基于HNC理論和自動文摘的計算機輔助英漢科技翻譯模式
2012-10-29 10:21:46杜玲莉紀再祥楊繼唐
湖北工程學院學報 2012年6期
杜玲莉,紀再祥,周 宏,楊繼唐,王 俐
(1.武漢理工大學 外國語學院,湖北 武漢430063;2.武漢航海職業技術學院,湖北 武漢430062;3.武漢交通職業技術學院,湖北 武漢430062)
一、研究背景
HNC即概念層次網絡(Hierarchical Network of Concepts),它是黃曾陽創立的用于描述自然語言理解的理論框架。該框架以傳統國學研究和現代語言學研究成果為基礎,其核心目標是建立一種自然語言的計算機表述和處理模式,使機器能夠真正實現模擬人腦的語言感知功能。[1]它以語義表達為方向,著眼于深層次的理解,沖破了以前相關理論基于文本語言形式的句法分析思路的局限性,表達呈現出概念化、層次化和網絡化的特征。它面向整個自然語言理解,建立了強大而完善的語義描述體系。其內容涵蓋了語句處理、句群處理、篇章處理、短時記憶向長時記憶擴展處理、文本自動學習處理等方面。“在科學上為認知科學、語言學與人工智能的研究提供了一個全新的理論框架”[2]。HNC理論模擬人腦的認知機制,特色鮮明,在自然語言理解領域獨領風騷,因其在計算機理解人類自然語言方面開拓出的新路子而成為了國內目前自然語言理解和處理的三大流派之一。
該理論將人腦的認知結構劃分為局部和全局兩個聯想脈絡,而語言深層(即語言的語義層面)的根本問題正是對聯想脈絡的表達。根據HNC理論,全球6000多種人類的自然語言之所以能相互理解并翻譯,是由于人類大腦中存在著一個概念空間,這正是人類賴以認識世界和進行思維活動的基礎。而作為整個概念空間中的一個子空間,語言概念空間與自然語言的理解以及運用都息息相關。雖然自然語言空間呈現出多種多樣的形態,但人類卻有著共同的語言概念空間。兩者相互對應,構成果與因、流與源的關系。前者是后者的外在表現形式,兩個空間之間存在著多對一的映射關系。HNC理論認為人類語言之間的翻譯可以解釋為將一種自然語言空間映射到另一種自然語言空間的過程。該過程可分為兩個階段:第一階段由源語言向HNC語言概念空間映射,源語言的語詞和語句將分別映射為HNC概念以及句類表示符號;而在第二階段中,語言概念空間將向目標語言進行反映射,即源語言中的HNC概念和句類表示符號反映射到目標語,成為目標語中的語詞和語句(如圖1所示)。[3]
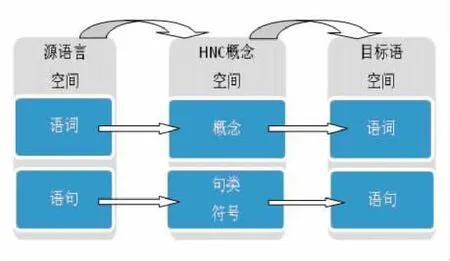
圖1 HNC語言空間映射模型
在這個模型中,第一部分即是源語分析過程或翻譯理解過程,而第二部分則是目標語的生成過程或翻譯的形成過程。兩者的中間存在一個過渡處理過程,即運用HNC概念和符號表述的過程。它包含句類轉換和語句格式轉換,即從語義塊感知來辨識句類,并對句類進行假設,然后依據句類先驗知識對語義塊的構成作進一步的分析,并據此來對語句中存在的發音模糊、音詞轉換模糊、詞的多義模糊、語義塊構成的切分模糊、指代冗缺模糊等進行消解,涉及語義塊構成變換、語義塊主輔變換以及輔塊和小句的排序調整等。這一系列的過渡處理是生成高質量翻譯的必要條件。
