基于最優變分模態分解的渭河流域多步徑流預報
2024-12-31 00:00:00邱緒迪王坤陳飛相里宇錫王斌
人民長江 2024年8期
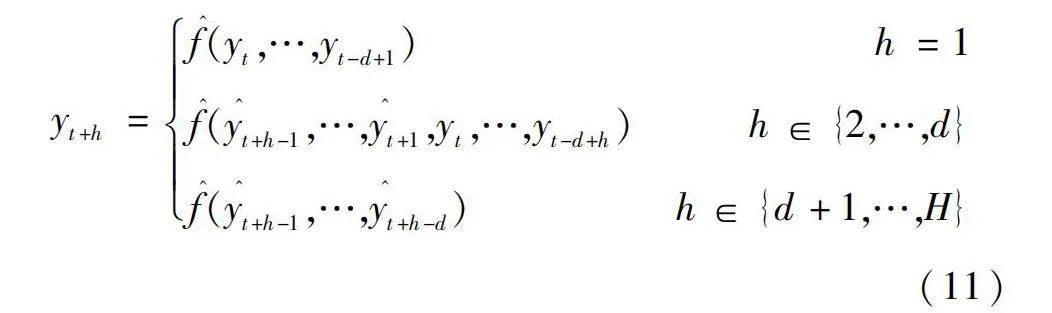

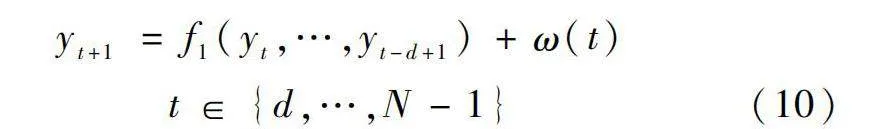
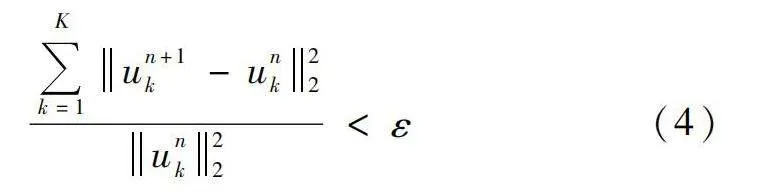
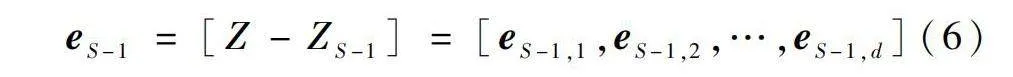
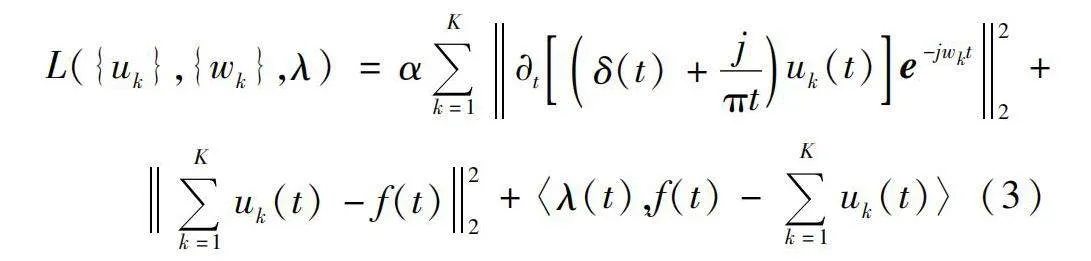
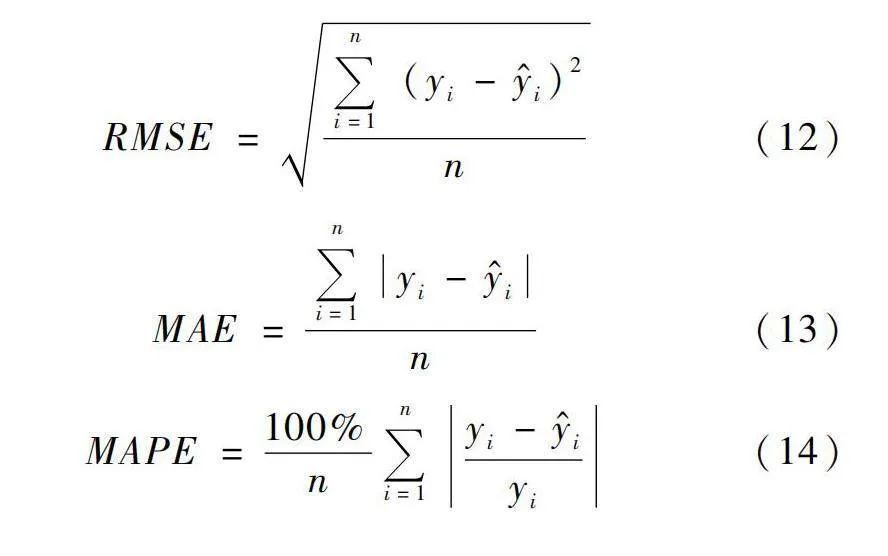

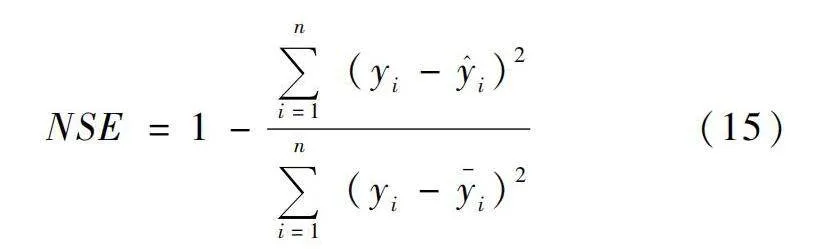
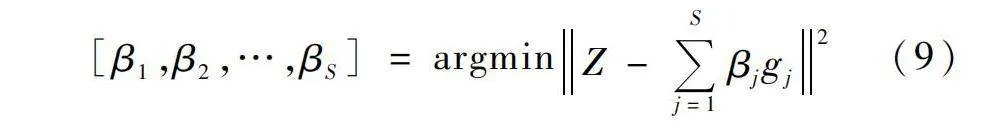
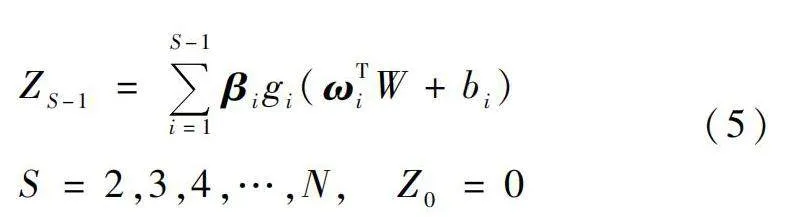

摘要:針對渭河流域月徑流序列的非平穩性日益加劇而難以對其進行精準預測的問題,提出了一種基于最優變分模態分解(OVMD)、隨機配置網絡(SCN)和遞歸多步預測策略的月徑流序列多步預測模型。首先,利用OVMD將徑流數據投影到不同頻率的子序列中;然后通過SCN對每個分解部分進行預測,疊加得到單步預測結果;最后通過遞歸多步預測方法對未來較長時間的徑流數據進行預測,得到多步預測結果。選取渭河流域華縣水文站和咸陽水文站1970~2019年的實測月徑流時間序列進行實例分析,并與其他常用模型進行對比,選取均方根誤差RMSE、平均絕對誤差MAE、平均絕對百分比誤差MAPE以及納什效率系數NSE對預測結果進行評價。研究結果表明:在華縣水文站和咸陽水文站的單步預測試驗中,OVMD-SCN模型的NSE分別達98.15%和98.52%,顯著高于其他流行模型;在兩個水文站的多步預測試驗中,OVMD-SCN的各項評價指標均優于其他流行模型,表明所提方法可以精準預測5個月后的徑流量。研究成果可為渭河流域的月徑流精準預測提供技術支持。
關 鍵 詞:徑流預報;最優變分模態分解;隨機配置網絡;遞歸多步預測;渭河流域
中圖法分類號:P338
文獻標志碼:ADOI:10.16232/j.cnki.1001-4179.2024.08.011
0 引 言
徑流預報是在掌握水文客觀規律的基礎上對未來一段時間的流量、水位等水文狀態做出定量或定性預測的科學技術。干旱和洪水等極端水文事件每年都造成巨大損失[1],且可能由于氣候變化而變得更加頻繁[2],難以對其進行精準預測。渭河是黃河的一級支流,對渭河流域進行準確的月徑流預報可以幫助決策者更好地采取科學措施進行防洪調度、用水管理和水資源規劃[3]。但由于徑流預報周期較長,影響因素較多,需要不斷提高其徑流預報精度。
已有研究表明,通過選擇合適的信號處理方法對數據進行預處理,可以有效提取徑流序列中隱含的有用信息,從而提高預報精度[4]。信號分解方法能夠深度挖掘徑流時間序列中的周期性和趨勢性信息,使模型能夠更好地識別和學習輸入數據的特征規律[5]。常用的信號處理方法包括小波分析[6]、傅里葉變換[7]、經驗模態分解[8]、集合經驗模態分解[9]和變分模態分解(VMD)[10]。但小波分析需要預先設置基函數[11],經驗模態分解易出現模態混疊等問題。VMD具有數學理論支撐,對于噪聲具有更好的魯棒性,可通過自行設置和調節模態分解的個數來有效避免模態混疊的問題[12],近年來已被應用于故障分析、水文預報等領域,且表現出良好的信號分解性能。包苑村等將VMD與卷積-長短期記憶神經網絡進行組合,對渭河流域的張家山站和魏家堡站進行月徑流預測,效果良好[13]。孫國梁等將VMD和基于麻雀搜索優化的長短期記憶神經網絡模型應用于福建省池潭水庫的月徑流預報中[14],也得到了較好的預測效果。可見將VMD用于徑流數據的分解可以有效消除徑流序列中的噪聲,故本研究利用最優VMD實現對渭河流域原始徑流序列的分解。
