基于SGAN深度學習的企業財務風險的預警研究
2024-12-31 00:00:00徐婷婷?劉洪久?胡彥蓉
信息系統工程 2024年9期
關鍵詞:深度學習
摘要:及時了解企業的財務風險情況,可以有效對財務風險進行預警預測。選取2019年2580家企業的財務數據為樣本數據,首先利用CRITIC對樣本數據的各項指標賦予權重并用灰色關聯分析法進行測度,然后利用K-means聚類方法劃分公司的風險等級,最后利用SGAN模型構建財務風險預警模型。實驗結果表明:與其他深度學習模型相比較,基于SGAN的財務風險預警模型的預測效果最好,在測試集上的準確率可以達到91.75%,證明了SGAN模型在財務風險領域應用的可行性。
關鍵詞:SGAN模型;財務風險預警;深度學習
一、前言
隨著經濟的發展,企業間的競爭因產業結構的升級而愈加激烈。一些上市企業采取激進策略導致財務風險不斷累積。為規避風險,提出有效準確的財務風險預警方法是十分必要的。生成對抗網絡GAN就是一種近年來出現的新興混合型深度學習模型,且已經廣泛應用到各個領域。但是,GAN作為一個創新的無監督學習模型,存在效率低、精確度不高等缺陷。為了使原始GAN具有更強大的學習能力,將原先的無監督模型變為半監督的網絡架構,即半監督生成對抗網絡(SGAN)模型。本文將結合CRITIC-灰色關聯分析和K-means方法,探索SGAN如何解決財務風險預警問題。
