基于改進YOLOv5s和傳感器融合的目標檢測定位
2024-05-10 11:38:12鄭宇宏曾慶喜冀徐芳王榮琛宋雨昕
河北科技大學學報 2024年2期
關鍵詞:深度學習
鄭宇宏 曾慶喜 冀徐芳 王榮琛 宋雨昕

摘 要:針對無人車環境感知過程中相機無法提供道路目標的位置信息,激光雷達點云稀疏以致檢測方面難以達到很好效果的問題,提出一種通過融合兩者信息進行目標檢測和定位的方法。采用深度學習中YOLOv5s算法進行目標檢測,通過聯合標定進行相機與激光雷達外參的獲取以轉換傳感器之間的坐標,使雷達點云數據能投影到相機圖像數據中,得到檢測目標的位置信息,最后進行實車驗證。結果表明,所提算法能在搭載TX2嵌入式計算平臺的無人車自動駕駛平臺上擁有27.2 Hz的檢測速度,并且在一段時間的檢測環境中保持12.50%的漏檢率和35.32 m的最遠識別距離以及0.18 m的平均定位精度。將激光雷達和相機融合,可實現嵌入式系統下的道路目標檢測定位,為嵌入式平臺下環境感知系統的搭建提供了參考。
關鍵詞:傳感器技術;深度學習;目標檢測與定位;無人車環境感知;相機與LiDAR融合
中圖分類號:TP242.6? 文獻標識碼:A? ??文章編號:1008-1542(2024)02-0122-09
Target detection and localization based on improvedYOLOv5s and sensor fusion
ZHENG Yuhong,ZENG Qingxi,JI Xufang,WANG Rongchen,SONG Yuxin
(College of Automation Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing, Jiangsu 211106, China)
Abstract:As two important sensors in the process of unmanned vehicle environment perception, the camera cannot provide the position information of the road target, and the LiDAR point cloud is sparse, which makes it difficult to achieve good results in detection, so that a method was proposed which fuses the information of the two sensors for target detection and localization. YOLOv5s algorithm in deep learning was adopted for target detection, and the external parameters of camera and LIDAR were acquired through joint calibration to convert the coordinates between the sensors, so that the radar point cloud data can be projected into the camera image data, and finally the position information of the detected target was obtained. The real vehicle experiments were conducted. The results show that the algorithm can achieve a detection speed of 27.2 Hz on the unmanned vehicle autopilot platform equipped with TX2 embedded computing platform, and maintain a leakage rate of 12.50%, a maximum recognition distance of 35.32 m, and an average localization accuracy of 0.18 m over a period of time in the detection environment. The fusion of LiDAR and camera can achieve road target detection and localization in embedded system, providing a reference for the construction of environment perception systems on embedded platforms.