前饋神經網絡(feedforward neural network,FNN)由于結構簡單的性能及其可以任意精度對非線性映射的通用逼近能力而被廣泛關注[15]。典型的前饋神經網絡包括早期提出的感知機模型,基于梯度傳播的BP神經網絡以及以徑向基函數為變換函數的徑向基函數網絡。2017年,Wang等提出了隨機配置網絡(SCN)理論[16],這是一種帶有監督機制的前饋神經網絡。具有人為參數少、收斂速度快、泛化性能好、測試精度高等優點,極大改善了前饋神經網絡的不足。已有研究表明,SCN在風速預測[17]、故障診斷[18]等領域均取得了較好的預測結果。
一般情況下,時間序列的多步預測主要有5種策略,分別為直接多步預測、遞歸多步預測、直接遞歸混合預測、多輸出預測和 seq2seq 預測[19]。其中遞歸式多步預測法通過單步預測模型的迭代來實現對未來多個時間點的預測,即通過在每個時間步引入先前步驟的預測值作為輸入,實現對隨后多個時間步的預測,更符合數據的實際生成形式,且遞歸多步預測只需構建一個模型即可實現,方法十分清晰簡便。故本文采用遞歸式多步預測法來實現未來較長時間的徑流預測。
綜上,針對現有研究中在渭河流域不能精準地進行未來較長時間的徑流預報問題,本文通過構建多步徑流預測模型,來幫助決策者根據旱澇情況及時制定方案,采取防洪或水資源管理措施,更好地保障渭河流域及周邊地區人民的生命財產安全。
1 模型原理
1.1 最優變分模態分解
VMD是一種在時域頻域上同時非遞歸、自適應、準正交的信號分解方法,通過預設參數,將時間序列數據分解為K個固有模態分量(IMF)。最優變分模態分解(OVMD)通過中心頻率的方法確定分解層數K[20],數據從時域轉化到頻域進行分解,很好地捕捉了時間序列的非線性特征,避免了變量信息重疊,其分解過程具有較好的魯棒性,且由于K值可以預先設定并自行調整,可以通過設置合理的收斂次數,來有效降低模型計算的復雜度。OVMD分解的主要過程如下:
(1)假定待分解的時序信號為f(t),將其分解為K個IMF函數,每個IMF表示為uk(t),其中k=1,2,…,K,并將固有模態函數估計帶寬之和最小作為分解的約束條件:
式中:x(t)為原始徑流序列,億m3/s;K為經OVMD分解得到的IMF個數;wk為uk(t)對應的中心頻率;{uk}={u1(t),u2(t),…,uK(t)}是模態函數的集合;{wk}={w1,w2,…,wK}是與模態函數{uk}相對應中心頻率的集合;?t表示函數對于時間t的偏導數;δ(t)為單位脈沖函數;e-jwkt是復平面上中心頻率的向量表示。
第8期
邱緒迪,等:基于最優變分模態分解的渭河流域多步徑流預報
人 民 長 江2024年 (2)對上述變分模型求最優解,使用二次懲罰因子α和拉格朗日乘子λ構造增廣拉格朗日表達式,將約束變分模型轉化為無約束變分模型,表示如下:
式中:α可用于保證信號的重構精度對帶寬加以限制。使用交替方向乘子法,交替更新{uk}、{wk}和λ,對上述模型進行求解。算法的收斂條件設置為
式中:ε為判別精度,用來控制相對誤差,若殘差小于判別精度,則停止更新,否則繼續更新{uk}、{wk}和λ,直到滿足算法收斂條件。
1.2 隨機配置網絡
隨機配置網絡(SCN)是一種具有監督機制的隨機權重神經網絡,它從一個小規模網絡開始,在固定頻率分布下逐步增加隱含層節點,以最大化殘差為目標網絡搜索輸入權值與偏置,直到網絡達到可接受的誤差,與傳統前饋神經網絡不同。這種監督機制保證了給定非線性映射所產生SCN模型的通用逼近特性。SCN的詳細過程如下:
(1)給定一個訓練數據集{W,P},其中W為輸入數據;P為輸出數據。假設SCN模型具有S-1個隱含節點,那SCN的輸入ZS-1為
