基于超分辨率重建的低分辨率人臉識別
2024-04-16 12:18:56李一洋
火力與指揮控制 2024年3期
趙 驍,陳 勇,李一洋
(北方自動控制技術研究所,太原 030006)
0 引言
人臉識別技術在單兵領域有著廣泛的應用,其重要性不言而喻。通過人臉識別技術進行敵我識別,可以獲取關鍵的戰術信息,輔助指揮員作出重要決策,實現對戰場態勢的實時把控。單兵作戰時,往往面臨著復雜的作戰環境,這就導致應用于單兵作戰的人臉識別也受到了惡劣環境的影響。在復雜的環境中,采集到的人臉圖像往往會存在著低畫質、低分辨率的問題。這種情況下,人臉識別的精度受到了很大的影響。
軍事場景中,提高低分辨率人臉識別的準確率具有重要意義。隨著科技的不斷發展,軍事情報的收集和作戰行動都越來越多地依賴于人臉識別的技術。然而,實際應用中,由于各種條件的限制,低分辨率人臉識別率往往較低,這給軍事情報的收集和作戰行動帶來了諸多困難和挑戰。
提高低分辨率人臉識別的準確率,可以幫助軍方更加準確地識別敵我雙方的人員。在軍事情報收集中,敵方人員的身份識別是至關重要的,而敵方往往會采取各種手段來限制情報的獲取,其中,包括了對人臉圖像進行故意模糊化處理。如果能夠提高對低分辨率人臉的識別率,就能夠更好地識別敵方人員的身份,為軍事情報的收集提供更加準確的數據支持。其次,提高低分辨率人臉識別的準確率可以幫助軍方更好地進行目標追蹤和監視。在作戰行動中,軍方往往需要對目標進行追蹤和監視,而目標往往會采取各種手段來隱藏身份和行蹤。如果能夠提高對低分辨率人臉的識別準確率,就能夠更好地對目標進行追蹤和監視,為作戰行動提供更加準確的情報支持。此外,提高低分辨率人臉識別的準確率,還可以幫助軍方更好地進行反恐作戰和打擊犯罪活動。提高軍事場景中低分辨率人臉識別的準確率具有非常重大的意義。不僅可以幫助軍方更好地進行情報收集、作戰行動、反恐作戰、打擊犯罪活動、邊境管控和入境檢查,還可以提高國家安全的整體水平。因此,軍事科研機構和企業應該加大對低分辨率人臉識別技術的研發投入,不斷提高其準確率和可靠性,為軍事情報收集和作戰行動提供更加強大的技術支持。
由于現實生活中攝像頭分辨率的限制或者圖像傳輸過程中的損失,導致獲取的人臉圖像分辨率較低。低分辨率圖像可能會影響人臉識別系統的準確性和性能。因此,研究人員開始關注如何利用超分辨率重建技術來提高人臉圖像的質量,從而改善人臉識別的效果。本文的研究內容如圖1 所示,利用人臉超分辨率重建技術對低分辨率人臉進行處理。對人臉進行超分辨率重建可以提高識別的準確性,通過提高人臉圖像的分辨率和清晰度,可以提高人臉識別系統的準確性和魯棒性,從而降低誤識率;增強細節信息,高分辨率圖像能夠提供更多的細節信息,有助于更準確地捕捉人臉的特征,提高識別的精確度;改善圖像質量,通過超分辨率重建技術,可以改善低分辨率圖像的質量,使得圖像更加清晰自然,提高用戶體驗。
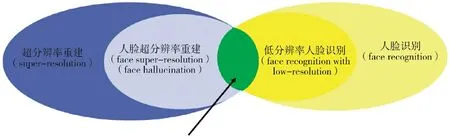
圖1 研究內容Fig.1 Research contents
超分辨率重建在人臉識別領域的研究主要包括以下幾個方面:
基于深度學習的超分辨率重建算法:研究人員正在開發深度卷積神經網絡,通過開發深度卷積神經網絡來實現超分辨率人臉圖像重建,從而研究低分辨率和高分辨率圖像之間的關系[1]。結合生成對抗網絡的超分辨率重建算法:利用生成對抗網絡(GAN)的思想,設計可以生成高質量人臉圖像的超分辨率重建模型。融合圖像修復和超分辨率重建技術結合圖像修復技術,對低分辨率圖像中的噪聲和失真進行修復,然后再進行超分辨率重建,以提高人臉圖像的質量。
超分辨率重建在人臉識別領域的研究仍在不斷深入,未來有望通過更加精確的超分辨率重建技術來提高人臉識別系統的性能和效果。
1 超分辨率重建