Keywords:sensor technology; deep learning; target detection and localization; unmanned vehicle environment perception; camera and LiDAR fusion
對無人車行駛過程中的障礙物(如行人)進行檢測和定位是保障其行駛安全非常重要的一部分。相機、毫米波雷達、激光雷達等是無人駕駛領域最常用的感知傳感器[1-2],其中相機很容易受到光線、遮擋等環境因素的影響,而激光雷達在高線數下成本昂貴,低線數下點云稀疏[3]。如何結合不同傳感器的優缺點,進行準確有效的檢測定位,成為眾多學者研究的一個重要方向。
隨著大數據、神經網絡等相關技術的發展,深度學習的概念首次由加拿大學者HINTON等提出[4],由于其檢測精度和速度都優于傳統方法,成為當前的主流目標檢測算法。而基于深度學習的目標檢測算法可以分成2類:基于區域提取的Two-stage目標檢測算法,以及直接進行位置回歸的One-stage目標檢測模型。Two-stage目標檢測算法有R-CNN[5],SPP-Net[6],FastRCNN[7],FasterRCNN[8],Mask R-CNN[9]等,One-stage目標檢測算法有YOLO[10],YOLOv2[11],YOLOv3[12],SSD等。
基于激光雷達的方法在近距離情況下提供準確的深度信息,通過點云學習到幾何空間特征,但是由于遠距離情況下點云的稀疏特性,探測遠距離目標、小目標和形狀相似目標的性能還有待加強。相較于能夠提供豐富外觀特性但缺乏良好的深度估計信息的相機,激光雷達在三維任務中的表現顯然是優越的。這些互補特性促使基于激光雷達和相機信息融合的高精度三維目標檢測方法被越來越多的學者關注,旨在克服單一傳感器易受環境因素影響、抗干擾能力差的問題,從而提升整個感知網絡的可靠性、準確性。學者們開發了多種傳感器融合方案,如F-PointNet[13],ConvNet[14],MV3D[15],AVOD[16],MVFusion[17]等,但是這些傳感器方案在嵌入式系統中卻因為計算量大面臨實時性和檢測性能不能兼備的問題。
1 神經網絡算法設計
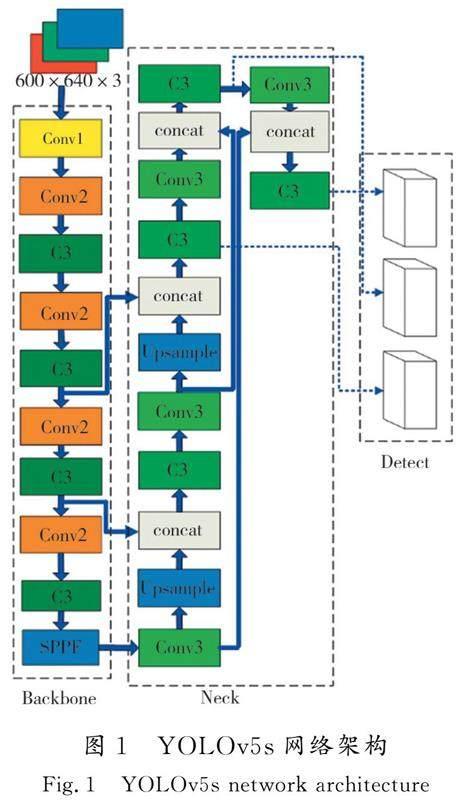
采用深度學習YOLOv5s模型作為目標檢測模塊。該算法采用CSP-DarkNet53結構作為主干,CSP-DarkNet作為一種CSPNet,通過將淺層的特征圖一分為二,分別通過特征提取模塊向后傳播以及跨過階級層次直接與特征提取模塊進行合并,能一定程度上解決主干網絡中信息重復的問題和緩解梯度消失的問題,有效減少模型FLOPs值和參數數量,加快推理速度。其架構示意圖如圖1所示。
其中Neck部分采用FPN+PAN的結構思路進行多尺度信息融合,并使用SPPF替代SPP來提高檢測速度和應對多尺度問題。在檢測頭中,采用CIOU LOSS 作為Bounding box 的損失函數。
注意力機制作為一種資源分配機制,核心思想是根據原有的數據找到其關聯性,然后突出重要的特征。YOLOv5s作為輕量化模型具有較少的參數量。為了更好地滿足在低光照環境下對道路目標檢測的要求,本文采用SENet模塊以增強網絡的表示能力[18],其分別通過Squeeze操作和Exciation操作實現所述功能。
首先是Squeeze,輸入一個維度為W×H×C的特征圖,其中W是width,H是height,C是channel,通過全局平均池化操作,獲得一個1×1×C的向量,見式(1)。
z=Fsq(uC)=1H×W∑Hi=1 ∑Wj=1u(i,j)。(1)
其次是激勵(Exciation),它由2個全連接層組成。第1個全連接層有C×S個神經元,S為一個縮放參數,輸入為1×1×C,輸出為1×1×C×S;第2個全連接層有C個神經元,輸入為1×1×C×S,輸出為1×1×C。最后通過sigmoid激活限制到[0,1]的范圍得到權重矩陣,將權重矩陣和特征圖的C個通道進行相乘計算以賦予權重,作為下一級的輸入。其公式為
