聚焦可解釋性:知識追蹤模型綜述與展望
2024-06-03 18:29:39楊文陽楊益慧
現代教育技術 2024年5期
關鍵詞:智慧教育
楊文陽 楊益慧
摘要:模型的可解釋性是評估其實用性和實際應用價值的重要指標,但目前基于深度學習的知識追蹤模型普遍存在可解釋性差的問題,導致教學決策過程不透明。對此,文章首先介紹了知識追蹤的流程,分析了知識追蹤模型的可解釋性,并根據可解釋性方法在模型訓練過程中作用的時間,將可解釋知識追蹤模型分為事前可解釋的知識追蹤模型和事后可解釋的知識追蹤模型。隨后,文章分別對這兩種模型進行再分類,并從優點、缺點兩個維度,對不同類型的事前、事后可解釋知識追蹤模型進行了對比。最后,文章從模型可視化、融入教育規律、多模態數據融合、解釋方法探索、可解釋性評估等方面,對未來可解釋知識追蹤模型的教學應用進行了展望。文章的研究有助于提升知識追蹤模型在教學中的實用性,推動教育數字化的進程。
關鍵詞:知識追蹤;可解釋性;全局可解釋性;局部可解釋性;智慧教育
【中圖分類號】G40-057 【文獻標識碼】A 【論文編號】1009—8097(2024)05—0053—11 【DOI】10.3969/j.issn.1009-8097.2024.05.006
引言
隨著人工智能、云計算、大數據等新一代信息技術的快速發展,智慧教育進入了新的發展階段。黨的二十大報告明確提出“推進教育數字化,建設全民終身學習型社會、學習型大國”[1],這就需要構建智慧教育發展新生態,以數據為驅動,促進人工智能技術在教育教學中的應用。基于此,有必要發展數字化教育服務,利用數字技術提供個性化、定制化的教育服務,包括在線學習、網絡輔導、遠程教育等,來支撐智慧教育的實現。知識追蹤(Knowledge Tracing,KT)由美國卡內基梅隆大學人機交互研究所專家Corbett等[2]于1995年引入智能教育領域,后成為個性化學習系統中學習者知識狀態建模的主流方法[3]。深度學習因其能夠處理大規模數據、自動化地進行特征提取和數據分析等優點,使知識追蹤模型的性能得到了顯著提升。然而,作為人工智能領域的關鍵技術,深度學習也因其“端到端”和高度的非線性操作特點,導致其模型可解釋性不足。在模型研究中,可解釋性是模型優化的有效途徑;而在實際應用中,可解釋性是模型應用推廣的助力器[4]。在知識追蹤領域,模型的可解釋性也是衡量模型的一項重要指標。
基于上述分析,本研究嘗試從可解釋性知識追蹤的基本概念切入,深入剖析可解釋性在知識追蹤領域的作用;同時,通過對當前領域研究成果的梳理與分析,根據解釋時間和范圍的不同,對可解釋知識追蹤模型進行分類探討;最后,探討可解釋知識追蹤模型在教學中的應用并提出相關建議,以期為教育教學工作的開展提供有力支持。
一 知識追蹤模型的相關問題
在知識追蹤領域,模型的可解釋性有助于解釋模型的決策基礎和推理過程。而對可解釋知識追蹤模型的研究,涉及智慧教育、認知科學、計算機科學等多個領域。本研究首先對知識追蹤的流程、可解釋性的概念及其在知識追蹤模型中的必要性進行介紹。
1 知識追蹤的流程
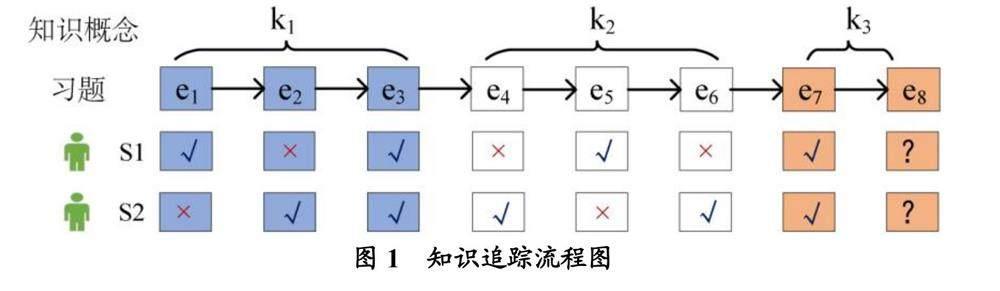
知識追蹤是一項針對時間序列的學習任務,其基于用戶的歷史答題數據進行建模,從而獲得學習者對知識的掌握情況,并預測學習者在下一次練習中答對題目的概率。知識追蹤流程如圖1所示,其中k1、k2、k3分別表示三個不同的知識概念,k1、k2各包含3道習題,k3包含2道習題;S1、S2分別表示學習者1、學習者2的答題表現;“√”表示學習者答對習題,“×”表示學習者答錯習題,“?”表示學習者還未作答。知識追蹤通過學習S1、S2兩位學習者對習題e1~e7的作答表現,預測未來某個時刻學習者對習題e8的作答表現。
2 知識追蹤模型的可解釋性
目前,學術界對“可解釋性”的定義尚未達成一致,不同研究者從不同角度對“可解釋性”賦予了不同的內涵。可解釋性具有相對主觀性,難以通過具體的數學公式來定義。Miller[5]表示,可解釋性是人類為了能夠理解決策原因或能夠準確重現模型付出努力的程度。在人工智能領域,可解釋性是指以一種可理解的方式解釋模型或算法的決策過程、預測結果或學習到的知識,涉及將復雜的模型、特征、數據轉化為人類可理解和可解釋的形式,使人們能夠理解模型的工作原理、依據和推理過程。