式中:βi=[βi,1,βi,2,…,βi,d]T為第i個隱含節點的輸出權重,d為輸出維度;ωi和bi分別為第i個隱含節點的輸入權重和偏置;gi(·)為SCN模型的激活函數。同時,根據式(6)可計算當前網絡的誤差eS-1:
eS-1=[Z-ZS-1]=[eS-1,1,eS-1,2,…,eS-1,d](6)
(2)SCN引入監督機制為隱含節點S的分配函數,具體監督機制如下:
式中:〈eS-1,j,gS〉為向量eS-1,j與gS的內積;gS為第S個隱含節點的輸出;n為樣本數;對于任意g∈Γ(Γ表示張成的空間)都有,0≤‖g‖≤bg,bg∈R+,limS→∞ μS=0且0lt;μS≤1-r,r為正則化參數,范圍在0~1之間。根據監督機制確定隱含節點最佳參數ωS和bS。
(3)利用最小二乘法計算出隱含層輸出權重:
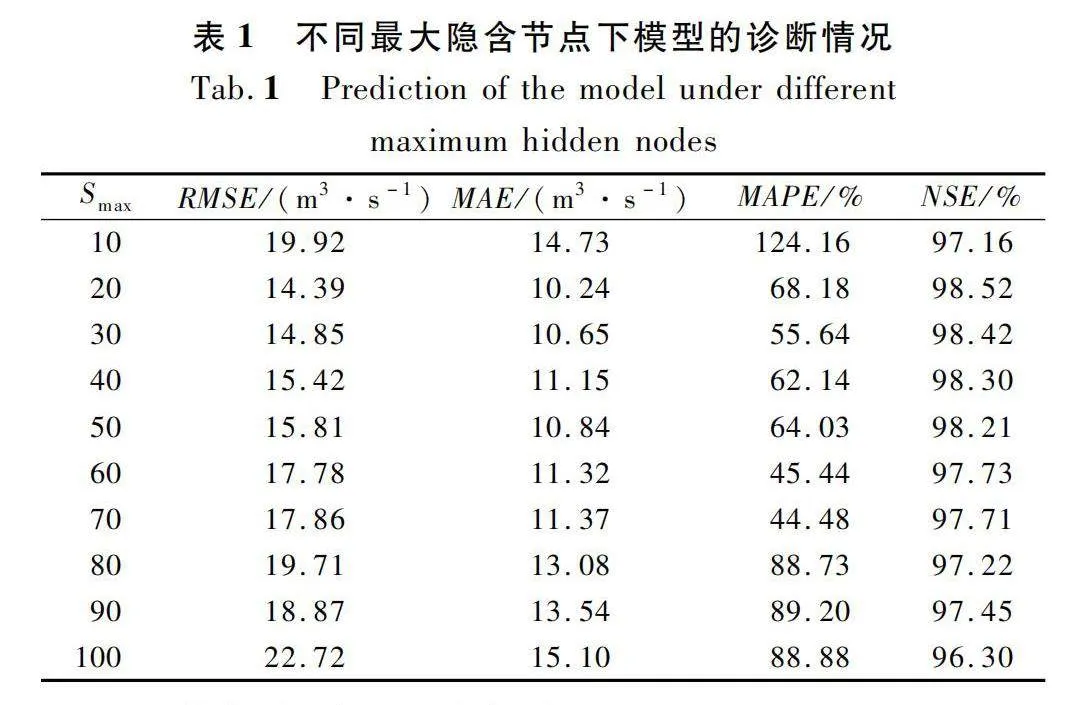
通過不斷增加隱藏層節點,重復式(5)~(9),直到模型誤差‖eS‖達到期望的誤差容限χ或隱含節點數達到最大隱含節點數Smax,最終輸出最優模型。本文分析了Smax≤100的情況下OVMD-SCN模型的預測效果,咸陽水文站的預測結果對比如表1所列。從表1中可以看出發現:當Smax=20時,模型的納什效率系數最接近1,即取得最佳的預測效果,故文中將Smax設置為20(華縣水文站方法同上)。
1.3 遞歸多步預測方法
遞歸多步預測方法僅僅需要建立1個模型就可以預測未來n步的值。該模型輸入的原始數據為真實值,在進行了單步預測的基礎上,每預測完一個值,將其作為下一步預測時的歷史數據輸入,來迭代預測下一個值。
首先建立一個單步預測模型來進行第1步預測:
yt+1=f1(yt,…,yt-d+1)+ω(t)t∈{d,…,N-1}(10)
式中:yt+1為在t+1時刻的單步預測值;f1為1步預測模型;d為輸入數據的滯后階數,也是作為輸入特征的歷史數據序列長度;ω(t)為噪聲序列,本文取ω(t)=0,N為時間序列長度。
然后將第1步的預測值加入輸入變量輸入到同一個預測模型中,來進行第2步的預測,依此類推,直到進行H步的預測。假設1步預測的模型用f^表示,則多步預測的規則如式(11)所示:
遞歸多步預測法利用了時間序列的相關性來提高預測的準確度,但隨著預測時間范圍的增加,超前預測步數增多,預測值不斷代替真實值,式(11)中第3行表示的是預測步數超過滯后階數的情況,此時輸入的數據均為之前的預測值,會造成較大的誤差積累,使模型性能迅速下降,因此,需要進行預測的時間序列不能過長。
1.4 預報精度評價
為衡量預測模型的精準度和可靠性,本文選取均方根誤差RMSE、平均絕對誤差MAE、平均絕對百分比誤差MAPE以及納什效率系數NSE作為徑流預報的精度評價指標。其中RMSE和MAE表示預測值偏離實際值的絕對大小,MAPE表示預測值偏離實際值的相對大小,這3個值越小,表明該預測模型精確度越高。納什效率系數NSE表示模擬值與實測值間的擬合程度,NSE值越接近于1,表明擬合度越高,模型的預測性能越好。計算公式如下:
式中:yi為徑流序列的實測值;?i為實測值的平均值;?i為預測值。
2 數據來源與預處理
2.1 數據來源
渭河是黃河的最大支流,全長818 km,流域總面積134 766 km2,多年平均徑流量75.7億m3,徑流地區分布不均,自南向北減小。且渭河徑流的季節變化明顯,干流以秋季流量最大,約占年徑流的38%~40%。
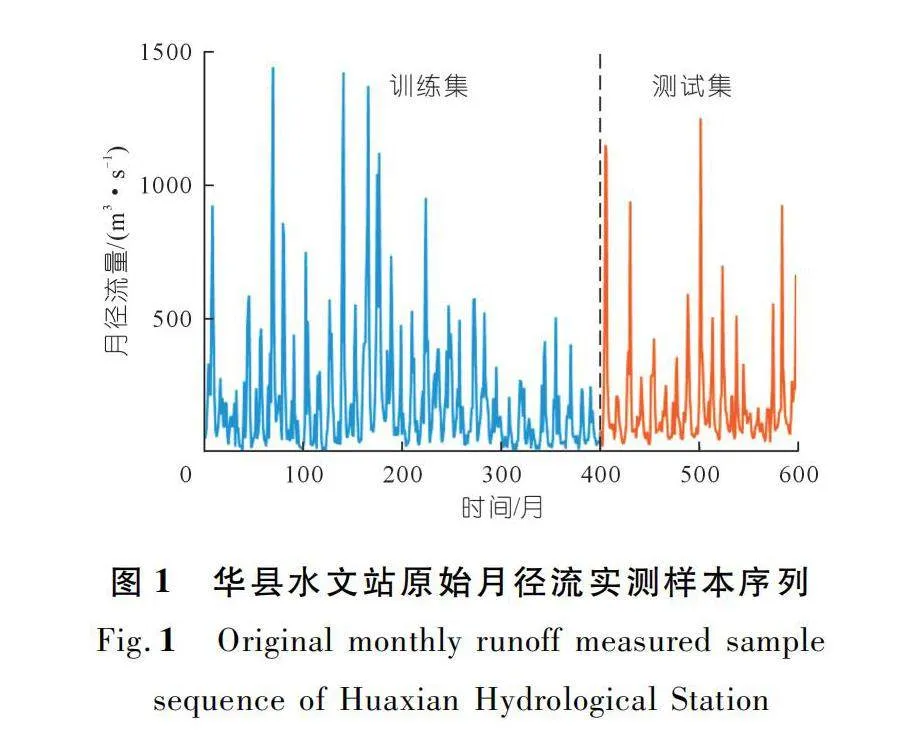
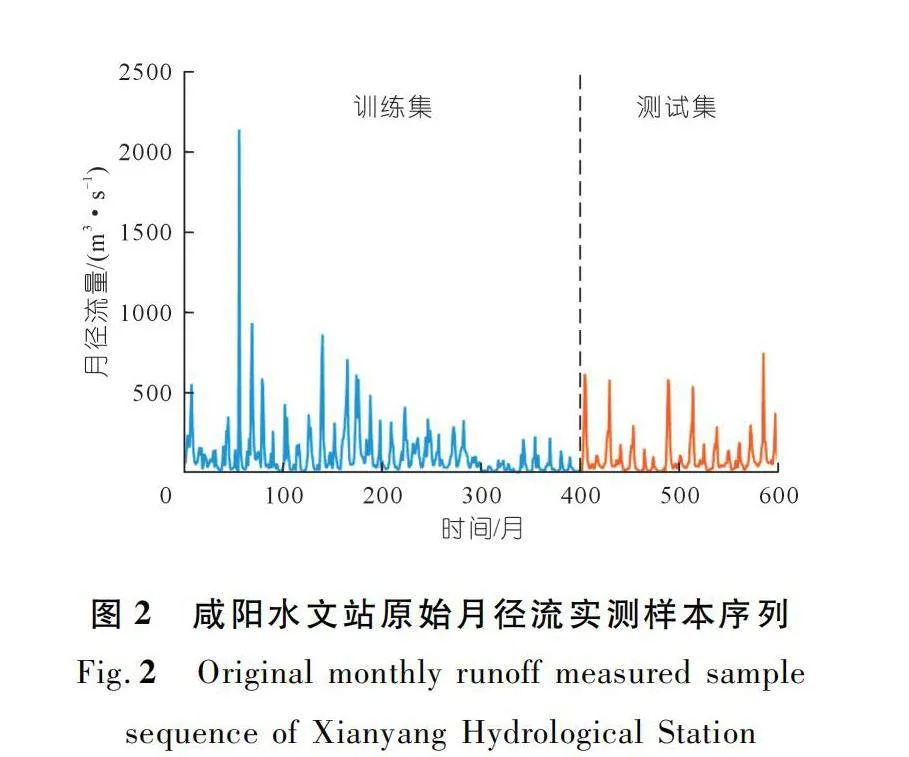
