涉海翻譯中的機器翻譯應用效能:基于BLEU、chrF++和BERTScore指標的綜合評估
2024-05-15 05:20:37劉世界
中國海洋大學學報(社會科學版) 2024年2期


摘 要:深度學習技術和生成式人工智能技術已在機器翻譯領域引發質的變革,為該領域的進步開辟了新徑。為綜合評價不同技術和算法背景下的機器翻譯在涉海領域的應用效能,構建涵蓋100個代表性涉海例句的中英雙語方向的測試集,基于涉海文本的語言結構特點選取BLEU、chrF++和BERTScore 3種自動評估指標,對人工智能助手ChatGPT(4.0)和文心一言(4.0),及Google Translate、Microsoft Translator、DeepL Translate、Tencent TranSmart、百度翻譯和有道翻譯等六大主流翻譯引擎的譯文進行定量定性評估。實驗結果既為理解機器翻譯系統在涉海領域的應用效能提供了實證支撐,又為機器翻譯技術開發者提供了關于算法優化和翻譯精度提升方面的見解,同時為涉海專業人士選擇合適的翻譯系統提供了實用指引。
關鍵詞:涉海翻譯;機器翻譯應用效能;BERTScore;BLEU;chrF++
中圖分類號: I305.9文獻標識碼:A文章編號:1672-335X(2024)02-0021-11
DOI:10.16497/j.cnki.1672-335X.202402003
機器翻譯,尤其是隨著深度學習的發展而興起的神經機器翻譯,已成為突破語言障礙、提高交流效率的關鍵。隨著全球海洋經濟的增長,特別是在涉海領域,對跨語言信息交流的高效、精確需求日增。盡管深度學習和生成式人工智能技術顯著提升了機器翻譯的質量與效率,但處理涉海文本仍具挑戰。這類文本常含密集的專業術語、領域知識和復雜概念,翻譯精確度和專業性要求較高。因此,評估機器翻譯在此領域的應用效能,對推動技術進步和滿足行業需求具有重要意義。
當前,機器翻譯質量評估領域常用的評估指標包括BLEU[1]、METEOR[2]、chrF[3]、chrF++[4]、BERTScore[5]、COMET[6]和BLEURT[7]。這些指標從詞匯準確性、語法流暢度以及語義保留等維度評估翻譯質量,為不同領域中機器翻譯的應用效能提供了量化評估基準。為此,本研究嘗試構建中英雙語的涉海領域測試集,選取包括大語言模型支持的人工智能助手ChatGPT(4.0)、文心一言(4.0)及其他六大主流翻譯引擎作為評估對象(統稱為“翻譯系統”),針對涉海文本的獨特語言結構,采用BLEU、chrF++和BERTScore三個自動化評估指標,旨在綜合評估機器翻譯在涉海領域的應用效能與局限。通過定量指標數據和定性案例分析,深入探討翻譯系統在處理專業術語、領域知識、復雜句式方面的能力,為機器翻譯在涉海領域的應用提供新見解。
一、BLEU、chrF++和BERTScore評估指標
本部分將探討與解析本研究所采用的三種評估指標——BLEU、chrF++和BERTScore。
BLEU(Bilingual Evaluation Understudy)由Papineni等人于2002年提出,它通過計算機器翻譯輸出與一組參考翻譯之間的n-gram重疊來評估翻譯的準確性。[1]BLEU的核心在于n-gram匹配,涉及1-gram到4-gram的匹配,并通過修正的精確度計算來避免過度懲罰短譯文。由于其簡單性和高效性,BLEU成為當前機器翻譯評估的黃金標準,但它也因在翻譯的語義準確性和流暢性方面缺乏敏感性而受到批評。[8]盡管如此,BLEU仍然被廣泛用作機器翻譯性能評估的指標之一,特別是在WMT(Workshop on Machine Translation)等國際機器翻譯評測活動中。BLEU分數的范圍是0到1,其中0表示完全不匹配,1表示完全匹配。在行業評估實踐中,BLEU分數通常轉換為百分制,以使得評估結果易于理解和比較,也方便非專業人士快速把握翻譯系統的性能水平。
chrF++(Character n-gram F-score)是由Popovic′于2017年提出的機器翻譯評估指標chrF的改進版本,它通過計算字符級的n-gram F-score來評估翻譯質量,以此來補充基于詞級別n-gram計算的傳統評估方法(如BLEU)的不足。這種方法適用于處理語言結構差異大或非標準表達的語言,因為它能更細致地捕捉語言的微妙差異(如拼寫、詞形變化等)。[4]chrF++還引入了加權因子,以平衡不同長度n-gram的影響,從而提高評估的準確性和公平性。由于這些特點,chrF++已經被納入WMT評測活動的評估指標體系中,作為補充BLEU和其他評估指標的一部分,幫助研究人員和開發者從多個角度評估和理解機器翻譯系統的性能。