S=Fex(Z)=σ(W2δ(W1Z)),(2)
式中:W1和W2作為門控制機制,W1∈Rcr×c,W2∈Rc×cr;σ表示sigmoid函數;r為一個固定參數。
YOLOv5s主干特征提取網絡采用C3結構,帶來較大的參數量,當運用在嵌入式系統時,大量的參數量帶來的將是更長的處理時間。本文將主干特征提取網絡替換為更輕量的Ghost網絡[19],以實現網絡模型的輕量化,平衡速度和精度。Ghost Module主要包括常規卷積、Ghost生成和特征圖拼接3步。首先用常規卷積Yw*h*m得到本征特征圖Yw′*h′*m:
Y′=X*f′ ,(3)
然后將Y′每一個通道的特征圖y′i,用Depthwise卷積實現的線性操作Φi,j來產生Ghost特征圖
yij:yij=Φi,j(y′i), i=1,2,…,m, j=1,2,…,s,(4)
最后將第1步得到的本征特征圖和第2步得到的Ghost特征圖拼接(identity連接)得到最終結果Output。
由于YOLOv5s主干特征提取網絡采用C3結構,其參數量較大,在嵌入式設備中運用較為局限,因此采用Ghost瓶頸結構對YOLOv5s網絡中的C3模塊進行改進,將C3模塊中添加輕量化的Ghost瓶頸網絡,這樣就能有效減少計算參數數量,使得整個網絡的速度和效率大大增加。最后修改得到的網絡架構如圖2所示。
模型訓練采用公開數據集KITTI[20]。從檢測精度、速度、計算復雜度等方面對最新的檢測算法和本文提出的檢測模型進行比較。KITTI數據集是由德國卡爾斯魯厄理工學院和豐田工業大學芝加哥分校聯合贊助的用于自動駕駛領域研究的數據集,包含市區、鄉村和高速公路,采集過程是在德國的卡爾斯魯厄進行的,檢測目標包括Car,Van,Truck,Tram,Pedestrian,Person_sitting,Cyclist和misc 8類,本文將Car,Van,Truck和Tram合為一類Car,將Person和Person_sitting合為一類Pedestrian,忽略Misc類,最后檢測Car,Pedestrian和Cyclist 3類,一共7 481個訓練圖像和7 518個測試圖像。由于標簽的格式和YOLOv5s模型的格式不一致,通過腳本將其轉換成YOLOv5s所需要的.txt格式以進行模型的訓練。
為了驗證本實驗所用模型的性能,選取精準率、召回率、平均精度和幀率作為模型的評價指標。精準度評價指標為
Precision=TPTP+FP,(5)
式中:FP為負類預測為正類;TP為正類預測為正類。召回率評價指標為
Recall=TPTP+FN,(6)
平均精度指標為
mAP=∫10P(R)dR,(7)
對不同的模型設置相同的訓練參數,將Batchsize設置成16,初始學習率大小為0.01,訓練50個epoch,訓練和測試結果如表1所示。
2 聯合標定實驗
2.1 聯合標定模型
假設點云在以激光雷達為原點的坐標系下的具體坐標為(Xl,Yl,Zl)T,在相機坐標系下空間坐標為
(Xc,Yc,Zc)T;K是相機內參,K∈R3×3;(u,v,1)T是點云在像素平面上的投影點。
將點云由激光雷達坐標系變換到相機坐標系:
XcYcZc=RXlYlZl+t ,(8)
式中R和t分別為激光雷達和相機之間的旋轉矩陣和平移向量,即激光雷達和相機的外參。再由相機坐標系變換到歸一化平面坐標系,并投影到像素平面上:
uv1=KXcZcYcZc1。(9)
根據圖像大小判斷投影點(u,v,1)T是否在圖像上,保留投影在圖像上的投影點并在圖像上標出,建立圖像投影點和立體點云的對應關系[21]。
利用機器人操作系統(ROS)進行數據通信,然后進行外參R,t的調整,濾除距離遠處的點云,就能找到點云投影點和圖像像素的真實對應關系,使點云投影點和圖像像素盡可能重合。如圖3所示,OwXwYwZw是標定板坐標系,OcXcYcZc是相機坐標系,OlXlYlZl為激光雷達坐標系。Pci是相機坐標系下標定板的單位法向量,Pli是激光雷達坐標系下標定板的單位法向量。
tci是相機坐標系原點Oc到標定板坐標系原點Ow的平移向量,tli是激光雷達坐標系Ol到標定板坐標系原點Ow的平移向量[22]。
假設:
Pc=[Pc1Pc2…Pc(n-1)Pcn],(10)
Pl=[Pl1Pl2…Pl(n-1)Pln],(11)
分別為2個坐標系下n個標定位置的n個法向量組成的矩陣,由夾角余弦之和最大可求得:
R=argmaxR∑niPTciRPli=argmaxRtr(RPlPTc),(12)
解得R′=VUT,其中V和U由矩陣奇異值分解USVT=PlPTc得到。
由坐標系關系可知,激光雷達坐標系和相機坐標系的原點到標定平面的距離差為
PciT=‖Pcitci‖-‖Plitli‖。(13)
對于n個標定位置,取目標函數為
T=minT∑ni=1[PTciT-(‖Pcitci‖-‖Plitli‖)]2,(14)
其等價為求使‖PTcT-(PTlT1-PTcT2)‖2最小的列向量T,其中T1=tc1tc2…tcn,T2=tl1tl2…tln,通過最小二乘法求解得到:
T=(PcPTc)-1Pc(PTlT1-PTcT2)。(15)
可知若進行聯合標定,需要固定激光雷達和相機之間的位置關系,采集足夠多點的數據進行計算。
2.2 相機內參標定
相機的內參標定首先要準備一塊9 m×6 m×0.024 m的標定板,借助OpenCV的相機標定工具完成內參標定[23],圖4為標定界面。
通過改變標定板在畫面中的位置、遠近、角度等,收集到足夠多的數據進行標定,輸出一個.yaml文件,其中就包含相機的內參矩陣R和畸變系數向量t。相機的內參包含4個參數,即fx,fy,u0和v0。其中fx也就是f/dx,fy也就是f/dy,f代表的是焦距,dx和dy代表的像元密度,也就是在像素坐標系下每一個像素分別在x和y方向分別占用了多少個單位,fx和fy代表了焦距f在x方向和y方向上的投影,u0和v0為感光板在坐標系x方向和y方向下的坐標。這4個參數就構成了相機內參,當經過標定獲得了這些參數就能夠把模型完整的表達出來。
內參標定結果如下:
R=502.889 760303.387 440504.454 30249.910 56001,t=0.082 64-0.100 470.000 71-0.000 610?? T。
2.3 相機和激光雷達聯合標定
激光雷達配置成功后進行相機與激光雷達的聯合標定,激光雷達和相機安裝位置如圖5所示。
然后用相機和激光雷達進行錄包操作,手持標定板在不同的位置停留5 s左右,在不同的位置都采集一定數量的數據,包括近點靠左、近點靠中、近點靠右、遠點靠左等。在不同的位置時,手持標定板的傾斜幅度也需要進行調整,以便獲得更多的數據。
包錄制完成后,打開Autoware的Camera Calibration Tools,通過ROS進行傳感器數據的通信,然后先導入上文中標定獲得的內參文件,然后對實現錄制好的包進行播放,先調整點云顯示區的角度、亮度等使后續標定板能夠較清晰地呈現,對包中合適的圖片和點云進行Grab收集,然后對每一張點云圖進行手動標記,最后點擊右上角Calibrate鍵獲得標定結果。由于標定板較小,16線雷達點云密度相對稀疏,因而需要多次進行標定以確保標定的準確性,標定界面如圖6所示。點擊右上角的Project鍵,外參文件即被輸出到home文件夾下[24]。
計算得到外參矩陣如下:
R=499.637 440327.010 530500.102 49235.770 21001,t=0.104 19-0.204 82-0.002 25-0.001 510.164 47[JB))]T。
2.4 傳感器時間同步
不同種類的傳感器運行頻率不相同,掃描頻率和信號的傳遞速度也存在偏差,因此就需要數據幀同步的方式對數據進行對齊。常見的數據幀同步方法主要包括硬件同步方式以及軟件同步方式[25],本文采用的相機和激光雷達的融合方式并不存在能夠同步觸發的硬件同步方式,因此采用軟件同步的方式。
本文采用ROS機器人操作系統來對不同傳感器進行數據幀同步[26],使用的是message_filters::Synchronizer時間同步器,通過設置閥門,只有當在同一時間戳同時接收到2個傳感器的數據時才控制消息的輸出,以達到數據對齊的目的。其工作原理大致是:首先相機和激光雷達分別發布話題/image_raw和/point_raw,然后message_filters::Synchronizer時間同步器程序訂閱2個話題,在回調函數中對同步結果進行輸出,當時間同步對齊時,繼續進行點云和圖像數據的處理,否則就繼續等待時間同步的話題數據到來。而判斷2個傳感器的數據是否對齊則是根據2個傳感器的時間戳的差值是否小于某一閾值。本文所用的激光雷達發布話題的頻率是10 Hz,相機發布話題的頻率是30 Hz,當2個話題的時間戳差值在0.1 s以內時就可以將2個數據同步輸出,認為其已經同步對齊,當時間戳的差值大于0.1 s或者有1個傳感器沒有數據傳輸到時間同步器的時候,都不能正常觸發回調函數將數據輸出,如圖7所示。
