基于ERes-ECAM 的動物聲紋識別
2024-09-14 00:00:00侯衛民孫藝菲劉峻滔
無線電通信技術 2024年4期
關鍵詞:深度學習

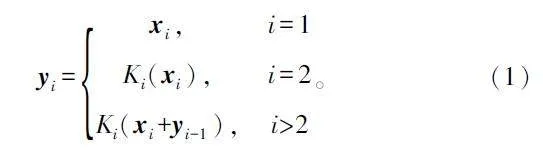
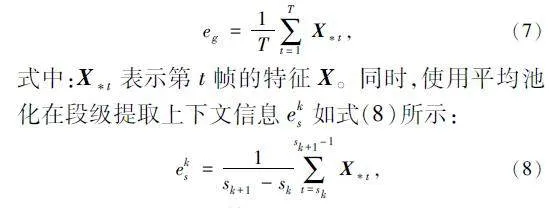

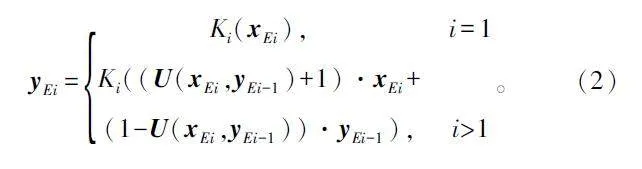
摘 要:聲紋識別技術不僅在人類身份驗證領域廣泛應用,在動物種類識別方面也取得一定進展。現有模型存在特征表達能力不足的問題,同時,在保證性能的前提下,模型的時間復雜度和推理速度有待優化。提出用于發聲動物嵌入學習的改進的殘差塊連接改進的上下文感知掩蔽(Enhanced Res2block connected Enhanced Context Aware Masking,ERes-ECAM)新型架構,采用了稠密連接的時延神經網絡(Densely-connected Time Delay Neural Network,D-TDNN)作為骨干,為了解決模糊不相關噪聲問題的同時能夠提取更多有效的關鍵信息,在D-TDNN 層中采用多粒度池化方法的改進的上下文感知掩蔽(Enhanced Context Aware Masking,ECAM)模塊,前端連接殘差模塊,通過局部特征融合(Local FeatureFusion,LFF)的方式,將殘差塊內提取的特征進行融合來提取局部信息,提升了聲紋驗證系統的準確性和魯棒性。在Anim-Celeb 和Pig-Celeb 兩個測試集中分別實驗,實驗結果表明,所提架構的等錯誤率(Equal Error Rate,EER)分別達到6. 88% 和7. 24% ,同時,對動物種類和豬只種類識別準確率達到了93. 12% 和92. 76% 。
關鍵詞:深度學習;聲紋識別;上下文感知掩碼;局部特征融合;動物種類識別
中圖分類號:TN912. 34 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3114(2024)04-0789-10
0 引言
近年來,隨著人類對生態環境的影響,尤其是對生物棲息地的破壞[1],各種類動物數量大幅下降。因此,無論是在復雜的野外環境還是在日常生產養殖方面,對動物種群進行有效監測是進行有效動物保護的重要途徑。目前,應用較多的是圖像觀測識別和DNA 分析檢測方法[2]。但是這些方法存在著成本高、識別率有待提高等缺點。于是,借助聲紋特征進行動物種類識別進而估計分布區域逐漸成為研究熱點[3]。采用動物聲紋識別動物種類具有高效率、非損傷、低干擾、大范圍等優勢,有很好的應用前景[4]。
此前,很多學者對基于深度學習方法的說話人識別系統做了大量研究。Snyder 等[5]提出一種基于時延神經網絡(Time Delay Neural Network,TDNN)的端到端說話人嵌入模型,該模型提取的說話人嵌入矢量稱為x-vector。Desplanques 等[6]提出的ECAPA-TDNN 神經網絡完成說話人驗證的任務,采用的是Res2Net 中的Res2block,其具有更大的感受野,可獲取不同尺度的特征。
同時,基于動物聲紋的動物種類識別方法也得到了廣泛的研究。Cheng 等[7]采用音頻信號的梅爾頻率倒譜系數作為輸入,利用高斯混合模型實現了基于鳥鳴的鳥類識別,最佳準確率達到92. 5% 。Towsey 等[8]的研究中,可以在野外有噪聲環境中區別黑噪鐘雀、大石鸻、雄性考拉、海蟾蜍、亞洲家壁虎、地棲鸚鵡、綠嘯冠鶇、澳洲鴉等動物的聲音。Larranaga 等[9]研究匈牙利馬地犬叫聲,性別識別達到了85. 13% 的準確率,發育程度識別(幼年、成年、老年)達到了80. 25% 的準確率。Sasmaz 等[10]采集了10 種動物的875 段音頻構建動物叫聲數據集,使用的網絡模型由3 個卷積層和3 個全連接層組成,提取動物叫聲音頻的梅爾頻率倒譜系數特征并作為模型輸入進行物種分類,最終獲得了75%的準確率。