二、文獻回顧
財務風險預警的方法包括單變量模型、多元判別模型、多元邏輯回歸模型和人工智能技術。李長山(2018)[1]運用logistic回歸建立財務風險預警模型,取得了較好的預警效果,但由于多元邏輯回歸方法計算量大且樣本選擇有限,導致該類模型應用逐漸減少。隨著神經網絡概念的提出,張春梅(2021)等人[2]研究基于Lasso+SVM的財務風險預警模型,取得不錯的效果。
半監督生成對抗網絡(SGAN)模型是通過生成對抗網絡(GAN)衍生改變的模型。祝琳(2019)[3]利用半監督GAN來研究高光譜的圖像分類,證明SGAN模型可以應用到分類問題中。但目前還沒見到過半監督生成對抗網絡(SGAN)模型在財務風險預警領域的研究應用。
三、研究方法
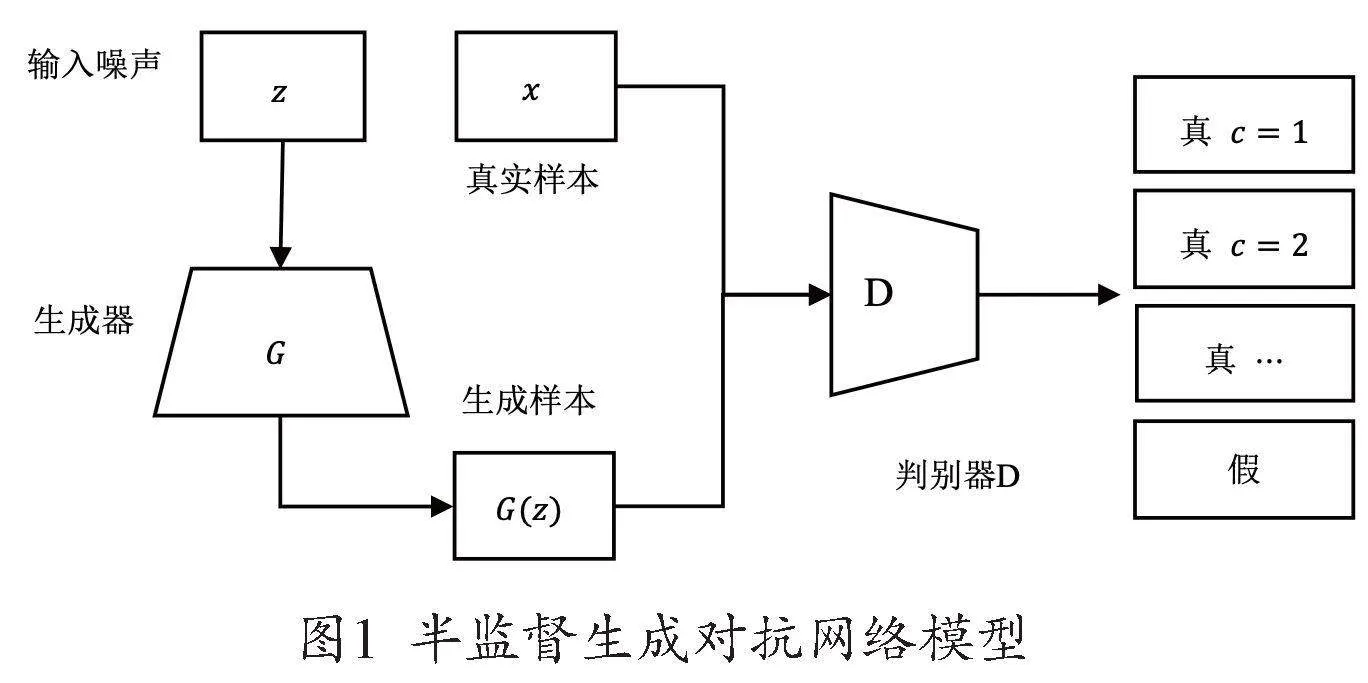
SGAN由一個生成網絡G和一個判別網絡D組成。該判別器D多分類器能夠學會區分N+1類,其中,N是原始訓練數據集中的類數,生成器G生成的偽樣本增加了一個類。生成器G的目的是接收一個隨機噪聲z并生成偽樣本,使其生成的偽樣本G’(z)最大限度接近原始數據集。判別器D的D接收無標簽的真實樣本x、有標簽的真實樣本(x,y)和生成器G生成的偽樣本G’(z)三種輸入,在判斷輸入樣本為真的情況下將其正確分類或者在判斷輸入樣本為假的情況下將其排除。在實際過程中,生成器G和一個判別器D是一體的。SGAN模型的流程圖如圖1所示。
