng)絡(luò),驗(yàn)證MV1 模塊的合理性,本文以YOLOv4 原始網(wǎng)絡(luò)為基礎(chǔ),選取常見(jiàn)的輕量化網(wǎng)絡(luò)GhostNet、MobileNetv1(改造后的MV1 模塊)、MobileNetv2、MobileNetv3、DenseNet 121、ResNet50、VGG 替換YOLOv4 的Backbone,包含數(shù)據(jù)增強(qiáng)等預(yù)處理環(huán)節(jié),同時(shí)調(diào)整所有3*3 卷積為DW 卷積,其他部分不變。改動(dòng)后的算法分別稱為YOLOv4-G、YOLOv4-MV1、YOLOv4-MV2、YOLOv4-MV3、YOLOv4-D121、YOLOv4-R50、YOLOv4-VGG,將以上7 種算法與YOLOv4 在Pascal VOC 07+12 上進(jìn)行對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表2 所示。
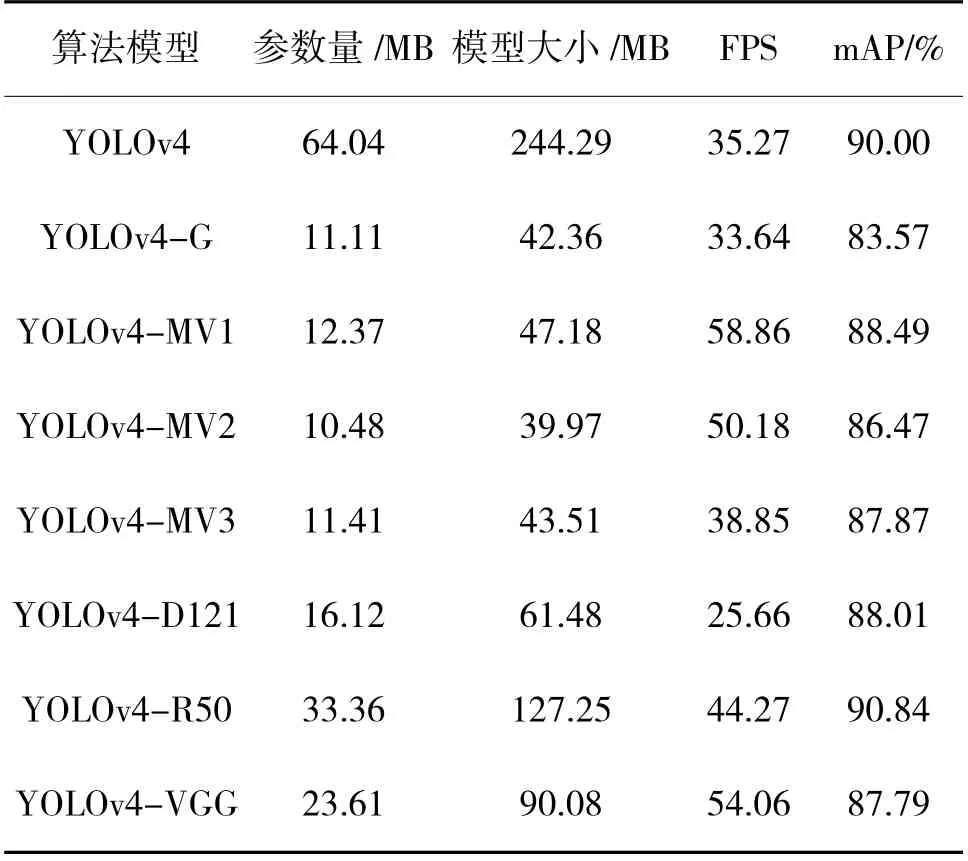
表2 替換Backbone 的實(shí)驗(yàn)結(jié)果Table 2 Experimental results of replacing Backbone
從表2 可以看出,GhostNet 和MobileNet 系列在參數(shù)量的降低方面都達(dá)到80%以上,表現(xiàn)優(yōu)異。要移動(dòng)端的使用需要得到盡可能大的FPS,即每秒傳輸幀數(shù)(Frames Per Second),視頻流暢度越好,所以表現(xiàn)最好的是MobileNet 模塊,同時(shí)還兼顧最高的精度,與YOLOv4 原算法的mAP 相比只差0.51%。從算法檢測(cè)精度來(lái)說(shuō),藍(lán)色字體標(biāo)注的算法是精度最高的前3 種,最優(yōu)的替換網(wǎng)絡(luò)是YOLOv4-MV1 和YOLOv4-R50,后者精度更高甚至超越Y(jié)OLOv4,但模型大小只降低了一半,而MobileNetv1 降低了80.7%。所以綜合來(lái)看YOLOv4-MV1 在Pascal VOC 07+12 表現(xiàn)最好,本文采用基于MobileNet 塊設(shè)計(jì)的主干特征提取網(wǎng)絡(luò)。
3.5.2 改進(jìn)Neck 部分的實(shí)驗(yàn)驗(yàn)證
