大數據系統與企業管理適配度評價指標權重確定研究
2024-05-09 00:51:52黃平根
技術與市場 2024年4期
黃平根
江西理工大學商學院,江西 贛州 338000
0 引言
是否能夠高度適配企業管理需求,是衡量大數據管理系統開發適用性和科學性的重要指標。目前,國內外關于大數據系統與企業管理適配度評價的研究較多,一些成熟的評價模型和算法也隨之提出,但已有模型和算法的匹配指標權重仍主要依靠經驗法確定,導致評價結果仍存在非線性、時變性和不穩定性問題。為提升大數據系統與企業管理適配度評價指標權重的精確度,本文引入消除非線性、時變性和不穩定性更優的“期望-熵”理論實施研究。
1 “期望-熵”理論概述
“期望-熵”理論由國內學者徐緒堪[1]提出,屬于管理學和信息科學交叉領域理論,內涵為:信息系統與管理服務對象之間的適配度評價可用期望值(Ev)、熵(En)和外延熵(Ec)3個數字特征值表示,并通過期望值的浮動規律予以確定。其中,Ev是信息系統與管理服務對象最佳適配的中心值,也是衡量兩者適配度的關鍵數值;En反映了信息系統與管理服務對象適配度的非線性和時變性干擾程度,數值在0.2~0.6時,兩者的非線性和時變性干擾程度較低;Ec反映了信息系統與管理服務對象適配度的不穩定性程度,數值在0.05~0.1時,兩者的不穩定性程度較低[2]。實際應用時,可通過專家選擇、逆向發生器計算指標特征值、獲取適配度權重值等步驟,確定信息系統與管理服務對象之間適配度的指標因素、權重等內容。
引入“期望-熵”理論確定大數據系統與企業管理適配度評價指標的權重,能夠規避經驗法確定指標權重存在的問題,通過Ev、En和Ec數據的加權呈現,得到期望值最優的評價指標權重數值,是大數據系統與企業管理適配度評價指標權重確定可探索和應用的最優方法之一。
2 大數據系統與企業管理適配度評價指標框架
在對已有研究文獻進行梳理的基礎上,本文創建了大數據系統與企業管理適配度評價指標框架,如表1所示。

表1 大數據系統與企業管理適配度評價指標
2.1 功能匹配度
用于衡量大數據系統開發的功能與企業管理需求之間的匹配度,具體通過功能是否完善及功能是否能夠拓展2個二級指標進行測評。
2.2 架構匹配度
用于衡量大數據系統硬件和軟件架構與企業管理應用之間的匹配度,具體通過數據架構應用是否適配及管理效果是否能得到顯著提升2個二級指標進行測評。
2.3 戰略匹配度
用于衡量大數據系統應用對企業管理戰略達成輔助效應,具體通過數據系統應用后對企業管理戰略達成效果的支持程度及表達性2個二級指標進行測評。
2.4 資源匹配度
用于衡量大數據系統開發配套資源與企業管理的適配度,具體通過數據系統開發現場環境是否優越、企業支持數據系統開發的政策是否到位2個二級指標進行測評。
3 大數據系統與企業管理適配度評價指標權重確定
3.1 權重等級范圍設置
本文以“期望-熵”理論為依據,從期望值、熵值語言描述、強度等級、權重范圍4個層面入手,編訂了大數據系統與企業管理適配度評價指標權重等級范圍描述表(見表2)。為了方便量化統計,為每個匹配指標分配“低、較低、一般、較高、高”5個語言描述等級。此外,根據語言描述等級,將權重強度等級范圍也分為5個,等級越高說明該指標因素影響強度越強。例如:一級指標“功能匹配度”對應的二級指標“功能完善因子”的權重期望值,可在專家選擇過程中從“低、較低、一般、較高、高”5個衡量等級中選取,選取結果也將被定量地映射到[0,1]區間,轉換為具體的期望值,供逆向發生器計算指標特征值、獲取適配度權重值等步驟參考應用。

