淺述因果推斷中的混雜問題
2024-05-02 03:24:04肖志尊
大眾文藝 2024年7期
肖志尊
(中山大學哲學系暨邏輯與認知研究所,廣東廣州 510275)
從古希臘哲學家亞里士多德的“四因說”(four causes),到蘇格蘭哲學家大衛·休謨的原因與結果的“恒常匯合”(constant conjunction),再到美國哲學家大衛·劉易斯的“反事實依賴”(counterfactual dependence),認識因果關系一直是我們心之所向。
隨著互聯網的迅速發展,二十一世紀大數據(big data)的出現,使得情況發生了些許變化。大數據,其基本特征是3V,即容量大(Volume)、速度快(Velocity)、種類多(Variety)。[1]基于此,對大數據的相關研究蓬勃發展,部分大數據主義者認為我們不再需要理論和模型,只需要關注相關關系就夠了,基于大數據的相關分析方法更快、更客觀、更準確。那么處于大數據時代,相關關系是否能取代因果關系?本文更贊同“如何從相關關系中推斷出因果關系,才是大數據真正問題所在”[2]這一觀點。
因果關系,其表現形式多種多樣,一因一果較為少見,更常見的是多因一果、一因多果和多因多果。通常我們只會研究主要的(或感興趣的)因或果,這時就會存在不確定性。于是我們將概率語言納入對因果關系的研究中,從數學的意義上來探究因果關系。此時,對因果關系的判定就轉變為對因果效應的準確估計。這在很多方面都是舉足輕重的,大到國家,加征十個點的關稅會使得商品的產量增加多少;小到個人,每天多吸一支煙會多大程度影響到身體健康。在流行病學研究中,推斷因果關系并估計因果效應更是永恒不變的主題,而消除混雜是實現這一目標的重要前提[3]。本文擬從混雜的角度認識相關和因果,并介紹了消除混雜實現因果效應準確估計的三種方法,對它們的優勢、不足做了對比和分析。
一、相關,因果與混雜
清晨早起,你在觀察到公雞打鳴的情況下,大概率也會看到太陽升起。前者增加了后者發生的可能性,后者的發生總是伴隨著前者的出現,我們認為這兩者之間存在相關聯系。那么相關就意味著因果嗎?公雞打鳴是太陽升起的原因嗎?我們如何判定兩個事件之間是否具有因果關系并估計因果效應的大小呢?
為了厘清這些困惑,我們介紹一些概念來更好地認識相關和因果。首先相關關系,指的是兩個變量之間具有的相互關系和函數關系[4]。從概率論的角度看,變量(事件)X與變量(事件)Y的相關程度,可以用“條件概率”P(Y|X)來表示[5]8。它表示當你觀察到X的情況下,Y將會發生的可能性。當概率提高時(P(Y|X)>P(Y)),我們認為X增加了Y發生的可能性,X與Y是相關的。[5]25此種情況對應于因果關系之梯第一層級“關聯”。[5]8當觀察到公雞在打鳴了,我們就知道太陽也要升起了,這兩者呈現高度相關。
因果關系,“指的是事件之間的一個序列,如果事件A引起事件B,則事件A是原因,而事件B是結果”[4]。已有文獻利用概率來分析因果關系。[6]接下來我們介紹朱迪亞·珀爾(Judea Pearl)的想法,從概率的角度定義“因果效應”這個概念。首先介紹用來表示主動干預的do算子。[7]珀爾用do算子do(X=x),表示對變量X進行假想的干預。與之對應,在因果圖中它意味著刪除所有指向變量X的箭頭,并且將變量X的值固定為x。此時,子變量X不再受原有父變量(原因變量)的影響,關于變量X的機制被強制干預引入的新機制X=x所取代,而保持其他機制不變。有了do算子,我們接著定義因果效應。變量(事件)X對變量(事件)Y的因果效應(causal effect),可以用“干預概率”P(Y|do(X))表示[5]127,其中P代表概率,豎線意味著“當你實施……行動的情況下”。它表示當你實施X行動的情況下,Y將會發生的可能性。當概率提高時(P(Y|do(X))>P(Y)),我們認為X導致了Y,X是Y的一個因。[5]27此種情況對應于因果關系之梯第二層級“干預”[5]8。