為了驗(yàn)證Neck 部分兩個(gè)創(chuàng)新點(diǎn)的合理性,首先增加1 層淺層信息,3 尺度擴(kuò)展為4 尺度,稱為YOLOv4-MV1-F;其次在YOLOv4-MV1-F 的基礎(chǔ)上調(diào)整特征金字塔結(jié)構(gòu),連接主干網(wǎng)絡(luò)與下采樣結(jié)構(gòu),增強(qiáng)信息融合,稱為YOLOv4-MV1-FB。對(duì)比結(jié)果如表3 所示。
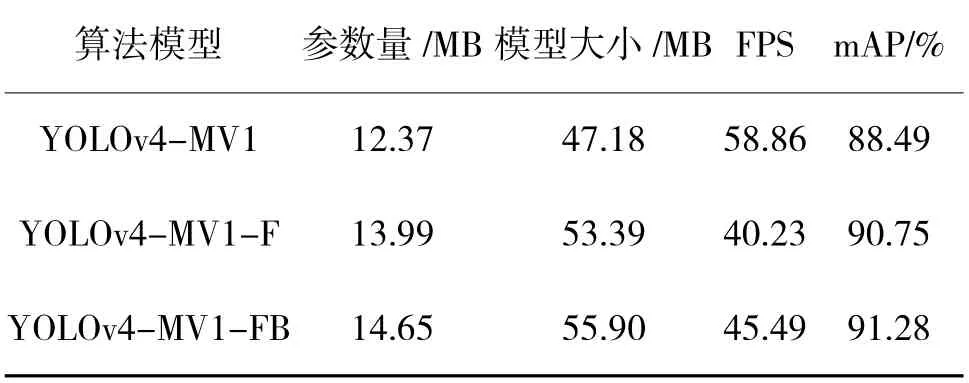
表3 改進(jìn)Neck 部分的實(shí)驗(yàn)結(jié)果Table 3 The experimental results of improving the Neck section
從表3 可以看出,增加1 層淺層信息,并增強(qiáng)尺度融合都會(huì)使算法的參數(shù)量和模型大小少量增加,F(xiàn)PS 也有所降低,但模型的改進(jìn)對(duì)算法精度分別提高了2.26%和2.79%,依然保持著較好的實(shí)時(shí)性,因此,證明了該改進(jìn)方法的有效性。
3.5.3 融合注意力模塊的實(shí)驗(yàn)分析
為了驗(yàn)證融合注意力機(jī)制的有效性,并探究哪種注意力模塊對(duì)精度的提升效果更好,本文在YOLOv4-MV1-FB 網(wǎng)絡(luò)的基礎(chǔ)上設(shè)計(jì)實(shí)驗(yàn),選取4種最常用的注意力機(jī)制CBAM、ECA、CA、SE 插到Neck 的最后,其他部分不做改動(dòng),實(shí)驗(yàn)結(jié)果如表4所示。
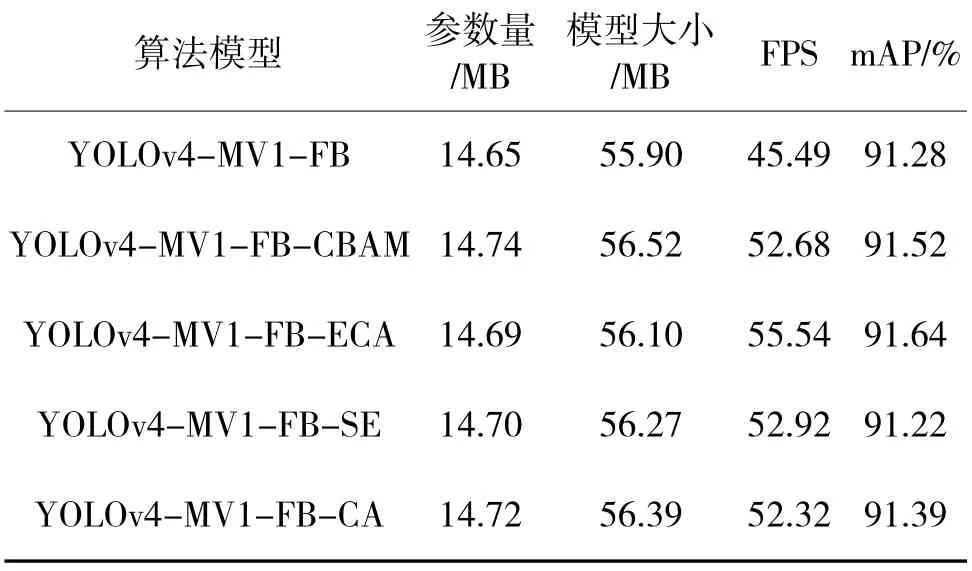
表4 融合注意力模塊的實(shí)驗(yàn)結(jié)果Table 4 The experimental results of fusing attention module
從表4 中可以看出,在網(wǎng)絡(luò)的檢測(cè)頭前分別加入4 種注意力機(jī)制帶來(lái)的參數(shù)變化并不大,在參數(shù)量的增加上幾乎可以忽略不計(jì);從平均類別精度mAP 來(lái)看,ECA 表現(xiàn)更好,增加了0.36%;同時(shí)ECA具有更好的FPS,更能滿足實(shí)時(shí)性要求。因此,本文在Neck 的最后引入ECA 注意力機(jī)制更有效,實(shí)現(xiàn)運(yùn)行速度和精度的統(tǒng)一。
3.5.4 消融實(shí)驗(yàn)