雖然國內外學者對發聲動物的聲紋識別展開了深入研究,但仍存在一些問題:當前對發聲動物的聲紋識別的研究仍存在技術難點;忽視了不相關噪聲及缺乏局部信息交互的影響,不能提取更多有效的關鍵信息,導致模型特征表達能力不足;在不犧牲性能的前提下,現有模型的時間復雜度有待降低且推理速度有待提高。
針對上述問題,本文提出一種動物聲紋識別的新型架構,主要貢獻如下:
① 提出了改進的殘差塊連接改進的上下文感知掩蔽(Enhanced Res2block connected Enhanced ContextAware Masking,ERes-ECAM)架構利用動物聲紋進行身份識別,提取相關的聲紋特征訓練模型,建立了動物的聲紋識別系統,有效地對動物種類和豬只種類進行分類。
② 改進了稠密連接的TDNN(Densely-connectedTime Delay Neural Network,D-TDNN)骨干網絡以提升模型的表征能力,采用多粒度池化的方法使網絡模型在模糊不相關噪聲的同時能夠提取更多有效的關鍵信息。
③ 在ERes2block(Enhanced Res2block,ERes2-block)中提出局部特征融合(Local Feature Fusion,LFF)的結構,可以捕獲輸入信號中的本地模式,獲取更細粒度的特征,加強局部信息交互,從而提高聲紋識別系統的魯棒性和準確性。
1 網絡結構
1. 1 總體架構
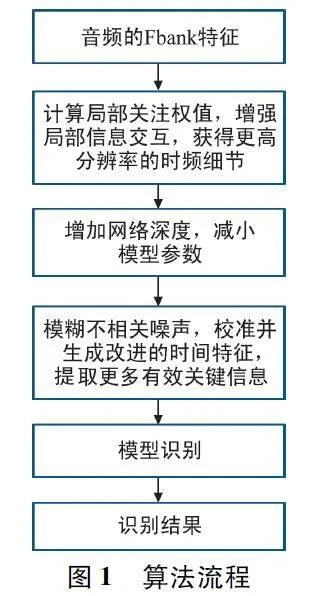
本文所提出的算法流程如圖1 所示。首先,提取音頻Fbank 特征作為輸入;其次,將輸入的特征經過前端殘差模塊(Front-end Residual Module,FRM)結構,計算局部關注權值,增強了局部信息的交互,從而獲得更高分辨率的時頻細節;再次,通過采用密集連接的D-TDNN 骨干網絡,包含3 個塊,增加了網絡深度,減小了模型參數;然后,通過每個D-TDNN層的改進的上下文感知掩蔽(Enhanced ContextAware Masking,ECAM)模塊,在模糊不相關噪聲的同時能提取更多有效關鍵信息;最后,利用ERes-ECAM 進行識別,得到識別結果。
本文提出的ERes-ECAM 網絡模型總體框架結構如圖2 所示。該體系結構主要由兩部分組成:FRM 和D-TDNN 結構。FRM 由多個殘差模塊組成,通過在時頻域對聲學特征進行編碼從而獲得更高分辨率的時頻細節。其中,在ERes2block 塊中通過在相鄰特征映射之間的類殘差連接中引入了一種注意特征融合(Attentional Feature Fusion,AFF)模塊,可對LFF 進行增強。FRM 所得到的特征圖隨后沿通道和頻率維度被平坦化,并用作D-TDNN 的輸入。
在D-TDNN 主干中包括3 個塊,每個塊包含一系列D-TDNN 層,通過ECAM 為每層D-TDNN 的輸出特征分配不同的權重。本文在ECAM 模塊中采用多粒度池化的方法,將全局平均池化和分段平均池化進行結合,更有效聚合不同層次的上下文信息。通過密集鏈接的方式,將每個DTDNN 層的輸出與前面的所有層連接起來作為下一層的輸入。
1. 2 Res2block 與ERes2block
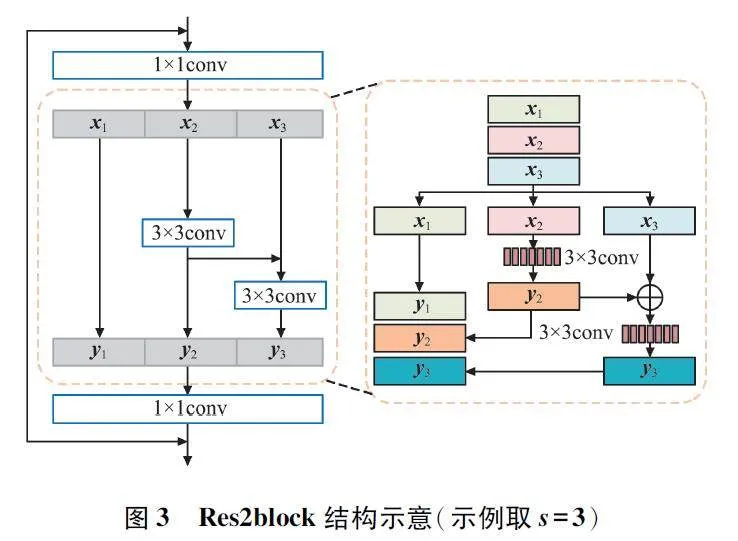
Res2block[11]通過增大感受野來提高模型的多尺度表示能力。在每個殘差塊內,使用分層類殘差連接提取通道維度上的多尺度特征,Res2block 結構示意如圖3 所示。
在圖3 中,將特征映射劃分為s 個特征映射子集,用xi 表示,其中i∈{1,2,…,s}。每個特征子集xi 具有相同的空間大小,但通道數為1 / s。除了x1之外,每個xi 都要經過一個卷積濾波器Ki(·)輸出yi 的表達式如式(1)所示:
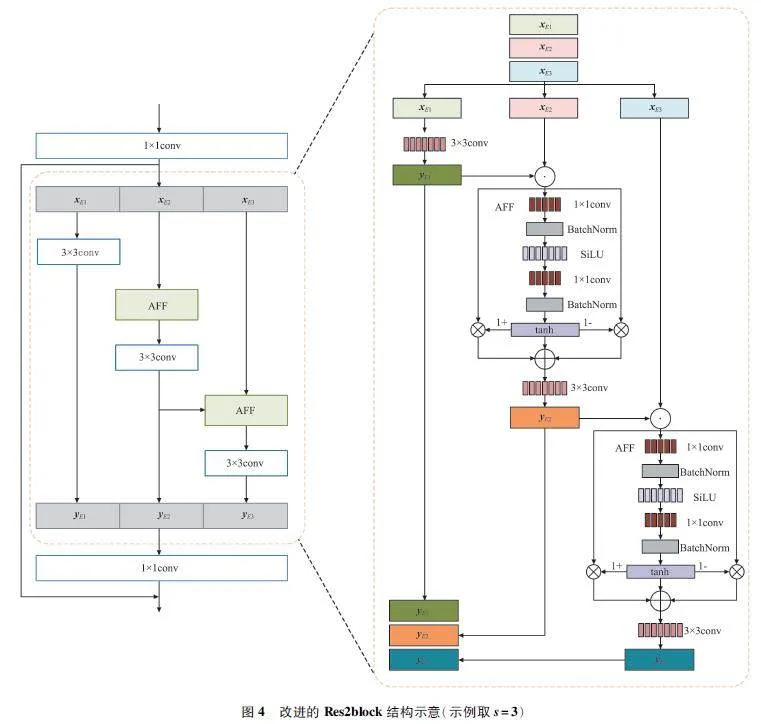
Res2block 的分割和拼接策略缺乏有效的局部信息交互。針對該問題,本文對其改進提出了ERes2block 模塊,其結構示意如圖4 所示。在該模塊中提出LFF 結構,該結構通過在相鄰特征映射之間的類殘差連接中引入了AFF 模塊,可對LFF 的進行增強,獲取更細粒度的特征,加強局部信息交互。并且LFF 允許ERes2block 塊捕獲輸入信號中的本地模式,從而提高動物聲紋驗證系統的準確性和魯棒性。
在圖4 中,特征映射用X∈RD×T×C 表示,其中D、T、C 分別表示頻率維度、時間維度和信道維度。將X 經過1 × 1 卷積后,根據通道維數分成不同的組xEi,i∈{1,2,…,s},其中,AFF 模塊將前一組的輸出特征與另一組輸入特征映射進行融合,從而加強信息之間的交互。
在LFF 模塊中的分層融合結構可以增加模型的接受域,并跨不同通道整合局部信息。ERes2block 的輸出如式(2)所示:
AFF 模塊將相鄰特征映射xEi 和yEi-1 作為輸入,其中計算局部關注權值U 如式(3)所示:
U=tanh(BN(V2 *SiLU(BN(V1*[xEi,yEi-1])))),(3)
式中:[·]為沿通道維度的連接,V1 和V2 分別為輸出通道大小為C/r和C 的點向卷積,r 為通道縮減比(本文設r = 4),BN(·)為批歸一化,SiLU(·)和tanh(·)分別為Sigmoid Linear Unit(SiLU)和tanh激活函數。根據特征的重要程度,該模塊進行動態加權和組合特征,提高模型從輸入信號中提取相關信息的能力。
1. 3 Front-end Residual Module
基于TDNN 的網絡沿著時間軸進行一維卷積,使用的卷積核覆蓋了輸入特征的完整頻率范圍。與二維卷積網絡相比,這種方法更難捕捉發生在某些局部頻率區域的發聲動物特征[12]。通常,需要大量的濾波器來模擬完整頻率區域中的復雜細節。在本文中,每個D-TDNN 塊中使用較窄的層來控制參數的大小,可能導致在一些局部區域內難以準確捕捉特定頻率模式。于是,需要增強D-TDNN 對時間頻率領域中的微小和合理變化的魯棒性,并補償實際發聲動物的發音變化。
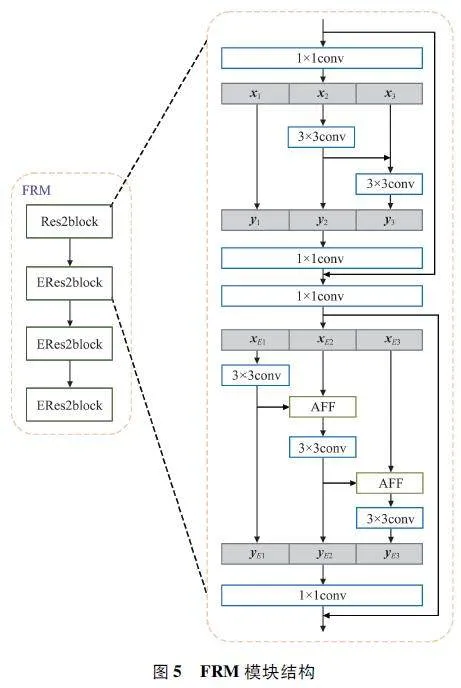
針對這個問題,本文提出在D-TDNN 網絡前連接一個二維FRM[12-13],在FRM 中加入4 個殘差塊,如圖5 所示。
在圖5 中,包含一個Res2block 塊和3 個ERes2block 塊,所有殘差塊的通道數設置為32。在最后3 個ERes2block 塊中,本文在頻率維度上使用步幅2,導致在頻率域中進行8 倍的下采樣。FRM的輸出特征圖隨后沿通道和頻率維度展平,并用作D-TDNN 主干的輸入。
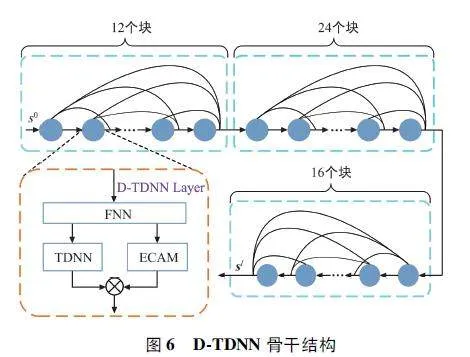
1. 4 D-TDNN 骨干結構
x-vector 模型中的TDNN 最先采用沿時間軸擴展的一維卷積結構作為主干,目前TDNN 在說話人驗證任務中被廣泛應用。基于TDNN 改進的D-TDNN[14] 是一種高效的說話人嵌入模型,與DenseNet[15]類似,它采用密集連接,即各層之間以前饋方式直接連接。本文采用D-TDNN 作為ERes-ECAM 網絡骨干,其與傳統的TDNN 相比,參數量更小,識別效果更好。
D-TDNN 的基本單元由前饋神經網絡(Feed-forward Neural Network,FNN)和TDNN 層組成。在兩個連續D-TDNN 層的輸入之間通過直接連接的方式連接。第l 層D-TDNN 表達式為:
Sl = Hl([s0,s1,…,sl-1]), (4)
式中:s0 為D-TDNN 模塊的輸入,Sl 為第l 層D-TDNN 的輸出, Hl 為第l 層D-TDNN 的非線性變換。
