基于文本挖掘的ISO標準術語自動識別與標準術語知識圖譜構建研究
2024-12-31 00:00:00方思怡
標準科學 2024年8期
關鍵詞:文本挖掘
關鍵詞:ISO,國際標準,術語自動識別,標準數(shù)字化,文本挖掘
0 引言
術語(Ter m)是蘊含特定學科領域核心概念的專用名詞,與特定學科的領域知識密切相關[1,2]。術語識別(Terminology recognition,TR)是指從語料中抽取具有領域代表性的詞匯或短語的過程,被視為信息抽取和命名實體識別(Naming entityrecognition,NER)領域的重要分支[3]。近年來術語自動識別(Terminology automatic recognition,TAR)逐漸引起各界研究者的關注。標準是領域技術情報的重要來源,標準術語也是領域技術信息的核心載體,具有較強的專業(yè)性與系統(tǒng)性。在標準文本中,ISO國際標準是推進國際貿易與合作的重要準繩,其地位和影響力不言而喻。在標準數(shù)字化轉型下,ISO術語自動識別將為標準語料庫、標準知識圖譜、標準智能檢索、標準自動標引、標準智能翻譯、標準本體、相關產(chǎn)業(yè)畫像和知識體系構建等標準知識服務奠定重要的數(shù)據(jù)基礎[4,5]。
1 標準術語自動識別的研究現(xiàn)狀
1.1 術語自動識別的相關研究進展
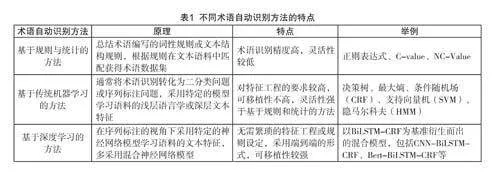
縱觀已有的研究,術語識別技術歷經(jīng)多個發(fā)展階段,迄今為止已形成了基于專家人工、基于規(guī)則與統(tǒng)計、基于傳統(tǒng)機器學習以及基于深度學習的識別方法。
受限于技術水平,早期的術語識別研究多通過專家人工模式進行,該方法能確保術語抽取的質量,但人力和時間成本較高,可推廣性不強。隨著計算機技術的發(fā)展,術語自動識別逐漸取代了專家人工識別,成為各領域術語識別的主流發(fā)展方向。術語自動識別的具體技術取決于其所針對的文本語料特性。本研究系統(tǒng)梳理了術語自動識別研究的技術方法,表1概括了不同術語自動識別方法的原理、特點及案例。
1.2 標準術語自動識別的現(xiàn)狀與發(fā)展趨勢
當前國內外標準數(shù)字化轉型正處于起步階段。2021年發(fā)布的《國家標準化發(fā)展綱要》明確指出要加快標準的數(shù)字化、網(wǎng)絡化和智能化轉型,由此對標準數(shù)字化文本的知識自動抽取與加工技術提出了全新的要求[6]。與專利、科技論文等領域相比,標準術語自動識別研究尚存在大量的提升空間。作為標準的基本要素之一,標準術語是標準文本技術信息的重要組成,也是標準知識自動抽取的對象之一。近來涉及標準實體識別的國內外研究大多針對標準起草單位、標準提出單位、標準指標和標準規(guī)范性引用文件[7-9],尚未對國際和國內外標準進行術語自動識別的深入探索。