3 試驗驗證
無人車試驗平臺在設計上分為底層和上層2個部分。底層由STM32單片機作為主控制器,進行車體的運動控制;上層由NVIDA Jetson TX2嵌入式開發板控制,分別接入單目相機、激光雷達。
激光雷達選用鐳神的16線激光雷達,相機采用感光元件為200萬1/2.8CMOS的60幀1080p馳圖運動相機攝像頭,在檢測的時候,會將相機實際拍攝獲得的圖像通過自適應圖像縮放的方式變成640×640大小的圖像送入網絡模型中進行處理。
試驗平臺為自主研發的智能自動駕駛無人車,如圖8所示。
所用軟件平臺為基于ARM架構的ubuntu18.04系統,算法框架主要在ROS melodic系統中開發運用,GPU為NVIDIAPascalTM,256 CUDA cores,CPU為dual-core NVIDIA Denver2+quad-core ARM Cortex-A57,TensorRT版本為8.2.1,Cuda版本為10.2,系統內核為LinuxUbuntu 4.9.253-tegra。Jetson TX2運行Autoware自動駕駛框架、Pytorch深度學習框架、ROS機器人操作系統,分別負責傳感器之間的標定配準和融合、深度學習模型的部署和訓練,不同傳感器和模塊之間的數據通信。上層主要負責圖像和激光數據的采集處理以及算法的實現,底層則主要負責無人車的運動控制,如圖9所示。
將激光雷達和運動相機安裝到阿克曼無人車上,并采用TTL轉USB的轉接線將無人車控制器和TX2相連接,在前方出現行人或者障礙物時無人車能順利地進行避障或者制動。無人車沿著學校道路進行駕駛,運行過程中,激光雷達不斷采集周圍物體的點云信息并通過預處理進行特征采集,相機則是通過YOLOv5s神經網絡對前方采集到的圖像進行道路目標檢測,對周圍的目標進行檢測以及定位,如圖10—圖12所示。
對于采集到的數據包也分別采用YOLOv5s,CenterPoint和Autoware中的LiDAR+SSD算法進行處理,漏檢率以圖像的框選率為基準。當一個目標在15 m內還沒有被正確檢出,則判定其為漏檢,用漏檢的目標數量比總目標數量,得出的結果就為漏檢率。最遠檢測距離為能檢測到的最遠的行人的距離,平均定位精度為所有目標被檢出后激光雷達對其進行定位距離和其物體質心的定位距離差值的平均值。對一段時間內學校校內門口處和天橋底下路過的行人,車輛、自行車進行檢測和定位,定位真值以事先用激光測距儀的測量數據為準,具體結果如表2所示。
其中影響最遠檢測距離的主要因素是對小目標的檢測性能,對小目標檢測性能好的檢測器在這個部分的表現性能較好。由于本文使用的激光雷達為16線,點云比較稀疏,所以CenterPoint點云檢測算法表現性能較差。影響平均定位精度的主要是檢測框對檢測物體的擬合性能,歐氏聚類算法在這個部分表現性能差。
4 結 語
本文在Jetson TX2嵌入式系統中,采用激光雷達和相機融合技術和基于深度學習YOLOv5s的目標檢測算法,實現了目標檢測和定位系統的設計和開發。通過實車試驗實現了道路目標的檢測和定位,結果顯示在一段時間的檢測環境中實現了12.50%的漏檢率,最遠識別距離達到了35.32 m。
本文采用的傳感器融合系統考慮到嵌入式系統計算能力有限,主要是進行決策級的融合,沒有對異構傳感器的原始數據進行融合處理,未來還需對融合算法進行進一步的改進,使得算法能夠更好地利用不同傳感器的優點,提高算法的魯棒性。
參考文獻/References:
[1] 蔣婷.無人駕駛傳感器系統的發展現狀及未來展望[J].中國設備工程,2018(21):180-181.JIANG Ting.Development status and future prospects of autonomous driving sensor systems[J].China Plant Engineering,2018(21):180-181.
[2] 余世全.無人駕駛汽車的發展現狀和相關建議[J].專用汽車,2023(1):11-14.YU Shiquan.The development status of driverless vehicles and related suggestions[J].Special Purpose Vehicle,2023(1):11-14.
