基于類型輔助引導的代碼注釋生成模型
2024-09-14 00:00:00劉利呂韋岑汪洋
無線電通信技術 2024年4期
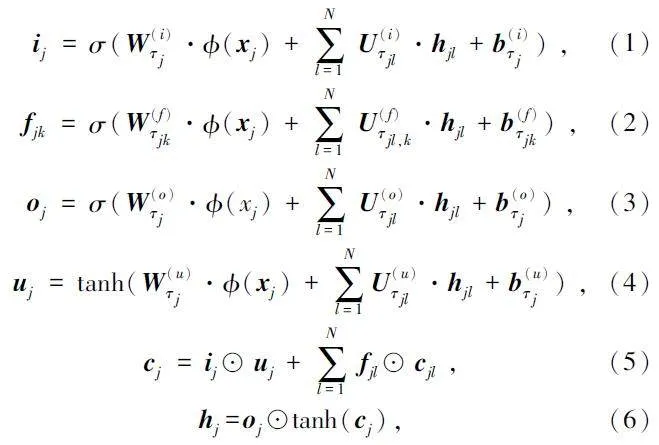
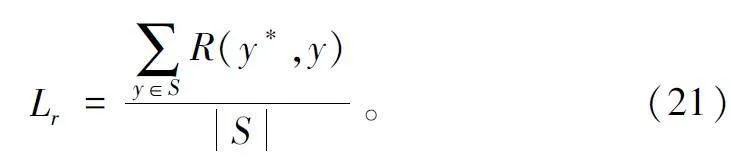
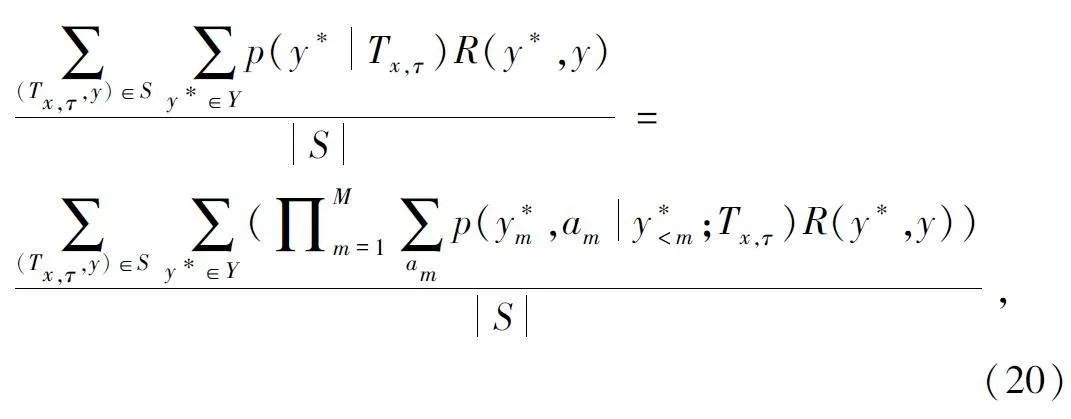


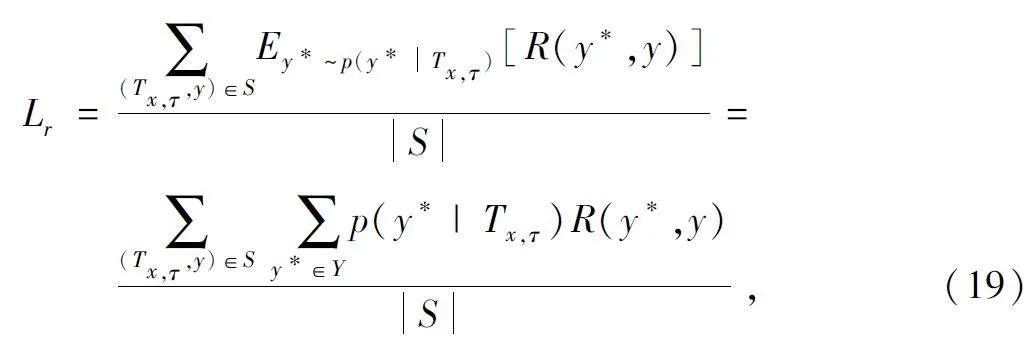
摘 要:代碼注釋生成方法通常基于結構-序列(Structure-Sequence,Struct2Seq)框架,但忽略了代碼注釋的類型信息,例如操作符、字符串等。由于類型信息之間的層次具有依賴性,將類型信息引入已有的Struct2Seq 框架并不適用。為了解決上述問題,提出一種基于類型輔助引導的代碼注釋生成(Code Comment Generation based on Type-assisted Guid-ance,CCG-TG)模型,將源代碼視為帶有類型信息的n 元樹。該模型包含一個關聯類型編碼器和一個限制類型解碼器,可以對源代碼進行自適應總結。此外,提出一種多級強化學習(Multi-level Reinforcement Learning,MRL)方法來優化所提模型的訓練過程。在多個數據集上進行實驗,與多種基準模型對比,證明所提CCG-TG 模型在所有評價指標上的性能最優。
關鍵詞:代碼注釋生成;類型信息;結構序列框架;類型輔助引導;強化學習
中圖分類號:TP311 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3114(2024)04-0807-08
0 引言
程序員對代碼進行注釋對維護軟件項目代碼庫以及顯著提高可讀性至關重要。代碼注釋生成旨在借助深度學習技術將程序代碼自動轉換為自然語言,以提高代碼開發和維護的效率[1]。
現有方法利用代碼固有的結構特征,以編碼器- 解碼器的方式解決結構- 序列(Structure-Sequence,Struct2Seq)的編碼生成任務。充分利用抽象語法樹(Abstract Syntax Trees,AST)的語法結構或源代碼的解析樹,可以顯著提升注釋生成的質量[2-3]。另外,通過提取代碼的結構信息,使用圖神經網絡學習更新各節點信息也可以提高注釋生成的質量[3-5]。文獻[6]構建了一種結構感知的混合編碼模型,兼顧程序代碼的序列表示和結構表示,并利用聚合編碼過程將兩類信息融合至解碼器。
代碼注釋生成框架可以從源代碼片段,例如結構化查詢語言(Structed Query Language,SQL)、lambda 表達式等,生成自然語言。作為一種特定的自然語言生成任務[7-8],主流的方法可分為文本驅動方法和結構驅動方法。
文本驅動方法:該類方法僅考慮源代碼的順序文本信息。文獻[9]使用主題模型和n-gram 來預測源代碼片段的注釋。Iyer 等[10]提出一種帶有注意力的長短期記憶網絡(Long Short Term Memory,LSTM)語言模型,用于生成關于C#和SQL 的注釋。文獻[11 ]提出一種基于卷積神經網絡(Convolutional Neural Network,CNN)的自動化代碼注釋生成方法來緩解長期依賴問題,以生成更準確的注釋信息。文獻[12]研究了14 個不同的Java 軟件項目使用代碼注釋的風格,提出一種機器學習方法將行級Java 代碼注釋自動分類。