華縣水文站是國家重要水文站,承擔著渭河水文測報任務。華縣水文站位于陜西省華縣下廟鄉茍家堡村,距河口73 km。該段洪水多發于每年的7~10月份,洪水漲落急劇。咸陽水文站是渭河中游控制站,也是國家重要水文站,位于咸陽市秦都區渭河南岸,距河口211.1 km,距上游魏家堡站112 km,距下游臨潼水文站53.7 km。分別收集華縣、咸陽水文站1970~2019年實測月徑流數據,資料顯示人類活動和極端水文事件的發生使得徑流序列的復雜性和非平穩性更加突出。取所采集的前400個月的徑流數據作為訓練集,用于訓練模型;取后200個月的徑流數據作為測試集,用于測試模型仿真結果(圖1~2)。
2.2 月徑流時序數據分解
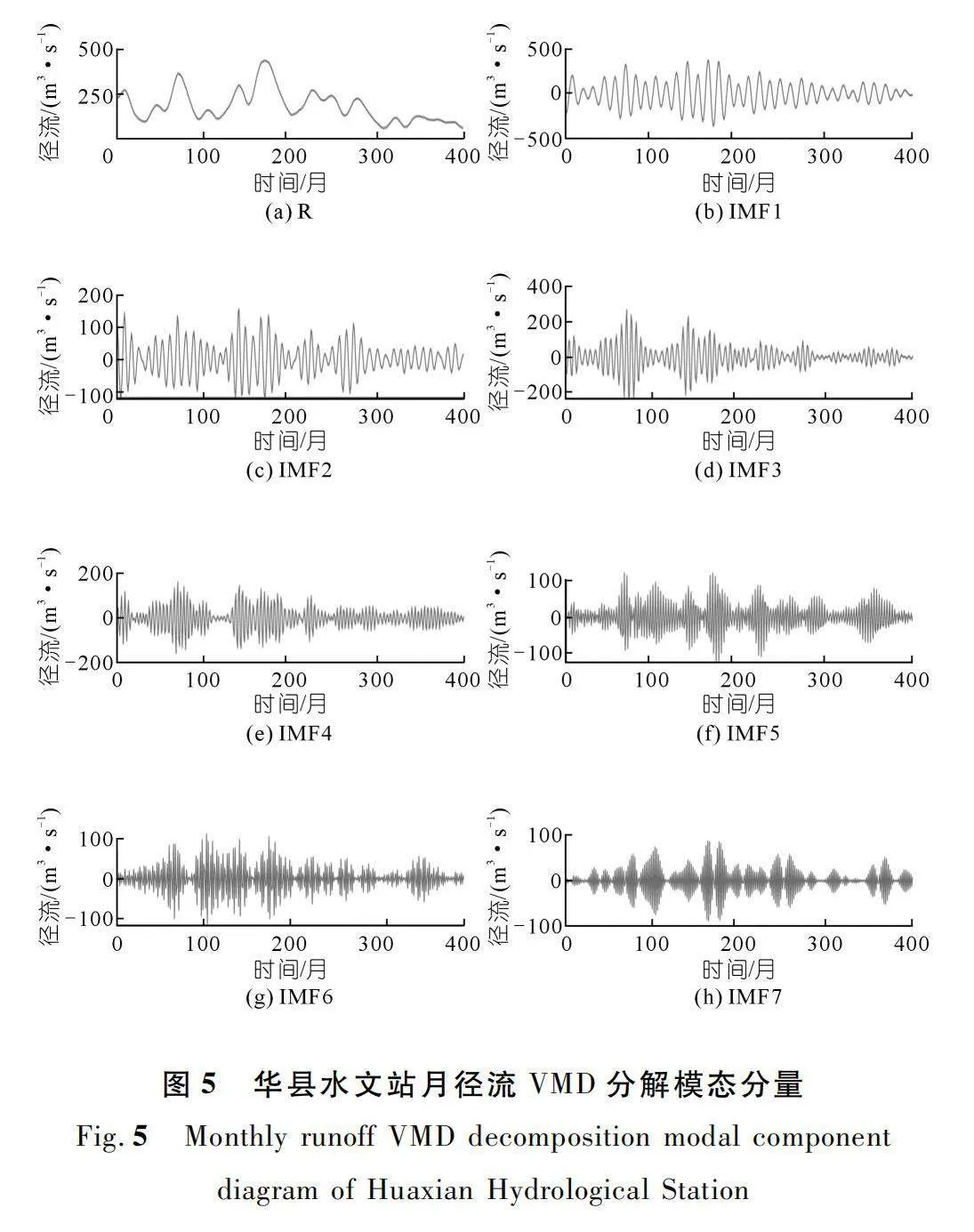
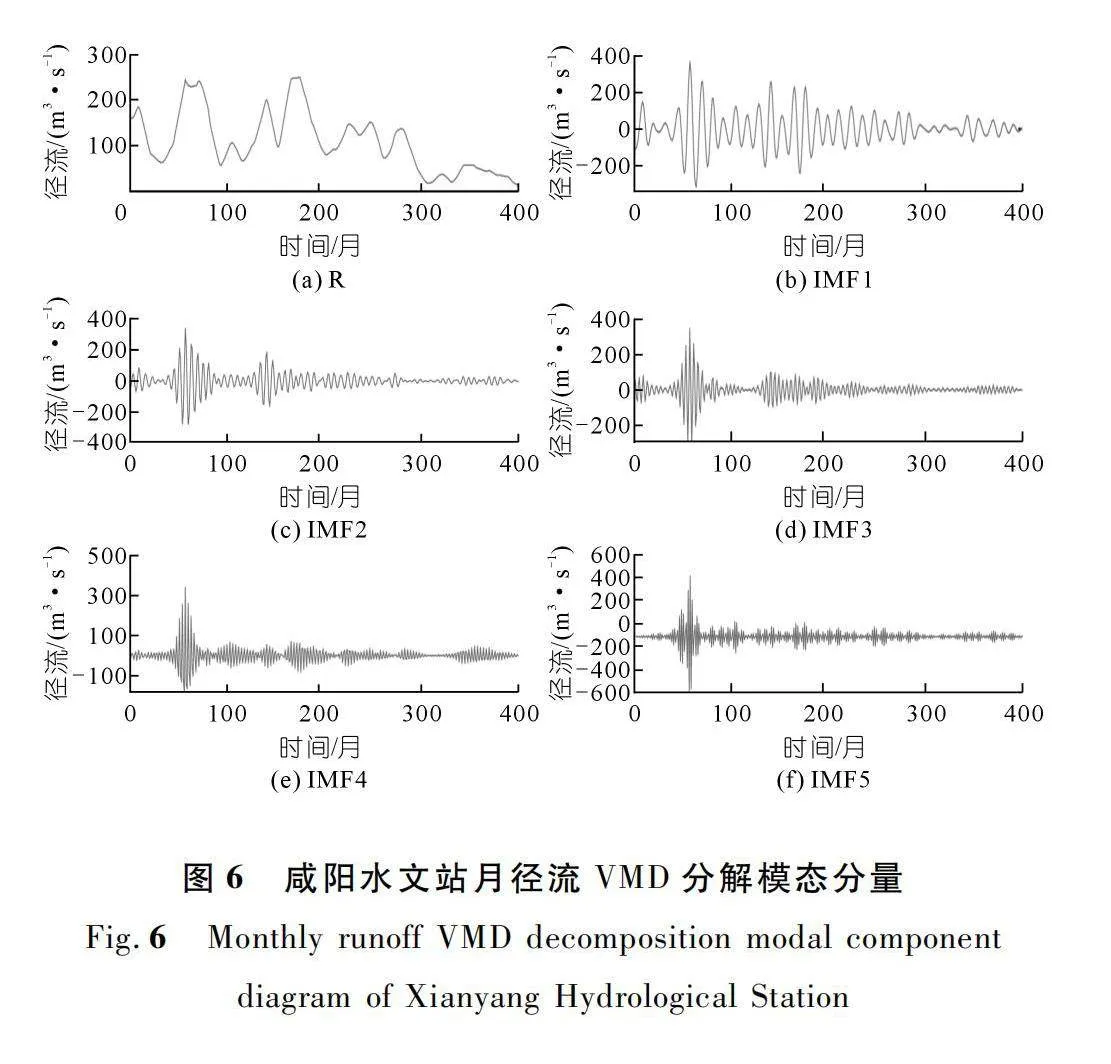
利用OVMD分解方法將原始徑流序列分解為K-1個IMF和一個殘差序列R。殘差序列R為去除周期性信息后,重構序列與原始徑流序列的誤差,一定程度上能夠反映原始徑流序列的變化趨勢。需要注意的是,模態數K的取值過大和過小都會影響模型的精度。當取值較大時,相鄰IMF的中心頻率距離偏小,會產生混頻現象;當取值較小時,原始徑流序列中的重要信息容易丟失,無法充分挖掘信息,從而可能影響模型后續的預測精度。因此,K的取值十分重要,本文通過比較中心頻率的接近程度來進行合理選擇。
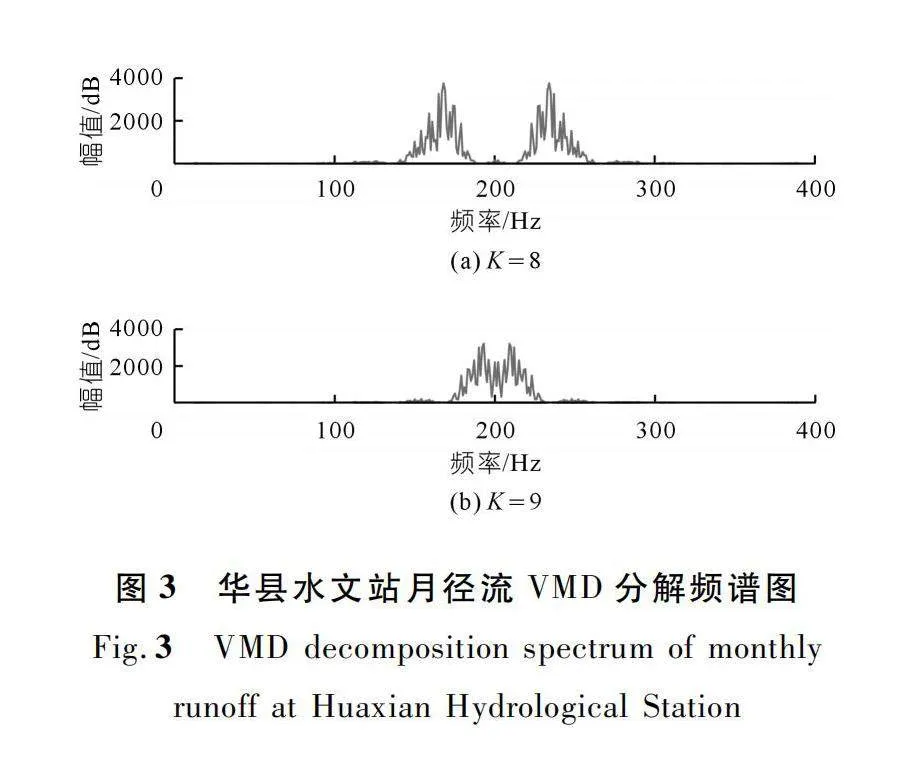
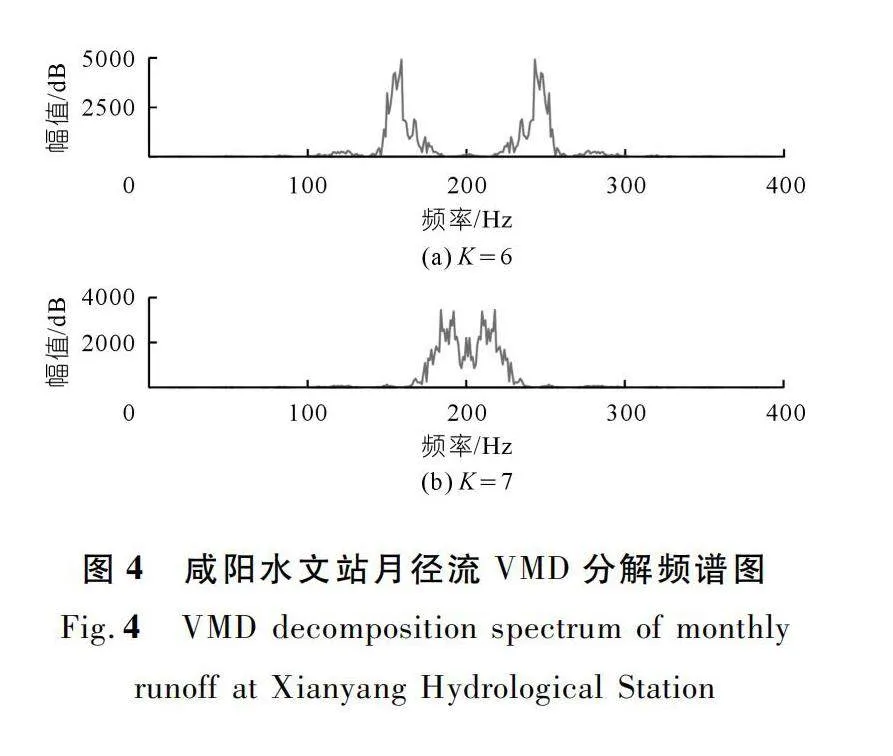
如圖3~4所示,通過多次試驗發現在K=9時,華縣水文站的月徑流兩相鄰模態的中心頻率存在混疊現象,因此K選擇為8。而在K=7時,咸陽水文站的月徑流不同頻率的尺度仍有部分重疊,因此K選擇為6。預測結果也證明所取K值進行的數據預處理達到了較優的效果。
如圖5~6所示,利用VMD對原始徑流序列進行分解,將其分為不同頻率的K個分量(IMF),挖掘出原始徑流序列中的隱藏信息(周期及趨勢信息),圖中所示分量的頻率由低到高依次排列,第1個分量顯示出了原始徑流序列的趨勢變化,后K-1個分量顯示了序列的周期性信息。證明經OVMD分解后,確能使所建模型更好地理解和學習原始徑流序列中的信息,同時也增加了數據量。
3 結果與分析
深度置信網絡(deep belief network,DBN)是一種深度人工神經網絡,BP神經網絡(back propagation neural network,BPNN)是最基礎的神經網絡,集合經驗模態分解(EEMD)是改進后的經驗模態分解,常用于預測領域。為驗證本文所提OVMD-SCN多步預測模型的預測效果,引用了OVMD-BPNN、OVMD-DBN、SCN、EEMD-SCN徑流預報模型進行試驗,并采用RMSE、MAE、MAPE、NSE等指標對5種模型預測性能進行評價。
3.1 月徑流單步預測試驗結果及分析
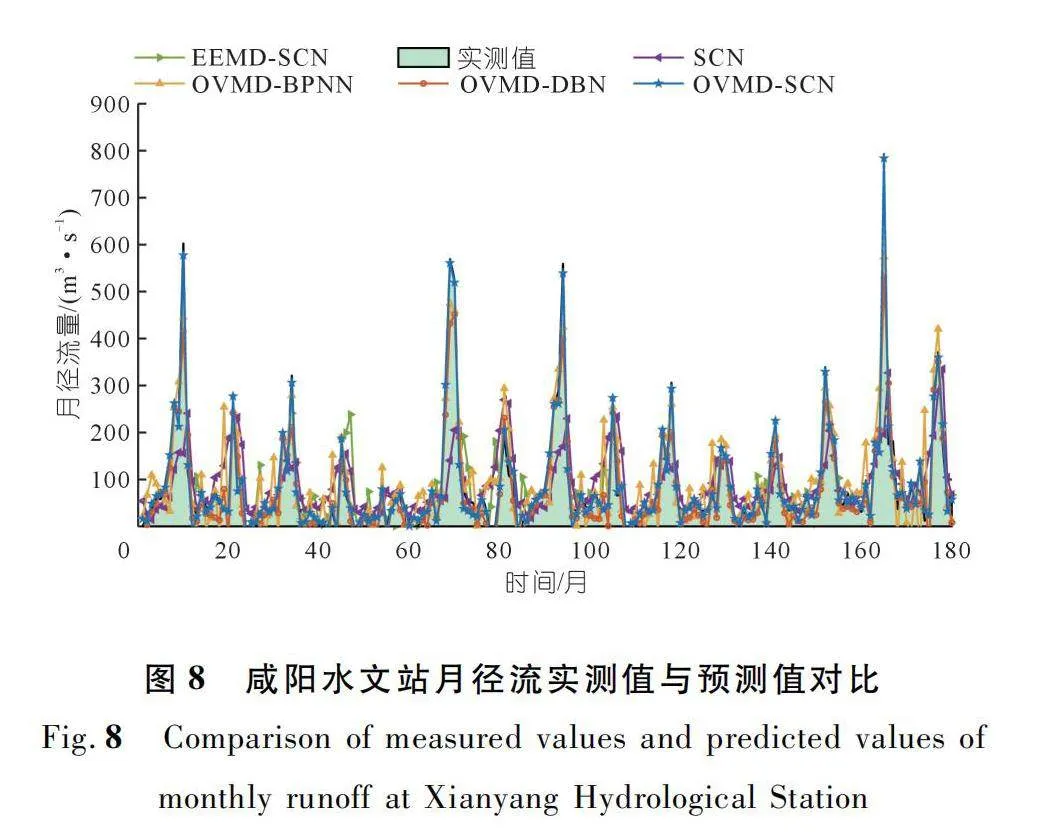
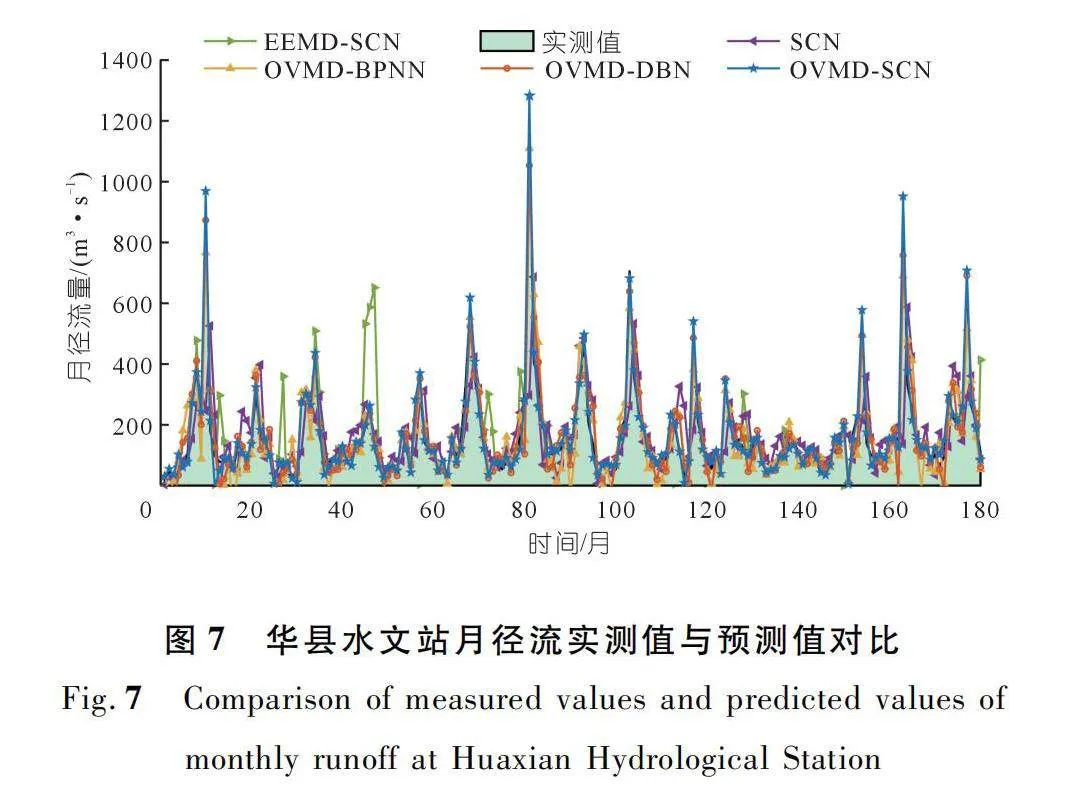
當僅預測未來一個時刻的徑流數據時,5種模型對兩個水文站徑流數據的單步預測結果如圖7~8所示。從圖7~8中可以看出:所選5種不同模型對于兩個水文站的月徑流趨勢預測整體來看較為準確。其中,本文所提的OVMD-SCN模型預測結果與實際值的重合度較高,沒有出現嚴重的紊亂現象,初步判斷所提模型具有較好的預測性能。
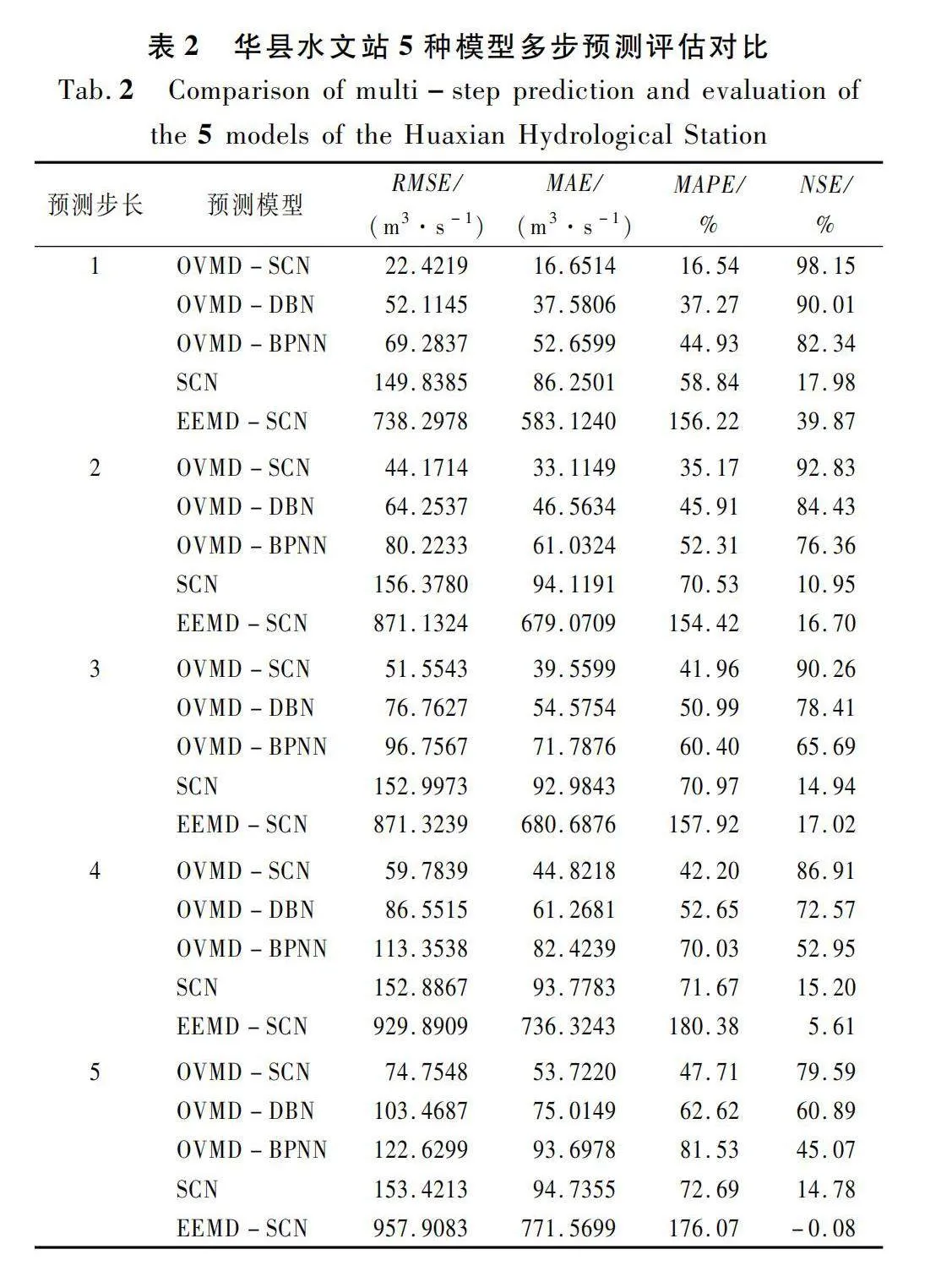
為精確比較模型性能,根據選定的模型評價指標得出所選不同模型的預測值與徑流序列實測值之間的誤差評價指標如表2所列。結合表2分析可知,單步預測中模型OVMD-SCN的RMSE、MAE、MAPE值顯著低于其他模型,而NSE達95%以上。因此認為在單步預測中,本文所提的OVMD-SCN模型相較于其他流行模型,具有更好的預測效果,是一種提高徑流預測精度的有效方法。
3.2 月徑流多步預測試驗結果及分析