從算法的角度來看,在知識追蹤任務中傳統的機器學習方法結構簡單,具有良好的可解釋性。隨著人工智能技術的迅速發展,深度學習已成為當前主流的方法之一。相較于傳統方法,深度學習顯著提升了知識追蹤模型的性能。深度學習的過程需要經過多層非線性變換,即每一層神經元對輸入進行非線性變換并傳遞給下一層,這使模型學習到的特征較為抽象、難以直觀理解。從教育的角度來看,可解釋性是模型應用的必要條件,既是學習者與模型建立信任的關鍵方式,也是研究人員優化模型的重要依據。然而,知識追蹤領域對模型的研究更多地關注其準確率,而忽視了可解釋性的重要性。在實際的教學應用中,知識追蹤模型的可解釋性是建立學習者與教師之間信任關系以及模型長期使用和推廣的重要條件。在教學中,教師不僅需要了解學習者的學習效果,還需要了解其學習過程,以幫助他們做出更好的學習決策;同時,研究者也需要及時獲取知識追蹤模型的變化狀態,以在后續的研究和模型訓練中進行改進,從而在不斷變化的學習環境中更準確地評估學習者的知識掌握情況。
綜上可知,知識追蹤模型的可解釋性對于教育教學至關重要。深度學習雖然提升了知識追蹤模型預測的精度,但其抽象性使模型的解釋變得更加困難。因此,知識追蹤研究除了要關注模型的精度,也要重視模型的可解釋性,以提高模型的實用性和推廣性。近年來,研究者提出了不同的可解釋性方法,如分層關聯傳播[6]、因果解釋法[7]等。本研究根據可解釋性方法在模型訓練過程中作用的時間,將可解釋知識追蹤模型分為兩類:事前(Ante-hoc)可解釋的知識追蹤模型和事后(Post-hoc)可解釋的知識追蹤模型。
二 事前可解釋的知識追蹤模型
事前可解釋性是指模型的可解釋性行為發生在模型訓練之前,而對于一個已訓練好的學習模型來說,無須添加額外的信息就可以解釋模型的決策過程或預測結果,因此這種解釋方式也被稱為內置可解釋性。事前可解釋性可用于模型的設計和構建,使其內部工作機制相對直觀和易于理解,有助于研究者或學習者直接觀察模型組件,理解其如何根據輸入數據產生輸出。
1 模型分類
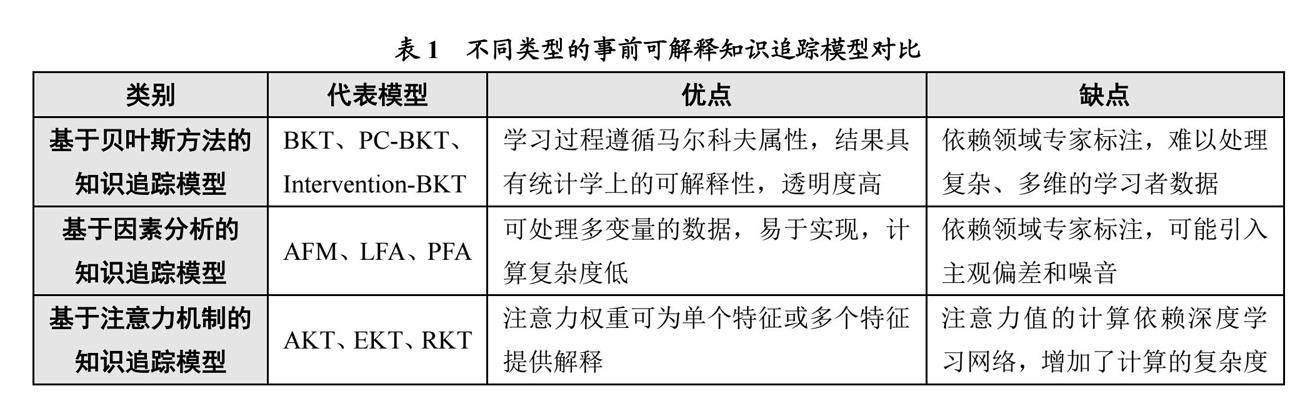
通過對當前知識追蹤領域相關研究成果的分析,參考可解釋人工智能領域模型的分類[8],可以得出以下三類模型屬于事前可解釋知識追蹤模型的范疇:①基于貝葉斯方法的知識追蹤模型,其在進行預測前能夠提供先驗概率信息;②基于因素分析的知識追蹤模型,其能夠考慮潛在因素結構;③基于注意力機制的知識追蹤模型,其在預測前就確定了模型關注的重要信息。
(1)基于貝葉斯方法的知識追蹤模型
貝葉斯方法是一種利用先驗知識和觀測數據來更新后驗概率的方法。貝葉斯知識追蹤(Bayesian Knowledge Tracing,BKT)利用貝葉斯方法的原理解決知識追蹤問題,其通過定義學習者知識狀態與答題表現之間的概率關系、答題數據的變化情況來更新知識狀態,達到知識追蹤的目的。貝葉斯知識追蹤可以提供每個知識點的掌握概率和每個答題結果的后驗概率,從而直觀地反映學習者的知識水平和答題表現。
研究者將先驗知識、教學干預措施等引入BKT模型,使模型在可解釋性方面具有更高的可信度。例如,Pardos等[9]通過引入特殊的先驗知識模塊,為學習者賦予不同的先驗概率參數,實現了對學習者先驗知識狀態的個性化建模;Lin等[10]假設不同類型的教學干預會對學習者的潛在狀態產生不同的影響,在此基礎上提出了基于干預的BKT模型(Intervention-BKT),并通過將教學干預措施引入BKT模型,對學習者的知識掌握狀態進行了預測;Nedungadi等[11]提出了基于個性化聚類的知識追蹤模型(Personalized Clustered BKT,PC-BKT),其可以通過對知識點賦予單獨的先驗概率,動態聚類學習者的行為模式和能力水平,從而為學習者提供更合適的知識內容與學習路徑。
整體而言,基于貝葉斯方法的知識追蹤模型具有強大的可解釋性且構造相對簡單,已被廣泛應用于學習者知識狀態的診斷、教育決策的制定、個性化學習路徑的推薦等方面[12],是教育領域中一種有價值的工具,可為教育決策提供重要的支持和指導。
(2)基于因素分析的知識追蹤模型
因素分析(Factories Analysis,FA)是一種統計方法,可以用來分析多個變量之間的相關性,從而提取出一些潛在的因素,來解釋變量之間的共同變異。基于因素分析的知識追蹤模型的理論基礎是項目反應理論,此理論在教育評估和測量方面發揮了重要作用。項目反應理論的核心思想是根據學習者在解決問題過程中的影響因素,通過學習邏輯函數來評估學習者的表現。