多年來,諸如中心動詞的辨識、語序的確定、詞義模糊、未登錄詞的識別等這些困擾漢語理解和人工語言處理的多個難題終于在HNC理論的句類分析方法中找到了解決方案。有了句類分析對源語正確理解為前提,如何進一步提高翻譯的精度和質量則依賴于對反映射知識庫的更廣泛和深入的挖掘。
二、問題描述
科技文獻因其強烈的專業性而對翻譯的有效性提出了較高要求。科技翻譯研究也走過了基于規則、基于實例、基于統計的不同階段。關于文本理解的研究對象和表述,從語詞、語句,再到語篇,語言學和人工智能學界多年來爭論不休,語篇語義的理解和表達成為了相關研究的瓶頸。那么,如何從語篇角度更全面地理解文本,從而有效提高翻譯時效和質量。
長期的語言智能和翻譯實踐表明語篇的理解不等同于語詞或語句意義的簡單相加。如果說HNC理論中語義塊概念為此提供了理論支持,那么自動文摘技術則為這一問題的解決提供了現實有效的途徑。自動文摘就是利用計算機從原始文獻中自動地提取文本的主要內容。面對信息時代大量的科技文獻,對其進行快速提煉和濃縮是提高信息資源獲取效率的有效手段。這一技術實際上將文本語義的理解和表述推向了極致。筆者大膽設想,科技文本翻譯可以從這里起步。這樣做的好處在于:借助相關技術,不僅翻譯工作者可以大大提高翻譯理解階段的準確度和效率,而且為機器翻譯領域研究減少部分因復雜的語言深層結構分析所耗精力。
自動文摘研究在過去50多年發展歷史中吸引了世界上許多國家的學者投入研究,其領域橫跨了計算機科學、人工智能、情報科學和語言學等多個學科,并取得了很大的進步。目前這方面的研究已形成了一定的理論與方法,其中,基于句子概率統計、文本結構、領域理解、信息抽取和四種自動文摘技術成為了主流方法。它們共同的設計理念都離不開對自然語言的分析和技術處理兩部分。這四種主流自動文摘技術應用中的技術難度、應用領域、生成的文摘質量方面各有優劣,因此不少學者提出建議——采用一種綜合式的面向非受限領域的自動文摘方法,既要從微觀上考慮文本的表面結構,又要從宏觀上把握篇章結構特征。即文本形式特征將作為衡量文章中句子權值的基本方法,用篇章結構分析替代深層的語義分析,從而避免機械抽取文摘內容會遺漏的問題,最后引入句法和語義分析,對所抽取文摘句進行可讀性的潤色加工,解決文摘簡潔性和連貫性不足的問題。目前,較新的研究成果就來自這種綜合式的思路。
三、翻譯模式設計
根據HNC理論和自動文摘技術,科技文獻新的翻譯模式設計如下(見圖2):