結構驅動方法:該方法考慮了不同程序語言的結構信息,優于文本驅動方法。Alon 等[13]在AST中將代碼片段處理為組合路徑集,并在解碼過程中使用注意力機制選擇相關路徑。Hu 等[14]提出一種基于神經機器翻譯的模型,該模型將AST 節點序列作為輸入,并捕獲Java 代碼的結構和語義。Haque等[15]提出使用三類編碼器分別對給定子程序的代碼/ 文本、AST 和文件上下文進行編碼,其中文件上下文是子程序的代碼/ 文本嵌入矢量。
復制機制:通過重用部分輸入而不是從目標詞匯表中選擇單詞來解決生成任務中的域外詞(Outof Vocabulary,OOV)問題。文獻[16]提出一種混合指針生成器網絡,將指針網絡[17]用于抽象文本摘要的標準序列-序列(Sequence-Sequence,Seq2Seq)模型。Gu 等[18]提出使用COPYNET 將傳統的復制機制融入到Seq2Seq 模型中,并有選擇地將輸入片段復制到輸出序列中。文獻[19]提出一種指針生成網絡模型,該模型結合了抽取式和生成式兩種文本摘要方法,能夠選擇從源文本中復制單詞或利用詞匯表來生成新的摘要信息。
為了解決上述問題,提出一種基于類型輔助引導的代碼注釋生成(Code Comment Generation basedon Type-assisted Guidance,CCGTG)模型,將源代碼視為帶有類型信息的n 元樹。該模型包含一個關聯類型編碼器和一個限制類型解碼器,可以對源代碼進行自適應總結。此外,提出一種多級強化學習(Multi-level Reinforcement Learning,MRL)方法來優化所提模型的訓練過程。
1 相關定義
定義1(令牌類型樹)令牌類型樹Tx,τ 是一棵n 元樹,表示節點集V 的源代碼。V = {v1,v2,…,v V }表示偏序節點集,令節點vi = {xi,τi },xi 表示令牌序列,τi 表示語法類型集T 中的類型。可以從源代碼的令牌信息及其AST 的類型信息構造令牌類型樹。
定義2(代碼注釋生成任務)設S 為訓練數據集,標記樣本(Tx ,τ,y)∈S,其中Tx,τ 為輸入的令牌類型樹,y =(y1,y2,…,yM)為帶有M 個詞的真實注釋。代碼注釋生成的任務是設計一種模型,該模型將未標記的樣本Tx,τ 作為輸入,并預測輸出y 作為注釋。
2 CCGTG 模型
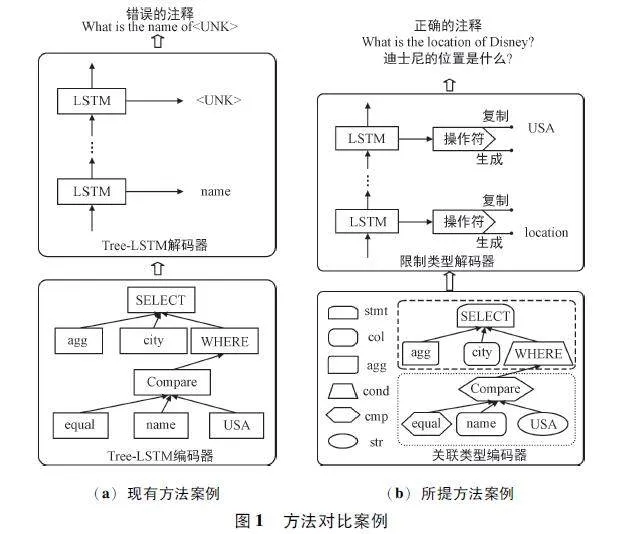
圖1(a)展示了使用樹型結構的長短期記憶網絡(Tree-Long Short Term Memory,Tree-LSTM)編碼器提取SQL 結構信息,關鍵字SELECT 的子樹和WHERE 子句的子樹具有相同的結構,但類型不同。如果忽略了類型信息,傳統編碼器使用相同的神經網絡參數對結構樹進行編碼,會導致注釋生成不準確。因此,充分利用類型信息,提出基于類型輔助引導的代碼注釋生成模型。
在圖1(a)的解碼器中,缺少TOM 節點的類型通常會導致生成的注釋中出現未知符號或詞語(記作UNK)。因此,解決局限性的關鍵是有效利用節點類型信息。
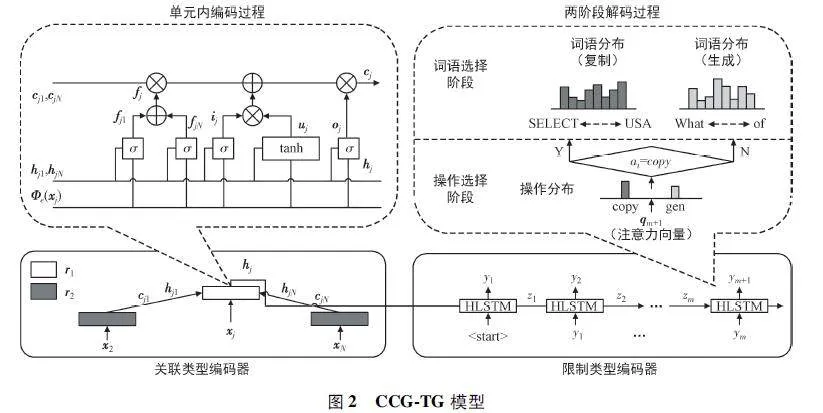
如圖1(b)所示,在編碼階段,包含一個關聯類型編碼器,對n 元樹的節點類型信息進行編碼;在解碼階段,利用類型信息輔助注釋生成,并通過操作選擇階段和詞語選擇階段來減少搜索空間大小,避免出現OOV 的情況。考慮到解碼過程中的操作選擇結果沒有真實標簽,進一步設計一種MRL 方法來優化訓練過程。