普通的D-TDNN 有兩個塊,每個塊分別包含6 和12 個D-TDNN 層。如圖6 所示,本文增加D-TDNN 網絡深度,在最后添加一個額外的塊,并將每個塊的層數擴展到12、24 和16。同時,為了降低網絡的復雜性,在每個塊中采用更窄的D-TDNN 層,即將原始增長率k 從64 降低到32。
1. 5 ECAM
擠壓-激勵(Squeeze-Excitation,SE)[16]將全局空間信息壓縮到通道描述符中,目的是模擬通道相互依賴性并重新校準濾波器響應。同時,利用自注意力機制來計算加權統計量,改進時序池化技術[17-19]。
CAM[20]通過專注于目標發聲動物并模糊不相關的噪聲,從而提高D-TDNN 的性能。但CAM 僅應用于每個D-TDNN 塊之后的過渡層,并且有限的CAM 模塊數量不足以提取有效的關鍵信息,針對該問題,本文在每個D-TDNN 層中插入了一個更輕的ECAM,以捕獲更多有用的目標發聲動物的聲紋特征。
本文將D-TDNN 塊中頭部FNN 輸出的隱藏特征表示為X。將X 輸入TDNN 層,提取局部時間特征F 如式(5)所示:
F= (X), (5)
式中:F (·)表示TDNN 層的變換,并只關注局部感受野。因此,比例子掩碼M 是基于提取的上下文嵌入來進行預測,并且期望包含有用的聲紋權值及噪聲特征,其表達如式(6)所示:
M*t =σ(W2 δ(W1 e+b1)+b2), (6)
式中:σ (·)和δ (·)分別表示Sigmoid 函數和ReLU 函數,M*t 表示M 的第t 幀,e 表示上下文嵌入,W1 和W2 表示聲紋權值,b1 和b2 表示噪聲特征。
語音信號具有典型的層次結構,并在不同字段之間具有動態變化的特征。因此在特定的語段中,目標發聲動物也存在一種特定的發聲方式,此時通過全局池化[20]的單個嵌入可能會導致精確的本地上下文信息丟失,從而導致次優屏蔽。
針對該問題,本文采用多粒度池化的方式替代傳統的單一全局池化,使網絡能夠在不同層次上捕獲更多的上下文信息,從而生成更準確的掩碼。使用全局平均池化來提取全局級別的上下文信息eg如式(7)所示:
式中:sk 為特征X 的第k 段的起始幀。
對不同層次的上下文嵌入(eg 和es)進行聚合,以預測上下文感知掩碼Mk*t。式(6)可改寫為:
Mk*t =σ(W2 δ(W1(eg +eks)+b1)+b2),sk≤t≤sk+1。(9)
使用預測的Mk*t 進行校準并生成改進后的時間特征F ~ ,如式(10)所示:
F~ =F(X)⊙Mk*t, (10)
式中:⊙表示逐元素的乘法。與傳統的CAM 相比,式(10)具有更簡單的形式和更少的可訓練參數。將這種高效的上下文感知掩碼插入到每個DTDNN層中,以增強整個網絡中基本層的表示能力。
2 實驗過程及結果分析
2. 1 聲音樣本集
為使得聲紋識別算法適應更多應用場景的需求,本文使用多種算法來驗證聲紋識別模型在動物數據集的應用效果。本文使用了自制的包含各種類動物叫聲數據集和自制的包含各種類豬只叫聲數據集。每個數據集詳細信息如下:
① Anim-Celeb:對于Anim-Celeb,使用Anim-Celeb1 和Anim-Celeb2 的開發集進行訓練,其中包括24 個動物種類,有鯨魚、青蛙、鳥、貓、狗、大象、鴨子、雞、牛、羊、豬等。數據集中的所有動物種類音頻材料來自于各個動物網站,總共792 條音頻數據。對訓練數據進行預處理,使用Goldwave 軟件將所收集到的所有音頻文件格式轉換為wav 格式,并以44. 1 kHz 的采樣頻率進行重采樣。使用Audacity軟件收聽音頻,截取各個動物發聲片段并進行相應的標記,同時將短音頻進行拼接,保證每段音頻時長不小于5 s。在Anim-Celeb 測試集中,每種動物都有多段發聲音頻。選擇對注冊的同種類發聲動物的所有語料嵌入進行平均,得到最終的發聲動物嵌入進行評估。
