知識社區環境下的DBpedia研究
2013-08-21 08:36:38
圖書館 2013年4期
(北京大學信息管理系 北京 100871)
知識社區的概念源于知識管理。網絡環境下,知識社區可理解為:由于部分人對某個主題的共同興趣和知識獲取、交流需求而聚集起來,并基于網絡創造和分享知識的平臺。維基百科作為開放、自由、免費、共享的多語言網絡百科全書,由全球網民共同編寫,正是知識社區的產物。然而維基百科的條目多以自然語言描述,只支持文本檢索而不支持結構化檢索,也無法跨頁面進行檢索,導致其中雖然蘊含海量信息,卻無法被深度挖掘利用。
語義網作為萬維網的延伸,利用XML、RDF、本體、OWL等技術,使其中的信息都具有定義完好的含義,通過機器可“理解”的語義,讓計算機擁有一定的推理能力和自動處理大規模數據的能力。因此,利用語義網技術挖掘維基百科內容的項目不斷展開,DBpedia就是其中一項。
1 DBpedia簡介
DBpedia由柏林自由大學和萊比錫大學的研究人員發起,與OpenLink Software公司合作,致力于從維基百科的結構化和半結構化信息中抽取數據并生成RDF三元組,將其組織后形成龐大的數據集,與外部的關聯數據連接,提供給人們使用。〔1〕該項目也被“互聯網之父”蒂姆·伯納斯·李盛贊為關聯數據工程中最知名的項目之一。
2007年2月,DBpedia數據集開始開放下載,之后每隔約半年時間都會有更新。最新的版本為2012年8月發布的DBpedia3.8,該版本數據集中描述了超過377萬個資源,其中235萬個資源使用統一的DBpedia本體進行描述,包括76.4萬個人物,57.3萬個地點,11.2萬張音樂專輯,7.2萬部電影,1.8萬種視頻游戲,19.2萬個組織機構(包括4.5 萬家公司、4.2萬所學校),20.2萬個生物物種和5500種疾病。DB-pedia用111種不同的語言以RDF三元組的形式為上述資源做了摘要和詳細的描述,其中有800萬條指向圖片的鏈接、2440萬條指向其他Web頁面的鏈接、2720萬條指向其他RDF 數據集的鏈接。〔2〕
DBpedia的目標是從維基百科中抽取結構化信息并開放下載,與其他數據集互聯而形成知識網絡。如今該目標正在逐步實現,由于DBpedia的跨領域、多語言等特征,DB-pedia自發布后便與諸多數據集互聯,成為關聯數據網的核心。基于該數據集的應用也愈來愈多,漸漸滲入社會生活各個方面。
2 知識社區環境下DBpedia的信息組織
2.1 基于維基百科的信息抽取
信息抽取是指從文本中抽取出用戶感興趣的信息,包括實體、事實等,并以結構化的形式存儲起來,即將非結構化的數據轉換為語義信息。〔3〕維基百科中蘊含大量的信息,單靠人力不可能完成對其內容的抽取整理,因此必須依賴大規模的人機協同進行處理。
DBpedia通過知識抽取框架(DBpedia Knowledge Extraction Framework)抽取維基百科中的標簽、摘要、語言鏈接、圖片等數據項,該框架的技術基礎由項目組提供,普通參與者亦可改進和完善。知識抽取框架從維基百科中抽取信息主要采用兩種方式,其一是利用維基百科的數據庫轉儲文件,將其關系數據表格中存儲的關系直接轉換為RDF三元組;其二是利用維基百科的文章內容及信息盒模版抽取RDF三元組。〔4〕從維基百科的文章內容中抽取信息時,既可以從部分非結構化的文本中抽取,也可以從半結構化的部分及條目內部的鏈接結構中抽取。其中主要的信息抽取來源如下圖:
圖示抽取源所含的信息都有較高的挖掘價值,且易于抽取,將這些信息抽取整理后能夠進行更深層次的挖掘,從而得到更多有價值的信息。
目前DBpedia支持定時抽取和實時抽取兩種抽取模式,前者以一個月為周期,后者可以動態監測維基百科頁面,當數據內容有變化時,編輯者只需在維基百科中進行數據修改,就可以同步到DBpedia中。
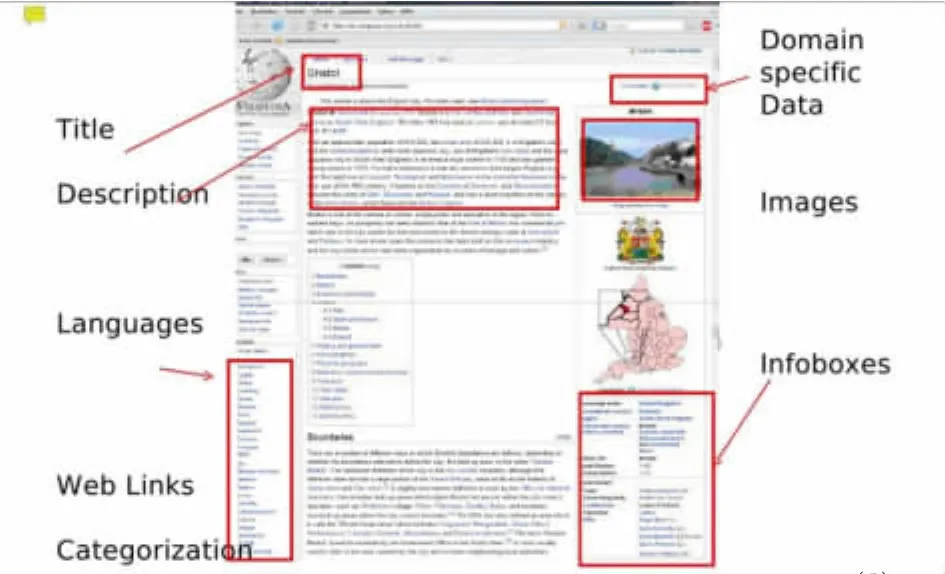
圖1 DBpedia從維基百科抽取數據的信息源圖解〔5〕

表2 DBpedia從維基百科抽取數據的信息源詳解
2.2 DBpedia中的資源描述和組織
用RDF描述事物的基本思想是:將一切可以在萬維網上標識的事物(具體的或抽象的,存在的或不存在的)統稱為“資源”;用URI(統一資源標識符)表示資源;用屬性和屬性值描述資源,其中屬性值可以包含URI,屬性也是一種資源。〔6〕
維基百科中的每個條目在DBpedia中都擁有唯一的URI,與其頁面鏈接地址相對應,形式為http://DBpedia.org/resource/Name,其中Name部分是從該資源的英文版維基百科的鏈接地址 http://en.wikipedia.org/wiki/Name中抽取的。這種方式使得該資源直接與英文版維基百科的條目頁面聯系起來。〔7〕
DBpedia中的每個資源都有標簽、英文短摘要和英文長摘要、相應的維基百科頁面鏈接和描述該資源的圖片鏈接等屬性。除了以上基本屬性外,不同類型的資源通過不同的屬性描述,這些屬性不僅限于DBpedia所定義的,還可以引用其他本體或數據集中定義的,如FOAF、dc、RDF以及owl等。引用外部定義屬性的優勢可以彌補DBpedia屬性定義的不足,更加完善地描述資源;缺陷在于,多處引用容易造成屬性的重復,進而造成數據冗余。由于DBpedia涉及的資源多種多樣,如何對某一類資源引用合適的外部屬性也是DBpedia需要解決的問題。
通過精確細致的屬性描述資源后,用戶查詢時得到的不再是整個頁面,而是精確的答案。通過設定規則,為后續的自動推理和進一步數據挖掘提供了極大的便利。在DBpedia中,用RDF描述得到的實體通過本體和分類體系進行組織。DBpedia數據集的本體庫是從維基百科信息盒中抽取并組織而成的,包括170個類和720個屬性,是個淺層的分類體系。但該分類并不完善,因此DBpedia還使用了另外三種分類方法對資源進行組織,分別是:維基百科分類方法、YAGO分類方法和UMBE分類方法。〔8〕
維基百科的分類體系包含了415000個類目,該體系支持協同擴展并可以持續更新。但由于其編輯維護者為長尾用戶,在分類體系的設置上權威性欠缺,類目的等級關系以及橫向關系揭示方面也不完善。YAGO分類體系包含286000個類目,其特點是類目劃分較深、較精確。UMBEL是一個輕型本體,包括20000個類目,該本體是為鏈接Web中的內容和數據而創建。
2.3 DBpedia的信息獲取途徑
2.3.1 SPARQL 端點檢索
SPARQL是一種面向RDF數據模型的查詢語言和數據訪問協議,用于訪問任何可以映射到RDF模型的數據資源。為了實現對DBpedia的查詢,開發者提供了SPARQL終端,用戶可以利用SPARQL語言在http://DBpedia.org/sparql進行檢索,直接得到相應的數據。例如查詢某條河流的長度,系統會直接返回其長度作為答案,而不是返回河流相關頁面再讓用戶到其中篩選信息。用戶也可以檢索較復雜的問題,例如“從1990至1920年期間出生在北京的姓李的女作家”這個問題,經過正確的SPARQL語言組織后,系統即可匹配并返回結果。