所提CCG-TG 模型遵循編碼器-解碼器架構,主要由關聯類型編碼器和限制類型解碼器組成。如圖2 左側所示,關聯類型編碼器循環地將令牌類型樹Tx,τ 作為輸入,并使用隱藏狀態保持源代碼的語義信息。關聯類型編碼器使用多組參數集來學習不同類型的節點。在處理輸入令牌類型樹時,根據當前節點的類型自適應地調用相應單元的參數,使結構化語義表示能夠包含源代碼的類型信息。
如圖2 右側所示,限制類型解碼器以關聯類型編碼器的原始令牌類型樹Tx,τ 及其語義表示作為輸入,并生成相應的注釋。采用注意力機制計算注意力向量,通過兩階段解碼過程生成輸出詞:
① 根據操作的分布決定是從原始的令牌類型樹復制輸出詞還是從當前的隱藏狀態生成輸出詞。
② 如果選擇復制操作,則從Tx,τ 中選擇的節點復制具有類型限制的單詞;否則,將從目標字典中選擇候選詞。
兩階段解碼過程均由注意力機制從編碼器的隱藏狀態中提取類型來引導,實現了復制和生成過程之間的自適應切換,不僅減少了生成過程的搜索空間,而且復制機制解決了OOV 問題。
盡管所提CCG-TG 利用代碼中的類型信息提供了有效的解決方案,但其訓練過程面臨如下困難:① 沒有為操作選擇階段提供訓練標簽;② 評價指標與目標函數無法適配。因此,進一步設計一個MRL 方法來訓練CCG-TG 模型。在MRL 訓練中,CCG-TG 模型不依賴于操作選擇階段的真實標簽,將評價指標作為學習獎勵反饋到訓練過程。
2. 1 關聯類型編碼器
關聯類型編碼器用于學習輸入源代碼的語義表示,為具有相同結構但不同語義的子樹進行信息總結。關聯類型編碼器的本質是n 元Tree-LSTM[20]。將類型信息作為編碼器網絡學習參數集的索引進行集成,而不是直接將類型信息作為特征輸入到編碼器中進行學習。換句話說,通過不同的類型定義不同的參數集,提供了更詳細的輸入信息。令牌類型樹包含N 個有序子節點,索引1 ~ N。對于第j 個節點,其第k 個子節點的隱藏狀態和存儲單元分別表示為hjk 和cjk。為了有效地捕獲類型信息,設置和為第j 個節點的權重和偏置,為第j 個節點的第k 個子節點權重,n 元Tree-LSTM 的形式化表示如式(1)~ 式(6)所示。
式中:fjk 表示第j 個節點的第k 個子節點參數向量,Uτjl,k 表示第k 個遺忘門中第j 個節點的第l 個子節點的類型權重。
2. 2 限制類型解碼器
本節介紹解碼階段的限制類型解碼器,將類型信息合并到兩階段解碼過程中。解碼時,使用高速LSTM(Highway LSTM,HLSTM)[21]作為基本解碼單元。采用注意力機制,將編碼器的隱藏狀態作為輸入,生成注意力向量。得到的注意力向量作為兩階段解碼過程的輸入,分別稱為操作選擇階段和詞語選擇階段。操作選擇階段在生成操作和復制操作之間進行選擇。如果選擇生成操作,將從目標字典中生成預測的單詞。如果選擇復制操作,則啟用類型限制復制機制,通過屏蔽非法語法類型來限制搜索空間。此外,使用復制衰減策略解決由注意力機制引起的對特定節點的重復關注問題。
HLSTM 重復利用記憶單元堆疊層之間的空間域連接。HLSTM 僅在細胞狀態的計算方式上與傳統LSTM 不同,如式(7)~ 式(8)所示:
clt=dlt·cl-1t +f lt·clt-1 +ilt·tanh(Wlxc·xlt+Wlhc·hlt-1 +blc),(7)
dlt=σ(Wlxd xlt+Wlcd clt-1 +Wlcd cl-1t +bld), (8)