② Pig-Celeb:對于Pig-Celeb,使用Pig-Celeb1和Pig-Celeb2 的開發集進行訓練,其中包含長白豬、大約克夏豬、杜洛克豬、香豬、寧鄉花豬、馬身豬等10 個種類的豬只,共計1 738 頭豬只。豬只全部音頻取自于各種類豬只音頻數據集的集合。在訓練數據的數據預處理中,制作數據集方法與各種類動物的相同,同樣以44. 1 kHz 的采樣頻率進行重采樣,將短音頻進行拼接,保證每段音頻時長不小于5 s,在Pig-Celeb 測試集中,每個種類注冊的發聲豬只都有多段發聲音頻。選擇對注冊的同一種類發聲豬只的所有語料嵌入進行平均,得到最終的發聲豬只嵌入進行評估。
2. 2 實驗設計
本文仿真實驗在每10 ms 提取25 ms 窗口,在25 ms 長窗口中提取80 維的Fbank 特征作為輸入。采用速度擾動增強,通過從[0. 9,1. 0,1. 1]中隨機抽樣一個比率。處理后的音頻被視為來自一個新的發聲動物[21]。此外,在訓練過程中采用了兩種常見的數據增強技術,分別是使用RIR 數據集模擬混響效果[22],同時,為了評估ECAM 的有效性,使用MUSAN 數據集添加噪聲。
實驗均采用Arc-Softmax 損失函數[23]。Arc-Softmax 損失的邊界余量和縮放因子分別設置為0. 2和32。在訓練過程中,使用隨機梯度下降優化器,結合余弦退火調度器和線性熱身調度器,學習率在10-4 和0. 1 之間進行變化。動量設定為0. 9,權重衰減設定為10-4。每個音頻樣本都會被隨機裁剪為3 s 時長的片段,以構建訓練小批次數據。
本文使用余弦相似度得分進行評估,在后端沒有進行得分歸一化。本文采用等錯誤率(EqualError Rate,EER)和準確率作為評價指標。
EER 是錯誤拒絕率(False Acceptance Rate,FAR)與錯誤接收率(False Rejection Rate,FRR)相等時的錯誤率。
FAR:被錯誤檢索的正樣本數與所有標記的負樣本數之比,如式(11)所示。
FRR:被錯誤檢索的負樣本數與所有標記的正樣本數之比,如式(12)所示。
FAR= FP/FP+TN, (11)
FRR= FN/TP+FN, (12)
式中:TP 表示識別正確的正樣本數,TN 表示識別正確的負樣本數,FP 表示識別錯誤的正樣本數,FN 表示識別錯誤的負樣本數。
EER:FAR 與FRR 相等時的錯誤率,如式(13)所示。
EER=FAR=FRR, (13)
準確率作為最常用的性能指標之一,可以從整體上衡量一個模型的性能,表示被正確檢索的正負樣本數和總樣本數之比。當使用EER 評估時,也等于1減等差率,如式(14)所示:
Accuracy=1-EER。(14)
2. 3 實驗結果分析
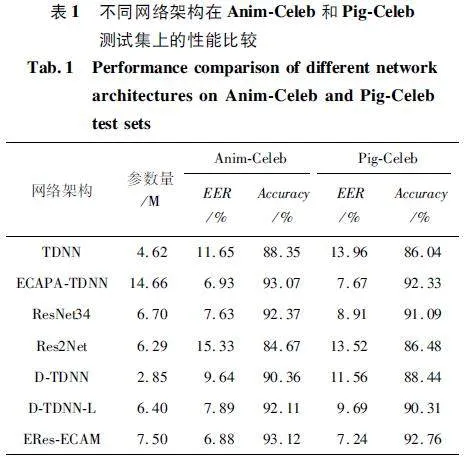
在本組仿真實驗中,對本文所提模型進行驗證,同時與TDNN[5]、ECAPA-TDNN[6]、ResNet34、Res2Net[19]、D-TDNN[24]、D-TDNN-L 模型進行性能比較,其中ResNet34 模型在每個塊中包含4 個不同通道大小的剩余塊[64,128,256,512],ECAPA-TDNN 模型所構建的通道數為1 024,實驗結果如表1 所示。
由表1 可知,通過ECAPA-TDNN 模型計算得到的EER 相較于TDNN 和Res2Net 有所提升,但其模型所需參數有所變大。而D-TDNN 采用密集連接的方式,相較于TDNN 可以在模型參數更少的情況下提升性能。本文對D-TDNN 進行深度及濾波器參數改進得到的D-TDNN-L 模型雖然性能優于D-TDNN,但與ECAPA-TDNN 和ResNet34 相比仍具有性能差距。當本文將D-TDNN-L 作為骨干網絡與ECAM 和FRM 結合時,ERes-ECAM 在參數量及性能均優于本文所提其他模型。
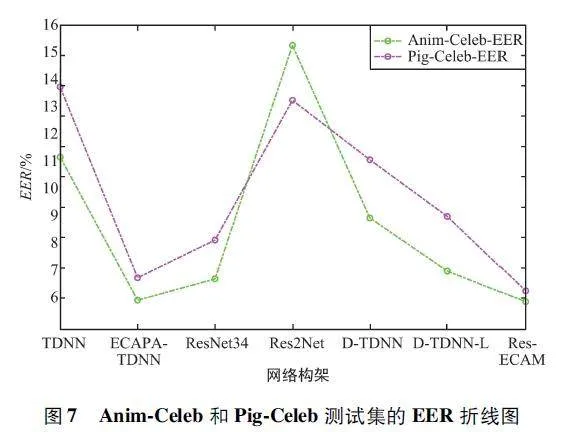