研究者將做題時間、遺忘概率等參數納入因素分析模型中,實現了從單參數邏輯回歸模型到多參數邏輯回歸模型的升級。例如,Cen等[13]提出了加性因子模型(Additive Factor Model,AFM),即假設各因子對響應變量的貢獻是相互獨立且可累加的,通過對每個因子進行參數估計,可以對模型進行解釋;Cen[14]提出了學習因子分析(Learning Factors Analysis,LFA)模型,此模型引入了心理測量學中的Q矩陣概念,通過先驗知識、任務難度、任務學習率來預測學習者的表現;Pavlik等[15]認為LFA模型動態區分特定學習者各個知識點的能力非常有限,因而提出了表現因子分析(Performance Factors Analysis,PFA)模型,此模型具有靈活的自適應性,能以補充的方式用于多個知識點的觀測。整體而言,基于因素分析的知識追蹤模型通過學習數據中的潛在因子并將這些因子與預測變量進行加權組合來建模,也可以對數據中的復雜關系建模。基于因素分析的知識追蹤模型還可以為模型參數和因子權重的設計提供解釋,其解釋性依賴于數據和模型的正確假設,并且解釋結果可能因數據選擇、因子提取和模型擬合等因素而有所不同。因此,因素分析模型主要適用于大規模線上學習和小規模課程教學[16]。
(3)基于注意力機制的知識追蹤模型
注意力機制可以通過為不同的輸入特征分配權重,來指導知識追蹤模型的決策過程。在基于注意力機制的知識追蹤模型中,這些權重可用于表示模型在處理輸入時的關注程度。通過觀察注意力權重,可以理解模型對不同特征的關注程度,從而解釋模型在做出預測時的決策過程。
研究者將注意力機制引入知識追蹤模型中,在提升預測準確性的同時也增強了可解釋性。例如,Ghosh等[17]提出注意力知識追蹤(Attentive Knowledge Tracing,AKT)模型,將學習者未來對問題的回答與其過去的回答相聯系,計算注意力的權重,并將基于注意力的神經網絡模型與可解釋的模型組件相結合,對多個案例進行研究,結果表明AKT具有可解釋性。Liu等[18]使用具有馬爾科夫屬性且具有注意力機制的練習增強循環神經網絡框架,將學習者的多知識點狀態向量擴展到知識狀態矩陣,從而實現了具有可解釋的練習增強的知識追蹤(Exercise-aware Knowledge Tracing,EKT)。Pandey等[19]提出了關系感知自注意力知識追蹤(Relationship-aware Self-attention for Knowledge Tracing,RKT)模型,引入具有上下文信息的關系感知自注意力層,將注意力權重與感知關系系數相結合,可視化知識點之間的相似度和關聯性,提升了學習者對預測結果的信任度。
整體而言,從注意力機制能否反映輸入和輸出之間的關系角度來講,注意力機制具有可解釋性,可以幫助學習者理解模型;但從模型的透明度來講,注意力機制并不具有可以反映模型內部機理的能力。考慮到不同的預期用戶和不同的解釋目標,可以在知識追蹤模型中引入注意力機制,通過分析注意力權重的時序變化,來理解學習者的答題策略和知識結構,有助于增強學習者對模型的信任感。因此,基于注意力機制的知識追蹤模型主要適用于個性化學習規劃與習題推薦。
2 模型對比
在上述事前可解釋性的知識追蹤模型中,基于貝葉斯方法的知識追蹤模型利用概率模型和貝葉斯推理計算后驗概率分布,提供直觀、可解釋的模型輸出和置信度估計;基于因素分析的知識追蹤模型依托項目反應理論評估學習者的表現,解釋模型參數和因子權重;而在基于注意力機制的知識追蹤模型中,注意力機制作為知識追蹤模型構建過程中的引入模塊,可以通過分析注意力權重的分布,在一定程度上解釋模型的關注點和決策依據。這些模型通過提供可解釋的輸出結果,幫助教育決策者理解模型的決策過程,并進行個性化的學習評估和反饋,故在教育決策過程中發揮了重要作用。結合上述分析,本研究從優點、缺點兩個維度對不同類型的事前可解釋知識追蹤模型進行了對比,具體如表1所示。
三 事后可解釋的知識追蹤模型
事后可解釋性是指在模型訓練完成后,通過對已獲得的結果進行分析和解釋,揭示模型的決策依據和推理過程。與事前可解釋性不同的是,事后可解釋性關注對模型已經生成的輸出進行解釋,而不是在模型訓練過程中提供解釋或指導。事后可解釋性不僅可以幫助人們理解模型得出某個預測或決策結果的過程,還可以提供對模型內部狀態、權重和特征的解釋,以及模型對輸入的響應和預測結果的解釋。
1 模型分類
根據可解釋范圍的大小,即是否解釋單個實例或預測整個模型行為,本研究將事后可解釋分為全局可解釋和局部可解釋兩類。
(1)全局可解釋
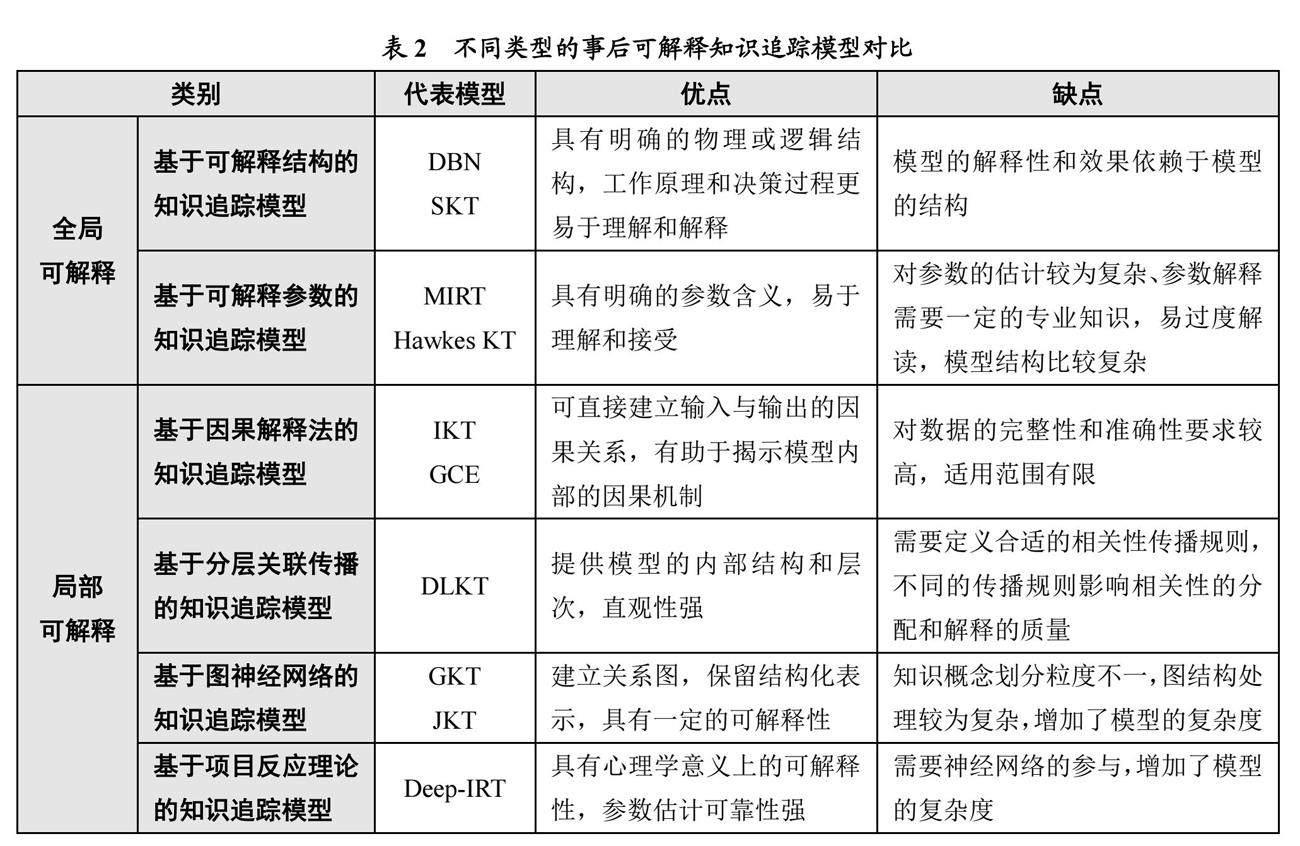
全局可解釋是指對整個機器學習或深度學習模型在整個數據集上的預測結果進行解釋和理解的能力,關注揭示模型整體行為、內部結構和決策過程的解釋,并提供對模型整體性能和特征重要性的理解。全局可解釋性重在回答以下問題:整個模型如何學習、表示數據的特征和模式?模型的預測結果受哪些特征或因素的影響最大?通過全局解釋,可以獲得對模型整體性能的洞察,理解模型如何進行決策,并發現模型的整體行為模式。通過對當前知識追蹤領域相關研究成果的分析,參考人工智能領域可解釋模型的分類,得出以下兩類模型屬于全局可解釋知識追蹤模型的范疇:
①基于可解釋結構的知識追蹤模型。在知識追蹤任務中,多知識點之間往往存在各種依賴關系。構建模型時考慮不同知識點之間的結構關系,可以提升模型的有效性。例如,K?ser等[20]提出了一種能夠聯合表示多種技能的動態貝葉斯網絡(Dynamic Bayesian Network,DBN),來解決BKT模型無法表示學習領域不同技能之間層次結構關系的問題。另外,通過建立知識點的拓撲結構,可以增強知識追蹤模型的表征能力,從而更好地理解學習者的學習過程。例如,Tong等[21]提出了一種基于結構的知識追蹤(Structure-based Knowledge Tracing,SKT)框架,可以利用知識結構之間的關聯性模擬概念之間的傳播影響。基于可解釋結構的知識追蹤模型結構清晰,考慮知識點之間的結構關系,可以有效評估學習者對知識點的掌握程度,在教育教學中主要用于個性化學習路徑推薦[22]。
②基于可解釋參數的知識追蹤模型。基于可解釋參數的知識追蹤模型的應用,旨在通過使用具有明確含義和解釋性的參數,捕獲數據中的模式和關聯,以增強模型的可解釋性和理解性。例如,Su等[23]提出了時間和概念增強多維項目響應理論模型,可以將多維項目響應理論(Multidimensional Item Response Theory,MIRT)參數集成到遞歸網絡,使模型能在每個特定知識領域生成可解釋的參數。具體來講,MIRT考慮每個題目和每個學習者在多個知識領域的能力與難度,循環神經網絡捕捉隨時間變化的學習者知識狀態,使用EM算法、梯度下降法等優化方法估計題目區分度、題目難度、學習者能力和作答時間等參數并將這些參數分解為不同知識領域的權重,以幫助師生了解每個知識領域對題目的貢獻。Wang等[24]提出了霍克斯知識追蹤(Hawkes Knowledge Tracing,Hawkes KT)模型,可以對不同知識點之間的時間交叉效應進行顯式建模,通過對參數假設的可視化分析,驗證了模型中的參數具有高度可解釋性。可解釋參數使模型的決策過程更加透明和可解釋,并使用戶能夠理解模型對學習者狀態和學習過程的推斷。通過分析模型參數,了解不同學習因素的影響程度,可以幫助學習者準確定位學習過程中的影響因素,故基于可解釋參數的知識追蹤模型在教育教學中適用于學情分析與干預。
(2)局部可解釋
局部可解釋性是指在機器學習和深度學習模型中,對于給定的單個樣本或輸入,解釋模型對其決策或輸出的依據。局部可解釋性聚焦模型在個別樣本上的預測過程,并提供對該樣本決策依據和關鍵特征的解釋,從而幫助人們理解學習模型的決策過程和決策依據。局部可解釋性重在回答以下問題:對于某個特定的輸入樣本,模型是如何做出決策的?模型對于該樣本的預測結果受哪些特征的影響最大?通過對當前知識追蹤領域相關研究成果的分析,參考人工智能領域可解釋模型的分類,得出以下四類模型屬于局部可解釋知識追蹤模型的范疇:
①基于因果解釋法的知識追蹤模型。因果解釋法通過對知識追蹤模型的因果推斷,分析不同行為特征對學習效果的影響,探究輸入與輸出之間的因果關系。例如,Minn等[25]提出了具有因果關系的可解釋知識追蹤(Interpretable Knowledge Tracing,IKT)模型,其使用傳統的機器學習技術來提取有意義的特征,之后使用樹增強樸素貝葉斯分類器對學習者的未來表現進行預測,結果顯示此模型具有較高的預測性能和推理解釋性。Li等[26]提出了基于遺傳算法的因果解釋方法,稱為遺傳因果解釋器(Genetic Causal Explainer,GCE),并構建了一個因果框架來指導模型預測的子序列歸因,可在不影響模型訓練的情況下生成解釋結果。因果解釋法提供對模型因果關系的解釋,有助于人們理解模型如何根據輸入產生輸出,以及不同輸入對輸出的影響程度,這使模型的輸出更具可解釋性和可信度,有助于學習者更好地理解模型的內部機制并預測結果的產生過程。在教育教學中,基于因果解釋法的知識追蹤模型適用于教學方法的選擇與優化、學情的診斷等。
②基于分層關聯傳播的知識追蹤模型。基于反向傳播的分層關聯傳播(Layer-wise Relevance Propagation,LRP)方法的主要思想是利用深度神經網絡的反向傳播機制,將模型中影響決策的重要信息從模型的輸出層傳播到輸入層。具體來講,根據各層不同的傳播規則,將傳入的相關性重新分配到下一層,直至到達輸入層——在輸入層,可以計算出神經網絡中每個神經元對輸出的影響程度,并生成對應的熱力圖,可視化輸入特征對輸出結果的貢獻度,從而實現對模型的解釋。例如,Lu等[27]提出可采用事后解釋方法研究深度學習知識追蹤(Deep Learning for Knowledge Tracing,DLKT)模型的可解釋性,通過應用分層關聯傳播方法將相關性從模型的輸出層反向傳播到輸入層,從而解釋各輸入特征的重要性。