盡管標準術語自動識別尚存在大量研究空白,在標準數(shù)字化轉型的驅動下,隨著標準知識服務對細粒度和深層次的需求日益增加,國際和國內外標準的術語自動識別方法將成為大勢所趨。作為國際標準的重要品種,ISO標準術語自動識別技術也存在迫切的發(fā)展和應用需求。
2 ISO標準術語自動識別的研究方法
2.1 研究思路
本研究以上海市質量和標準化研究院“標準文獻發(fā)行系統(tǒng)”中現(xiàn)有的ISO文本為數(shù)據(jù)來源,結合ISO文本編寫的相關要求[10]和對ISO文本結構特性的深入分析,形成相應的研究思路。經(jīng)過分析可知,當前ISO國際標準的載體為PDF格式的數(shù)字化文本,通常以英語語種為主,可能存在多語種的情況,ISO術語條目的編寫也遵循較為明確的規(guī)則。綜上所述,本研究選取基于規(guī)則的文本挖掘技術作為ISO標準術語的自動識別方法,由此制定相應的技術路徑。
2.2 研究流程
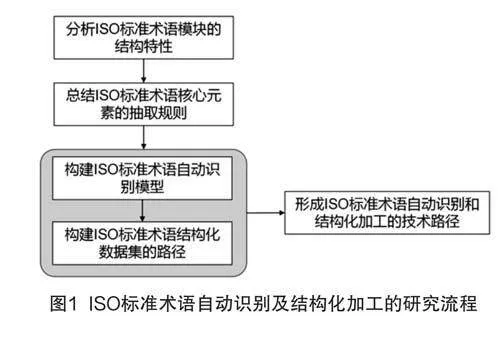
本研究基于研究思路,制定了如圖1所示的研究流程框架。
2.2.1 分析ISO標準術語模塊的結構特性
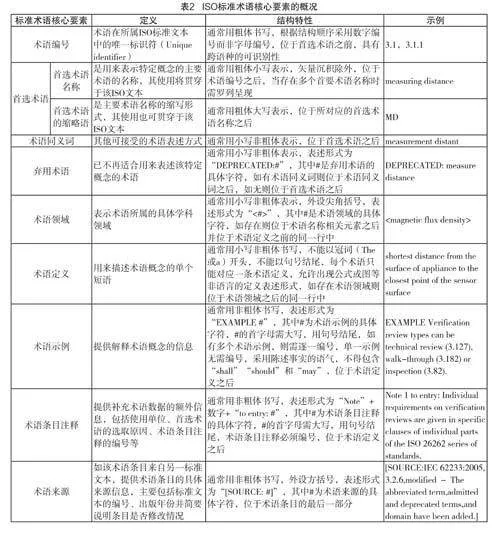
研究流程的第一步為分析ISO標準術語模塊的結構特性,以ISO的編寫指南為依據(jù),結合現(xiàn)行ISO文本術語數(shù)據(jù)的實際情況,明確ISO術語自動識別的研究范疇,并概括研究范疇內ISO術語模塊核心元素的文本結構特性。
經(jīng)過系統(tǒng)分析可知,I S O標準術語模塊可以囊括的元素有術語介紹(Introductory wording)、術語編號(Term number)、首選術語(Prefer redterm)、首選術語的縮略語、可接受的術語同義詞(Accepted term)、棄用術語(Deprecated term)、術語領域(Te r m d o m a i n)、術語定義(Te r mde f i n it ion)、術語示例(Ter m ex a mple)、術語條目注釋(Note to ent r y)以及術語來源(Ter msource)。本研究堅持以應用到導向,重點關注ISO術語中與技術密切相關的信息,故將研究范疇界定為術語編號、首選術語、首選術語縮略語、可接受的術語同義詞、棄用術語、術語定義、術語示例、術語條目注釋和術語來源。結合現(xiàn)有的ISO文本數(shù)據(jù),將上述核心要素的定義、結構特性和示例概括見表2。
2.2.2 總結ISO標準術語模塊中核心元素的抽取規(guī)則
在此基礎上開展研究流程的第二步,也即根據(jù)文本結構特性,從文本表述形式、在術語條目中的所在位置等幾個方面總結ISO標準術語模塊中核心元素的抽取規(guī)則。以術語元素中的術語編號為例,其抽取規(guī)則可以概括為兩點,其一是通常位于術語模塊的第一個位置,其二是由阿拉伯數(shù)字和間隔點構成,且間隔點位于兩個阿拉伯數(shù)字之間。