有了以上的概念,我們能明白為什么相關和因果容易讓人混淆了。直覺上,我們可以用“概率提高”這一概率定義因果關系,“如果X提高了Y的概率,那么我們就說X導致了Y”[5]25。但是,如果只使用條件概率來表示概率提高,這種概率提高很可能是由其他因素(如混雜)造成的,你只能得到統計上的相關性,回答的也只是因果關系之梯的第一層級“關聯”的問題。要想體現概率提高的因果解釋,我們需要借助do算子,使用干預概率來表示概率提高。
絕大多數情況下,相關程度P(Y|X)不等于因果效應P(Y|do(X))。在諸多影響因素中,混雜因子的存在是最常見,也是最重要的影響因素之一。接下來,讓我們介紹混雜因子的簡單定義:一個變量Z同時影響到變量X和變量Y時,變量Z就是混雜因子[5]115。
珀爾使用圖模型來表示變量及其因果關系,直觀的因果圖幫助我們識別混雜因子。因果圖模型由節點,有向邊和路徑組成。如圖1所示,節點X,Y,Z代表不同的變量(事件),兩節點之間的有向邊表示直接的因果關系,“X→Y”表示X導致了Y,X是Y的一個因。同理,圖1中的Z既是X的原因,也是Y的原因,Z是X和Y的共同原因,變量Z就是混雜因子。而路徑則是由一系列邊連接而成。從節點X到節點Y一共有兩條路徑:路徑X←Z→Y和路徑X→Y。由路徑X←Z→Y誘導的X和Y之間的偽相關[8](即無因果的相關),與路徑X→Y表示的X對Y真正的因果效應混合在一起了,我們只能觀察到X和Y之間總的相關程度。
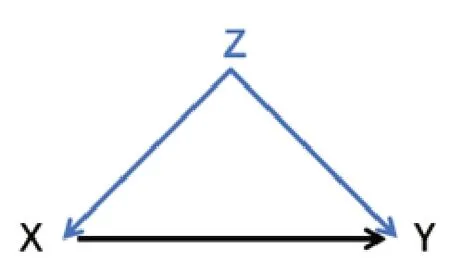
圖1
回到公雞打鳴的例子。用變量X,Y,Z分別表示公雞打鳴,太陽升起和時間。我們觀察到的是兩個時間段X和Y的狀態:早上公雞打鳴和太陽升起,晚上公雞不打鳴和太陽不升起。這兩個狀態的差異讓我們以為公雞打鳴X是太陽升起Y的原因,即“X→Y”。我們現在知道了時間Z是混雜因子,在控制混雜也就是比較同一時間段的情況下:早上公雞打鳴和太陽升起,早上公雞生病不打鳴和太陽依舊升起;晚上公雞不打鳴和太陽不升起,晚上嚇唬公雞使得公雞打鳴和太陽依舊不升起。通過同一時間段下的對比,我們明白了公雞打鳴并不會導致太陽升起。我們觀察到的這兩者之間的相關,是由“X←Z→Y”誘導產生的偽相關。這是一種特殊的情況,其中X完全不是Y的原因,“X→Y”不存在。現實中,圖1描述的混合現象更為常見,它涉及著名的辛普森悖論[9]。它向我們展示了由于混雜因子的存在,數據會如何“欺騙”我們的大腦,影響我們做出錯誤的決策。
現在我們知道,混雜因子的存在使得相關程度P(Y|X)不等于因果效應P(Y|do(X))。消除混雜因子影響的過程,是從相關性走向因果性的重要過程[10]。下一步我們要做的是,消除混雜,使得最后留下來的相關性就是真正的因果效應。
二、消除混雜實現因果效應準確估計的三種方法
混雜存在時,相關不等于因果。在消除混雜因子的影響后,我們就可以得到真正的因果效應。這一節我們介紹消除混雜實現因果效應準確估計的三種方法:[5]133
第一種消除混雜的方法被稱為,Z調整或Z控制,即對混雜因子Z進行統計調整或者控制。由于混雜因子Z的存在,我們不能直接使用觀測數據估計X對Y的因果效應。首先我們需要按照混雜因子Z將數據分為不同的組,在每個組內分別估計X對Y的因果效應,最后再加權求和。