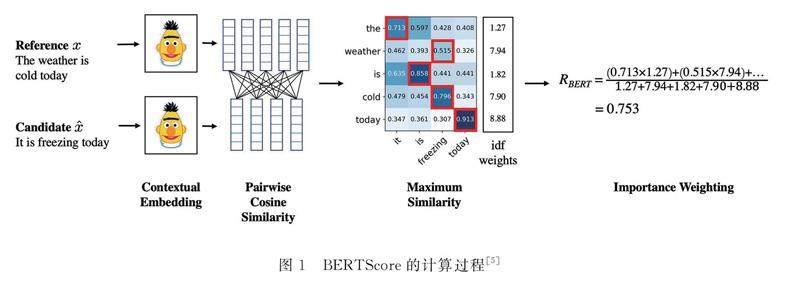
BERTScore由Zhang等人于2020年提出,是一種利用預訓練的BERT模型計算候選翻譯和參考句子之間語義相似度的評估指標。在研究中他們采用BERTScore及相關指標評估363個機器翻譯和圖像描述系統的輸出,實驗結果表明BERTScore與人類評價的相關性更好,魯棒性更強,并且相比現有的評估指標,BERTScore提供了更強的模型選擇性能。[5]BERTScore通過計算詞嵌入之間的余弦相似度來評估翻譯質量,為評估提供了基于語義的新視角,這使得BERTScore在處理同義詞和復雜句子結構時能夠更好地捕捉到翻譯中的細微語義差異。具體計算過程如圖1所示。
二、研究方法
(一)數據收集
在構建英譯中(E2C)和中譯英(C2E)兩個方向的涉海翻譯測試集(各50條例句)的過程中,采用嚴格的標準選取測試例句,確保測試集最大程度地覆蓋涉海領域的關鍵概念、專業術語和主要場景。這些內容包括但不限于法律與政策(海事海洋法律法規、海事審判報告)、工程與技術(船舶工程、海洋工程)、環境與生態(海洋環境、海洋生物資源)、文化與社會(海洋文化、海洋史)、經濟與發展(航運業發展)等。對于部分缺少參考譯文的例句,邀請三位涉海領域專家討論確立高質量參考譯文,保證專業性和準確性。此外,為避免任何潛在的順序效應(order effects),[9]測試集例句隨機打亂編碼,確保評估的客觀性和公正性。
(二)系統/助手選取
本研究選取具有代表性的神經機器翻譯系統和大語言模型支持的人工智能助手(翻譯功能)進行評估,包括Google Translate(Google)、Microsoft Translator(Microsoft)、DeepL Translate(DeepL)、Tencent TranSmart(TranSmart)、百度翻譯、有道翻譯,以及人工智能助手ChatGPT(4.0)(GPT)和文心一言(4.0)(文心一言)。雖然ChatGPT(4.0)和文心一言(4.0)本質上不是專門設計用于機器翻譯的系統,但它們作為大語言模型支持的人工智能助手,同樣具備處理翻譯任務的能力。選擇這些系統和助手是基于它們的技術領先地位和廣泛應用,以及它們在訓練過程中使用的不同規模和領域的數據集,這些因素可以反映出各自的性能特點和應用差異。每個翻譯系統或人工智能助手的背后,都是數十億甚至數萬億個詞匯的龐大訓練數據集,覆蓋廣泛的主題和領域,適合作為工業界機器翻譯技術的代表,評估機器翻譯在涉海領域的應用效能和局限。在譯文輸出過程中,人工智能助手未使用結構化的提示詞進行引導,所有機器譯文輸出時間均為2024年2月18日。
(三)實驗參數
在計算BLEU指標評分時,在Python中采用jieba分詞處理漢語譯文(英文譯文無需額外的分詞處理),并調用NLTK庫中的SmoothingFunction().method4作為BLEU得分計算的平滑方法,旨在解決當測試集中出現未在訓練集中見過的n-gram時BLEU得分計算結果為零的問題。同時將n-gram權重等同設置(每個1-gram到4-gram的權重為0.25),這種權重分配方法符合BLEU評分中廣泛認可和默認采用的標準實踐。
在計算chrF++指標評分時,本研究遵循Popovic′于2017年所提出的方法[4]進行編程,調用sacreBLEU庫中的CHRF模塊對測試譯文進行評分。在初始化CHRF對象的過程中,特別設置了幾個關鍵參數,以確保評分體系既能反映詞序與字符序的重要性,又能保證評分的穩定性和可靠性。具體而言,詞序權重設為2,旨在適度懲罰譯文中的詞序錯誤,以體現詞序在翻譯質量中的作用;字符序權重則設為6,強調字符級別匹配的重要性,以捕捉翻譯中的部分正確匹配情況;平滑因子beta設為2,目的是平衡精確率(precision)和召回率(recall),避免極端情況下的評分失衡。