1.文獻理解。首先,使用ParaConc對待譯科技文獻(Ts)進行預處理——分詞處理,得到用于建立文摘的向量空間模型(VSM)的段落和詞。[4]采用向量空間模型將文本的篇章結構進行自動分析,根據語義相似度建立段落間的關系圖,該段落與主題的關系就是段落的重要度,提取各段落的重要度信息,使用標題或聚類的方法將意義相近的段落歸納為同一語義塊;依據文本中詞的頻度、句子位置、提示語等形式特征計算語義塊的權值,分別從各語義塊中提取權值較高的句子作為文摘句;從句法和語義兩方面對提取的文摘句進行分析,解決諸如指代詞不明、表述冗余、詞句不連貫等問題,最終的文摘將具備簡潔、通順、可性讀強等特點。[5]
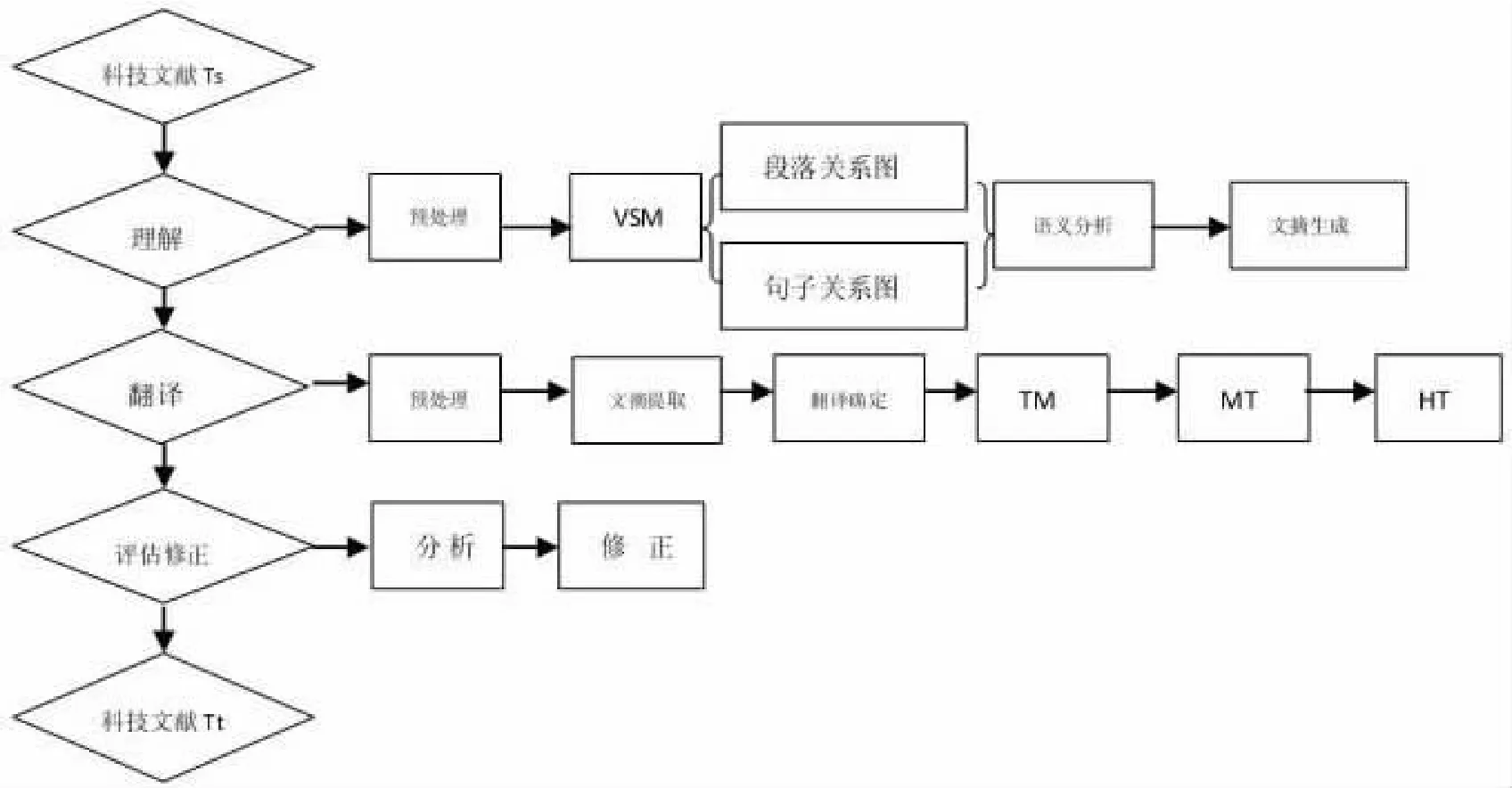
圖2 科技文獻翻譯模式圖
2.計算機輔助翻譯(Computer Assisted Translation,CAT)。將文獻理解階段所獲文摘進行中心句和關鍵詞提取,使用Yaxin或Trados等機輔翻譯軟件進行翻譯前預處理,檢索并確定中心句和關鍵詞的譯法,利用語料對齊技術將確定后的雙語對應翻譯文本導入相應的雙語數據庫;使用翻譯記憶庫(Translation Memory,TM)進行機器預翻譯(Machine Translation,MT),得到初步的由源文本(Ts)映射到目標語的翻譯文本(Tt);然后進行最后也是最關鍵的由翻譯人員進行的細致的修正過程(Human Translation,HT),從而得到翻譯初稿。修正涉及詞語、句法、語篇等各個層次,特別是語際分詞錯誤、歧義、固定習語等機器翻譯的盲點。
3.評估修正(Evaluation &Correction,EC)。對翻譯譯文的評價,如果通過人工實現則人為因素影響很大,并且對評價人員的要求也很高,不僅實現起來困難,而且還導致了評價標準的不一致。于是設計自動化、規范化的評價方法便成為許多學者的研究目標。各種研究成果紛呈,基本設計方向是從TM語料庫中獲取翻譯知識,建立n元語言模型,在此基礎上為譯文的任意句子評分。[6]
根據HNC理論,語際翻譯實際上就是一個從源語言到目標語的概念映射過程,所以系統評估的標尺是語際映射的速度和準確程度。映射規則的復雜程度決定了映射的速度,而準確程度的評估參照物則是通過比對機輔翻譯文本與專家翻譯文本的相符度。兩個文本越相近,翻譯質量就越高。這里包含了評估系統的兩個重要指標:準確率和召回率。
召回率是指所有機輔翻譯Tt與所有待譯的文本數的比率,其表達式如下:
召回率(Recall)=機輔翻譯Tt中正確翻譯句子數/所有待譯的句子數
準確率是指所有機輔翻譯Tt中與專家翻譯的文本相吻合的句子所占的比率,其表達式如下:
準確率(Precision)=機輔翻譯Tt中正確翻譯句子數/專家翻譯的句子數
召回率和準確率是評估翻譯質量的兩個重要方面,必須將兩者進行綜合考慮。
此外,Neubert等將語篇內部和外部屬性具體概括為七個方面:意向性、可接受性、情景性、信息性、互文性、連貫性和銜接性。[7]建立評估模型時,文本語篇層面的這些重要特征可作為相應參數,并可根據不同類型的Ts調整各參數的權重。