四、數據的選取和處理
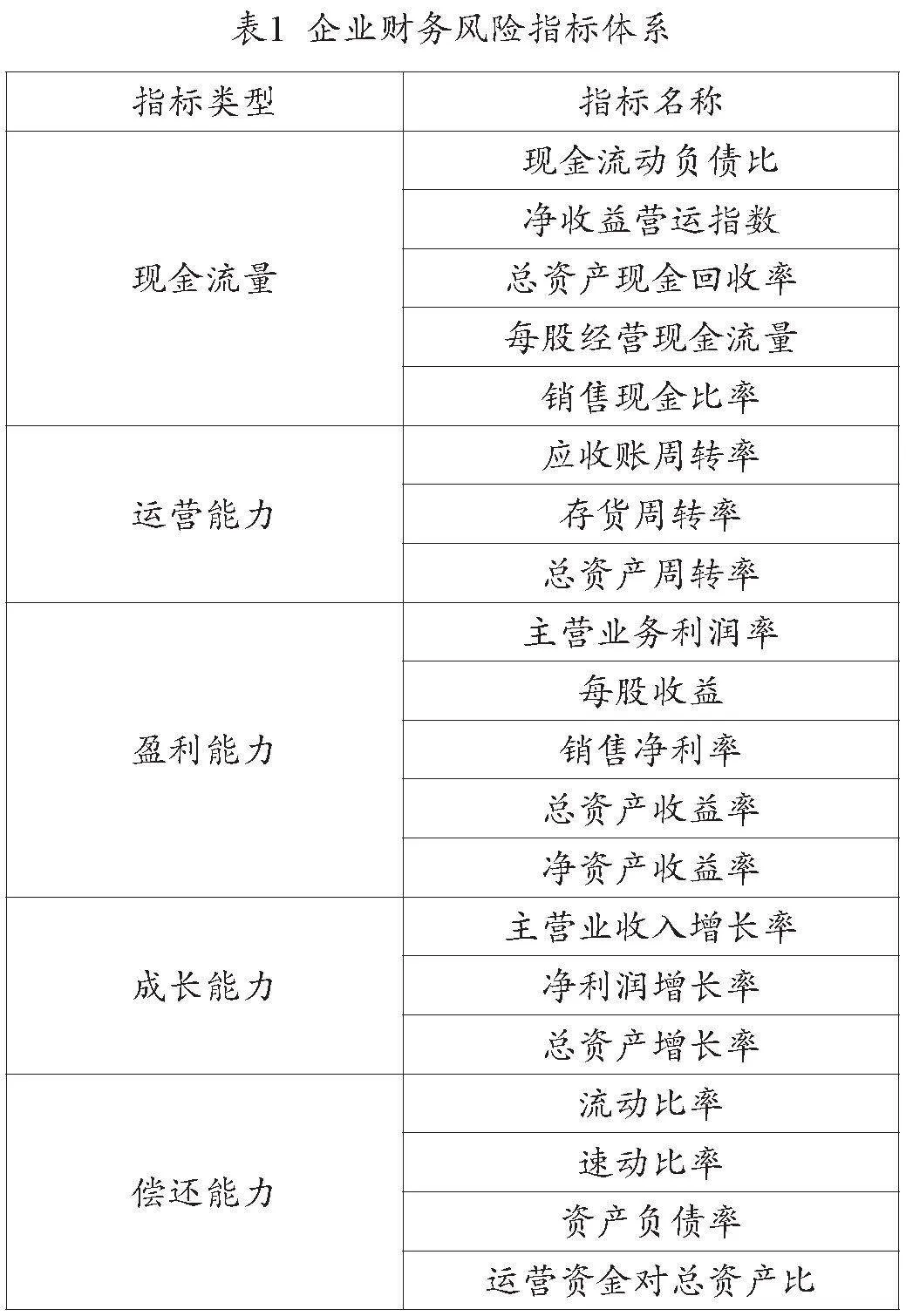
本文在網易財經網站爬取了2019年1月—12月2580家企業20個指標的財務數據作為研究對象,通過剔除存在空值的樣本數據后建立了一套對應的財務風險指標體系,并對其進行統一的歸一化處理。該體系包括了年度現金流量指標、年度運營能力、年度盈利能力、年度成長能力和年度償還能力五個部分,具體指標見表1。
五、模擬仿真與結果討論
(一)CRITIC-灰色關聯分析的風險測度
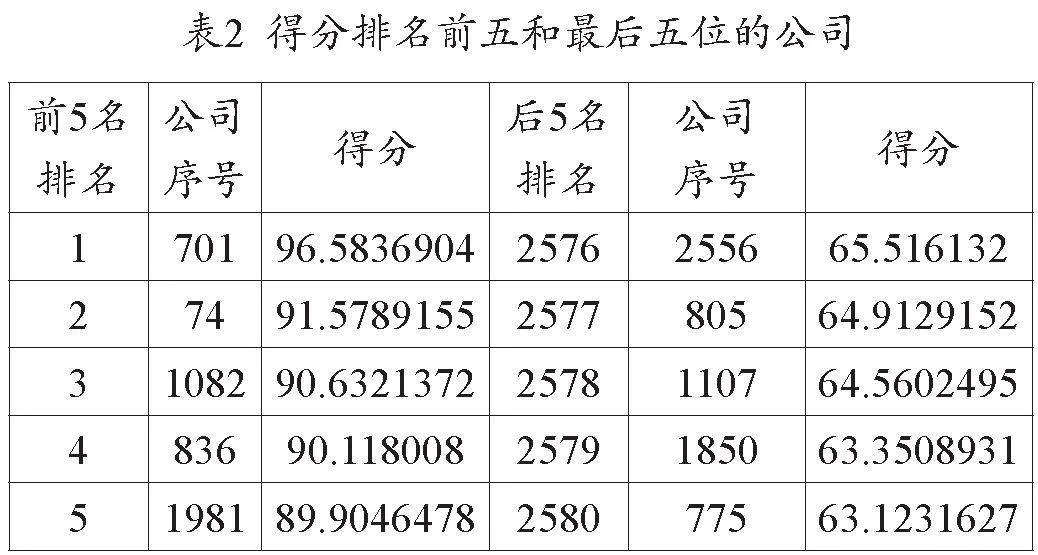
利用CRITIC法賦予每個指標的權重,通過MATLAB仿真用CRITIC-灰色關聯分析法計算每個公司的財務風險得分,由于樣本數據太多,僅選擇前五和最后五位的得分排序,見表2。
表2數據顯示,排名前五的公司在2019年都有非常好的銷售利潤,其中排名第一的701號公司在2019年更是達到了2708億元人民幣的銷售額,同比增長22.48%。而排名后五的公司,財務狀況都不太理想,2556號公司上半年凈利虧損8810萬元;805號業績虧損3.21億元,較上年同期由盈轉虧;1107號公司凈利1.13億元,下滑51.46%;1850號公司虧損2.69億元,由盈轉虧;775號公司更是處于連續五年的虧損狀態。因此基于CRITIC-灰色關聯分析評價的風險測度得到的結果是合理的。