BERTScore指標評分的計算涉及E2C和C2E兩個方向的模型選擇及參數設置。在E2C方向的BERTScore指標得分計算中,基于BERTScore庫的默認設定,采納預訓練的bert-base-chinese模型處理中文譯文。該模型作為專為中文文本設計的BERT模型版本,能夠有效地揭示中文文本間的語義相似性,被認為是進行中文得分計算的理想工具。針對C2E方向的得分計算,則選用了microsoft/deberta-xlarge-mnli模型。DeBERTa模型(Decoding-enhanced BERT with disentangled attention)通過解耦注意力機制和增強解碼功能,在文本理解及表達上超越標準BERT架構,而microsoft/deberta-xlarge-mnli作為一種擴展規模的DeBERTa模型,在多項自然語言理解(NLU)任務上的預訓練背景賦予了其在處理英文文本時,特別是在解析英文中復雜的語義關系與識別句間隱含意義上的卓越性能。因此,通過指定microsoft/deberta-xlarge-mnli模型來執行C2E方向上的BERTScore指標計算,可確保研究獲得更精細準確的語義相似度評估結果。
三、結果與討論
(一)定量分析
1.BLEU和chrF++指標評分結果
對兩個翻譯方向的測試集進行BLEU及chrF++指標評估,具體得分結果整理成表1。通過表格數據的橫向及縱向分析,初步觀察到:(1)文心一言在E2C方向的BLEU指標及E2C和C2E兩個方向的chrF++指標上表現良好;(2)TranSmart在E2C方向的chrF++指標得分顯著;(3)有道翻譯在C2E方向的BLEU得分較高,顯示出其在中譯英方面的優勢;(4)GPT在兩個翻譯方向的BLEU和chrF++指標表現最差;(5)在chrF++指標評估中,C2E方向上的得分普遍高于E2C方向,這可能歸因于英語作為目標語言時,翻譯輸出中字符級別的匹配和詞序的正確性相對更易于實現,與chrF++自身的評估方法與原理有較強的關聯性;(6)即便是在兩個指標中表現最佳的翻譯系統,得分也主要集中在20至60分之間,這一分布可能受文本測試集規模、復雜度和評估方法自身局限性的影響。上述觀察和初步分析是基于量化結果的探索性總結,為了綜合評估各翻譯系統在處理涉海文本翻譯中的應用效能,還需結合BERTScore指標的評分結果及定性案例分析來進一步驗證。
2.BERTScore指標評分結果
依據Zhang等人所提出的BERTScore評估方法,[5]并針對具體任務特性進行編程,以實現對E2C及C2E兩個翻譯方向上的測試集進行詳細的評估。具體而言,計算測試集中各個測試句在BERTScore指標上的得分表現(如表2所示),繪制各翻譯系統在兩個翻譯方向上的F1得分分布圖(如圖2所示)和比較圖(如圖3所示)。盡管BERTScore提供包括精確率、召回率和F1得分在內的三項評估指標,但F1得分作為精確率與召回率的調和平均值,能夠提供一個平衡兩者的綜合效能評價指標。在機器翻譯質量的評估過程中,依賴單一的精確率或召回率指標可能無法全面揭示翻譯質量的多維度特征。高精確率可能反映出翻譯過度保守,而高召回率可能意味著翻譯輸出包含較多的不精確元素。F1得分通過平衡精確率和召回率,能夠全面評價翻譯系統的應用效能,反映其在保持翻譯準確性與覆蓋原文意義之間的平衡能力。因此,本研究選用F1得分作為評估翻譯系統應用效能的主要指標。
基于圖表信息及測試集評分數據,歸納出以下關鍵發現:(1)在E2C方向上,TranSmart的平均F1得分最高(0.890),而在C2E方向上,文心一言的平均F1得分最高(0.859);(2)在E2C方向上,TranSmart的標準差最大(SD=0.046),而在C2E方向上,DeepL的標準差最大(SD=0.045),反映了這些系統在處理不同句子時性能的波動性較大;(3)文心一言在兩個翻譯方向上均展現了最大的F1得分(E2C為0.986,C2E為0.974);(4)各翻譯系統在E2C方向的F1得分普遍高于C2E方向。
在實施單因素方差分析(ANOVA)之前,采用Shapiro-Wilk檢驗[10]對數據集的正態分布假設進行驗證,以確保滿足ANOVA分析的前提條件。Shapiro-Wilk檢驗的結果揭示,部分翻譯系統在特定翻譯方向上的數據未能通過正態性檢驗,具體包括GPT、DeepL、TranSmart、有道翻譯在E2C方向上,以及Google與Microsoft在C2E方向上,均顯示p值小于0.05,表明這些系統的F1得分分布不符合正態分布,抑或揭示了機器翻譯系統性能分布的內在復雜性。