為了更全面地分析YOLOv4-MV1-FB-ECA 中各個(gè)模塊的改進(jìn)效果,在YOLOv4 的基礎(chǔ)上設(shè)計(jì)消融實(shí)驗(yàn)。4 種改進(jìn)策略分別命名MV1(MobileNet 塊構(gòu)建主干特征網(wǎng)絡(luò),并將所有3*3 卷積換成深度可分離卷積)、F(3 尺度變4 尺度)、B(調(diào)整特征金字塔結(jié)構(gòu))、ECA(注意力機(jī)制)。在原始YOLOv4 的基礎(chǔ)上分別加入各個(gè)模塊,在Pascal VOC 07+12 數(shù)據(jù)集上進(jìn)行試驗(yàn),實(shí)驗(yàn)結(jié)果如表5 所示。

表5 消融實(shí)驗(yàn)結(jié)果Table 5 Results of ablation experiment
實(shí)驗(yàn)結(jié)果表明,引入MobileNet 塊并替換DW卷積對(duì)模型參數(shù)量的影響很大,有效地提升了FPS,模型精度下降了1.51%,說(shuō)明整體網(wǎng)絡(luò)結(jié)構(gòu)使用深度可分離卷積能帶來(lái)積極的正效應(yīng)。其他改進(jìn)的3個(gè)模塊中,3 尺度改為4 尺度對(duì)模型的提升效果最大,mAP 增加了1.02%,模型參數(shù)量增加了1.62 MB;模塊B 的精度提升較小,模型參數(shù)量增加了0.84 MB;而注意力機(jī)制ECA 的模型參數(shù)量對(duì)YOLOv4 的數(shù)量級(jí)來(lái)說(shuō)幾乎為0,模型精度提升了0.20%。
3.5.5 不同網(wǎng)絡(luò)的性能對(duì)比實(shí)驗(yàn)
在Pascal VOC 07+12 數(shù)據(jù)集上,對(duì)比分析目前流行的目標(biāo)檢測(cè)算法,除二階段模型Faster-RCNN、SSD 輸入圖片大小設(shè)置為600*600、300*300,其他一階段模型的輸入圖片均設(shè)置為416*416,檢測(cè)結(jié)果如下頁(yè)表6 所示。
由表6 可知,本文算法的mAP 為91.64%,除略小于YOLOX 以外,超越其他目標(biāo)檢測(cè)算法,但模型的參數(shù)量只有YOLOX 的27.12%。這主要是由于兩者的主干特征提取網(wǎng)絡(luò)不同,DarkNet53 有較好的提取能力,但模型參數(shù)量很大;而本文采用MobileNet 降低了參數(shù)量,并通過(guò)其他方式加強(qiáng)特征提取,彌補(bǔ)了精度上的不足。FPS 表現(xiàn)也處在中上游,YOLOv3 和YOLOv5s 的處理速度更快,但精度遠(yuǎn)小于本文算法。此外與最新的YOLOv7 相比,mAP 提高了0.74%,模型參數(shù)量降低了60%。綜上所述,本文算法YOLOv4-MV1-FB-ECA 在速度和精度的平衡上達(dá)到了較好的統(tǒng)一,證明算法的有效性。