式中:dlt表示連接第l-1 層的細胞狀態cl-1t 和第l 層細胞狀態clt的深度門,f lt表示第l 層遺忘門,ilt表示輸入門。
編碼器中根節點的隱藏狀態記為hr,初始化解碼器的隱藏狀態z0 ←hr。在時間步長為m 時,給定輸出ym -1 和時間步長m-1 時解碼器的隱藏狀態zm -1,由解碼器中的HLSTM 單元計算隱藏狀態zm,如式(9)所示:
zm = HLSTM(zm -1,ym -1)。(9)
注意力向量qm 的計算方法如式(10)~ 式(11)所示:
式中:Wq 為注意力機制的權重參數,αmj 為注意力分數,|Vx| 為節點數。注意力向量包含標記和類型信息。
操作選擇階段根據編碼器的注意力向量和隱藏狀態決定使用復制操作還是生成操作來選擇單詞。給定時間步長m 的注意力向量qm,操作選擇階段估計條件概率計算方法如式(12)所示:
p(am |y*<m;Tx,τ)= softmax(Ws·qm), (12)
式中:am∈{0,1},0 和1 分別表示復制和生成操作,Ws 表示可訓練參數。式(12)由一個全連接層和一個softmax 激活函數實現。由于沒有操作選擇的真值標簽,采用多級MRL 方法訓練操作選擇階段,詳細內容見2. 3 節。
詞語選擇階段也包括兩個分支,如果在操作選擇階段選擇了生成操作,注意力向量將被輸入softmax 層來預測目標詞分布式:
p(ym| am =1,y*<m;Tx,τ)= softmax(Wg·qm), (13)
式中:Wg 表示輸出層的可訓練參數。
如果選擇復制操作,使用點積(Dot-product)得分函數計算節點隱藏狀態和注意力向量的得分向量sm。得分向量將被輸入到softmax 層來預測輸入詞的分布,計算方法如式(14)~ 式(15)所示:
sm =[h1,h2,…,h |Vx| ] T ·qm, (14)
p(ym| am =0;y*<m;Tx,τ)= softmax(sm)。(15)
為了過濾非法復制的候選項,在每個解碼步驟m 中使用基于語法類型的掩碼向量dm,其每個維度對應于令牌類型樹的每個節點。如果令牌類型樹中節點的掩碼表明該節點需要被過濾掉,則設置為負無窮。否則,設置為0。受限復制階段如式(16)所示:
p(ym |am =0;y*<m;Tx,τ)= softmax(sm +dm)。(16)
在式(13)和式(16)中,詞語概率分布用輸入單詞或目標字典單詞的softmax 輸出表示。在每個時間步驟中,將選擇概率最高的詞語。
使用注意力向量作為指針來引導復制過程。帶有類型限制的復制機制可能關注特定節點,忽略其他可用節點,使得某些復制的令牌在單個生成的文本中重復出現,導致內容大量冗余。因此,引入復制衰減策略來微調某些未被復制節點的概率。定義第i 個樹節點在第m 個解碼步驟中的衰減率為λm,i。如果在時間步長中復制一個節點,則將其衰減率初始化為1。在下一個時間步m+1 中,衰減率通過系數γ∈(0,1)縮放,如式(17)所示:
λm +1,i =γ*λm,i。(17)
限制類型解碼器的完整公式如下:
p(ym |am =0;y*<m;Tx,τ)= softmax(sm +dm)⊙(1-λm)。(18)
2. 3 多級強化學習
訓練所提CCGTG 存在2 個挑戰:① 缺乏操作選擇階段的基礎真值標簽;② 評估指標與目標函數之間不兼容。為了解決上述問題,提出一種MRL 方法來訓練操作選擇階段和詞語選擇階段。
將MRL 的目標設置為最大化預測序列y*和真值序列y 之間獎勵R(y*,y)的期望值記為Lr,可以表示為輸入元組{Tx,τ,y}的函數:
式中:Y 表示候選注釋序列的集合。獎勵R(y*,y)是不可微的評價指標。通過從分布p(y* Tx,τ)中采樣y*來近似期望值。預測序列y*依賴于詞語選擇階段和操作選擇階段,令a 表示操作選擇階段的動作。將動作am 引入時間步長m 中,兩個階段的聯合分布如式(20)所示:
式中:模型從y*< m,am,Tx ,τ 為條件的詞語分布中選擇詞語y*m ,而操作選擇的動作am 需要單獨計算,在詞語選擇階段和操作選擇階段之間存在多級依賴關系。Y 表示所有候選注釋的搜索空間,利用該搜索空間最大化Lr 的計算代價巨大。解碼過程可近似于從概率分布中采樣,采樣方法采用Gumbel-Max 算法[22]。經過最大采樣步長M 時,Lr 可近似于:
3 實驗與分析
3. 1 數據集描述
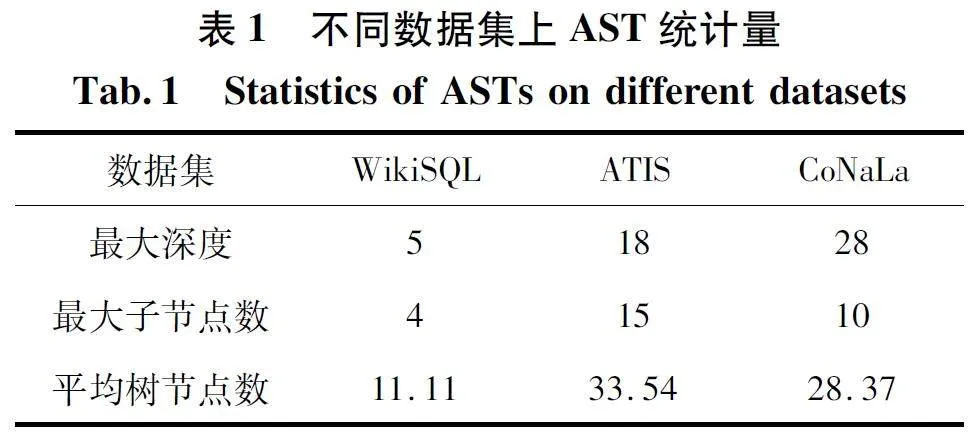
本文在3 個通用的基準數據集上評估CCGTG框架的性能,分別是WikiSQL[23]、ATIS[24]和CoNaLa[25]。WikiSQL 是一個數據集,包含了80 654 個手工標注的SQL 查詢和自然語言注釋對示例,分布在維基百科的2 424 個表中。SQL 查詢進一步分為訓練集(5 635 個)、開發集(8 421 個)和測試集(1 587 個)。ATIS 以lambdacalculus 的形式存在,是一個包含4 434 個訓練實例、491 個開發實例和448 個測試實例的5 373 個飛行信息查詢集合。CoNaLa 是一個與python 相關的數據集,使用其原始版本,其中包括從Stack Overflow 抓取的2 879 個片段對,分為2 379 個訓練實例和500 個測試實例。從其訓練集中提取了200 個隨機樣本作為開發集。
根據抽象語法描述語言(Abstract Syntax De-scription Language,ASDL)語法,將WikiSQL 的SQL查詢轉換成具有6 種類型的AST,其中SQL 查詢的ASDL 語法在文獻[25]提出。根據文獻[24]提出的方法,將ATIS 的lambda-calculus 邏輯形式轉換為7 種類型的樹結構。CoNaLa 的python 代碼段則按照python 的官方ASDL 語法轉化為20 種類型的AST。這些數據集的AST 數據如表1 所示,其中顯示了AST 的最大深度(Max-Tree-Depth)、AST 中的最大子節點數(Max-ChildCount)和AST 中的平均樹節點數(Avg-Tree-NodeCount)。
3. 2 基準模型
選擇具有代表性的代碼注釋生成設計作為比較基準。選擇Code-NN[10]的原因在于其第一個將源代碼轉化為句子的模型;指針生成器(PG)是一種基于Seq2Seq 的模型,具有標準的復制機制。此外,選擇了Tree-to-Sequence (Tree2Seq)模型[26]。在Tree2Seq 模型中加入了復制機制,作為基準模型(T2S+CP)。Graph-to-Sequence(Graph2Seq)[27]作為基于圖的基準模型進行比較,因為沒有發布數據預處理的代碼,于是將SQL 數據源代碼的樹狀結構表示轉換成有向圖,用于復制。
3. 3 超參數設置
Code-NN 的嵌入大小和隱藏大小均為400,使用隨機均勻初始化器進行初始化,初始化權重為0. 35,并采用隨機梯度下降算法訓練模型,學習率為0. 5。P-G 采用128 嵌入大小、256 隱藏大小,并使用0. 02 初始化權重的隨機均勻初始化器進行初始化,采用Adam 優化器訓練模型,學習率為0. 001。Graph2Seq 采用100 嵌入大小、200 隱藏大小,并使用截斷正態初始化器進行初始化。使用Adam 優化器以0. 001 的學習率訓練模型。