四、試驗驗證
為檢驗該模型的可行性,筆者分別從PNAS(Proceedings the National Academy of Science of the USA)和中國知網上隨機抽取了24篇專業期刊文章進行了對照實驗。其中,自然科學類(涉及生物、化學等專業)和人文類(包括管理、教育等專業)各占50%,中英文各50%。對照組為掌握自動文摘(AA)生成和計算機輔助翻譯軟件的翻譯者以及普通的翻譯者。試驗方式是將24篇文章給3組被試分別用傳統方式(Tr)、計算機輔助翻譯方式(CAT)、文摘自動提取加計算機輔助(AA+CAT)模式各自進行翻譯。并將所譯文檔建成小型數據庫,分析結果如下(h/p:小時/篇):
表1
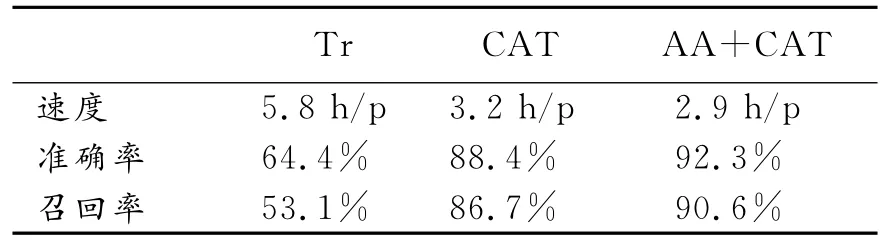
表2
五、結 論
通過比較,發現AA+CAT模式在準確率和速度方面與其他模式相比有明顯優勢,召回率與CAT模式區別不大,但比Tr模式改善不少。說明從整體效率而言,計算機輔助翻譯比傳統翻譯方式先進,而采用自動文摘技術對文本進行譯前處理又比單純使用計算機輔助翻譯技術的效率有所提高。當然,這一結果也可能因被試的專業背景和掌握相關技術的熟練程度等因素而受影響。另外由于條件限制,試驗樣本范圍有限,代表性有待進一步驗證。
[1]黃曾陽.HNC理論與自然語言語句的理解[J].中國基礎科學,1999,1(2):83-88.
[2]許嘉璐.現狀和設想——試論中文信息處理與現代漢語研究[J].中國語文,2000(6):491.
[3]張克亮,基于HNC理論的漢英機器翻譯策略研究[J].解放軍外國語學院學報,2003(5):60-64.
[4]郭王箐,萬敏.面向非受限領域的綜合式自動中文文摘方法[J].清華大學學報:自然科學版,2002,42(1):7-9.
[5]錢多秀.計算機輔助翻譯[M].北京:外語教學與研究出版社,2011:139-142.
[6]張劍,吳際,周明.機器翻譯評測的新進展[J].中文信息學報,2003,17(6):1-8.
[7]Neubert A,Gregory M S.Translation as Text[M].Kent:Kent State University Press,1992:117.
猜你喜歡
當代陜西(2022年5期)2022-04-19 12:10:18
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:28
湘潮(上半月)(2021年4期)2021-07-20 08:05:28
汕頭大學學報(自然科學版)(2020年4期)2020-12-14 07:05:00
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