為便于直觀分析數據,對Anim-Celeb 和Pig-Celeb 測試集中的EER 實驗結果進行數據可視化,如圖7 所示。
由圖7 可以看出,ERes-ECAM 對比其他基線模型有最低的EER。特別是Pig-Celeb 測試集中,ERes-ECAM 相比ECAPA-TDNN,模型參數量減少49% 且EER 降低了6% 。在Anim-Celeb 測試集上,ERes-ECAM 相對比其他模型具有最低的EER。
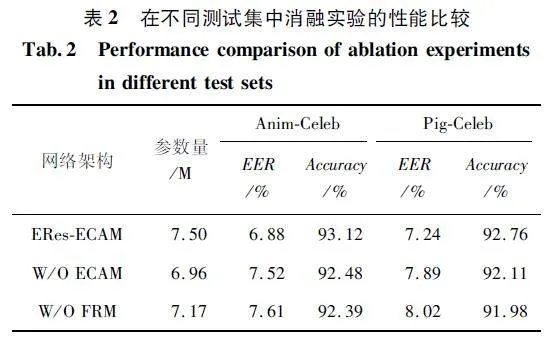
為進一步驗證不同模塊對整體模型的性能影響,分別對ECAM 及FRM 模塊進行消融實驗,實驗結果如表2 所示。
由表2 可知,采用多粒度池化的ECAM 在Anim-Celeb 和Pig-Celeb 測試集上的EER 分別降低了9%和8% ,在Anim-Celeb 和Pig-Celeb 測試集上提高了0. 64% 和0. 65% 的識別準確率。結果進一步論證在不同層次上聚合上下文向量來執行注意力掩蔽的可行性。當去除FRM 時,導致兩個測試集中的EER均提升,并且識別準確率明顯降低。實驗結果表明,本文所采用的二維卷積和基于TDNN 的混合網絡可以更好地提取發聲動物的聲紋特征。
2. 4 多粒度池化與其他池化方法的性能對比
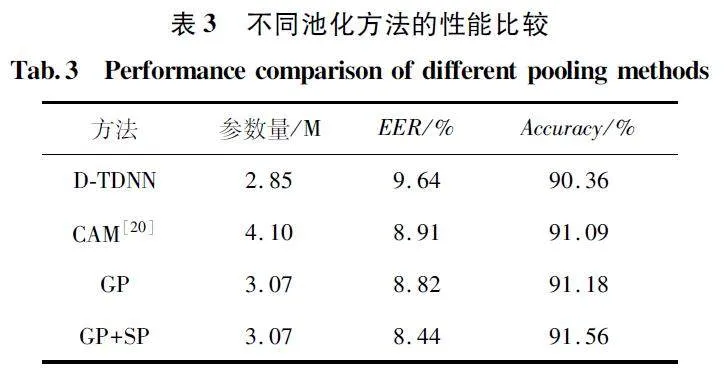
進一步對改進的多粒度池化CAM 性能進行實驗仿真,本組仿真在Anim-Celeb 測試集中進行,并與D-TDNN、CAM 進行對比。實驗結果如表3 所示。
表3 在Anim-Celeb 測試集上重新實現了文獻[20]中提出的CAM,并發現它能將EER 降低8% ,但參數量增加了44% 。本文將ECAM 應用于D-TDNN,僅使用全局平均池化(Global average Poo-ling,GP),這將使EER 得到類似的改善,但參數僅增加了8% ,顯示出更好的參數效率。使用分段平均池化(Segment average Pooling,SP),并將其與GP融合,在不引入額外參數的情況下觀察性能提升。這些結果表明,在執行更準確的掩蔽時,局部的上下文信息對降低EER 起到重要作用。
2. 5 LFF 模塊對模型的影響
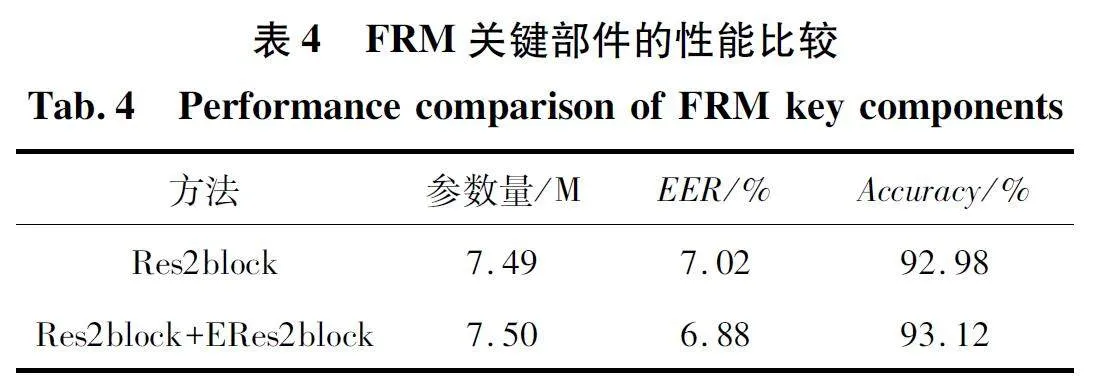
進一步評估改進的殘差模塊Res2block 的有效性。附加實驗結果如表4 所示,針對Anim-Celeb 測試集進行實驗。將FRM 部分只應用Res2block 塊的ERes-ECAM 作為基線模型。在Anim-Celeb 測試集上重新實現了基線模型和所提出的模型架構,將LFF 的ERes2block 塊應用于FRM,并將其與Res2block 塊融合,在不引入額外參數的情況下觀察性能提升。
表4 的實驗結果顯示,Res2block 塊與Res2block+ERes2block 塊參數相差無幾,但Res2block +ERes2block 塊在EER 降低了2% ,識別準確率也有提高。這些結果表明,在提取聲紋特征時,FRM 使用LFF 結構,能夠獲取更細粒度的特征,加強局部信息交互,提高聲紋驗證系統的準確性和魯棒性。
2. 6 聲紋識別在動物種類識別中的應用
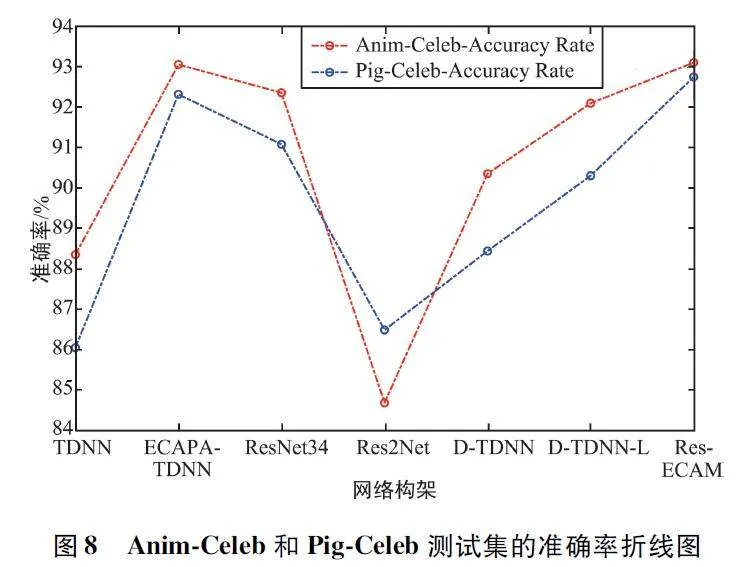
使用動物的聲紋識別可以用來識別動物身份。這對動物保護和畜牧業發展具有重要意義,可以幫助監測動物數量、研究遷徙模式以及跟蹤動物的種群變化,同時,為大型養殖場的運用提供新方法。對比ECAPA-TDNN 模型,ERes-ECAM 模型大大減少了模型參數,在動物種類和豬只種類的識別準確率方面也有顯著的提升。Anim-Celeb 和Pig-Celeb 測試集的準確率折線圖如圖8 所示。