表2 大數據系統與企業管理適配度評價指標權重等級范圍描述表
3.2 專家選擇
進行專家選擇是運用“期望-熵”理論確定指標權重的首要步驟,通過專家選擇能夠確定權重初值,為后期的深度運算提供原始數據。
為了使專家選擇確定的指標權重初值趨于科學合理,本文選擇20位專家,其中包含5名大數據系統研發的教授級專家、6名高校企業管理專業教授、6名上市公司企業高管、3名大數據系統資深項目經理。以“功能完善因子”指標專家選擇評價為例說明確定過程。①邀請專家結合自身對大數據系統、企業管理多年的開發實踐經驗,給出指標的熵值語言描述等級。②結合表2中的權重等級及范圍,將專家定性評價語言轉換為量化的權重范圍數值,并用統計學方法進行整理,繪制出20位專家關于“功能完善因子”適配度評價權重的散點分布圖(見圖1)。③根據散點分布圖,大致確定“功能完善因子”適配度評價權重數值范圍。
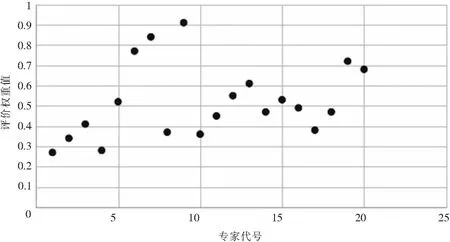
圖1 專家選擇給出的適配度評價指標權重散點圖
3.3 逆向發生器計算指標特征值
通過專家選擇獲取“功能完善因子”指標的初步權重后,仍需要通過逆向發生器計算指標的特征值,以考證指標權重的Ev、En和Ec,通過這3個特征值的量化表現,綜合判斷指標權重的非線性、時變性和不穩定性干擾程度,以確保指標權重最優。具體來說,將“功能完善因子”指標專家選擇確定的20個權重初值代入MATLAB[3]軟件中,再運用軟件中的逆向發生器算法進行計算,獲得對應的指標權重特征值。具體程序代碼如下。
Flag=0;
i=1;m=0;C1=C;D1=D;
While i<=(20-flag)
If D1(1,i)>0.99
D1(:,i)=[];C1(:,i)=[];
Flag=flag+1;
Else
I=i+1;
M=m+1;
End
End
Ex=mean(C1);En1=zeros(1,m);
For i=1:m
En1(1,i)=abs(C1(1,i))/sqrt(-3*log(D1(1,i)));
End
在MATLAB中新建工程項目[4],輸入上述程序內容,導入20個專家選擇確定的指標權重初值后,經過計算得到Ev為0.632 1、En為0.617 3、Ec為0.063 3。
3.4 獲取適配度權重值
由逆向發生器計算結果可知,“功能完善因子”指標的En為0.617 3,不在En值認定的非線性、時變性干擾最優值0.2~0.6;Ec為0.063 3,在Ec認定的不穩定性干擾最優值0.05~0.1,說明得到的指標期望Ev為0.632 1仍有待優化。因此,進一步在MATLAB軟件中運用逆向發生器過濾優化算法功能,對指標的特征值進行解析,獲取優化后的3個特征值為:Ev為0.641 7,En為0.3557,Ec為0.072 1,符合“期望-熵”理論確定的特征值最優情況,得到“功能完善因子”指標的影響強度為五級[5],其權重為0.64。其他匹配指標的確定采用同樣方法,最后得到完整的確定權重的大數據系統與企業管理適配度評價指標體系,如表3所示。

表3 確定權重的大數據系統與企業管理適配度評價指標體系
4 結束語
本文基于“期望-熵”理論確定大數據系統與企業管理適配度評價指標權重值,相較于以往的專家經驗確定權重方法,本文采用的方法能夠更好地考察指標權重的非線性、時變性和不穩定性,通過期望特征值描述評價指標權重的處理思路也更加科學合理,因此,最終確定出的評價指標權重體系也更為穩健,為企業成功建設和應用大數據管理系統提供了可靠保障。
猜你喜歡
今日農業(2022年15期)2022-09-20 06:56:20
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
石油瀝青(2021年4期)2021-10-14 08:50:44
云南畫報(2020年9期)2020-10-27 02:03:26
雜文月刊(2016年1期)2016-02-11 10:35:51
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
現代企業(2015年8期)2015-02-28 18:54:47
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