在對混雜因子Z進行控制后,留下的相關性就是真正的因果效應。例如我們觀察到,當冰激凌的銷量增加時,溺水事件也會同時增加。此時,溫度是混雜因子,會同時影響到這兩個事件。所以實際上是,在溫度升高的影響下,我們觀察到冰激凌銷量和溺水事件增加。如果消除溫度的影響,結果會怎樣呢?可以在同一溫度下記錄這兩個事件的數據,我們會發現這兩者之間很可能是毫無聯系的,冰激凌銷量的變化并不會影響到后者。在對溫度進行控制后,這兩者之間就變得不相關了,也就說明了前者并不是后者的原因。在這里,混雜因子溫度就等同于哲學家所提出的“背景因子”[5]26。不足之處是,你需要事先識別所有的混雜因子。
第二種消除混雜的方法是,隨機對照試驗(randomized controlled trial,簡稱RCT),其研究方法是將符合標準的受試者隨機分配到處理組或對照組,對每一組實施相應的干預措施,在一致的條件下對比效果差異。[11]179隨機對照試驗通過隨機化方法,可以消除混雜因子的影響,對因果效應進行內部有效的無偏估計,被認為是臨床試驗的黃金標準。
那么,隨機對照試驗可能存在哪些問題。(1)內部有效性問題,指“一項研究不存在偏倚或系統性誤差的程度”[11]33。在現實操作中,隨機試驗的實際過程會很大程度影響到內部有效性,比如招募不力引起的樣本不足。(2)外部有效性問題,是指“研究結果可應用、可推廣或可轉用于未參與研究的人群或群組的程度”[11]34。由于實際參與隨機試驗的人一般是經過層層篩選產生的,他們和患有相同疾病的人群是存在差異的,因此并不能代表真正的患病人群,得到的試驗結果無法直接使用。這就是外部有效性問題。(3)其他問題。由于道德倫理或試驗成本的限制,使得隨機對照試驗無法順利開展和完成[11]11。另外,大型的隨機試驗需要投入大量的時間、金錢和人力,成本高昂。
第三種消除混雜的方法就是,以因果圖為基礎的do演算(do-calculus)。Do演算,是一組(三條)推理規則。其中,每一條推理規則解釋do算子為干預,對應修改初始圖模型中的一組函數。通過這些推理規則,包含干預概率和條件概率的語句能轉換為其他等價的語句,因此提供了一個干預聲明的句法推導方法。[12]Do演算可以作為隨機對照試驗的補充或擴展,在不實際實施試驗的情況下,使用觀測數據就可以預估真正的因果效應。
使用do演算來估計因果效應的方法如下。假如我們的目的是確定事件X對事件Y的因果效應P(Y|do(X))。首先,根據已有的科學知識和必要的假設構建因果模型即因果圖(部分情況下,利用收集到的數據信息,用算法協助可實現因果網絡結構學習[13])。在因果圖中,節點對應于事件,箭頭對應于直接的因果關系。箭頭為子節點,箭尾為父節點,父節點就是子節點的直接原因。當然,因果圖是部分可驗證的。根據因果圖,我們可以輸出可驗證的數據,將其與實際數據進行對比,當兩者相沖突的時候,我們就需要修改因果圖,使得數據與因果假設能相互匹配。
在建立因果圖后,我們要確定事件X對事件Y的因果效應P(Y|do(X)),就要對X實施干預do操作。我們用do(X=x)或者do(x)來表示主動干預將變量X的值設定為恒定值x。此時,變量X不再受父變量影響,X的值由新的機制X=x唯一確定。這意味著,我們需要修改因果圖,將所有指向X的箭頭全部抹去(圖2)。其理由是,偽相關信息通過混雜因子Z在X和Y之間傳遞,造成X和Y之間的偽相關。那么將所有指向X的箭頭全部抹去后,X只能通過因果路徑到達Y,此時留下的相關性就等于真正的因果效應。

圖2
那么,我們如何從表達式中去除do算子,將干預概率轉化為條件概率,達到從觀測數據估計因果效應的目的呢?