然而鑒于大多數用戶并不熟悉SPARQL語言,因此該系統的友好易用性欠缺。為了使普通用戶也能夠在DBpedia上進行查詢,可以借助一些工具如 Auto SPARQL,用戶只需鍵入所要查詢的關鍵詞并指定所查找的屬性,檢索工具會自動轉換為SPARQL語言并將結果反饋給用戶。
2.3.2 關聯數據接口
關聯數據在2007年提出,目的是構建計算機能理解的語義數據網絡,而不僅僅是人能讀懂的文檔網絡,也就是把文檔的網絡變成數據的網絡,基于此構建更智能的應用。〔9〕DBpedia自與其他數據集互聯以來,由于其跨領域的特點而處在關聯數據網的核心。基于各個數據集間的互聯,用戶在數據集之間游歷,一旦涉及DBpedia中的數據,自然會通接口進入其中。
在2007年,加入關聯數據網的數據集共有16個,其中10個數據集與DBpedia相連接。到2011年,加入關聯數據的數據集增長更迅速,而DBpedia儼然已經成為整個關聯數據網中的核心。用戶可以通過大其他數據集進入DBpedia,也可通過DBpedia連接到其他數據集,DBpedia作為關聯數據中轉站的特征也更明顯。
2.3.3 下載RDF文件包
DBpedia的數據集是對公眾開放并可以免費下載的,DB-pedia的下載頁面列出了DBpedia的所有版本,并標出各版本的最后修改時間及其大小,用戶點擊相應的版本即可進入下載頁面。在最新的DBpedia3.8中,共提供了111種語言版本的數據集,每個數據集中有不同的數據包,列出相應語言的標簽信息、映射關系信息以及維基百科信息盒中屬性等數據包供用戶下載,用戶可根據自己的需求有選擇地下載或全部下載。
3 DBpedia的特點
3.1 協同編輯
知識社區環境下,DBpedia的一大特點就是協同編輯,由眾多的用戶共同完成數據集創建和維護。在數據集的建設過程中,除了數據源于維基百科,是大眾共同編輯的成果外,其知識抽取框架、映射關系定義、本體維護等技術也并非項目組獨立的成果,而是在項目組提供的基礎框架上,經過許多人參與并貢獻智慧后的成果。DBpedia能夠成為大規模、跨領域、多語言的知識庫,與其協同編輯的基本特征密不可分。
3.2 數據結構化
DBpedia區別于維基百科之處在于其數據描述的結構化,即用以描述資源的每個屬性都是經過定義的,可被機器理解。描述資源的RDF三元組形式為“資源—屬性—屬性值”,以屬性作為資源和屬性值之間的聯系,通過簡單的三元組結構實現良好的組織,便于后續的數據利用。在有良好結構的數據基礎上,通過定義一定的規則,可以實現機器自動推理。推理是使用預先定義的規則基于知識庫中存儲的事實信息獲得額外的、潛在的知識。例如,預先定義“擁有相同父母的兩個男性為兄弟”,那么在描述資源時,如果A和B的父母關系的屬性值相同,則可以自動得出A和B是兄弟的結論,并自動將A的兄弟關系屬性值賦值為資源B,B的兄弟關系屬性值賦值為資源A,從而建立聯系。同時,如果定義了出生年份更早則為兄長的規則,那么就可以根據兩者的出生年份自動得出其長幼順序。
3.3 大規模人機協同知識處理
