基于k-最鄰近分類法的灰色評估方法的改進(jìn)
2011-09-05 02:48:54朱美玲陳勇明羅廷友
統(tǒng)計與決策 2011年19期
關(guān)鍵詞:考核
朱美玲,陳勇明,羅廷友
(成都信息工程學(xué)院 數(shù)學(xué)學(xué)院,成都 610225)
0 引言
在預(yù)測與決策理論中,評估是極其重要的一個環(huán)節(jié)。評估方法的種類很多,例如層次分析法、Bayes概率法、模糊評價法、聚類評估等[1],而灰色評估是評估中較為重要的一種。
在評估的研究過程中可以發(fā)現(xiàn),觀測矩陣是評估的主要依據(jù),是評估的出發(fā)點(diǎn)。觀測矩陣主要有兩種形式:一是客觀數(shù)據(jù),二是專家評分。本文中我們將第二種觀測矩陣稱為專家評分矩陣。現(xiàn)實生活中有很多這樣的例子,如企事業(yè)單位的人才招聘,在面試環(huán)節(jié)往往由有經(jīng)驗的員工出任考官考察應(yīng)聘者的專業(yè)知識技能、人際關(guān)系處理能力、創(chuàng)新能力以及工作態(tài)度等各方面的指標(biāo),然后利用考官們對各指標(biāo)的評分進(jìn)行評估以確定是否錄取應(yīng)聘對象。對于這類專家評分問題,評價主體——專家在評分過程中往往帶有自身的主觀傾向,如某些專家打分較為保守,對所有對象評分值普遍偏低;同時另一些專家打分又習(xí)慣性偏高。而以往的灰色評估方法,無論是經(jīng)典的灰色聚類評估的主要方法白化權(quán)函數(shù)和關(guān)聯(lián)度,還是近年來的一些新的灰色評估方法或者灰色評估方法的改進(jìn)[2~4],都沒有考慮到這一點(diǎn),即在評估過程中沒有考慮如何消除專家主觀因素對結(jié)果的影響。針對這一問題,本文擬借鑒k-NN方法,利用每位專家以往的評分記錄修正其當(dāng)前評分矩陣,消除評分時存在的主觀傾向,使評估更趨于客觀與合理。
1 預(yù)備知識
1.1 k-NN的基本原理
定義[5]k-NN(k-Nearest-Neighbor)即k-最鄰近分類法,是數(shù)據(jù)挖掘中常用的一種算法:在觀測數(shù)據(jù)集中動態(tài)的確定k個與我們希望分類的新觀測相類似的觀測,并使用這些觀測把新觀測分到某一類中。
在使用k-NN方法時,需要先確定一個適當(dāng)大小的k值。如果k值選取過小,如k=1,則分類方式將對數(shù)據(jù)的局部特征非常敏感;如果k值選取過大,如k=n(其中n是觀測數(shù)據(jù)集中觀測的總數(shù)),則相當(dāng)于對大量數(shù)據(jù)取平均值,同時平滑掉了因單個數(shù)據(jù)點(diǎn)的噪聲而導(dǎo)致的波動性[5]。因此選擇適當(dāng)?shù)膋值是非常重要的。
1.2 灰色關(guān)聯(lián)度
定義[6]設(shè)系統(tǒng)行為序列S=(s1,s2,…sm),以及

其中,ξ∈(0,1),稱為分辨系數(shù)。γh(k)=γ(sh,rhk)表示向量S的第k個分量與Rh第k個分量的關(guān)聯(lián)度,令

對所有的h=1,2,…,ti計算出γh,得向量:

這里,γh稱為Rh與S的灰色關(guān)聯(lián)度。
1.3 問題的一般描述
需要考慮的問題的一般描述如下:
設(shè)評分主體為某專家組,用集合E={E1,E2,…,Ek}表示;考核指標(biāo)用集合I={I1,I2,…,Im}表示;當(dāng)前被考核對象用集合A={A1,A2,…,An}表示。另設(shè)專家Ei有ti次歷史評分記錄,將評分值以及相應(yīng)的最后聚類結(jié)果制成表格。不失一般性,為了便于書寫我們此處將評分值的取值范圍定義為區(qū)間[1,10]上的整數(shù),基于評分值的聚類標(biāo)準(zhǔn)為:當(dāng)8≤rhj≤10時,指標(biāo)Ij歸屬于①類等級;當(dāng)5≤rhj≤7,指標(biāo)Ij歸屬于②類等級;1≤rhj≤4,指標(biāo)Ij歸屬于③類等級,評分值越高對應(yīng)的類越令人滿意,即①類優(yōu)于②類,②類優(yōu)于③類。根據(jù)上述規(guī)定,制作表1。將第u(u=1,2,…,n)個當(dāng)前考核對象的評分?jǐn)?shù)據(jù)制成表2。

表1 專家Ei歷史評分?jǐn)?shù)據(jù)

表2 第u個當(dāng)前考核對象評分?jǐn)?shù)據(jù)
則相應(yīng)的當(dāng)前評分矩陣為:

2 基于k-NN方法對當(dāng)前專家評分矩陣修正的算法和基本原理
2.1 算法的基本原理
為了修正當(dāng)前被考核對象的專家評分矩陣,首先我們利用關(guān)聯(lián)度來度量在每位專家的歷史評分?jǐn)?shù)據(jù)與其對當(dāng)前被考核對象Au評分?jǐn)?shù)據(jù)的相似度,并選出個數(shù)適當(dāng)?shù)淖钕嗨茪v史數(shù)據(jù),這樣做是因為利用最相似歷史數(shù)據(jù)而不是全部歷史數(shù)據(jù)來修正當(dāng)前專家評分向量,所得的結(jié)果將更趨于客觀、合理;其次我們構(gòu)造修正函數(shù),根據(jù)篩選出的每位專家的最相似歷史數(shù)據(jù)修正其當(dāng)前評分向量,從而得到修正的專家評分矩陣,繼而進(jìn)行評估。
2.2 算法
首先,根據(jù)關(guān)聯(lián)度來度量在每位專家以往的評分?jǐn)?shù)據(jù)與其對當(dāng)前被考核對象Au評分?jǐn)?shù)據(jù)的相似度。
由表1專家Ei的ti次歷史評分?jǐn)?shù)據(jù),我們得到ti個序列(即專家Ei的ti次歷史評分向量):

另外有專家Ei對被考核對象Au當(dāng)前評分向量:



根據(jù)要求取臨界值γ0,篩選出專家Ei的歷史評分?jǐn)?shù)據(jù)中與其對當(dāng)前考核對象Au評分向量最接近的數(shù)據(jù)。
經(jīng)過上述計算后對專家Ei可以得到ki個與當(dāng)前評分向量相近的歷史評分向量。這里我們借鑒k-NN方法對每個專家Ei利用關(guān)聯(lián)度從其過去的ti次評分記錄中找到與當(dāng)前評分最為接近的ki個評分;與其不同的是我們并不事先確定ki值,而是利用關(guān)聯(lián)度選擇適當(dāng)?shù)臄?shù)據(jù)后,得到ki的取值。根據(jù)k-NN方法對k值的考慮,我們得到ki值以后,根據(jù)其大小適當(dāng)?shù)男拚P(guān)聯(lián)度的臨界值,以保證ki值不是過大或者過小。設(shè)修正后ki調(diào)整為。將個數(shù)據(jù)按照取出的順序排列,仍記為仿照表1的做法,我們制作表3
由前文所述知,表3中元素(即評分值)的取值范圍是1到10的整數(shù),表中?是某次考核對某指標(biāo)經(jīng)專家組聚類評價后最后劃分所至的類,?的取值是①類、②類或者③類。
將規(guī)定的評分值(這里是1到10的正整數(shù))作為列,將規(guī)定的類作為行,以評分值在各類出現(xiàn)的次數(shù)作為元素,繪制成表4。例如表4中第一行第一列元素n1,1表示表3中評分值為1最后被分至①類的次數(shù),其他以此類推。
下面構(gòu)造修正函數(shù)。構(gòu)造函數(shù)時我們只考慮評分值規(guī)定的所屬類別與最終被劃分到的類別是相鄰的。因為實際情況下參加考核的專家具有較為豐富的經(jīng)驗,對評分的劃分標(biāo)準(zhǔn)有較好的把握,因此不同專家評分時一般不會出現(xiàn)對同一被考核對象給出差異懸殊的評分。構(gòu)造修正函數(shù)如下:
表3 篩選后專家Ei的個相似評分?jǐn)?shù)據(jù)