后來,Lu等[28]又利用LRP技術從知識追蹤模型輸入中捕捉到技能級別的語義信息(包括技能相關的差異、距離、內在關系等),并通過對模型進行綜合實驗評估,驗證了所提出的解釋方法在“技能-答案”層面的可行性和有效性。分層關聯傳播方法的可解釋性表現為其能夠提供深度學習模型內部的層級關系和重要特征,此方法能更好地理解模型的決策過程、特征作用和相互關系,從而增加模型的可解釋性和可信度。但LRP的實現需要根據不同的網絡結構和激活函數選擇合適的傳播規則,而規則的選擇可能會影響相關性的分配和解釋的質量。在教育教學中,基于分層關聯傳播的知識追蹤模型可以直觀地了解學習者知識掌握情況的動態變化,適用于學習路徑推薦、薄弱知識點診斷等。
③基于圖神經網絡的知識追蹤模型。圖神經網絡(Graph Neural Network,GNN)的可解釋主要表現在三個方面:一是節點級別的解釋,GNN可以對每個節點進行表示學習,通過觀察節點的表示向量,了解該節點在圖中的特征和重要性;二是圖級別的解釋,GNN可以生成整個圖的表示向量,通過觀察圖的表示向量,來了解整個圖的拓撲結構和全局特征;三是信息傳遞路徑,GNN通過在圖上進行信息傳遞來學習節點表示,解釋GNN的信息傳遞路徑有助于理解模型如何從圖的局部信息逐步推導出全局信息。研究者根據圖數據結構自身的特點,將圖神經網絡引入知識追蹤模型表示知識之間的關聯。例如,Nakagawa等[29]提出基于圖的知識追蹤(Graph based Knowledge Tracing,GKT)模型,可以將知識結構轉換為圖形,從而實現關系歸納偏差,并將知識追蹤任務重新表述為GNN中的時間序列節點級分類問題;Song等[30]提出了一個基于聯合圖卷積網絡的深度知識追蹤(Joint Graph Convolutional Network based Deep Knowledge Tracing,JKT)框架,將多維關系建模為圖,構建交叉概念下練習之間的關系,有助于捕捉高層次的語義信息。在基于圖神經網絡的知識追蹤模型中,圖神經網絡的信息傳遞機制可以有效學習到課程知識的隱式表示,提高了知識概念狀態的可解釋性,有助于學習者呈現任意時刻的知識掌握狀態,故此模型主要適用于生成推理路徑、診斷知識薄弱點和多知識點習題的推薦等。
④基于項目反應理論的知識追蹤模型。項目反應理論(Item Response Theory,IRT)的可解釋性主要體現為其能夠直接刻畫學習者和題目之間的關系,并解釋相關變量如何影響這一關系。Rasch模型[31]通常被認為是最簡單的IRT模型,項目反應函數由單參數邏輯回歸模型定義,被廣泛用于項目反應數據分析。此外,Yeung[32]提出的Deep-IRT模型可以綜合項目反應理論和動態鍵值記憶網絡,將學習結果輸入IRT中進行預測,從心理學角度為學習者提供了解釋。Gan等[33]將動態鍵值記憶網絡與IRT模型相結合,對學習者的知識狀態、習題難度和嵌入三個向量進行變換,并作為IRT的三個輸入參數來預測學習者的答題結果。基于項目反應理論的知識追蹤模型通過將深度學習模型的輸出作為IRT模型的輸入,并利用IRT模型進行預測,可以實現深度模型的輸出與IRT模型中的可解釋參數相對應。這種結合使該模型可以通過IRT模型的參數解釋來理解模型的決策依據和推斷過程,適用于小測試與習題練習、教育評估和測量等。
2 模型對比
綜上所述,在事后可解釋的知識追蹤模型中,無論是全局可解釋還是局部可解釋,都需要研究者后期開發解釋技術或構建解釋模型。其中,全局可解釋的知識追蹤模型主要圍繞可解釋結構和可解釋參數展開,其模型能否被解釋依賴于模型自身的結構和數據;而局部可解釋的知識追蹤模型關注特定樣本或輸入的解釋,側重于可解釋技術的開發和外部可解釋模塊的引入,因而其結果不能很好地泛化到其他模型中。另外,對模型的解釋需要大量的分析和計算,也會導致模型的復雜度增加。結合上述分析,本研究同樣從優點、缺點兩個維度對不同類型的事后可解釋知識追蹤模型進行了對比,具體如表2所示。
四 可解釋知識追蹤模型的教學應用展望
隨著深度神經網絡的發展,可解釋知識追蹤模型的性能得到了顯著提升,但由于其“黑盒”性質,使模型的可解釋性仍然是一個難以回避的問題。為了更好地指導教育教學工作的開展,本研究在對比分析不同類型的事前、事后可解釋知識追蹤模型之優點與缺點的基礎上,對未來可解釋知識追蹤模型的教學應用進行了以下展望:
1 模型可視化,圖文輔助解釋