使用Xavier 初始化器[28]初始化提出的CCG-TG框架的參數。嵌入的大小與LSTM 狀態和隱藏層的維度相當,ATIS 和CoNaLa 的維度為64,WikiSQL 的維度為128。CCG-TG 使用學習率為0. 001 的Adam優化器進行訓練。為了縮小詞匯量,源代碼詞匯和目標注釋詞匯中都不保留低頻詞。WikiSQL 和ATIS 的最小閾值頻率設為4,而CoNaLa 的最小閾值頻率設為2。所有基準模型和所提出模型的最小批大小都設為32。
3. 4 評估標準
使用基于n-gram 的BLEU[29]和ROUGE 評價來評估生成評論的質量,并在基于MRL 的訓練中使用上述評價指標來設置獎勵。BLEU-4、ROUGE-2 和ROUGE-L 被用來評估模型的性能,因為其為基于上下文的文本生成中最具代表性的評估指標。
3. 5 不同基準模型對比
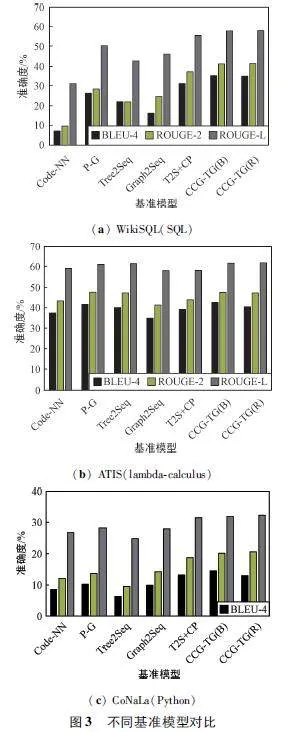
圖3 給出了基準框架和所提出的框架的評估結果。由MRL 可以切換到不同的獎勵函數,因此同時評估了框架的BLEU 定向訓練和ROUGE 定向訓練,分別稱為CCG-TG(B)和CCG-TG(R)。相比之下,CCG-TG(B)和CCG-TG(R)的結果略有不同。不過,這兩個結果都明顯高于所有選定的同類結果,表明所提出的框架在所有使用不同編程語言的數據集上都具有最佳的生成質量。
具體而言,與T2S+CP 相比,CCG-TG 在WikiSQL上的BLEU-4 指標提高了4%,ROUGE-2 指標提高了4. 1%,ROUGE-L 指標提高了2. 8%。對于與lambda計算相關的語料庫,CCG-TG 在ATIS 上的BLEU-4 提高了3. 5%、ROUGE-2 提高了3. 7%、ROUGE-L 提高了3. 6%。由于ATIS 中lambda-calculus 邏輯形式的子樹差異很大,因此其性能比其他兩個語料庫更難提高。在與python 相關的語料庫中,與基準中最好的語料庫相比,CCG-TG 在CoNaLa 上的BLEU-4 提高了1. 2% ,ROUGE-2 提高了1. 8% ,ROUGE-L 提高了0. 7% 。CoNaLa 的評估得分和改進幅度較低的原因在于語法結構復雜和缺乏足夠的訓練樣本,即僅有2 174 個訓練樣本中的20 種類型,導致所提方法沒有充分發揮其優勢。在這兩個數據集上,CCG-TG 模型仍然優于對比算法。
3. 6 消融實驗
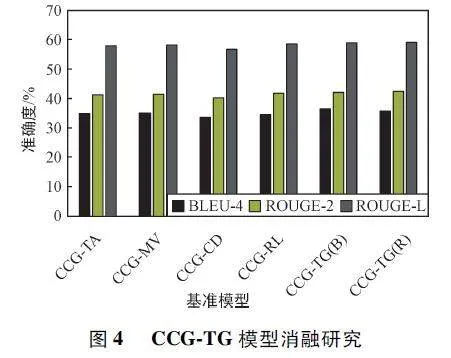
為了研究模型中每個組件的性能,對開發集進行了消融實驗。由于所有實驗結果趨勢相同,因此省略了其他數據集上的結果,僅介紹WikiSQL 數據集上的結果。模型的變體如下:
① CCG-TA:移除類型相關編碼器,改用樹狀LSTM。
② CCG-MV:移除掩碼向量dm。
③ CCG-CD:刪除復制衰減策略。
④ CCG-RL:用MLE 替換,將操作選擇的動作邊緣化。
圖4 給出了消融實驗的結果。總體而言,所有組件都是CCG-TG 框架必需的,并對最終輸出做出了重要貢獻。與CCG-TA 相比,標準CCG-TG 的高性能得益于關聯類型編碼器,它能自適應地處理不同類型的節點,并提取出更好的源代碼摘要。CCG-MV 和CCG-CD 的性能下降表明了類型限制掩碼向量和復制衰減策略的優勢。共同確保了復制和選詞的準確執行。CCG-TG 和CCG-RL 的比較表明了對所提出的框架訓練的必要性。