鑒于部分數據未滿足正態分布的假設,研究又采用Kruskal-Wallis檢驗[11]作為ANOVA的非參數替代方法,以評估不同翻譯系統間F1得分的統計學差異。該檢驗不依賴于數據的正態分布假設,也不要求各組方差一致,適用于本研究。檢驗結果顯示,在E2C方向上,不同翻譯系統的應用效能存在統計學意義上的顯著差異(H(7,400)=24.308,p<0.05),這表明至少一個翻譯系統的應用效能顯著不同于其他系統。而在C2E方向上,未觀察到統計學意義上的顯著差異(H(7,400)=9.894,p=0.195),這表明所有翻譯系統在該方向任務上的應用效能相對一致。
為進一步考察在E2C方向上特定翻譯系統間的應用效能差異,進行Kruskal-Wallis檢驗拒絕零假設之后適用的Dunn的多重比較檢驗,[12]并依據Dunn于1961年所提出的建議[13]對結果進行Bonferroni校正,以降低在多重比較過程中產生第一類錯誤(即假陽性)的風險。Dunn測試的結果表明,GPT與DeepL、TranSmart、文心一言及有道翻譯之間在E2C方向上存在統計學意義上的顯著應用效能差異(GPT的應用效能相對較差)。這一發現得到表2和圖3數據的支持,而其他翻譯系統之間無顯著差異。
針對上述發現與統計分析,發現兩個值得深入討論的問題:
(1)文心一言與GPT作為大語言模型支持的人工智能助手,為何表現出顯著的應用效能差異?
(2)翻譯系統在E2C方向的應用效能普遍優于C2E方向,可能原因是什么?
對于第一個問題,盡管二者均由大語言模型支持,但在設計理念、訓練數據、優化目標以及實現技術等方面存在顯著差異。這些差異可能導致二者在特定任務,如機器翻譯上的表現有所不同,以下是可能的原因:首先,專業化知識整合程度不同。文心一言強調通過整合領域知識來增強其語言模型的能力,尤其通過ERNIE模型融合知識圖譜信息,優化模型對專業術語和領域背景知識的理解能力。相比之下,GPT雖然接受了大量的數據訓練,但它可能沒有像文心一言那樣針對特定專業領域進行優化。其次,文心一言可能接入了更廣泛的專業數據集,尤其是在百度上的海量中英文資源,而GPT基于廣泛的互聯網文本進行訓練,可能在特定領域覆蓋和深度上與專門優化的模型有所差距。其他原因包括任務專注度的優先級、實時更新頻次和學習能力的差異。
對于第二個問題,可能因素包括:首先,在涉海領域,多數行業術語、操作指南、法律法規以英語制定,這意味著在該領域內,英語作為源語言的翻譯任務(即E2C)能夠直接利用已標準化的術語和表達。這種規約性的存在,為機器翻譯模型訓練提供了豐富的英文輸入,助力提升模型對專業術語和固定表達的識別與翻譯能力;其次,英語作為主要的國際交流語言,提供大量的專業文獻和文本資源,這些資源的廣泛可用性不僅加深了模型對特定術語的理解,也增強了模型的語言理解能力和泛化能力。這使得模型即使面對未曾見過的專業術語和表達,也能在其訓練數據和算法的基礎上,嘗試進行識別和翻譯,從而在概率意義上提供較為準確的翻譯選項。不過,這種自動翻譯仍可能需要人工審核或后處理以確保最終翻譯的準確性和適應度。在機器翻譯評估領域,準確使用術語對確保文本語義準確性和整體翻譯質量提升至關重要,尤其在專業化翻譯任務中更是評價質量的關鍵。
(二)定性分析
為深入分析各翻譯系統在涉海領域的應用效能及顯著差異的潛在原因,本研究選取在E2C和C2E方向上,各翻譯系統F1得分排名前三和后三的測試例句。基于這些例句的重復情況,構建可視化網絡圖,如圖4和圖5所示。
在圖4和圖5中,第一行和第三行區分了F1得分排名前三和后三中重復出現的測試例句編號,以突出不同翻譯系統中表現最佳和最差的測試例句。此方法旨在通過聚焦分析與探討具體案例,展現各翻譯系統的優勢和共同挑戰,為提升翻譯系統在涉海領域的應用效能提供洞見。
1.EC2翻譯方向的案例分析
在E2C方向上,通過分析F1得分前三中重復的測試例句,發現翻譯系統在專業術語識別與語義解析方面表現出一定的能力。例如“voyage charters”(航次租船)、“time charters”(定期租船)、“bareboat charters”(光船租船)、“innocent passage”(無害通過)、“Ro-Ro deck”(滾裝甲板)以及“traffic separation schemes”(分道通航制)等,均被準確識別和翻譯。專業術語的精確識別與轉換對保持語義完整性與準確性至關重要,這一點在F1評分結果中同樣得到充分驗證。然而,也發現一些不足之處,特別是GPT將“flag State”(船旗國)(編號30)處理為“旗國”,這可能因為GPT訓練語料中涉及特定領域(特別是涉海領域)專業術語的數據不足或缺乏充分的上下文信息。觀察到該句話的F1得分(0.897)相對于其他翻譯系統較低,這一結果可能與專業術語翻譯不準確有關聯。此觀察提示了翻譯過程中專業術語準確性對于整體翻譯質量可能持有關鍵性影響。