1.1 方法介紹
超分辨率重建是一種通過使用計算機算法來提高圖像或視頻分辨率的技術[2]。它可以通過增加像素數量或者利用圖像中的信息,來提高圖像的清晰度和細節。這種技術在圖像處理、視頻處理和計算機視覺領域得到了廣泛的應用,可以用于提高低分辨率圖像的質量,增強圖像的細節和清晰度。超分辨率重建的方法包括插值法、深度學習和圖像修復等。超分辨率重建在人臉識別領域中的應用非常廣泛,其中,基于深度學習的超分辨率重建算法被廣泛采用。目前有兩種應用較為廣泛的算法,SRCNN(super-resolution convolutional neural network)算法:是一種基于卷積神經網絡的超分辨率重建算法,其主要思想是利用多層卷積神經網絡研究低分辨率和高分辨率圖像之間的關系[3]。SRCNN 算法在訓練過程中使用了大量的高分辨率圖像和對應的低分辨率圖像,通過不斷迭代優化網絡參數,最終可以得到一個能夠將低分辨率圖像轉換為高分辨率圖像的模型[4]。在人臉識別領域,SRCNN 算法可以用于將低分辨率的人臉圖像轉換為高分辨率的圖像,從而提高人臉識別的準確率。SRGAN(super-resolution generative adversarial network)算法:是一種基于生成對抗網絡的超分辨率重建算法,其主要思想是通過兩個神經網絡相互博弈來實現圖像的超分辨率重建[5]。其中,一個神經網絡(生成器)用于將低分辨率圖像轉換為高分辨率圖像,另一個神經網絡(判別器)用于判斷生成器生成的圖像是否與真實的高分辨率圖像相似。在訓練過程中,生成器和判別器不斷交替進行迭代,最終生成一個能夠將低分辨率圖像轉換為高分辨率圖像的模型。在人臉識別的領域,SRGAN 算法可以用于增加低分辨率人臉圖片的細節,從而使得低分辨率人臉在識別過程能夠更加容易地被識別出來[6]。如今,廣泛使用的人臉識別算法往往側重于高質量的人臉捕捉,而對于在復雜作戰場景中拍攝的低質量人像,如果在不經過處理的條件下直接進行識別,識別率往往會大打折扣。因此,在真實的作戰場景中,獲取的低分辨率人臉圖像如何實現精準的識別,成為了亟待解決的難點。目前,對于低分辨率人臉識別常用的方法有以下4 種:超分辨率重建的方法、提取低分辨率圖像特征的方法、模糊矯正的方法以及統一特征空間的方法[7]。
在現有的方法中,超分辨率重建是比較有效且可行性強的一種方案。人臉超分辨重建(face superresolution reconstruction)屬于超分辨率重建的一個部分,對此人們已經做了許多相關的學習與研究。雖然圖像的視覺效果與識別率在理論上并不沖突,但在一些研究中發現,重建后圖像的視覺效果與實驗中指標的表現并不完全一致。然而,現有的大部分算法側重于研究人臉重建后的視覺效果,而沒有將重建后的模型應用于人臉識別的相關工作中。本文引入識別過程,關注重建模型是否能使低分辨率人臉的識別率得到明顯提升。
1.2 算法原理
本文提出了圖像超分辨率重建算法SRR,核心思想是利用深度學習和生成對抗網絡,來學習并重建高分辨率圖像,從而在保持圖像細節的同時提高圖像的清晰度和真實感。SRR 算法的結構如圖2 所示。SRR 算法的原理可以分為兩個主要部分:生成器和判別器。生成器負責將低分辨率的輸入圖像轉換為高分辨率的輸出圖像,而判別器則負責評估生成器生成的圖像是否真實。
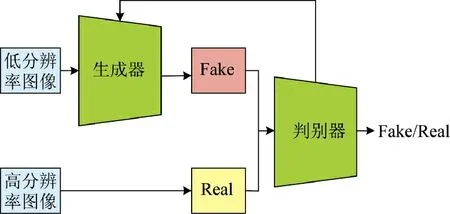
圖2 SRR 算法結構Fig.2 Structure of SRR algorithm