4 結束語
本文所提模型通過關聯類型編碼器和限制類型解碼器,充分利用了與代碼相關的類型信息,為模型的訓練提供了分層強化學習方法。實驗結果表明,與其他方法相比,本文所提模型有了顯著的改進,在軟件開發中具有很強的應用潛力。在未來的工作中,將通過設計高效的學習算法,將所提出模型擴展到更復雜的環境中。
參考文獻
[1] CAI R C,LIANG Z H,XU B Y,et al. TAG:TypeAuxiliary Guiding for Code Comment Generation[C]∥58th Annual Meeting of the Association for ComputationalLinguistics. Stroudsburg:ACL,2020:291-301.
[2] 王瀚森,王婷,陳鐵明,等. 融合語法和語義的代碼注釋生成方法[J]. 小型微型計算機系統,2023,44(11):2457-2463.
[3] 陳翔,于池,楊光,等. 基于雙重信息檢索的Bash 代碼注釋生成方法[J]. 軟件學報,2023,34(3):1310-1329.
[4] XU K,WU L F,WANG Z G,et al. SQLtoText Generationwith GraphtoSequence Model [C]∥2018 Conference onEmpirical Methods in Natural Language Processing.Brussels:ACL,2018:931-936.
[5] FERNANDES P,ALLAMANIS M,BROCKS M. StructuredNeural Summarization[C]∥7th International Conferenceon Learning Representations. New Orleans:ICLR,2019:1-18.
[6] 蔡瑞初,張盛強,許柏炎. 基于結構感知混合編碼模型的代碼注釋生成方法[J]. 計算機工程,2023,49(2):61-69.
[7] 段瑞雪,劉鑫,張仰森. 融合依存關系的對話關系抽取[J]. 重慶理工大學學報(自然科學),2023,37 (7):217-226.
[8] 王素芳,吳晨,陳志成. 智能節目輔助主持機器人系統與推薦算法[J]. 重慶理工大學學報(自然科學),2022,36(12):102-109.
[9] ATTIAS D M,COHEN W W. Natural Language Modelsfor Predicting Programming Comments[C]∥51st AnnualMeeting of the Association for Computational Linguistics.Sofia:ACL,2013:35-40.
[10]IYER S,IOANNIS K,CHEUNG A,et al. SummarizingSource Code Using a Neural Attention Model[C]∥54thAnnual Meeting of the Association for Computational Linguistics. Berlin:ACL,2016:2073-2083.