案例分析還顯示,即使是表現較好的翻譯系統,處理涉海法律英語中復雜句式時仍顯不足。例如,在案例(1)(編號35)中,“to the extent appropriate”這一修飾語的插入,導致多個翻譯系統錯誤地將“The master, officers and, to the extent appropriate, the crew are fully conversant with and”處理為“船長、高級船員和船員(在適當情況下)完全熟悉并……”,從而影響了句子原意圖的完整傳達。這一錯誤翻譯產生了兩種潛在的解讀:一種是對所有提及群體做出普遍性限定,另一種是專門針對船員的限定。這導致法律條文的傳達產生了歧義,可能會引起不同的解釋和實施問題,而原文的意圖是將這一限定條件特定地應用于“船員”這一群體,表達出不同群體可能根據情況存在不同程度的遵守規定的要求。
涉海法律因涉及國際性(跨國界)和多轄區復雜性,要求專業術語和條款翻譯不僅語義準確,還必須遵循涉海法律的專業表述,確保不同國家和地區對涉海法律體系有統一的理解和應用,達到法律功能對等。這種準確性和一致性是促進國際海事合作、確保航海安全及在全球范圍內有效管理海洋資源的基石。此外,海上活動的安全和責任進一步強調了術語精確性和法律條款明確界定與傳達的重要性,確保所有參與方清楚自身權利和責任,減少因誤解引發的風險。因此,開發涉海領域的術語自動抽取模型尤為關鍵,此舉旨在確保涉海法律文檔、操作規范以及安全指導原則等涉海關鍵信息的準確傳遞,減少因專業術語和法律條款翻譯不當而導致的誤解與潛在風險,保障國際海事和海洋活動的安全、效率及法律法規遵守。
案例(1)
原文:The master, officers and, to the extent appropriate, the crew are fully conversant with and required to observe the applicable international regulations concerning the safety of life at sea, the prevention of collisions, the prevention, reduction and control of marine pollution, and the maintenance of communications by radio. (來源:《聯合國海洋公約》)
參考譯文:船長、高級船員和在適當范圍內的船員,充分熟悉并須遵守關于海上生命安全,防止碰撞,防止、減少和控制海洋污染和維持無線電通信所適用的國際規章。
分析F1得分后三名中的重復句子發現,這些例句多涉及涉海法律法規,其特點在于密集的專業術語、深入的領域知識和復雜的法律構造,對翻譯系統的能力提出了較高要求,特別是在理解和表述相關法律專業術語及其所涵蓋的領域知識方面。例如,在案例(2)(編號45)中,翻譯系統對于“able seafarer deck”和“certification of ratings”等專業術語及其領域知識的處理,展示了其在術語識別與準確轉換方面的不足,影響整個句子的意圖傳達。例如,GPT將其翻譯為“能夠勝任甲板船員工作的最低要求”,而其他系統的翻譯為“合格海員甲板認證的強制性最低要求”,均未能準確捕捉原文意義。
依據《1987年海員培訓、發證和值班標準國際公約》,“ratings as able seafarer deck”指滿足特定資格、技能和經驗要求,能在甲板部門擔任高級角色(如高級值班水手)的船員,顯示了從普通船員到高級值班水手的資質等級差異。“certification”指正式認證過程,確保船員資格和能力達到國際認可標準。在參考譯文中,這些原文中的隱含背景信息都得到了明晰化處理,而現有翻譯系統在精確處理這些術語和領域知識細節上還存在挑戰。
案例(2)
原文:Mandatory minimum requirements for certification of ratings as able seafarer deck. (來源:《1987年海員培訓、發證和值班標準國際公約》)
參考譯文:對作為高級值班水手的普通船員發證的強制性最低要求。
2.C2E翻譯方向的案例分析