模型可視化是一種重要的事后解釋技術,通過可視化模型結構、權重、激活和梯度等信息,可以幫助理解模型的內部運作機制和學習過程。在應用可解釋知識追蹤模型時,研究者往往使用熱力圖來展示學習者的知識狀態變化情況,據此分析學習者學習過程中的薄弱點。與知識圖譜相結合,可解釋知識追蹤模型能夠精準刻畫學習者的知識結構,實現可視化的認知結構表征,因此可以用來進行教育診斷與干預[34]。可視化的圖像不僅可以幫助學習者理解模型的運作機制,還可以幫助學習者發現模型中存在的問題和缺陷,從而進行模型的調整與優化。
2 融入教育規律,解釋支持決策
從認知學習理論出發,將教育規律融入知識追蹤模型的解釋過程,可以使解釋更有說服力和可信度,并支持更明智的決策。例如,應用相關的教育知識,可以分析可解釋知識追蹤模型中特定參數以及模型輸出與學習者知識水平之間的關聯,幫助教育決策者理解模型的預測結果和學習者的知識掌握狀況。此外,將模型輸出與課程設置、評估標準等進行比較和解釋,可以更好地指導教育決策和教學實踐,幫助學習者提高學習成績。因此,未來可解釋知識追蹤模型可以結合教育教學規律,以做出更明智的教育決策。
3 多模態數據融合,增強模型可信度
當前,知識追蹤領域常用的數據類型有學習者的題目編號、學生表現、技能名稱、心理特征屬性等,這些數據通常呈現出不同的模態。將不同模態的數據進行融合應用,可以提高知識追蹤模型的準確度和可信度,增強模型的可解釋性。多模態數據融合利用不同模態數據之間的互補性、增強模型的泛化能力、提高模型的魯棒性等方式,來增強模型的可信度。因此,多模態數據融合是提升知識追蹤模型可解釋性的重要方向之一。后續研究可以探索研發多模態數據融合的技術,促進知識追蹤模型在學習資源推薦、自適應學習等方面的應用。
4 解釋方法探索,擴展解釋途徑
盡管現有的可解釋方法能在一定程度上解釋部分知識追蹤模型的預測結果,但其泛化能力明顯不足。根據知識追蹤模型的特點,研究者更傾向于探析學習交互過程中有哪些特征對知識掌握水平起到了關鍵作用,而這也是學習者和教師關注的重點。因此,比起全局可解釋方法,局部可解釋方法更適合知識追蹤模型的解釋。從模型的特征輸入角度分析,單特征的知識追蹤模型可以通過敏感性分析方法,對模型進行局部解釋;而涉及多個特征的模型可以采用沙普利可加性解釋(SHapley Additive exPlanations,SHAP)方法計算每個特征的重要性值,據此確定特征對模型的影響程度。
5 可解釋性評估,科學設計指標
目前,在知識追蹤領域關于模型可解釋性的評估研究相對缺乏,原因主要在于深度學習具有不透明性和復雜性,使研究者在設計評估指標時很難對學習者提取統一的監督信息。同時,研究者對評價指標的引入具有主觀性,不同模型的可解釋性評估方式也不盡相同。因此,在針對可解釋知識追蹤模型的未來研究中,開發合理的可解釋性評估指標也是一項重要的任務。對此,研究者應充分考慮模型的算法、數據特征、知識追蹤等專業知識的應用情況和人類的認知水平等多方面因素,科學設計合理的可解釋性評估指標。
參考文獻
[1]習近平.高舉中國特色社會主義偉大旗幟 為全面建設社會主義現代化國家而團結奮斗——在中國共產黨第二十次全國代表大會上的報告[OL].
[2]Corbett A T, Anderson J R. Knowledge tracing: Modeling the acquisition of procedural knowledge[J]. User Modeling and User-adapted Interaction, 1994,(4):253-278.
[3][12]戴靜,顧小清,江波.殊途同歸:認知診斷與知識追蹤——兩種主流學習者知識狀態建模方法的比較[J].現代教育技術,2022,(4):88-98.
[4]劉桐,顧小清.走向可解釋性:打開教育中人工智能的“黑盒”[J].中國電化教育,2022,(5):82-90.
[5]Miller T. Explanation in artificial intelligence: Insights from the social sciences[J]. Artificial Intelligence, 2019,267:1-38.
[6][27]Lu Y, Wang D, Meng Q, et al. Towards interpretable deep learning models for knowledge tracing[A]. Artificial Intelligence in Education: 21st International Conference[C]. Ifrane: Springer, 2020:185-190.