2.2.3 構建ISO標準術語自動識別模型
研究流程的第三步為針對ISO標準術語模塊的各個核心元素,采用Python構建基于規(guī)則的ISO標準術語自動識別模型,本研究首先將ISO標準術語模塊中各核心元素的抽取規(guī)則轉化為偽代碼,進而通過Python編寫程序,形成適用于ISO術語各核心元素的自動識別算法,再將上述算法整合成為統(tǒng)一的算法模塊,完成ISO術語自動識別模型的構建。
2.2.4 構建ISO標準術語結構化數(shù)據(jù)集的路徑
研究流程的第四步為采用Python構建ISO標準術語結構化數(shù)據(jù)集的實現(xiàn)路徑,主要包括設定結構化數(shù)據(jù)集的數(shù)據(jù)表達框架和結構化數(shù)據(jù)集的轉化算法。該步驟旨在將ISO標準術語自動識別模型中獲得的ISO術語各核心要素的抽取結果自動轉化為結構化數(shù)據(jù)集的形式,為后續(xù)的ISO標準數(shù)據(jù)深度挖掘和加工奠定一定的技術基礎。
2.2.5 形成ISO標準術語自動識別和結構化加工的技術路徑
在完成上述步驟后,采用Python將ISO標準術語自動識別模型和結構化數(shù)據(jù)集的技術路徑相結合,完成上述兩者的代碼模塊的順利鏈接,形成ISO標準術語自動識別和結構化加工的完整技術路徑。
2.3 模型設計
ISO標準術語自動識別模型是實現(xiàn)ISO標準術語自動抽取的關鍵所在。
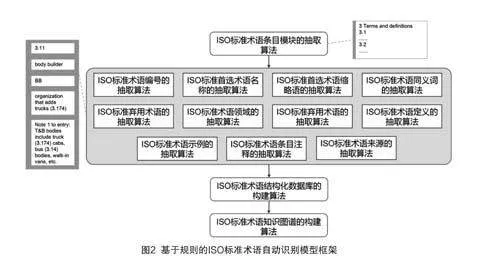
本研究采用基于規(guī)則的文本挖掘方法,通過Python編寫了提取ISO標準術語條目模塊與核心元素的抽取算法以及結構化和可視化加工的算法,形成了基于規(guī)則的ISO標準術語自動識別模型,模型框架詳如圖2所示。
由圖2可知,該模型主要由ISO標準術語條目模塊的抽取算法、ISO標準術語核心元素的抽取算法、I SO標準術語結構化數(shù)據(jù)庫的構建算法以及ISO標準術語知識圖譜的構建算法組成,其中ISO標準術語條目模塊的抽取算法、ISO標準術語核心元素的抽取算法旨在實現(xiàn)ISO標準術語核心元素的自動抽取,ISO標準術語結構化數(shù)據(jù)庫的構建算法旨在完成自動抽取結果的結構化加工,形成可適用于標準數(shù)字化平臺的ISO文本結構化數(shù)據(jù)集,而ISO標準術語知識圖譜的構建算法的目的在于對ISO標準術語的自動識別結果進行可視化展現(xiàn)并形成可供深度挖掘的數(shù)據(jù)集,為標準智能決策奠定數(shù)據(jù)基礎。
3 ISO標準術語自動識別的研究結果
3.1 ISO標準術語結構化數(shù)據(jù)庫的文獻計量學分析
本研究在完成ISO標準術語自動識別及結構化和可視化加工的技術路徑后,在特定的I SO標準文本上開展實證研究。本研究選取ISO 26262作為ISO術語自動識別技術的應用對象。ISO 26262針對汽車安全相關的電子電氣系統(tǒng),與汽車功能安全密切相關,其所涉及的汽車芯片也是近年來集成電路產(chǎn)業(yè)的熱點方向之一。