常見的方法有以下幾種。第一種方法,后門調整[5]195。我們通過對混雜因子進行調整來阻斷混雜因子的影響,也可以通過調整其他的可替代的變量來同樣達到消除混雜的目的,這就是后門調整公式。第二種方法,前門調整[5]199。當混雜因子未知且找不到其他可替代變量的時候,可以嘗試使用前門調整公式。那有沒有一種方法將上面兩種方法囊括其中?有,它就是do演算[5]206。利用do演算三大規則和因果圖及其子圖,通過逐步的推導論證就有可能將表達式P(Y|do(X))轉化為一個沒有do算子的表達式。如果最后能得到只含有標準的條件概率的表達式,就說明我們能通過已觀測的數據準確無誤地估計出因果效應,我們就說表達式P(Y|do(X))是“可識別的”。
以因果圖為基礎的do演算能解決隨機對照試驗的部分問題:(1)可遷移性問題,即將在研究人群中得到的因果效應遷移到目標人群的問題,是外部有效性中一個更加具體的問題。珀爾和伊萊亞斯·巴倫拜姆(Elias Bareinboim)對其做了研究,并提出了解決方案。其核心是根據圖示使用do演算進行遷移運算,將前者的結果“遷移”到后者上來使用。[14]在整個過程中,珀爾等人的研究方法依賴于研究者具備充足的背景知識這一假設,即至少能定性地確定研究人群和目標人群間存在的差異和共性。在現實使用時,可能選擇圖中的大部分變量都存在較大差異,此時我們將無法實現可遷移性。因此,研究環境和目標環境嚴格相似是可遷移性能實現的一個必要條件。
(2)不完全依從性問題,指在隨機對照試驗中,試驗對象沒有完全遵守隨機分配的治療方案,試驗偏離了隨機控制的理想方案。不完全依從性會帶來問題,如果拒絕服藥的受試者恰恰是那些會產生不良反應的受試者,這時我們就會高估藥物的有效性。此情況下不能簡單地對比處理組和對照組的治療效果來評估藥物的有效性。結合反事實的結構模型,亞歷克斯·巴克(Alexander Balke)和珀爾針對此問題提出了解決方案。[15]
(3)其他的問題,如樣本選擇偏倚問題[5]330。從總體中抽取樣本時沒有強制要求,受試者自愿接受研究,那么納入研究的樣本很可能并不具有代表性,研究的樣本與總體在某些方面不一致,就會產生選擇偏倚。理想中如果總體中的所有單位都被納入到樣本中,也就是說將總體作為樣本進行研究,此時就能完全消除選擇偏倚的影響。利用do演算,也可以解決非代表性樣本引起的選擇偏倚問題。在因果圖中,根據樣本選擇機制,從影響樣本選擇的變量到選擇變量S添加箭頭,形成新的因果圖。再利用do演算規則推演公式,收集正確的去混數據集,之后便能通過公式調整來消除選擇偏倚。
三、結語
相關并不意味著因果。公雞打鳴和太陽升起高度相關,但公雞打鳴并不是太陽升起的原因。我們通過對比兩種干預狀態下因果效應的差異來判定兩個事件之間是否具有因果關系。使用do算子表示的假設性的干預,將前事件置于兩種不同的干預狀態下(如有和無),得到后事件的兩個結果,結果的差異就是因果效應差異。如果因果效應無差異,我們認為前者不是后者的原因;如果因果效應存在差異,我們認為前者是后者的原因,而差異的具體大小就表明了前者對后者的因果影響程度。所以,判定因果關系關鍵在于估計因果效應。本文介紹了混雜因子存在時準確估計因果效應的三種方法,即Z-調整、隨機對照試驗和以因果圖為基礎的do演算,并分析了這三種方法的應用場景和不足之處。
作為黃金標準的隨機對照試驗能準確估計因果效應,在于它消除了估計因果干預效應重要挑戰之一——混雜問題。混雜因子通常以共同原因Z的形式出現,它在兩個目標變量之間誘導產生偽相關,使最終得到的結果產生偏倚。隨機對照試驗通過隨機化處理消除混雜,可以看作是一個現實的進行人為干預的方法。
隨機對照試驗有其局限性和實施難題[16],而以因果圖為基礎的do演算將因果過程直觀化,結合觀測數據也可能實現對因果效應的有效估計。當然,“根據觀察性研究得出的這種因果估計很可能會被標記為‘暫時的因果關系’,即因果關系取決于我們繪制的因果圖所反映的一組假設”。[5]127但筆者認為這個努力邁出了重要的一步,它提供了一個可選的方案,在隨機對照試驗不可行的情況下,利用已有數據仍有機會實現對因果效應的無偏估計,進而回答我們感興趣的因果問題。“與其說‘do演算’是一個類公理的運算系統,倒不如說是人類認知能力的形式化與機械化嘗試”[17],而因果圖則可視為將人類思維能力直觀化和形式化的結果。筆者認為do演算未來的一個方向,在于提高整體的容錯性,特別是因果圖的容錯性。Do演算結果的準確性很大程度上取決于因果圖的準確與否:因果圖上多(少)一個變量,多(少)一個箭頭,就可能得到錯誤的因果效應,導致“差之毫厘,謬以千里”的后果。但筆者相信,這些問題終將迎刃而解。
猜你喜歡
核科學與工程(2021年4期)2022-01-12 06:30:26
今日農業(2020年19期)2020-12-14 14:16:52
小學生必讀(中年級版)(2020年9期)2020-12-04 02:07:22
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學物理·高中(2016年12期)2017-04-22 11:53:03
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
小櫻桃·童年閱讀(2014年11期)2014-12-01 22:21:30