表3 篩選后專家Ei的個相似評分?jǐn)?shù)據(jù)
Ei I1 I2 Im REi 1 REi 2?r(i)11?r(i)21?r(i)12?r(i)22?r(i)1m?r(i)2m????REi-ki r(i)-ki1?r(i)-ki2?………?…r(i)-kim ?

表4 專家Ei相似評分?jǐn)?shù)據(jù)按類的次數(shù)分布

其中,對評分值s修正時s已經(jīng)確定,不作為變量存在于函數(shù)中,fs是對s修正后的評分值,Ns即表4最末一列的元素,即行元素之和,ns1、ns2和ns3為表4中的元素。





3 算法的一般步驟



4 算法實例
設(shè)有三個專家對被考核對象的四個指標(biāo)進(jìn)行評分,評分標(biāo)準(zhǔn)與前文一致:評分值的取值定義為在區(qū)間[1,10]上的整數(shù),基于評分值的聚類標(biāo)準(zhǔn)為:當(dāng)8≤sj≤10時,指標(biāo)Ij歸屬于①類;當(dāng)5≤sj≤7,指標(biāo)Ij歸屬于②類;1≤sj≤4,指標(biāo)Ij歸屬于③類(通常評分值越高對應(yīng)的類越令人滿意)。則專家組用集合E={E1,E2,E3}表示,被考核對象用集合A={A1,A2}表示;考核指標(biāo)用集合I={I1,I2,I3,I4}表示。先計算被考核對象A1修正的專家評分矩陣,依照同樣方法可以得出A2的修正評分矩陣。
專家E1,E2,E3對被考核對象A1關(guān)于指標(biāo)I1,I2,I3,I4的評分矩陣為:

表5、6、7中的第一行表示指標(biāo);第一列表示歷史數(shù)據(jù)的次數(shù)標(biāo)識;表中元素分為上下兩部分,上面部分是專家評分值,下面部分是最終該指標(biāo)被劃分的類。

表5 專家E1歷史數(shù)據(jù)

表6 專家E2歷史數(shù)據(jù)

表7 專家E3歷史數(shù)據(jù)


進(jìn)行計算(k=1,2,3,4;h=1,2,…,11)。取ξ=0.5,計算得




第三步,計算修正的專家評分矩陣。得到的向量個數(shù)為k1=5,歷史數(shù)據(jù)總數(shù)n1=11,則不需對k1進(jìn)行必要的修改。故根據(jù)篩選出來的歷史評分向量將表5縮減成表8。
將表8中出現(xiàn)的評分值作為列,將表8中出現(xiàn)的類作為行,以評分值在各類出現(xiàn)的次數(shù)作為元素,繪制成表9

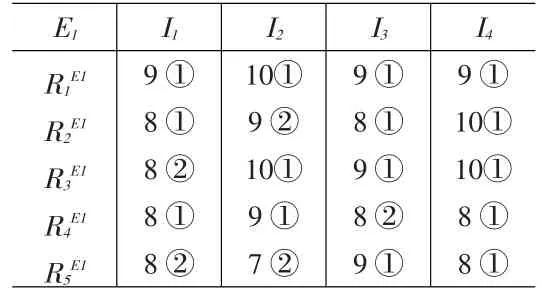
表8 專家E1歷史評分與S1的最相似數(shù)據(jù)