由圖8 可以看出,在Anim-Celeb 和Pig-Celeb 測試集上,相比ECAPA-TDNN 及Res2Net,除了在EER 上的提高外,動物種類識別分別提升了0. 05%和8. 45% 的準確率,豬只種類識別提升了0. 43% 和6. 28% 的準確率。對比其他基線模型,本文提出的模型對動物種類和豬只種類的識別準確率最高,其識別準確率分別達到了93. 12% 和92. 76% 。
2. 7 模型復雜性分析
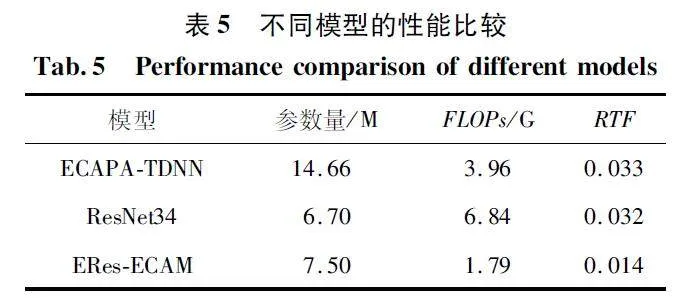
本文比較了ECAPA-TDNN、ResNet34 和ERes-ECAM 模型的復雜性,包括參數量、浮點運算(Floating Point Operations,FLOPs)和實時率(Real-Time Factor,RTF),如表5 所示。
由表5 可以看出,ERes-ECAM 與ResNet34 相比,ERes-ECAM 的參數量有所增大,但FLOPs 有所降低。同時,ERes-ECAM 的參數量和FLOPs 只有ECAPA-TDNN 的一半,而ERes-ECAM 實現的推理速度是ResNet34 和ECAPA-TDNN 的兩倍以上。
3 結束語
本文提出了一種新穎的聲紋識別模型———ERes-ECAM,用于對發聲動物進行動物種類分類。ERes-ECAM 采用LFF 和ECAM。LFF 提取了保留目標發聲動物特征,加強了局部信息交互。ECAM 旨在關注目標發聲動物并提高提取特征的質量,其中,多粒度池化融合了不同層次的上下文信息以產生準確的注意力權重。本文在Anim-Celeb 數據集和Pig-Celeb數據集上進行了全面的實驗,通過對比6 種不同實驗模型,實驗結果表明本文所提出的模型在兩個數據集下EER 分別為6. 88%和7. 24%,相較于其他模型,獲得的EER 值最小。同時,對動物種類和豬只種類識別準確率分別達到了93. 12% 和92. 76%。此外,與ECAPA-TDNN 和ResNet34 模型相比,ERes-ECAM 具有更低的時間復雜度和更快的推理速度。
參考文獻
[1] VIGNIERI S. Vanishing Fauna [J]. Science,2014,345(6195):392-395.
[2] HANNAY D E,DELARUE J,MOUY X,et al. MarineMammal Acoustic Detections in the Northeastern ChukchiSea,September 2007 - July 2011 [J]. Continental ShelfResearch,2013,67:127-146.
[3] MIELKE A,ZUBERBHLER K. A Method for AutomatedIndividual,Species and Call Type Recognition in Freeranging Animals [J]. Animal Behaviour,2013,86 (2):475-482.
[4] MA K. Biodiversity Monitoring Relies on the Integration ofHuman Observation and Automatic Collection of Data withAdvanced Equipment and Facilities[J]. Biodiversity Science,2016,24(11):1201-1202.
[5] SNYDER D,GARCIAROMERO D,SELL G,et al. Xvectors:Robust DNN Embeddings for Speaker Recognition[C]∥2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). Calgary:IEEE,2018:5329-5333.