在基于語義Web的知識處理過程中,人機協同知識處理強調人與計算機的分工與合作,通過人對知識處理前端控制,降低計算機知識處理的難度,在人與計算機之間尋找最佳的協同狀態。〔10〕DBpedia從維基百科中抽取海量數據,是個規模龐大的工程,單靠人力無法實現,必須借助機器的協助。然而機器本身智能程度有限,知識抽取框架的建設、知識間的映射關系的定義均需要發揮人的智慧,而機器可以據此自動完成重復性的工作,從而發揮了計算機對結構化程度較高的數據的重復操作能力。
維基百科的數據是不定期更新的,在預先定義出檢測和驗證規則后,DBpedia可以按照一定的時間間隔、有針對性地檢測對應的內容,如果有數據變化,則更新入數據集中。維基百科中的數據更新,則是依靠無數的編輯者進行的,通過人與機器的協同處理,完成數據集的更新和維護。
3.4 跨領域知識庫
DBpedia所描述的數百萬個資源中,內容涉及人類社會生活中所能涉及的幾乎所有領域,目前涉及人物、地點、音樂、電影、游戲、組織機構、生物物種、疾病等多個方面,這些屬于不同類別的實體又是相互關聯的。即DBpedia所描述的實體不僅跨越多個領域,并且在這些領域之間建立了聯系,隨著其技術的日漸完備和規模的不斷擴大以及越來越多志愿者的參與和貢獻,DBpedia所能涵蓋的范圍勢必會延伸至越來越多的角落,并不斷在各個實體間建立聯系,最終形成一張知識網絡。DBpedia的這一特征使得它與其他的領域本體和目前發布的數據集都有了交集并與之相連,從而成為關聯數據的核心,成為不同數據集之間鏈接的中轉站。在日后的相關應用開發和數據深度挖掘中,它的中轉站功能將不可忽視。
4 基于DBpedia的應用
4.1 為語義網應用服務提供數據支持
DBpedia的數據集可以授權給第三方使用,從而簡單、快速地衍生出眾多創新性應用,被美國科技媒體Read Write Web評為2009年最佳的語義網應用服務。
目前基于DBpedia開發的應用中比較典型的是DBpedia Mobile。DBpedia Mobile是一個基于DBpedia中的地理位置數據作為導航的客戶端服務。基于現有的GPS定位功能,用戶可以搜索、發布和標注某個地點的信息,并查看其它用戶對周圍環境的標注。由于DBpedia與其他數據集互聯,用戶有可能因此而進入一個更細致、針對性更強的數據集,從而得到更全面的信息。當然,僅靠DBpedia不可能完全滿足用戶的需求,只有越來越多的數據集發布并加入關聯數據網,才可以在該網絡中實現無縫隙游歷。
DBpedia的數據也可以整合入Web頁面中,例如從DBpedia查詢得到一個數據表后,可以通過客戶端將此數據表嵌入到用戶的頁面中并實現動態更新。目前正在進行的與之相關的應用是BBC interlinking project,該項目在DBpedia數據集和BBC的海量新聞信息間建立聯系。例如,當BBC中出現關于某個音樂家的新聞時,BBC可以基于DBpedia提供該音樂家的基本信息如圖片、個人資料、所發布的音樂專輯等。此外,BBC的新聞也可以通過DBpedia與對應的維基百科頁面進行互聯,例如當BBC中有關于某個城市的新聞,維基百科中對應城市的詞條頁面則可嵌入該新聞,讓用戶在查看詞條的同時了解其最新信息。
DBpedia的海量數據也值得發掘,從而創造出更多知識。例如DBpedia Relationship Finder就是典型的基于DBpedia的數據挖掘與知識發現系統,它可以通過DBpedia計算在英文維基百科中描述的兩個事物之間的語義距離。〔11〕
4.2 對維基百科的查詢