(二)K-means聚類
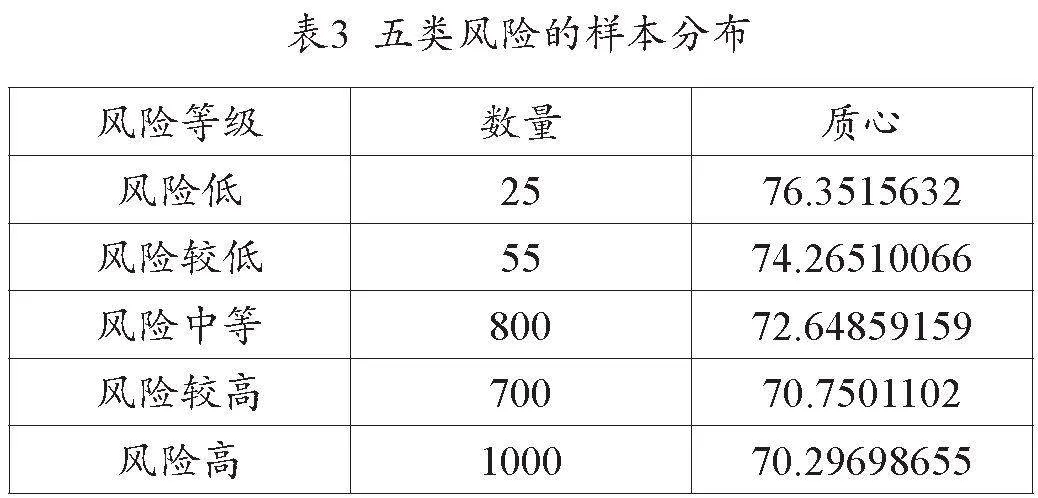
對企業的樣本數據進行風險測度后,通過MATLAB仿真利用K-means聚類將樣本數據進行風險等級劃分并打標簽,標簽一共分為五個等級,即風險低、風險較低、風險中等、風險較高、風險高。由于使用了正向化處理,因此企業得分越高,風險等級越低,得分越低,財務風險越高,劃分到每個類的樣本數量情況見表3。
(三)SGAN財務風險預警仿真
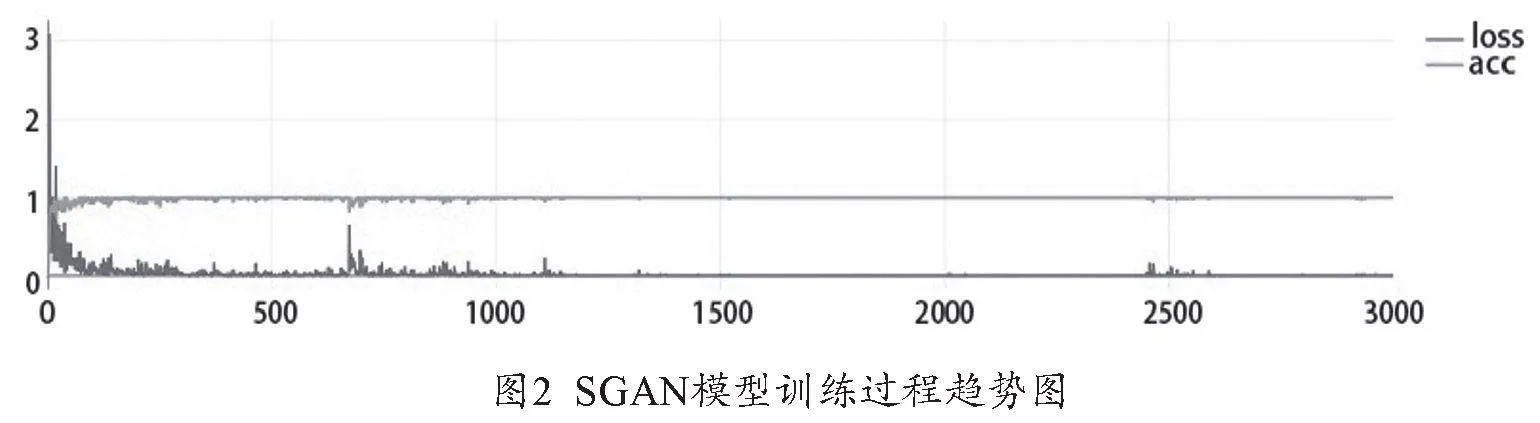
本文構建SGAN模型對2580條樣本數據進行仿真實驗,其中訓練集1865條數據,測試集715條數據。在SGAN模型的訓練過程中,訓練集的準確率和損失率變化趨勢如圖2所示。通過圖2可以看出:訓練集的準確率隨著迭代次數的增加而增加并不斷趨于1,訓練集的損失率則隨著迭代次數的增加而減少并不斷趨于0,兩者都在整個訓練過程中呈現收斂狀態,表示該模型訓練過程的學習效果良好,可以有效地進行測試和預測,保證測試仿真的準確性。
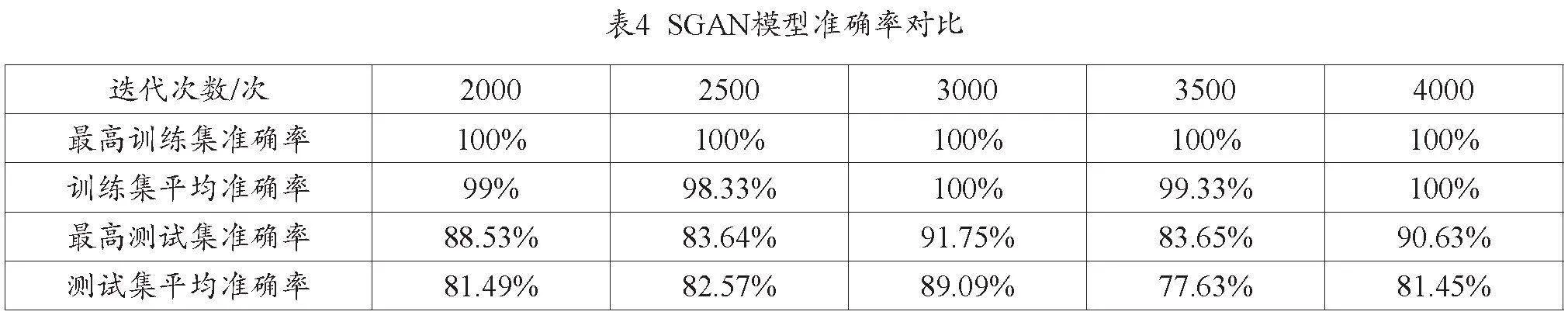
由于SGAN模型中的噪聲是隨機的,因此需要為保持其嚴謹和穩定性求出多次訓練中的平均準確率,同時可以改變迭代次數來尋找該模型對其樣本數據的最高準確率,結果見表4。