表9 專家E1相似評分?jǐn)?shù)據(jù)按類的次數(shù)分布
依據(jù)同樣方法,計算E2對A1的當(dāng)前評分向量S2=(7,9,8,9)的修正評分向量,關(guān)聯(lián)向量臨界值取γ0=0.8時k2=1,由于k2取值過小,調(diào)整關(guān)聯(lián)向量臨界值γ0=0.7,則k2相應(yīng)的調(diào)整為=4,修正評分向量為E3評分向量S3=(8,9,8,7)的修正評分向量,關(guān)聯(lián)向量臨界值取γ0=0.8時k3=1,由于k3取值過小,調(diào)整關(guān)聯(lián)向量臨界值γ0=0.5,則k2相應(yīng)的調(diào)整為=4,修正評分向量為
第四步,得到專家E1,E2,E3對被考核對象A1關(guān)于指標(biāo)I1,I2,I3,I4的修正的專家評分矩陣為:

專家E1,E2,E3對被考核對象A2關(guān)于指標(biāo)I1,I2,I3,I4的評分矩陣為:
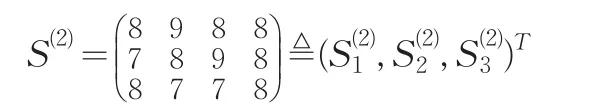
完全依照上面的處理方法,我們得到S(2)修正的專家評分矩陣:



顯然γ1>γ2,故被考核對象A1優(yōu)于被考核對象A2。
5 結(jié)語
基于k-NN對專家評分矩陣進(jìn)行修正,以消除專家評分時的主觀傾向(即習(xí)慣性偏高或者偏低)可以使得評估的結(jié)果更趨于客觀化、合理化。另外值得一提的是,利用本方法得出被考核對象之間的聚類系數(shù)更具有可比性。
[1]徐玖平,陳建中.群決策理論與方法實現(xiàn)[M].北京:清華大學(xué)出版社,2009.
[2]黨耀國,劉思峰.灰色綜合聚類[J].統(tǒng)計與決策,2004,(10).
[3]李宜敏,羅愛民,呂鳳虎.灰色聚類評估的一種改進(jìn)方法[J].統(tǒng)計與決策,2007,(1).
[4]王育紅,黨耀國.基于D-S證據(jù)理論的灰色定權(quán)聚類綜合后評價方法[J].系統(tǒng)工程理論與實踐,2009,29(2).
[5]K.P.Soman,Shyam Diwakar,V.Ajay.數(shù)據(jù)挖掘基礎(chǔ)教程[M].北京:機(jī)械工業(yè)出版社,2009.
[6]劉思峰,黨耀國,方志耕,謝乃明.灰色系統(tǒng)理論及應(yīng)用(第五版)[M].北京:科學(xué)出版社,2010.
猜你喜歡
課堂內(nèi)外·小學(xué)版(智慧數(shù)學(xué))(2025年2期)2025-02-28 00:00:00
童話世界(2020年10期)2020-06-15 11:53:22
當(dāng)代陜西(2019年13期)2019-08-20 03:54:18
當(dāng)代陜西(2019年12期)2019-07-12 09:12:02
當(dāng)代陜西(2019年9期)2019-05-20 09:47:40
輔導(dǎo)員(2017年18期)2017-10-16 01:14:51
影劇新作(2017年4期)2017-03-22 05:47:21
中國衛(wèi)生(2016年9期)2016-11-12 13:27:58
中國衛(wèi)生(2016年2期)2016-11-12 13:22:24
中國中醫(yī)藥現(xiàn)代遠(yuǎn)程教育(2014年11期)2014-08-08 13:23:44