3.5.6 檢測(cè)結(jié)果可視化
圖8 為利用Grad-CAM 算法對(duì)改進(jìn)前后的檢測(cè)算法進(jìn)行了熱力圖可視化,這是一種不需要修改模型結(jié)構(gòu),并且可以適應(yīng)多種任務(wù)的可視化方法。它是利用反向傳播過(guò)程計(jì)算梯度,從而得到特征圖每個(gè)通道的權(quán)重,通過(guò)計(jì)算得到熱力圖來(lái)解釋卷積神經(jīng)網(wǎng)絡(luò)關(guān)注的重點(diǎn)地區(qū)。圖8(a)為融合前原始網(wǎng)絡(luò)的模型熱力圖,圖8(b)為融合后本文算法的模型熱力圖。從圖中可以看出改進(jìn)算法更關(guān)注能檢測(cè)到的單個(gè)目標(biāo)本身,對(duì)物體的檢測(cè)效果更集中,因此,檢測(cè)效果更好。

圖8 算法改進(jìn)前后的模型熱力圖Fig.8 Model heat map before and after the improvement of the algorithm
4 結(jié)論
本文設(shè)計(jì)出一種基于YOLOV4 的目標(biāo)檢測(cè)算法YOLOv4-MV1-FB-ECA。通過(guò)重新構(gòu)建主干特征提取網(wǎng)絡(luò),使用深度可分離卷積的方法有效地降低了模型參數(shù)量;通過(guò)對(duì)Neck 的特征提取部分進(jìn)行改進(jìn),融合ECA 注意力機(jī)制進(jìn)一步提升模型的檢測(cè)精度。實(shí)驗(yàn)結(jié)果分析表明,改進(jìn)后的算法在公開(kāi)數(shù)據(jù)集Pascal VOC 07+12 的檢測(cè)精度提高了1.64%,模型參數(shù)量降低了77%,檢測(cè)速度達(dá)到了55.54 FPS。改進(jìn)模型在算法速度和精度上實(shí)現(xiàn)了統(tǒng)一和平衡,優(yōu)于其他主流的目標(biāo)檢測(cè)算法,較小的模型參數(shù)量和較高的FPS 為其他現(xiàn)實(shí)場(chǎng)景提供了模型基礎(chǔ)。后續(xù)工作將在進(jìn)一步提高精度的同時(shí)提高泛化能力,聚焦交通場(chǎng)景,尤其是使用率較高的車輛和行人檢測(cè),增強(qiáng)算法在復(fù)雜場(chǎng)景和多干擾情況下的魯棒性。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