表4數據顯示,SGAN模型在迭代次數為3000次的時候,仿真預測效果最好,最高訓練集準確率和測試集準確率為100%和91.75%,訓練集和測試集的平均準確率也都高于其他迭代次數時的準確率,為100%和89.09%。
(四)SGAN模型與其他模型的對比仿真
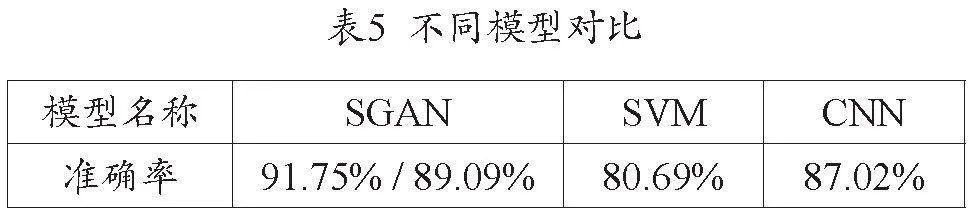
將支持向量機(SVM)模型、簡單卷積神經網絡(CNN)模型與SGAN模型進行比較,結果見表5。從表中可以看出:SVM模型的準確率為80.69%,CNN模型的準確率為87.02%,都不及SGAN模型的預測準確度。說明SGAN模型在財務風險預警方面有很好的預測能力,可以很好地應用于財務風險預警領域。
六、結語
本文構建了基于半監督對抗神經網絡的財務風險預警模型,實證研究表明:
在SGAN企業財務風險預警模型的訓練過程中,訓練集的準確率隨著迭代次數的增加而增加并不斷趨于1,訓練集的損失率則隨著迭代次數的增加而減少并不斷趨于0,兩者都在整個訓練過程中呈現收斂狀態,表示該模型訓練過程的學習效果良好,可以有效地對財務風險數據進行測試和預測,說明模型可以很好地提取財務風險數據的特征并保證了預測的準確度。