在C2E方向上,F1得分前三名中的重復句子主要涉及海事仲裁和海洋環境保護等話題,翻譯系統在處理這些涉海場景中的專業術語和法律程序時展現出較強的能力。例如,“船舶實時定位分析”(analysis of real-time positioning of ships)、“海上船舶碰撞動態模擬分析”(dynamic simulation analysis of ship collisions at sea)、“船舶碰撞損害責任糾紛”(cases of disputes over liability for damage caused by vessel collision)、“海上貨運代理合同糾紛”(disputes over contracts for sea freight forwarding)等術語,都被大部分系統準確地識別和翻譯。這類測試例句的高F1得分與E2C方向中得分高的句子分析結果一致,凸顯了正確表達專業術語在提高翻譯質量上的重要性。
F1得分后三名中的重復句集中在航運發展、海洋石油勘探和海商法等專業領域,文本充斥著如“冷藏艙”(refrigerating chamber)、“冷氣艙”(cool chamber)、“航道整治”(fairway/waterway regulation)、“江海直達船型”(ship types for sea-river direct shipping)、“數字航道”(digital fairways/waterways)、“冷藏集裝箱船”(reefer container ships)、“虧艙費”(dead freight)等一系列的專業術語。在處理這些專業術語時,多數系統未能充分體現術語的精確含義,導致文本語義傳達出現嚴重偏差。例如,“虧艙費”這一專業術語被不同系統翻譯為“shortage freight”(Google)、“loss of space”(DeepL)、“demurrage”(百度翻譯、有道翻譯),表述各異。在專業且嚴謹的涉海領域,這種術語的不精確使用顯著阻礙了行業內的交流與溝通,增加了誤解和潛在風險。
此外,這些句子還涉及復雜的海商法條款。案例(3)(編號19)討論海商法中關于航海操作過程中責任和準備工作的規定,從句式結構上也展現了涉海法律文本在邏輯、專業術語方面的特點。分析發現,大多數翻譯系統傾向于簡化內容,犧牲了涉海法律文本的嚴謹性和正式性。例如,“適拖”(tow-worthy)和“被拖物適合拖航的證書”(certificate of tow-worthiness)被通俗化為“ensure the towed object is in a condition/state suitable for towing/towage”“relevant certificates and documents issued by relevant inspection agencies indicating that the towed object is suitable for towing/towage.”,影響法律效力。對于涉海法律文件的翻譯,需要字字斟酌,以求譯文措辭準確,力求具有與原文相差無幾的法律效應。[14]相對而言,在追求法律文本的正式性與精確性方面,文心一言的處理顯得過于刻板,尤其是在其對“被拖物”一詞的處理上。通過四次冗余地使用“the object to be towed”進行表述,違背了涉海法律翻譯應遵循的精確性和經濟性原則。
案例(3)
原文:被拖方在起拖前和起拖當時,應當做好被拖物的拖航準備,謹慎處理,使被拖物處于適拖狀態,并向承拖方如實說明被拖物的情況,提供有關檢驗機構簽發的被拖物適合拖航的證書和有關文件。(來源:《中華人民共和國海商法》)
參考譯文:The tow party shall, before and at the beginning of the towage, make all necessary preparations therefor and shall exercise due diligence to make the object to be towed tow-worthy and shall give a true account of the object to be towed and provide the certificate of tow-worthiness and other documents issued by the relevant survey and inspection organizations.