[7][25]Minn S, Vie J J, Takeuchi K, et al. Interpretable knowledge tracing: Simple and efficient student modeling with causal relations[A]. Proceedings of the AAAI Conference on Artificial Intelligence[C]. California: AAAI Press, 2022:12810-12818.
[8]紀守領,李進鋒,杜天宇,等.機器學習模型可解釋性方法、應用與安全研究綜述[J].計算機研究與發展,2019,(10):2071-2096.
[9]Pardos Z A, Heffernan N T. Modeling individualization in a Bayesian networks implementation of knowledge tracing[A]. International Conference on User Modeling Adaptation, and Personalization[C]. Berlin: Springer, 2010:255-266.
[10]Lin C, Chi M. Intervention-BKT: Incorporating instructional interventions into Bayesian knowledge tracing[A]. International Conference on Intelligent Tutoring Systems[C]. Cham: Springer, 2016:208-218.
[11]Nedungadi P, Remya M S. Predicting students performance on intelligent tutoring system—Personalized clustered BKT (PC-BKT) model[A]. 2014 IEEE Frontiers in Education Conference Proceedings[C]. Madrid: IEEE Press, 2014:1-6.
[13]Cen H, Koedinger K, Junker B. Learning factors analysis—A general method for cognitive model evaluation and improvement[A]. International Conference on Intelligent Tutoring Systems[C]. Berlin: Springer, 2006:164-175.
[14]Cen H. Generalized learning factors analysis: Improving cognitive models with machine learning[M]. Pittsburgh: Carnegie Mellon University, 2009:1-51.
[15]Pavlik P I, Cen H, Koedinger K R. Performance factors analysis—A new alternative to knowledge tracing[A]. The 2009 Conference on Artificial Intelligence in Education: Building Learning Systems that Care: From Knowledge Representation to Affective Modelling[C]. Netherlands: IOS Press, 2009:531-538.
[16]盧宇,王德亮,章志,等.智能導學系統中的知識追蹤建模綜述[J].現代教育技術,2021,(11):87-95.
[17]Ghosh A, Heffernan N, Lan A S. Context-aware attentive knowledge tracing[A]. ACM SIGKDD Conference on Knowledge Discovery and Data Mining[C]. New York: ACM, 2020:2330-2339.
[18]Liu Q, Huang Z, Yin Y, et al. Ekt: Exercise-aware knowledge tracing for student performance prediction[J]. IEEE Transactions on Knowledge and Data Engineering, 2019,(1):100-115.