DBpedia的結構化數據源于維基百科,因此可以提供更準確和更直接的維基百科搜索,用以更好地發掘其中的資源。目前檢索界面如下:
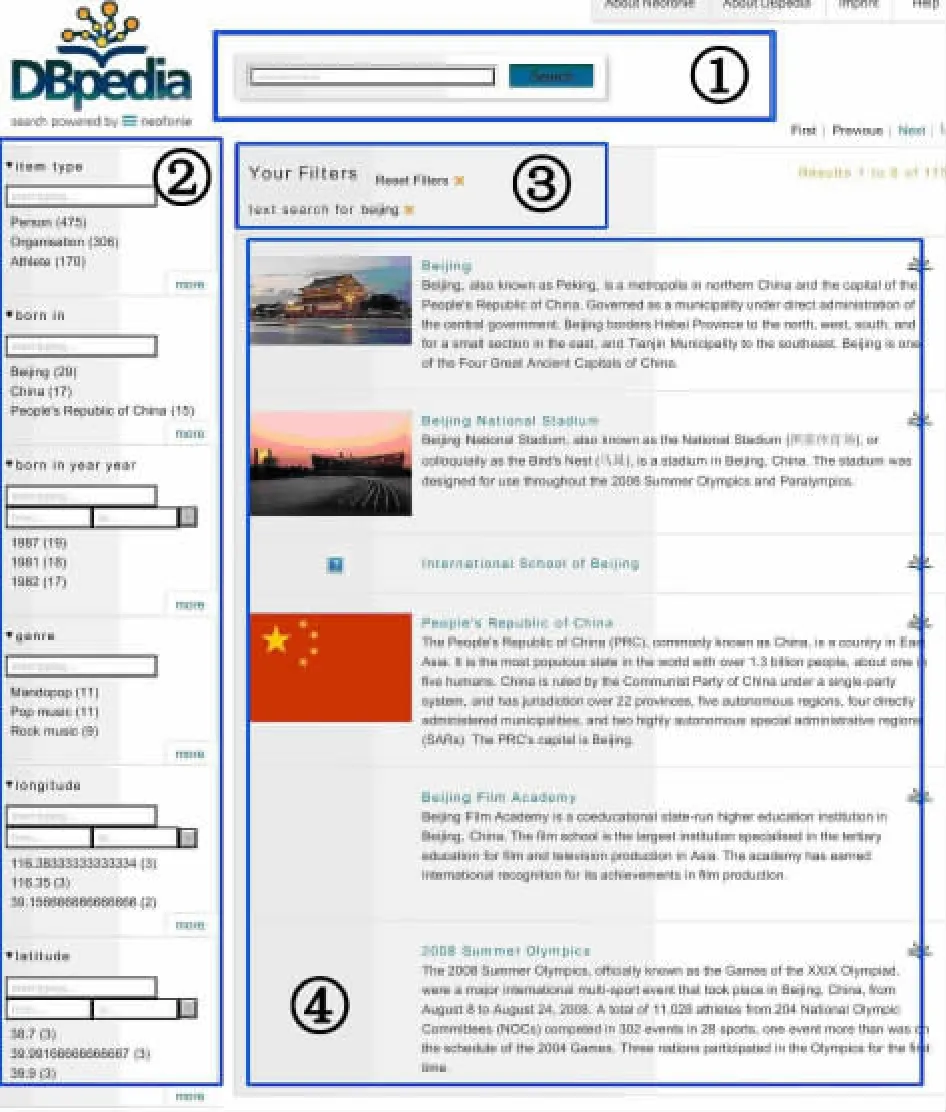
圖2 基于DBpedia的維基百科結構化查詢界面
該檢索界面主要包含四個模塊:用于自由檢索的文本檢索框(圖中①)、用于結構化檢索的部分(圖中②)、用于剔除檢索限定條件的部分(圖中③)、用于呈現檢索結果的結果顯示部分(圖中④)。用戶可以直接在文本檢索框中進行檢索,也可通過結構化檢索部分進行篩選,并不斷限定條件壓縮范圍,直至最后得出檢索結果。
當用戶有明確的檢索詞時,可以在文本檢索框中輸入檢索詞自由匹配,系統會判斷檢索對象的屬性并在左側的結構化檢索部分予以調整,方便用戶的后續甄選。例如檢索“Beijing”一詞,搜索結果包括與“beijing”相關的人物、地點、機構、組織等多種資源。此時,左側結構化檢索部分會陳列出人物、地點等相關的屬性供篩選,用戶可以做更為細致和精確的條件限定,從而縮小檢索范圍。檢索得到的結果按照被引用次數、詞條質量等綜合排序,列表中會展示詞條的縮略圖、題名、英文摘要。在用戶沒有明確的檢索詞時,可通過層層篩選接近目標,例如檢索“1960至1975年之間出生在北京的藝術家”,可在左側的結構化檢索框中選定目標類型為person,甚至更精確地選擇artist,系統經篩選后列出與artist相關的屬性,用戶只需限定出生地和出生時間即可得到想要的結果集合。
5 DBpedia的意義
5.1 基于知識社區建立大規模知識庫
DBpedia的數據抽取和更新依賴于Wiki這個協作共創的系統,該系統下眾多的長尾用戶所創造的知識涵蓋各個領域。其中內容包羅萬象,經過發展積累后,規模已非常龐大,并在不斷發展。DBpedia從中抽取有用信息并整理為知識庫后,不僅得到了大規模的數據,同時利用分類、本體以及內部互鏈等形式揭示了知識間的關系。DBpedia不僅具有大規模、跨領域、多語言的特征,其中的數據也是客觀公正、及時更新的。每個用戶既是讀者,也是監督者和糾錯者,一旦發現數據更新不及時,或觀點有失偏頗、內容不準確,都可以基于維基百科進行討論和修改。
5.2 多元應用為社會提供便利
DBpedia的出現為人們開發各種應用提供了便利,如前所述的DBpedia Mobile等項目已開創了良好的先例。在信息技術飛速發展的今天,各種各樣的技術應用繽紛呈現,使得人們的社會生活越來越便利。DBpedia中的數據涵蓋社會生活中的方方面面,依托這個龐大數據集的支撐,勢必能夠有更多應用出現。目前國外已經有許多政府和組織機構發布了相關的數據集,涉及地理、媒體、出版物、政府信息、生物科學等諸多方面,依托這些數據集的支撐和作為中介的DBpedia,可以開發涵蓋各個領域的應用,例如可以綜合正在建設的中藥本體和DBpedia可以開發簡單實用的中藥小百科,供日常使用。
5.3 推動語義網發展
語義網自從被提出后,在國際上已掀起了一輪研發熱潮,它的提出也為信息組織的發展提供了新的方向,其三大核心技術XML(S)、RDF(S)、Ontology也不斷完善,為語義網的發展提供了有力支持。除了技術保證,語義網的發展還需要數據作為支撐,才能在實踐中發現缺陷并彌補和完善。目前的領域本體建設中,由于所能接觸的數據源大多規模小、數據少、數據更新不及時且涉及的領域狹窄,給語義網技術的大規模應用造成了不便。DBpedia的出現結合了維基百科這一超大規模數據源和語義網的優勢,為本體和RDF等提供了數據支持。而基于DBpedia和其他數據集的應用的逐漸問世也必將使人們更加清晰地認識到語義網的先進之處與便利性,從而推動語義網的普及和發展。