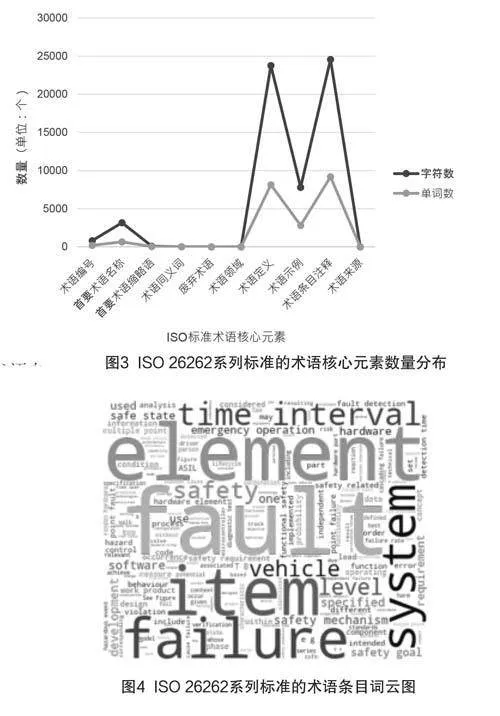
經(jīng)文本切詞后統(tǒng)計可知,ISO 26262共計10篇標準文本,含有194.42萬個字符與66.89萬個單詞。在上述文本中應用ISO標準術語自動化識別及結構化和可視化加工的模型,最終抽取獲得的ISO標準術語條目的字符數(shù)為6.2萬,單詞數(shù)為2.1萬;所涉及的ISO標準術語核心元素有術語編號、首要術語名稱、首要術語縮略語、術語同義詞、術語定義、術語條目注釋和術語示例,其標準術語核心元素的數(shù)量分布情況如圖3所示。
為了掌握ISO 26262標準術語數(shù)據(jù)的詞頻分布概貌,通過構建ISO標準術語條目干擾詞庫,剔除ISO術語條目常見的無關詞,并采用Python描繪詞云圖,所得結果如圖4所示。
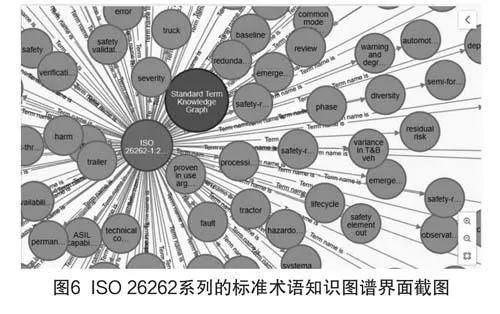
3.2 ISO標準術語知識圖譜
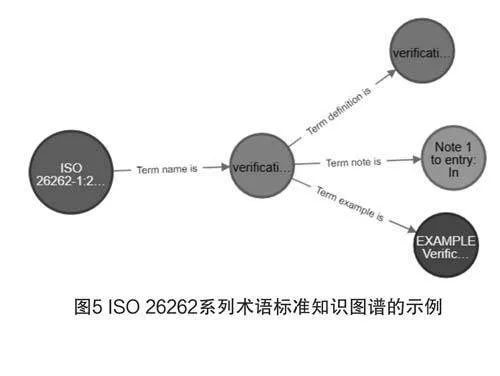
本研究基于ISO標準術語編寫的文本特性,初步設計了ISO標準術語知識圖譜的模式層,由此明確了標準術語的實體和關系類型。I SO標準術語知識圖譜的模式層框架主要以ISO標準術語核心元素為實體類型,以核心元素的名稱指向形式也即“ISO標準術語核心要素+是”的英文表述形式為關系類型。
采用Python編寫了ISO標準術語知識圖譜的可視化路徑,在Neo4j平臺中實現(xiàn)相關應用,圖譜的示例和界面截圖分別如圖5與圖6所示。該圖譜共含有547個不同的標準實體和7種不同的標準關系類型。
4 總結與展望
4.1 總結
本研究針對ISO標準的文本特性,構建了適用于ISO的術語自動識別模型及結構化和可視化加工路徑,在ISO 26262標準上完成驗證與應用,形成了ISO 26262的標準術語知識圖譜。
4.2 展望
本研究為ISO標準的標準術語自動識別提供了一定的技術參考,在后續(xù)工作中將繼續(xù)深化ISO標準實體抽取模型的研究,將其應用在標準數(shù)字化平臺中,以期能夠實現(xiàn)細粒度和深層次的ISO標準知識抽取與自動加工,推動標準數(shù)字化轉型下標準知識服務的發(fā)展。
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識與技術(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫(yī)藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學學報·自然科學版(2016年3期)2016-06-25 06:47:25
語文教學之友(2016年5期)2016-06-15 12:15:44