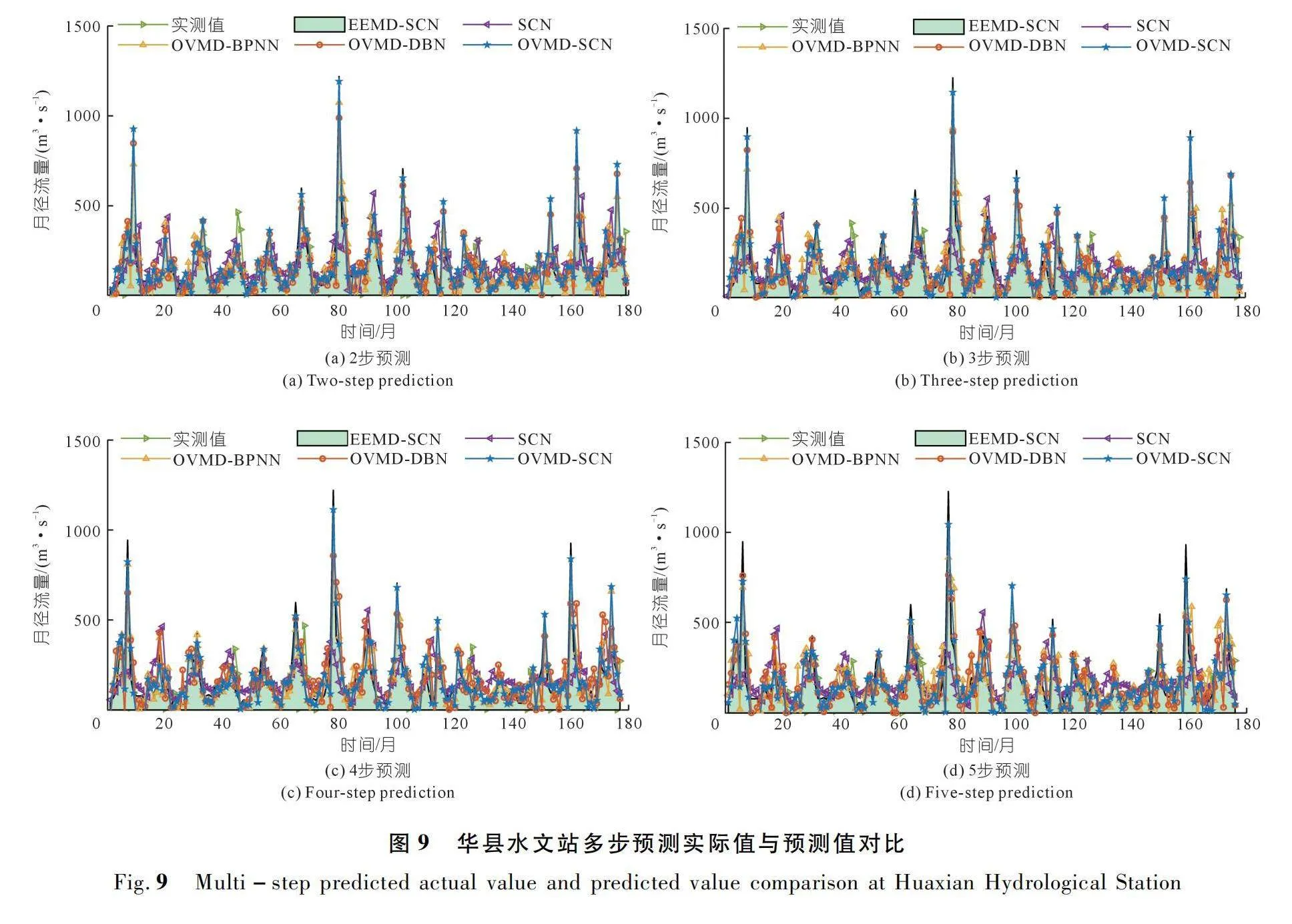
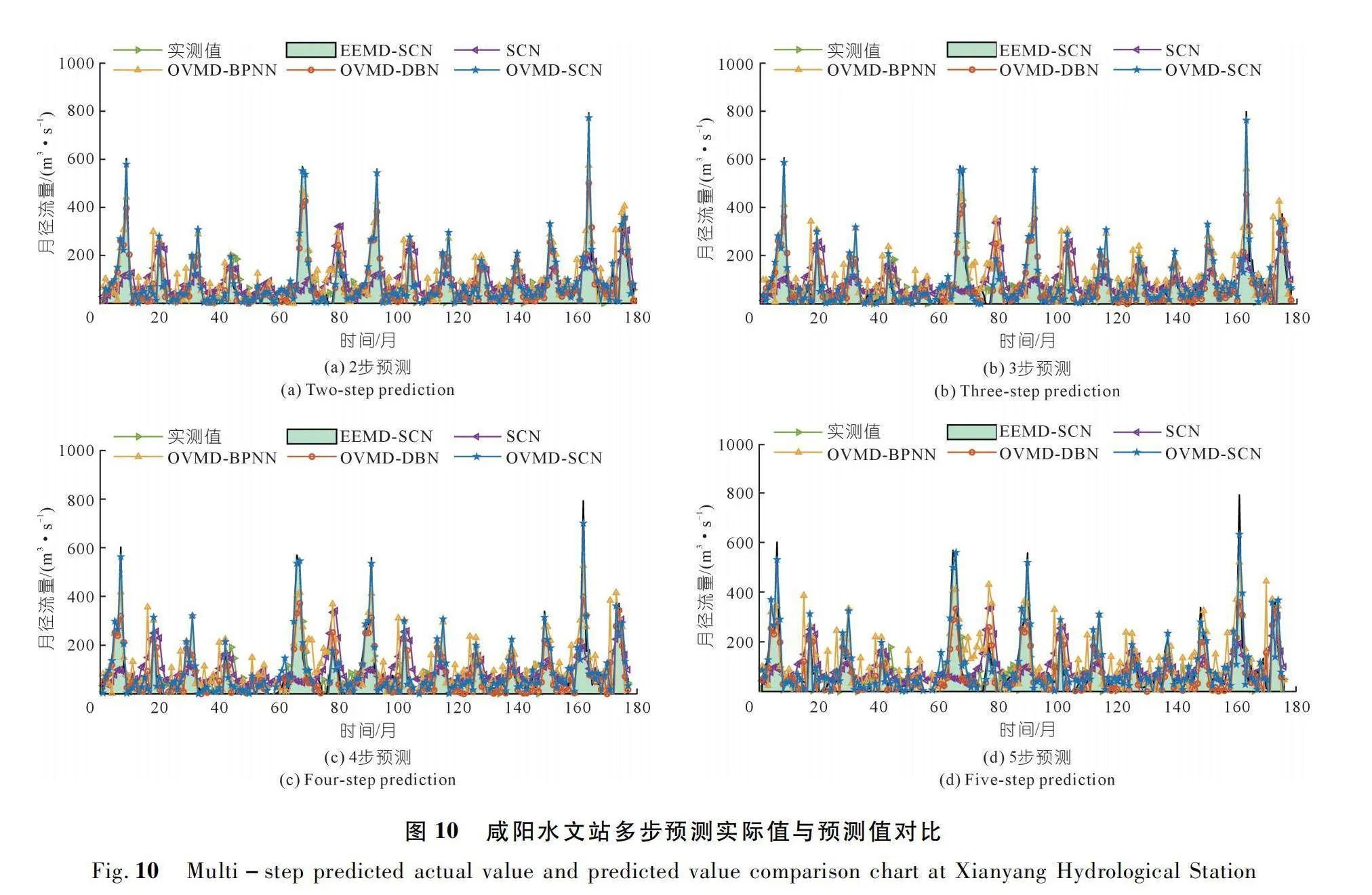
相比于單步預測,多步預測在徑流預報的實際應用中更為重要,本次研究采用的多步預報每次只向前預測一步,通過每次得到的預測值再進行下一次預報。仿真實驗步長為2,3,4,5步,華縣水文站和咸陽水文站5種模型的多步預測結果分別如圖9~10所示。
由圖9~10可知,在5種模型的多步預測結果中,OVMD-SCN模型的預測值變化趨勢與實際值最為貼合,當樣本數值出現較大突增突減的大波動情況時,預測值也沒有出現較大的偏差,只是隨著多步預測步數的增加,預測值與實際值出現越來越大的偏差,誤差明顯變大。而其他模型在原始序列出現波動的區域內均具有一定程度的紊亂和離散,且隨著預測步數的增加,所出現的波動也越來越大。5種模型多步預測的誤差指標值如表2~3所列。
結合圖表分析可知,本文所提OVMD-SCN模型在華縣水文站多步(1,2,3,4,5步)徑流預測中的NSE分別為98.15%,92.83%,90.26%,86.91%,79.59%,在咸陽水文站分別為98.52%,95.94%,93.92%,89.96%,77.89%,相較于其他模型均取得了最佳的NSE值和最小的誤差,且隨著預測步數的增加,華縣水文站和咸陽水文站的NSE分別下降了18.56%和20.63%。其他模型的擬合度均低于OVMD-SCN模型,且隨著預測步數增加,模型擬合度下降較為快速,證明其他模型只能大致擬合真實值的變化趨勢,模型可靠度較低。由此看出,OVMD-SCN模型的擬合度最好,模型精度最高,且隨著預測步數的增加,模型擬合度下降最為緩慢,說明OVMD可以有效挖掘出徑流序列中的有用信息,SCN在徑流預測領域可取得良好的效果。當需要預測渭河流域未來較長時間的徑流數據時,所提出的OVMD-SCN遞歸多步預測模型可作為一種有效的方法。
4 結論與展望
為解決日益變化的環境下渭河流域月徑流預報精度不高的問題,本文建立了OVMD-SCN遞歸多步預測模型,采用OVMD將月徑流時間序列進行分解,然后利用SCN對每個分解部分進行預測,疊加得到預測結果,最后利用遞歸多步預測方法對未來一段時間內的徑流數據進行預測。以華縣、咸陽水文站1970~2019年實測月徑流數據為輸入進行模擬,并與OVMD-DBN等流行預測模型進行對比分析。主要結論如下:
(1)利用最優變分模態分解(OVMD)實現對原始徑流序列的分解,克服了傳統信號分解方法的模態混疊問題。通過中心頻率法選取分解模態數K值分別為8和6,根據模態分量圖可以得出,經OVMD分解后,有效挖掘出了原始徑流序列中的周期性和趨勢性信息,能夠幫助模型更好地理解和學習序列的信息。
(2)本次研究利用隨機配置網絡(SCN)來對OVMD分解得到的每個模態分量(IMF)進行預測,疊加得到單步預測結果。通過該模型與OVMD-DBN等模型進行單步預測結果的比較,證明了本研究所提出的OVMD-SCN模型具有較好的擬合性,模型性能較高,是一種有效提高徑流預測精度的方法。
(3)利用遞歸多步預測方法進行未來一段時間內的徑流預測,構建了OVMD-SCN多步預測模型。通過與其他模型進行對比,證明了所建模型在每個多步預測步數上誤差均較小,擬合度較高,模型性能良好。
本次研究所進行的徑流預報是基于歷史徑流數據作為輸入,通過機器學習方法挖掘其歷史序列中的周期性和趨勢性徑流信息,再利用神經網絡對徑流序列進行預測。在數據預處理的過程中,采用整體信號分解的方式挖掘其信息,而在實際過程中數據逐點產生,未來應研究采用何種逐點數據分解方式能使模型在實際應用中充分發揮其預測性能。此外,渭河流域近年來受氣候變化條件影響較大,未來可考慮分階段進行預報。
參考文獻:
[1]HIRABAYASHI Y,MAHENDRAN R,KOIRALA K,et al.Global flood risk under climate change[J].Nature Climate Change,2013,3(9):816-821.
[2]ZHAI J.Spatial variation and trends in PDSI and SPI indices and their relation to streamflow in 10 large regions of China[J].Journal of Climate,2010,23(3):649-663.
[3]黃朝君,賈建偉,秦赫,等.基于Copula熵-隨機森林的中長期徑流預報研究[J].人民長江,2021,52(11):81-85.
[4]ZHANG X,PENG Y,ZHANG C,et al.Are hybrid models integrated with data preprocessing techniques suitable for monthly streamflow forecasting? Some experiment evidences[J].Journal of Hydrology,2015,530:137-152.
[5]梁浩,黃生志,孟二浩,等.基于多種混合模型的徑流預測研究[J].水利學報,2020,51(1):112-125.
[6]晉健,劉育,王琴慧,等.基于小波去噪和FA-SVM的中長期徑流預報[J].人民長江,2020,51(9):67-72.
[7]YU X,ZHANG X,QIN H.A data-driven model based on Fourier transform and support vector regression for monthly reservoir inflow forecasting[J].Journal of Hydro-environment Research,2018,18:12-24.
[8]REZAIE-BALF M,KIM S,FALLAH H,et al.Daily river flow forecasting using ensemble empirical mode decomposition based heuristic regression models:application on the perennial rivers in Iran and South Korea[J].Journal of Hydrology,2019,572:470-485.
[9]ALI M,PRASAD R,XIANG Y,et al.Complete ensemble empirical mode decomposition hybridized with random forest and kernel ridge regression model for monthly rainfall forecasts[J].Journal of Hydrology,2020,584:124647.
[10]張璐,劉真,李磊,等.基于VMD-PSR-BNN模型的月徑流預測方法研究[J].中國農村水利水電,2023(4):105-113.
[11]孫娜,周建中,朱雙,等.基于小波分析的兩種神經網絡耦合模型在月徑流預測中的應用[J].水電能源科學,2018,36(4):14-17,32.
[12]ZUO G,LUO J,WANG N,et al.Decomposition ensemble model based on variational mode decomposition and long short-term memory for streamflow forecasting[J].Journal of Hydrology,2020,585:124776.