[3] 張保,張安思,梁國強,等.激光雷達室內定位技術研究及應用綜述[J].激光雜志,2023,44(3):1-9.ZHANG Bao,ZHANG Ansi,LIANG Guoqiang,et al.A review of LIDAR indoor positioning technology research and application[J].Laser Journal,2023,44(3):1-9.
[4] HINTON G E,OSINDERO S,TEH Y W.A fast learning algorithm for deep belief Nets[J].Neural Computation,2006,18(7):1527-1554.
[5] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:580-587.
[6] MSONDA P,UYMAZ S A,KARAA[AKGˇ]A S S.Spatial pyramid pooling in deep convolutional networks for automatic tuberculosis diagnosis[J].Traitement du Signal,2020,37(6):1075-1084.
[7] GIRSHICK R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago:IEEE,2015:1440-1448.
[8] REN Shaoqing,HE Kaiming,GIRSHICK R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[9] HE Kaiming,GKIOXARI G,DOLLR P,et al.Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:2980-2988.
[10]REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:Unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:779-788.
[11]REDMON J,FARHADI A.YOLO9000:Better,faster,stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6517-6525.
[12]REDMON J,FARHADI A.YOLOv3:An Incremental Improvement[EB/OL].https://export.arxiv.org/abs/1804.02767,2018-04-08.
[13]QI C R,LIU Wei,WU Chenxia,et al.Frustum PointNets for 3D object detection from RGB-D data[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:918-927.
[14]WANG Zhixin,JIA Kui.Frustum ConvNet:Sliding frustums to aggregate local point-wise features for amodal 3D object detection[C]//2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).Macau:IEEE,2019:1742-1749.
[15]CHEN Xiaozhi,MA Huimin,WAN Ji,et al.Multi-view 3D object detection network for autonomous driving[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6526-6534.
[16]KU J,MOZIFIAN M,LEE J,et al.Joint 3D proposal generation and object detection from view aggregation[C]//2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).Madrid:IEEE,2018:1-8.