在SGAN企業財務風險預警模型的仿真過程中,迭代次數為3000次的時候,仿真預測效果最好,最高訓練集準確率和測試集準確率為100%和91.75%,訓練集和測試集的平均準確率也都高于其他迭代次數時的準確率,為100%和89.09%,驗證了SGAN在財務數據處理領域應用的可行性,存在很好的前景發展。
與SVM和CNN相比較,無論是平均準確率還是最高準確率,SGAN模型在企業財務風險預警研究中的預測效果都比其他兩個模型要好,SVM模型的準確率為80.69%,CNN模型的準確率為87.02%,而SGAN模型的平均準確率為89.09%、最高準確率為91.75%,從而也驗證了SGAN對比與其他深度學習模型的優越性,有更高的預測精度。
當然,本研究還存在一些不足之處需要改進,如建立指標體系時還需要考慮宏觀經濟類指標。進一步設置更多的對照組和如何穩定SGAN模型中的輸入噪聲從而提高其準確率,也是未來的研究方向。
參考文獻
[1]李長山.基于Logistic回歸法的企業財務風險預警模型構建[J].統計與決策,2018,34(06):185-188.
[2]張春梅,趙明清,官俊琪.基于Lasso+SVM的制造業上市公司財務風險組合預警模型[J].數學的實踐與認識,2021,51(05):1-12.
[3]祝琳.基于生成對抗網絡的監督/半監督高光譜圖像分類方法研究[D].哈爾濱:哈爾濱工業大學,2019.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