[13]包苑村,解建倉,羅軍剛.基于VMD-CNN-LSTM模型的渭河流域月徑流預測[J].西安理工大學學報,2021,37(1):1-8.
[14]孫國梁,李保健,徐冬梅,等.基于VMD-SSA-LSTM的月徑流預測模型及應用[J].水電能源科學,2022,40(5):18-21.
[15]OZANICH E,GERSTOFT P,NIU H.A feedforward neural network for direction-of-arrival estimation[J].The Journal of the Acoustical Soclety of America,2020,147(3):2035-2048.
[16]WANG D,LI M.Stochastic configuration networks:fundamentals and algorithms[J].IEEE Trans Cybern,2017,47(10):3466-3479.
[17]張皓博.隨機配置網絡的改進及其在風速預測中的應用[D].沈陽:沈陽工業大學,2022.
[18]陳飛,王斌,周東東,等.融合改進符號動態熵和隨機配置網絡的水電機組軸系故障診斷方法[J].水利學報,2022,53(9):1127-1139.
[19]高園晨.基于機器學習的多步風速預測模型研究[D].楊凌:西北農林科技大學,2023.
[20]PENG T,LI Y M,SONG Z Z,et al.Hybrid intelligent deep learning model for solar radiation forecasting using optimal variational mode decomposition and erolutionary deep belief network-online sequential extreme learning machine[J].Journal of Building Engineering,2023,76:107227.
(編輯:郭甜甜)
Multi-step runoff forecast in Weihe River Basin based on optimal
variational mode decomposition
QIU Xudi1,WANG Kun1,CHEN Fei2,XIANGLI Yuxi1,WANG Bin1
(1.College of Water Resources and Architectural Engineering,Northwest Aamp;F University,Yangling 712100,China; 2.State Key Laboratory of Water Resources Engineering and Management,Wuhan University,Wuhan 430072,China)
Abstract:The non-stationarity of monthly runoff series in Weihe River Basin is increasing and it is difficult to predict accurately,a multi-step prediction model of monthly runoff series based on optimal variational mode decomposition (OVMD),stochastic configuration networks (SCN) and recursive multi-step prediction strategy was proposed.Firstly,OVMD was used to project the runoff