6 結語
DBpedia在本體、網絡資源分類、文本知識抽取、信息資源描述、網絡信息傳播等諸多方面都有涉及,作為一個跨領域多語言的大規模知識庫,其在數據挖掘、語義網發展等方面都有著重要的意義。同時,作為知識社區環境下的產物,除了具有組織和傳播知識的功能外,其維基精神也有極其深遠的文化影響。希望在以后的學習和研究中能夠對其有更深入的了解和分析,從而探索這個新的知識庫在網絡信息資源的組織傳播等諸多方面的功能和意義。
雖然DBpedia有諸多優點,目前還是存在一些問題,例如數據抽取的來源還未覆蓋詞條正文,而正文才是信息量最大最全面的部分,這需要從自然語言中抽取結構化數據的技術支撐。此外,信息盒的覆蓋率與質量、不同語言版本間的內容出入等問題,需要從維基百科和DBpedia兩個方面進行探索。
1.Wikipedia:DBpedia.〔2013-03-01〕.http://en.wikipedia.org/wiki/DBpedia
2.DBpedia blog.〔2013-03-01〕.http://blog.DBpedia.org/
3.金海.語義網數據管理技術及應用.北京:科學出版社,2010:75
4.劉巧玲.維基百科上的語義搜索.上海交通大學計算機應用技術專業碩士論文,2009
5.圖片引自:Anja Jentzsch.DBpedia-Extracting structured data from Wikipedia,Presentation at Semantic Web In Bibliotheken(SWIB2009),Cologne,Germany,November 2009
6.戴維民等.語義網信息組織技術與方法.上海:學林出版社,2008:11
7.Christian Bizer,Jens Lehmann,Georgi Kobilarov,et al.DBpedia-A Crystallization Point for the Web of Data.Journal of Web Semantics:Science,Services and Agents on the World Wide Web,Issue 7,2009
8.Christian Bizer,Jens Lehmann,etc.DBpedia-A Crystallization Point for the Web of Data.Journal of Web Semantics:Science,Services and Agents on the World Wide Web,Issue 7,Pages 154-165,2009
9.譚潔清.關聯數據的簡介與進展.信息與電腦,2011(1):103-106
10.朝樂門.基于語義Web的人機協同知識處理研究.圖書情報工作,2009(24):115-119
11.朝樂門,張勇,邢春曉.DBpedia及其典型應用.現代圖書情報技術,2011(3):80-87
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
電腦愛好者(2011年11期)2011-06-22 08:20:18