E2C和C2E方向的案例分析表明,如TranSmart和文心一言等現代翻譯系統在涉海文本處理上已取得顯著進步,在識別和精確翻譯通用術語及解析語境方面,體現了對專業知識的深刻洞察。然而,分析也指出這些翻譯系統在處理特定法律文本時遇到的挑戰,特別是在精確識別和翻譯涉海專業術語方面存在的困難,直接影響了語義的準確傳遞,成為制約機器翻譯在涉海法律領域中有效應用的主要障礙。開發涉海領域的術語自動抽取模型,可以顯著解決這一問題,整體提升翻譯質量,增強機器翻譯在該領域的應用效能。
四、結語
在涉海專業領域,高質量的機器翻譯服務至關重要,它不僅可以為專業人士提供便捷,還能夠促進全球海事、海洋科學以及相關領域的知識共享和國際合作。本研究通過應用BLEU、chrF++以及BERTScore 3種評估指標,對國內外多個主流機器翻譯系統及人工智能助手(翻譯功能)在涉海文本中的應用效能進行綜合評估。結果表明:(1)在識別和翻譯通用術語以及解析語境、語義方面,各翻譯系統均表現出較好的性能,譯文準確性和流暢性達到了可接受水平,能夠在一定程度上提升涉海文本翻譯的效率,例如與航運發展、海洋文化、海洋歷史、海洋環境相關的文本;(2)在翻譯方向方面,各系統在E2C方向上的應用效能優于C2E方向,這一現象可能源于英語作為涉海領域的通用語言,在專業領域內擁有較為統一和廣泛認可的術語和表達體系,當從英語翻譯到中文時,系統能夠直接借鑒這些標準化的專業用語和表述,較為準確地進行術語和固定句式表達的識別、匹配和轉換;(3)在翻譯質量方面,各系統之間存在顯著差異,文心一言和TranSmart在E2C和C2E兩個翻譯方向的多項評估指標上表現較為優異,其輸出的譯文僅需輕度的譯后編輯即可達到使用標準,而GPT在兩個翻譯方向的三項指標上均是表現最差的,與其他系統相比,應用效能差距顯著。(4)在處理專業領域知識密集型、術語精確度要求高及邏輯結構嚴密的文本方面,特別是涉及海事法律法規的文本,即使是性能最優的翻譯系統也遭遇嚴峻挑戰,這一情況在EC2和C2E兩個翻譯方向上均顯著。
本研究針對機器翻譯技術在涉海領域的未來發展與應用提出兩個建議。首先,翻譯系統開發者應深度剖析在多系統評估中普遍表現不佳的測試案例,這有助于改善翻譯模型在處理與解析專業術語和領域知識時的局限;其次,術語具有認知、語言、傳播三個維度,分別指向的是概念知識體系、術語話語體系和受眾傳播體系,[15]學界和業界應重視涉海垂直領域語料庫的構建,[16]融合大語言模型與高質量領域標注數據集,開發涉海領域的術語自動抽取模型,以顯著提升術語識別、翻譯和傳播的精確度,這對于提高翻譯系統在涉海領域的應用效能,增強涉海領域中的跨語言交流和話語體系建構極為關鍵。未來的研究將包括擴展測試集的規模與多樣性,開發更全面、精確的評估指標,專注于構建涉海領域的術語自動抽取模型,進一步促進機器翻譯在涉海領域的集成與應用。
參考文獻:
[1] Papineni K, Roukos S, Ward T, & Zhu W J. BLEU: a method for automatic evaluation of machine translation[A]. In Isabelle, P. et al. (eds.). Proceedings of the 40th Annual Meeting on Association for Computational Linguistics[C]. Philadelphia, USA: Association for Computational Linguistics, 2002: 311-318.
[2] Banerjee S, Lavie A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments[A]. In Goldstein, J. et al. (eds.). Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization[C]. Michigan, USA: Association for Computational Linguistics, 2005: 65-72.
[3] Popovic′ M. chrF: character n-gram F-score for automatic MT evaluation[A]. In Bojar, O. et al. (eds.). Proceedings of the tenth Workshop on Statistical Machine Translation[C]. Lisbon, Portugal: Association for Computational Linguistics, 2015: 392-395.
[4] Popovic′ M. chrF++: words helping character n-grams[A]. In Bojar, O. et al. (eds.). Proceedings of the Second Conference on Machine Translation[C]. Copenhagen, Denmark: Association for Computational Linguistics, 2017: 612-618.
[5] Zhang T, Kishore V, Wu F, Weinberger K Q, & Artzi Y. BERTScore: evaluating text generation with BERT[A]. Proceedings of the eighth International Conference on Learning Representations[C]. Online: Association for the Advancement of Artificial Intelligence (AAAI), 2020: 1-43.