SRR 的生成器是基于深度卷積神經網絡(CNN)的結構,如圖3 所示,它由多個卷積層、反卷積層和殘差連接組成。生成器的主要任務是將低分辨率的輸入圖像轉換為高分辨率的輸出圖像,同時盡可能保留圖像的細節和紋理。為了實現這一目標,SRR 采用了殘差學習的思想,即通過殘差連接將輸入圖像的細節信息直接傳遞到輸出圖像中,從而減少信息丟失和模糊現象。在SRR 的生成器中,首先通過多個卷積層對輸入圖像進行特征提取和抽象表示,然后通過反卷積層逐步將特征圖放大到目標的分辨率。在這個過程中,生成器通過多層的殘差連接來學習和保留圖像的細節信息,從而使得輸出圖像更加清晰和真實。此外,為了進一步提高圖像的質量,SRR還引入了像素對齊和通道注意力機制,以增強對細節和紋理的學習能力,并減少圖像的偽影和失真。
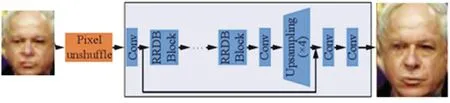
圖3 生成器的結構Fig.3 Structure of generator
SRR 的判別器是一個基于CNN 的二分類器,它的主要任務是評估生成器生成的圖像是否真實。判別器的輸入是高分辨率的真實圖像和生成器生成的高分辨率圖像,輸出則是一個二元值,表示輸入圖像是真實圖像的概率。通過對生成器生成的圖像進行評估和反饋,判別器可以指導生成器學習和改進,從而提高圖像的真實感和質量。在SRR 的判別器中,通過多個卷積層和池化層對輸入圖像進行特征提取和抽象表示,然后通過全連接層將特征圖映射到二元值輸出。判別器通過不斷訓練和學習,逐漸提高對真實圖像和生成圖像的識別能力,從而使得生成器生成的圖像更加真實和逼真。
SRR 的訓練過程是一個基于對抗學習的過程,即生成器和判別器之間的博弈過程。在訓練過程中,生成器通過最小化判別器的損失來提高生成圖像的真實感,而判別器則通過最大化真實圖像和生成圖像的差異來指導生成器的學習和改進。通過不斷的對抗學習和優化,生成器和判別器可以逐漸達到動態平衡,從而提高圖像的超分辨率重建質量和真實感。
2 實驗結果及分析
2.1 圖像超分辨率重構的評價指標
超高分辨率重建研究的結果的評估通常基于峰值信噪比(PSNR)和結構相似性(SSIM)兩個指標,它們可以較為客觀地評價重建后圖像的質量[8]。峰值信噪比(PSNR)是評估兩幅圖像相似度的一種指標,通過兩幅圖像的像素均方誤差計算得出。對于兩幅相同尺寸的圖像P 和Q,PSNR 的計算公式如下:
其中,m,n 分別代表了圖像的長度和寬度,MAXI代表了圖像顏色點的最大值,每個采樣點都使用8 bit的圖像,MAXI=225。
結構相似性(SSIM)是一種用于評估圖像質量的指標,它考慮了亮度、對比度和結構3 個方面的相似性。SSIM 指數是一種全參考的圖像質量評價指標,即需要有原始圖像作為參考來計算圖像的相似性。SSIM 指數的計算方法基于以下3 個因素:亮度相似性,表示圖像的亮度信息的相似程度,即圖像的平均亮度和對比度;對比度相似性,表示圖像的對比度信息的相似程度,即圖像的對比度變化;結構相似性,表示圖像的結構信息的相似程度,即圖像的結構變化。
對于兩幅尺寸一致的圖像P 與Q 來說,亮度對比函數、對比度對比函數,以及結構對比函數分別定義如下:
2.2 超分辨率重建實驗
本文的訓練數據集采用CASIA-WebFace 數據集,測試數據集采用LFW 數據集。CASIA-WebFace數據集中一共包括了494 414 幅圖像,其中,包含了10 575 個人[9-10]。在人臉識別的方向,LFW 數據集屬于常用的數據集之一,其包含了5 729 人的13 233張圖像,創立之初一定程度上解決了非限制的人臉識別問題。LFW 數據集中的圖像含有更豐富的變量,其中,包括了光的亮度以及人臉的面部表情等,在之前的研究中,人臉數據集通常是在相對固定的實驗環境中采集志愿者的人臉圖像得到的。現實情況中,人臉識別更加需要非限制性的條件。本節首先使用PSNR 和SSIM 測試模型重建效果,并與常用的一些重建方法進行了比較。