[17]FADADU S,PANDEY S,HEGDE D,et al.Multi-view fusion of sensor data for improved perception and prediction in autonomous driving[C]//2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV).Waikoloa:IEEE,2022:3292-3300.
[18]王玲敏,段軍,辛立偉.引入注意力機制的YOLOv5安全帽佩戴檢測方法[J].計算機工程與應用,2022,58(9):303-312.WANG Lingmin,DUAN Jun,XIN Liwei.YOLOv5 helmet wear detection method with introduction of attention mechanism[J].Computer Engineering and Applications,2022,58(9):303-312.
[19]李北明,金榮璐,徐召飛,等.基于特征蒸餾的改進Ghost-YOLOv5紅外目標檢測算法[J].鄭州大學學報(工學版),2022,43(1):20-26.LI Beiming,JIN Ronglu,XU Zhaofei,et al.An improved Ghost-YOLOv5 infrared target detection algorithm based on feature distillation[J].Journal of Zhengzhou University(Engineering Science),2022,43(1):20-26.
[20]王麒.基于深度學習的自動駕駛感知算法[D].杭州:浙江大學,2022.WANG Qi.Deep Learning-Based Algorithms for Autonomous Driving Perception[D].Hangzhou:Zhejiang University,2022.
[21]常昕,陳曉冬,張佳琛,等.基于激光雷達和相機信息融合的目標檢測及跟蹤[J].光電工程,2019,46(7):85-95.
CHANG Xin,CHEN Xiaodong,ZHANG Jiachen,et al.An object detection and tracking algorithm based on LiDAR and camera information fusion[J].Opto-Electronic Engineering,2019,46(7):85-95.
[22]王俊.無人駕駛車輛環境感知系統關鍵技術研究[D].合肥:中國科學技術大學,2016.WANG Jun.Research on Key Technologies of Environment Awareness System for Driverless Vehicles[D].Hefei:University of Science and Technology of China,2016.
[23]李莉.OpenCV耦合改進張正友算法的相機標定算法[J].輕工機械,2015,33(4):60-63.LI Li.Camera calibration algorithm based on OpenCV and improved Zhang Zhengyou algorithm[J].Light Industry Machinery,2015,33(4):60-63.
[24]歐陽毅.基于激光雷達與視覺融合的環境感知與自主定位系統[D].哈爾濱:哈爾濱工業大學,2019.OUYANG Yi.The Environment Awareness and Autonomous Positing System Based on LiDAR and Vision[D].Harbin:Harbin Institute of Technology,2019.
[25]陳德江,江灝,高永彬,等.基于16線激光雷達和相機融合的三維目標檢測[J].智能計算機與應用,2023,13(3):117-122.CHEN Dejiang,JIANG Hao,GAO Yongbin,et al.3D target detection based on fusion of 16-line LiDAR and camera[J].Intelligent Computer and Applications,2023,13(3):117-122.
[26]曾彪.基于多傳感器信息融合的機器人建圖研究與實現[D].成都:電子科技大學,2021.ZENG Biao.Research and Implementation of Robot Mapping Based on Multi-sensor Information Fusion[D].Chengdu:University of Electronic Science and Technology of China,2021.
責任編輯:馮民
基金項目:國家自然科學基金(51505221);南京航空航天大學研究與實踐創新項目(xcxjh20220337)
第一作者簡介:鄭宇宏(1997—),男,湖南邵陽人,碩士研究生,主要從事機器人環境感知方面的研究。
通信作者:曾慶喜,副教授。E-mail:Jslyzqx@163.com鄭宇宏,曾慶喜,冀徐芳,等.基于改進YOLOv5s和傳感器融合的目標檢測定位[J].河北科技大學學報,2024,45(2):122-130.ZHENG Yuhong,ZENG Qingxi,JI Xufang,et al.Target detection and localization based on improved YOLOv5s and sensor fusion[J].Journal of Hebei University of Science and Technology,2024,45(2):122-130.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