[6] Rei R, Stewart C, Farinha A C, & Lavie A. COMET: a neural framework for MT evaluation[A]. In Webber, B. et al. (eds.). Proceedings of the 2020 conference on Empirical Methods in Natural Language Processing (EMNLP)[C]. Online: Association for Computational Linguistics, 2020: 2685-2702.
[7] Sellam T, Das D, & Parikh A. BLEURT: learning robust metrics for text generation[A]. In Jurafsky, D. (eds.). Proceedings of the 58th annual meeting of the Association for Computational Linguistics[C]. Online: Association for Computational Linguistics, 2020: 7881-7892.
[8] Callison-Burch C, Osborne M, & Koehn P. Re-evaluating the role of BLEU in machine translation research[A]. In McCarthy, D., & Wintner, S. (eds.). Proceedings of the 11th conference of the European Chapter of the Association for Computational Linguistics[C]. Trento, Italy: Association for Computational Linguistics, 2006: 249-256.
[9] Perreault W D. Controlling order-effect bias[J]. The Public Opinion Quarterly, 1975, 39(4): 544-551.
[10] Shapiro S S, Wilk M B. An analysis of variance test for normality (complete samples) [J]. Biometrika, 1965, 52(3/4): 591-611.
[11] Kruskal W, Wallis W A. Use of ranks in one-criterion variance analysis[J]. Journal of the American Statistical Association, 1952, 47: 583-621.
[12] Dinno A. Nonparametric pairwise multiple comparisons in independent groups using Dunn's test[J]. The Stata Journal, 2015, 15(1): 292-300.
[13] Dunn O J. Multiple comparisons among means[J]. Journal of the American Statistical Association, 1961, 56(293): 52-64.
[14] 任東升, 白佳玉. 涉海法律英語翻譯[M]. 青島: 中國海洋大學出版社, 2015.
[15] 高玉霞, 任東升. 中國海洋政治話語翻譯語料庫的建構與研發[J]. 中國海洋大學學報 (社會科學版), 2020(6): 107-116.
[16] Zhang Y, Liu S. The maritime domain-specific corpus: compilation and application[J]. Pedagogika-Pedagogy, 2023, 95(5s): 139-156.
Evaluating the Application Efficacy of Machine Translation in Maritime Contexts: A Rigorous Evaluation via BLEU, chrF++, and BERTScore Metrics
Liu Shijie
(College of Foreign Languages, Shanghai Maritime University, Shanghai 201306, China)
Abstract: The advent of deep learning technologies and generative artificial intelligence has catalyzed a qualitative shift in the machine translation landscape, forging novel avenues for advancement in this arena. This investigation endeavors to conduct a comprehensive evaluation of the application efficacy of machine translation within the maritime sector, set against a backdrop of diverse technological and algorithmic frameworks. To this end, a curated test dataset comprising 100 emblematic bilingual (Chinese-English) sentences pertinent to maritime contexts was developed. Leveraging the unique linguistic structural nuances of maritime texts, three automatic evaluation metrics-BLEU, chrF++, and BERTScore-were employed to facilitate both quantitative and qualitative analyses of translations rendered by AI assistants ChatGPT (4.0) and ERNIE Bot (4.0), alongside six leading translation engines: Google Translate, Microsoft Translator, DeepL Translate, Tencent TranSmart, Baidu Translate, and Youdao Translate. The findings of this study not only furnish empirical evidence underpinning the application efficacy of machine translation systems within the maritime domain but also elucidate considerations for algorithmic refinement and translation precision enhancement for machine translation technology developers. Moreover, this research proffers a pragmatic blueprint for maritime professionals in the selection of apt translation systems.
Key words: maritime translation; application efficacy of machine translation; BERTScore; BLEU; chrF++
責任編輯:王 曉
收稿日期:2024-02-23
基金項目:國家社會科學基金項目“海洋強國視域下海事語言標準化及國際海事話語研究”(21BYY017);2023年教育部產學合作協同育人項目“基于海事語言數據的人才培養實踐條件與實踐基地建設研究”(230801549211644);上海海事大學2022年研究生拔尖創新人才培養項目“基于深度學習的海事領域術語自動抽取及分析研究”(2022YBR020)
作者簡介:劉世界(1994- ),男,河南永城人,上海海事大學外國語學院博士研究生,專業方向為海事術語自動抽取與文本挖掘、計量語料庫語言學(QCL)、翻譯技術。