實驗中選取的對比方法包括WaveletNet,SRGAN,VDSR,SICNN,EDSR,SRFBN。利用相同的訓練集對選取的方法進行訓練,來測試每個模型對于低分辨率人臉圖像的重建效果,結果如下頁表1 所示。可以看出,SRR 模型的實驗結果在SSIM 指標中有較好的表現,而在PSNR 指標中相比其他方法更為領先。
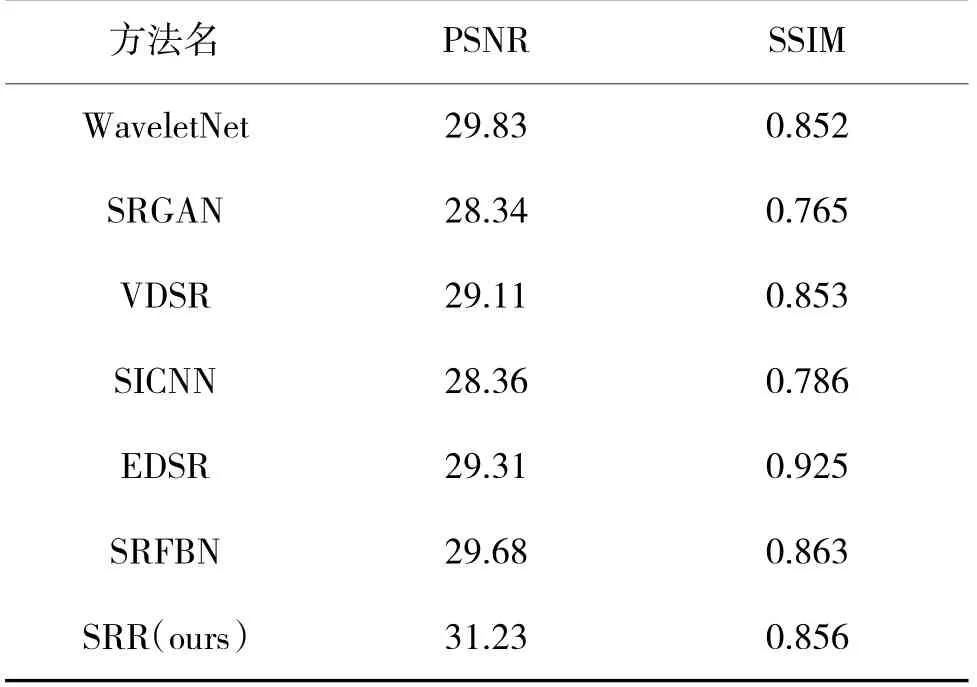
表1 超分辨率重建測試Table 1 Super-resolution reconstruction testing
表1 展示了SRR 模型在超分辨率重建的兩個指標中的成果,下頁圖4 則更為清晰地展現了模型對于低分辨率圖片的處理效果。如圖4 所示,圖4 包含了兩行圖像,其中,第1 行是未處理的低分辨率人臉圖像,而第2 行則是經過SRR 模型處理后得到的較為清晰的人臉圖像,可以看出,低分辨率人臉圖像經過處理后可以獲得清晰的、更便于識別的人臉圖像。

圖4 模型效果展示Fig.4 Demonstration of model effects
文中提到的PSNR 與SSIM 兩個指標都是誤差敏感的評價指標,它們主要用來描述圖片重建后的視覺效果。而很多研究都已表明,基于誤差敏感的評價指標與人眼對于圖片的評判并不完全一致。主要原因是人眼對于圖片的評判系統是一個非常復雜的系統,具有非線性的特征。現有的研究中,還未能發現與人眼的評價完全一致的圖像質量的評價指標。文中主要評述了SRR 模型對于低分辨率人臉的重建效果,為了解決根本的人臉識別問題,驗證模型對于人臉識別率的提高效果,需要對重建后的圖像進行人臉識別準確率的測試。
LFW 數據集廣泛地應用于人臉識別的領域,是一個經典的測試數據集,在人臉識別的測試任務中有一個標準的協議。本文利用LFW 數據集來進行各個模型的人臉識別測試,判別各個模型能否提高低分辨率人臉識別的精度。對比實驗的結果如表2所示,可以看出,SRR 模型測試的結果優于大部分的對比模型。

表2 LFW 數據集下的對比實驗Table 2 Comparison experiment under LFW data set
3 結論
實際應用的人臉識別研究過程中,低分辨率人臉識別是一個必須要面對的問題。通常只有在實驗室等一些苛刻的場景中,才能直接使用高分辨率的圖像進行人臉識別。而在復雜的作戰場景中,高分辨率的圖像難以獲取,必須對低分辨率的人臉圖像進行處理,來提高實際作戰中人臉識別的精度。本文采用超分辨率重建的方法,構建SRR 模型,有效提高低分辨率人臉識別的準確性,最終得到的結果在視覺效果上有良好的表現,一定程度上也提高了低分辨率人臉識別的準確性。
無人機、監控系統等偵察系統在發現和識別目標后,目標信息和坐標就在整個作戰平臺進行共享。之后,所有情報都會匯入大數據系統進行算法分析,在人工智能系統協助下得出最佳解決方案。最終,對偵察定位的敵方目標進行打擊,無人機還會對毀傷效果進行拍攝。通過提高在復雜作戰環境下低分辨率人臉識別的精度,可以有效地提高戰術末端作戰效能。利用較高精度的人臉識別,可以實現對戰場中敵軍目標的精準識別,給予指揮員關鍵目標信息,獲取敵兵力部署情況、作戰意圖等重要信息,輔助實現斬首行動、無人機偵察、智能導彈定位打擊等一系列軍事行動,有效提高我軍的戰場主動權以及綜合實力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2017年17期)2017-12-18 06:40:55
電子制作(2017年1期)2017-05-17 03:54:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
計算機工程(2015年8期)2015-07-03 12:19:07