[6] DESPLANQUES B,THIENPONDT J,DEMUYNCK K.ECAPATDNN:Emphasized Channel Attention,Propagation and Aggregation in TDNN Based Speaker Verification[C]∥2020 Annual Conference of the International SpeechCommunication Association (INTERSPEECH). Shanghai:ISCA,2020:3830-3834.
[7] CHENG J K,XIE B G,LIN C T,et al. A ComparativeStudy in Birds:Calltypeindependent Species and Individual Recognition Using Four Machinelearning Methodsand Two Acoustic Features [J]. Bioacoustics,2012,21(2):157-171.
[8] TOWSEY M,WIMMER J,WILLIAMSON I,et al. The Useof Acoustic Indices to Determine Avian Species Richnessin Audiorecordings of the Environment [J]. EcologicalInformatics,2013,21(3):110-119.
[9] LARRANAGA P,POZA M,YURRAMENDI Y,et al.Structure Learning of Bayesian Networks by Genetic Algorithms:A Performance Analysis of Control Parameters[J]. IEEE Transactions on Pattern Analysis and MachineIntelligence,1996,18(9):912-926.
[10]SASMAZ E,TEK F B. Animal Sound Classification Usinga Convolutional Neural Network[C]∥ 2018 3rd International Conference on Computer Science and Engineering(UBMK). Sarajevo:IEEE,2018:625-629.
[11]GAO S,CHENG M,ZHAO K,et al. Res2Net:A NewMultiscale Backbone Architecture[J]. IEEE Transactionson Pattern Analysis Machine Intelligence,2021,43(2):652-662.
[12]THIENPONDT J,DESPLANQUES B,DEMUYNCK K.Integrating Frequency Translational Invariance in TDNNsand Frequency Positional Information in 2D ResNets to Enhance Speaker Verification[C]∥2021 Annual Conferenceof the International Speech Communication Association(INTERSPEECH). Brno:ISCA,2021:2302-2306.
[13]LIU T,DAS R K,LEE K A,et al. MFA:TDNN withMultiscale Frequencychannel Attention for Textindependent Speaker Verification with Short Utterance[C]∥2022 IEEE International Conference on Acoustics,Speechand Signal Processing (ICASSP ). Singapore:IEEE,2022:7517-7521.
[14]LIU B,CHEN Z Y,WANG S,et al. DFResNet:BoostingSpeaker Verification Performance with Depthfirst Design[C ]∥ 2022 Annual Conference of the InternationalSpeech Communication Association (INTERSPEECH).Incheon:ISCA,2022:296-300.
[15]HUANG G,LIU Z,VAN DER MAATEN L,et al. DenselyConnected Convolutional Networks[C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Honolulu:IEEE,2017:2261-2269.
[16]HU J,SHEN L,SUN G. SqueezeandExcitation Networks[C]∥ 2018 IEEE Conference on Computer Vision andPattern Recognition (CVPR). Salt Lake City:IEEE,2018:7132-7141.
[17]OKABE K,KOSHINAKA T,SHINODA K. Attentive Statistics Pooling for Deep Speaker Embedding[C]∥2018Annual Conference of the International Speech Communication Association (INTERSPEECH). Hyderabad:ISCA,2018:2252-2256.
[18]ZHU Y K,KO T,SNYDER D,et al. Selfattentive SpeakerEmbeddings for Textindependent Speaker Verification[C ]∥ 2018 Annual Conference of the InternationalSpeech Communication Association (INTERSPEECH).Hyderabad:ISCA,2018:3573-3577.
[19]INDIA M,SAFARI P,HERNANDO J. Self Multihead Attention for Speaker Recognition[C]∥2019 Annual Conferenceof the International Speech Communication Association(INTERSPEECH). Graz:ISCA,2019:4305-4309.
[20]YU Y Q,ZHENG S Q,SUO H B,et al. Cam:Contextaware Masking for Robust Speaker Verification [C]∥2021 IEEE International Conference on Acoustics,Speechand Signal Processing (ICASSP). Toronto:IEEE,2021:6703-6707.
[21]CHEN Z Y,HAN B,XIANG X,et al. Build a SRE Challenge System:Lessons from VoxSRC 2022 and CNSRC2022[C]∥2022 Annual Conference of the InternationalSpeech Communication Association (INTERSPEECH).Dublin:ISCA,2023:3202-3206.
[22]KO T,PEDDINTI V,POVEY D,et al. A Study on DataAugmentation of Reverberant Speech for Robust SpeechRecognition[C]∥2017 IEEE International Conferenceon Acoustics,Speech and Signal Processing (ICASSP).New Orleans:IEEE,2017:5220-5224.
[23]DENG J K,GUO J,YANG J,et al. Arcface:AdditiveAngular Margin Loss for Deep Face Recognition [C]∥2019 IEEE Conference on Computer Vision and PatternRecognition (CVPR). Long Beach:IEEE,2019:4690-4699.
[24]YU Y Q,LI W J. Densely Connected Time Delay NeuralNetwork for Speaker Verification[C]∥2020 Annual Conference of the International Speech Communication Association (INTERSPEECH). Shanghai:ISCA,2020:921-925.
作者簡介:
侯衛民 男,(1972—),博士,教授。主要研究方向:人工智能、圖形處理和應用、陣列信號處理和無線通信。
(*通信作者)孫藝菲 女,(1998—),碩士研究生。主要研究方向:人工智能、聲紋識別。
劉峻滔 男,(1998—),碩士研究生。主要研究方向:遙感圖像處理、數字圖像處理和深度學習。
基金項目:河北省省級科技計劃項目(20355901D,21355901D)
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