[19]Pandey S, Srivastava J. RKT: Relation-aware self-attention for knowledge tracing[A]. Proceedings of the 29th ACM International Conference on Information & Knowledge Management[C]. New York: ACM, 2020:1205-1214.
[20]K?ser T, Klingler S, Schwing A G, et al. Dynamic Bayesian networks for student modeling[J]. IEEE Transactions on Learning Technologies, 2017,(4):450-462.
[21]Tong S, Liu Q, Huang W, et al. Structure-based knowledge tracing: An influence propagation view[A]. 2020 IEEE International Conference on Data Mining[C]. Sorrento: IEEE Press, 2020:541-550.
[22]王劍,李易清,石琦.融合多維偏好與知識追蹤的個性化學習路徑推薦——以“系統建模”課程為例[J].現代教育技術,2023,(11):99-108.
[23]Su Y, Cheng Z, Luo P, et al. Time-and-concept enhanced deep multidimensional item response theory for interpretable knowledge tracing[J]. Knowledge-Based Systems, 2021,218:106819.
[24]Wang C, Ma W, Zhang M, et al. Temporal cross-effects in knowledge tracing[A]. Proceedings of the 14th ACM International Conference on Web Search and Data Mining[C]. New York: Association for Computing Machinery, 2021:517-525.
[26]Li Q, Yuan X, Liu S, et al. A genetic causal explainer for deep knowledge tracing[J]. IEEE Transactions on Evolutionary Computation, 2023,(99):1.
[28]Lu Y, Wang D, Chen P, et al. Interpreting deep learning models for knowledge tracing[J]. International Journal of Artificial Intelligence in Education, 2023,(3):519-542.
[29]Nakagawa H, Iwasawa Y, Matsuo Y. Graph-based knowledge tracing: Modeling student proficiency using graph neural network[A]. IEEE/WIC/ACM International Conference on Web Intelligence[C]. Thessaloniki: ACM, 2019:156-163.
[30]Song X, Li J, Tang Y, et al. Jkt: A joint graph convolutional network based deep knowledge tracing[J]. Information Sciences, 2021,580:510-523.
[31]Holster T A, Lake J. Guessing and the Rasch model[J]. Language Assessment Quarterly, 2016,(2):124-141.
[32]Yeung C K. Deep-IRT: Make deep learning based knowledge tracing explainable using item response theory[OL].
[33]Gan W, Sun Y, Sun Y. Knowledge interaction enhanced knowledge tracing for learner performance prediction[A]. 2020 7th International Conference on Behavioural and Social Computing (BESC)[C]. Bournemouth: IEEE, 2020:1-6.
[34]周東岱,董曉曉,顧恒年,等.基于雙流結構和多知識點映射結構改進的深度知識追蹤模型[J].現代教育技術,2022,(8):111-118.
Focus on Interpretability: Overview and Prospect of Knowledge Tracking Models
YANG Wen-Yang1,2YANG Yi-Hui1
(1. School of Computer, Xian Shiyou University, Xian, Shaanxi, China 710065;
2. Key Laboratory of Modern Teaching Technology, Ministry of Education, Xian, Shaanxi, China 710062)
Abstract: The interpretability of model is an important index to evaluate its practicability and practical application value, but current knowledge tracking models based deep learning generally has the problem of poor interpretability, which leads to the opaque teaching decision-making process. Therefore, this paper firstly introduced the process of knowledge tracking, analyzed the interpretability of knowledge tracking model, and divided interpretable knowledge tracking models into Ante-hoc interpretable knowledge tracking model and Post-hoc interpretable knowledge tracking model according to the time of interpretable methods in the model training process. Then, this paper reclassified the two kinds of models, respectively, and compared different types of Ante-hoc and Post-hoc interpretable knowledge tracking models from two dimensions of advantages and disadvantages. Finally, from the aspects of model visualization, integration of education rules, multi-modal data fusion, interpretation method exploration, interpretability evaluation, the teaching application of interpretable knowledge tracking model in future was prospected. The research of this paper was helpful to enhance the practicability of knowledge tracking model in teaching and learning, and promote the process of education digitization.
Keywords: knowledge tracking; interpretability; global interpretability; local interpretability; smart education
*基金項目:本文為2023年度陜西省教師教育改革與教師發展研究重點項目“教育數字化背景下高校教師課堂教學評價創新路徑研究”(項目編號:SJS2023ZD020)、現代教學技術教育部重點實驗室2023年開放課題資助項目“融合注意力特征的腦電信號情感識別方法研究”(項目編號:2023KF05)、西安石油大學研究生創新與實踐能力培養計劃項目“智慧教育環境下基于圖神經網絡的知識追蹤模型研究”(項目編號:YCS22111028)的階段性研究成果。
作者簡介:楊文陽,副教授,博士,研究方向為數字化學習、智慧教育,郵箱為ywy80910@163.com。
收稿日期:2023年9月12日
編輯:小米
猜你喜歡
青年時代(2017年2期)2017-02-16 14:01:19
現代商貿工業(2016年22期)2016-12-27 10:49:22
亞太教育(2016年31期)2016-12-12 20:44:55
新教育時代·教師版(2016年25期)2016-12-06 08:07:24
中國信息技術教育(2016年22期)2016-12-06 01:22:18
中國遠程教育(2016年9期)2016-11-19 12:21:26
考試周刊(2016年49期)2016-07-05 07:44:10
中小學信息技術教育(2015年10期)2015-12-01 17:58:53
心理技術與應用(2015年10期)2015-10-09 13:34:55
中國信息化周報(2015年31期)2015-08-29 01:23:18