data into subsequences with different frequencies.Then,SCN was used to predict each decomposition part,and the single-step prediction results were obtained by superposition.Finally,the recursive multi-step prediction method was used to predict the runoff data for a long time in the future,and the multi-step prediction results were obtained.The measured monthly runoff time series of Huaxian Hydrological Station and Xianyang Hydrological Station from 1970 to 2019 were selected for case analysis,and we compared the predicted results with other popular models.RMSE,MAE,MAPE and NSE were selected to evaluate the prediction results.The results showed that the NSE of the OVMD-SCN model in the single-step prediction experiments of Huaxian Hydrological Station and Xianyang Hydrological Station reached 98.15% and 98.52%,respectively,which were significantly higher than other popular models.In the multi-step prediction experiments of two hydrological stations,the evaluation indexes of OVMD-SCN were better than other popular models.It showed that the proposed method can accurately predict the runoff in the future 5 months.The research results can provide a new method for monthly runoff prediction in the Weihe River Basin.
Key words:runoff forecast; optimal variational mode decomposition; randomly configuring network; recursive multi-step prediction; Weihe River Basin
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
廣西科技大學學報(2016年1期)2016-06-22 13:10:37
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
核科學與工程(2015年4期)2015-09-26 11:59:03
航空學報(2015年4期)2015-05-07 06:43:35
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
