Web文本挖掘在智能分類中的應用
2013-08-16 06:19:32張黎黎
山東工業技術 2013年11期
張黎黎
(長春工程學院,吉林 長春130012)
1 文本挖掘概述
文本挖掘,又稱為“文本數據挖掘”或“文本知識發現”,是從文本數據中抽取隱含的、未知的、潛在且有用信息的過程。它是個分析文本數據、抽取文本信息,進而發現文本知識的過程。文本挖掘的出現為文本信息的整理、分析、挖掘提供了有效手段[1]。
文本挖掘的主要目標是獲得文本的主要內容特征,如文本的主題、文本主題的類屬、文本內容的濃縮等。文本挖掘主要有特征抽取、文本分類、聚類等技術。從提取特征值作為起始點,將自然語言文本自動分配給預定義的類別,利用文本特征向量對文本進行分類,再將一個數據對象的集合分組成為多個類或簇,從而產生類標記。
2 Web 文本挖掘
Web 文本挖掘是指使用中心詞匯來表示文檔的方法。利用給出求取中心文檔和中心詞匯的算法[2],對Web 上大量文檔集合的內容進行總結、分類、聚類和關聯分析,亦可利用Web 文檔進行趨勢預測。
Web 文本挖掘過程中[3],關注的是信息元素本身的內容與意義,是以文本、圖片、音頻、視頻或者結構記錄等信息內容為對象,從中挖掘知識內容和語義關聯模式。
Web 文本挖掘是通過HTML 文檔進行信息的采集,將分布在Web 服務器上的待挖掘文檔集成在本地文本庫中提取有用的Web 文本信息。然后,采用基于詞典的逐字二分查找方法自動分詞。采用向量空間模型和語義檢索技術表示文本,采用評估函數X2統計法對文本的名稱、類型、大小等特征進行提取。Web 文本挖掘流程如下圖所示:
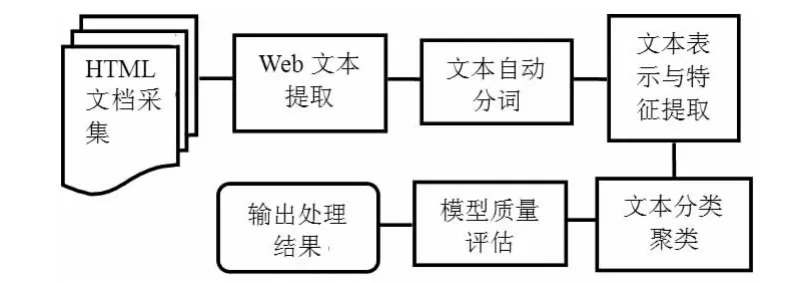
圖Web 文本挖掘的基本流程
3 文本分類常用算法
文本分類的算法有很多種,其中最常用到的是TFIDF 方法和Naive Bayes 算法。TFIDF 的主要思想是:如果某個詞或短語在一篇文章中出現的頻率高,并且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力。TFIDF 方法傾向於過濾掉常見的詞語,保留重要的詞語。
Naive Bayes 算法是以闕值大小對文本數據進行劃分[4]。利用:
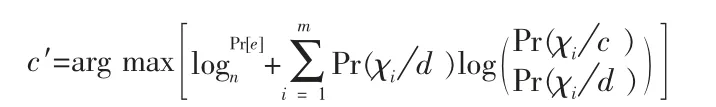
其中,χi指C 類文檔第i 個特征,Pr(χi/d )是從C 類文本中得到特征詞χi的概率,Pr(χi/d )是從文本d 中得到特征詞χi的概率,n 指d 中詞的個數,m 是系統詞典的大小。若所得闕值大于預先設定的值,則認為文本d 屬于C 類別,否則不是。
從概率的大小來研究,Naive Bayes 算法可描述為: 設文檔d 的文檔向量的分量為相應的特征詞在該文檔中出現的頻度,則d 屬于C 類文檔的概率公式為:
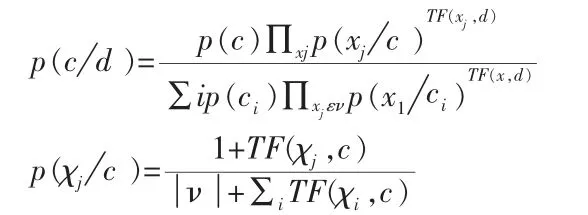
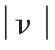
4 實例說明
利用Naive Bayes 算法,通過對用戶提交信息的關鍵字的提取,對專利信息進行智能歸類。
現假設已經對用戶提交信息提取完畢,形成的樣本為: 發明、請求、權利。且已事先給定一組分好類的文本作為訓練數據(如表1),完成對新樣本的分類。

表1
如上所述,該文本用屬性向量表示為d=(發明、請求、權利),類別集合為Y={發明專利、外觀專利}。
類“發明專利”下總共有5 個詞語,類“外觀專利”下總共有3 個單詞,訓練樣本單詞總數為8,因此P(發明專利)=5/8,P(外觀專利)=3/8。類條件概率計算如下:
P(發明|發明專利)=P(權利|發明專利)=P(請求|發明專利) =(1+1)/(5+)=2/8
P(發明|外觀專利)=P(權利|外觀專利)=(0+1)/(3+)=1/6
分母中的5,是指“發明專利”類別下文本長度,也即訓練樣本的單詞總數,3 是指訓練樣本有:發明、請求、權利共3 個單詞,是指“外觀專利”類下共有3 個單詞。
有了以上類條件概率,開始計算后驗概率:
P(發明專利|d)=2/8×2/8×2/8×5/8=5/512≈0.0097656
P(外觀專利|d)=1/6×1/6×2/6×3/8=2/1728≈0.0011574
比較大小,即可知道這個文檔屬于“發明專利”類別。即將專利信息都歸屬到“發明專利”類別下,從而減少了人工操作選擇。
5 結束語
Web 文本挖掘有利于文本特征項的提取和特征縮減,Web 的文本分類算法對Web 文檔的自動分類有極高的參考價值,對Web 文本挖掘有一定的指導意義。然而,對Web 文本的智能分析涉及Web 數據自動采集、Web 數據自動分析、統計分析、數據挖掘和人工智能以及復雜社會網絡等技術,是一個復雜過程。
[1]張群.文本挖掘技術及其在專利信息分析中的應用[J].現代情報,2006(3):209-21.
[2]王繼成.Web 文本挖掘技術研究[J].大理學院學報,2011(4):513-520.
[3]張玉峰,何超.基于Web 挖掘的網絡輿情智能分析研究[J].實踐研究,2011(4):64-68.
[4]王一蕾,林世平.Web 文本挖掘三種技術的比較[J].福建電腦,2003(12):20-21.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