[11]彭斌,李征,劉勇,等. 基于卷積神經網絡的代碼注釋自動生成方法[J]. 計算機科學,2021,48 (12 ):117-124.
[12] PASCAR L,BRUNTINK M,BACCHELLI A. ClassifyingCode Comments in Java Software Systems[J]. EmpiricalSoftware Engineering,2019,24(3):1499-1537.
[13]ALON U,BRODY S,LEVY O,et al. Code2Seq:GeneratingSequences from Structured Representations of Code[C]∥7th International Conference on Learning Representations.New Orleans:ICLR,2019:1-22.
[14]HU X,LI G,XIA X,et al. Deep Code Comment Generation[C]∥26th Conference on Program Comprehension. NewYork:ACM,2018:200-210.
[15]HAQUE S,LECLAIR A,WU L F,et al. Improved AutomaticSummarization of Subroutines via Attention to File Context[C]∥17th International Conference on Mining Software Repositories. Seoul:ACM,2020:300-310.
[16]SEE A,LIU P J,MANNING C D. Get to the Point:Summarization with Pointergenerator Networks[C]∥55th AnnualMeeting of the Association for Computational Linguistics.Vancouver:ACL,2017:1073-1083.
[17]VINYALS O,FORTUNATO M,JAITLY N. Pointer Networks[C]∥Advances in Neural Information Processing Systems28:Annual Conference on Neural Information ProcessingSystems. Montreal:NIPS,2015:2692-2700.
[18]GU J T,LU Z D,LI H,et al. Incorporating Copying Mechanism in SequencetoSequence Learning[C]∥54th AnnualMeeting of the Association for Computational Linguistics.Berlin:ACL,2016:1631-1640.
[19]胡清豐,魏赟,鄔春學. 基于指針生成網絡的中文對話文本摘要模型[J]. 計算機系統應用,2023,32 (1):224-232.
[20]TAI K S,SOCHER R,MANNING C D. Improved SemanticRepresentations from Treestructured Long Short TermMemory Networks[C]∥53rd Annual Meeting of the Association for Computational Linguistics. Berlin:ACL,2015:1556-1566.
[21]ZHANG Y,CHEN G G,YU D,et al. Highway Long ShortTerm Memory RNNS for Distant Speech Recognition[C]∥2016 IEEE International Conference on Acoustics,Speech and Signal Processing. Shanghai:IEEE,2016:5755-5759.
[22]HUIJBEN I A,KOOL W,PAOLUS M B,et al. A Reviewof the Gumbelmax Trick and Its Extensions for DiscreteStochasticity in Machine Learning[J]. IEEE Transactionson Pattern Analysis and Machine Intelligence,2023,45(2):1353-1371.
[23]ZHONG V,XIONG C M,SOCHER R. Seq2SQL:GeneratingStructured Queries from Natural Language Using Reinforcement Learning[EB/ OL]. (2017-11-09)[2024-01-05].https:∥arxiv. org/ abs/1709. 00103.
[24]LI D,MIRELLA L. Language to Logical form with NeuralAttention[C]∥54th Annual Meeting of the Associationfor Computational Linguistics. Berlin:ACL,2016:33-43.
[25]PENGCHENG Y,GRAHAM N. A Syntactic Neural Modelfor Generalpurpose Code Generation[C]∥55th AnnualMeeting of the Association for Computational Linguistics.Berlin:ACL,2017:440- 450.
[26]AKIKO E,KAZUMA H,YOSHIMASA T. TreetoSequenceAttentional Neural Machine Translation[C]∥54th AnnualMeeting of the Association for Computational Linguistics.Berlin:ACL,2016:823-833.
[27]KUN X,LINGFEI W,ZHIGUO W,et al. Graph2Seq:Graph to Sequence Learning with Attentionbased NeuralNetworks[EB/ OL]. (2018 -12 -03)[2024 -01 -05].https:∥arxiv. org/ abs/1804. 00823.
[28]XAVIER G,YOSHUA B. Understanding the Difficulty ofTraining Deep Feedforward Neural Networks[C]∥13thInternational Conference on Artificial Intelligence and Statistics. Sardinia:JLMR,2010:249-256.
[29]KISHORE P,SALIM R,TODD W,et al. Bleu:A Methodfor Automatic Evaluation of Machine Translation[C]∥40th Annual Meeting of the Association for ComputationalLinguistics. Berlin:ACL,2002:311-318.
作者簡介:
劉 利 男,(1988—),碩士,講師。主要研究方向:數據挖掘、大數據技術、人工智能。
呂韋岑 男,(1987—)碩士,講師。主要研究方向:電子技術應用、物聯網技術。
汪 洋 男,(1987—),碩士,講師。主要研究方向:人工智能、數據挖掘、軟件技術。
基金項目:瀘州市科技計劃項目(2021-JYJ-96)
