基于大數據混沌特性的分區域異常數據挖掘
2015-10-10 08:35:24鄭羽潔李茜
河池學院學報 2015年5期
鄭羽潔,李茜
(廣西經濟管理干部學院 計算機系,廣西 南寧 530007)
0 引言
隨著網絡技術的快速發展,導致大數據環境下的網絡犯罪活動逐漸增多,使得大數據環境下的異常數據量增加[1-3]。因此,尋求有效的大數據挖掘方法,對于確保大數據環境下相關系統的安全性具有重要意義[4-6]。當前的大數據挖掘方法大都依據已知的異常特征進行大數據挖掘,降低了大數據挖掘的可靠性和效率,使得處理大數據的開銷增加,導致大數據總體的可用性和性能降低。因此,如何在不干擾大數據性能的情況下,分析不同區域大數據失效發生率、概率分析以及調整方案,成為當前大數據挖掘領域重點分析的方向[7]。
在大規模的數據挖掘中,海量數據對現有的異常數據挖掘效率帶來較大困難。如何針對海量數據設計分區域挖掘算法[8]已經成為研究的熱點。由于數據量過于巨大,為了減輕硬件的壓力,當數據規模超過承載上限時,需要對大數據進行分區。在不具有容錯特性的分布式集群環境下,大數據分區的效率與參與挖掘的硬件成反比。因此,海量數據的異常數據挖掘是一項具有挑戰性的任務。傳統的基于均值聚類的分區挖掘算法受到數據相似性的影響,這類分區挖掘算法在并行過程中會產生較高的通信負載,難以達到很高的并行度。因此,本論文提出了一種基于大數據混沌特性的分區域異常數據挖掘技術,首先證明了分區域異常數據挖掘下的大數據具有混沌特性,設計了混沌性特征提取,并根據混沌特征的聚類分區算法,實現大數據的分區域和異常數據的準確挖掘。
1 大數據中異常數據的混沌特性證明
大數據的來源通常由地理位置不同的運算節點的軟件、硬件通過不同的采集方式產生。在相同的環境下,大數據中異常數據的出現會造成數據在分區過程出現異常特征循環等現象。一旦出現數據異常,現有的數據分區過程會被重試、替換、局部重構,導致大數據中的異常數據隨機性成分增加。增加的異常數據在分區過程同正常數據間的對立性,形成數據之間的高度隨機性糾纏,也就是偽隨機過程,這種特征可通過數學中的混沌性來進行描述。
大數據在異常前期的混沌性產生原因如下:
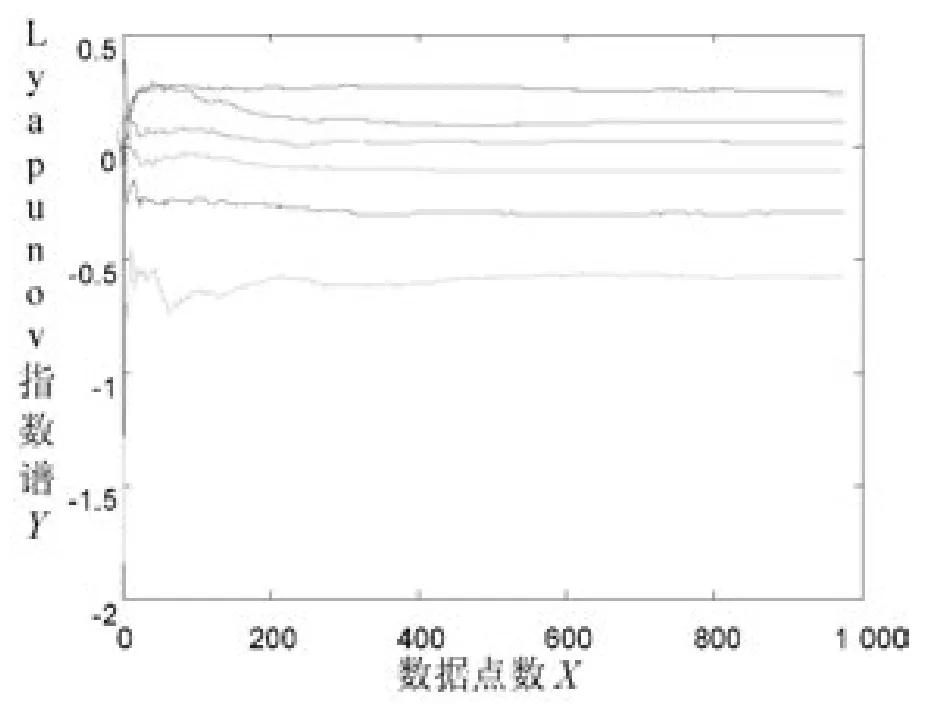
圖1 大數據異常數據序列Lyapunov指數譜
(1)大數據之間本身具有確定性和獨立性,如果數據突出出現異常會導致大數據呈現隨機與非隨機的特征,則出現混沌性;
(2)大數據出現異常數據時,數據在相關的區域中,同原始數據狀態具有較強的關聯性;
(3)數據混沌特征是大數據出現異常的先期評估標準。
證明大數據中出現異常數據有混沌性,可通過數據序列的最大Lyapunov指數是否大于0進行驗證。大數據中出現異常數據時,采用Matlab對異常數據進行Lyapunov指數圖仿真實驗,X軸表示異常數據出現的點數,Y軸為計算的lyapunov指數,結果用圖1描述。
分析圖1可得,該異常數據序列的最大Lyapunov指數大于0,進而證明大數據中在出現異常數據時,具有混沌性。
2 異常數據存在時的混沌特征采集
混沌特征是大數據中存在異常數據的特征,并可作為挖掘異常數據的一個特征,該特征符合波動規范和數據內部關聯性,可作為唯一區分特征進行提取,不必進行多次校驗。因此,可在海量大數據序列中獲取描述大數據異常特征的混沌數據特征關聯,完成異常特征的采集,得到大數據異常分析的數據集,過程為:
將大數據中的異常數據映射成一組概率密度函數,將該組概率密度函數作為劃分到不同分類頻點內的使用概率。通過概率分析形成可描述數據顯著混沌特征的隨機數序列,采集混沌特征數據。
異常數據符合概率密度隨機調頻需求,如果大數據中的異常數據序列為x(n),τ表示分析誤差。可對數據進行重構,重構映射的m維相空間中,可產生m維矢量,如式(1)所示:

其中,n=1,2,…,N,在重構數據映射的m維相空間內,采集一維數據矢量Xn,其在相空間內用點描述,與其距離最小的點用Xη(n)描述,將歐氏距離當成兩點的距離尺度。
在大數據異常數據序列映射相空間內,隨著m增加到m+1時,相空間內點同與其距離最小點間的距離用式(2)描述:

設置分類異常數據為Qs,原數據為Q0,對比分析兩種數據的差異S,評估異常概率分析映射分類是否正確,且有:
對比2組患者生活質量以及身體功能,研究組生活質量(42.45±5.45)分,身體功能(43.85±5.89)分,參照組生活質量(33.45±4.89)分,身體功能(34.12±5.01)分,數據對比t值為6.9530,p值為0.05、t值為7.1181,p值為0.05,研究組評分高于參照組患者,組間對比具有顯著性差異(P<0.05)。

其中,〈Qs〉表示N批概率分析映射數據的評估統計量值均值,σs表示N批概率分析映射數據的判別統計量值的標準差,則有:

通過Sigma檢驗S取何值時原數據是隨機的,設置不同概率分析映射異常數據的Qs值的概率分布為正態分布,則有:

優化異常數據分類模型概率分析置信區間與拒絕區間,也就是p(Qs)~(Qs)曲線,要否定概率分析映射分類,應確保S足夠大,使Qs的分布遠離Q0。當置信度為96%時,拒絕概率分析映射分類的機會為α=4%,通過相關判斷可得:
(1)S≥1.50概率分析映射分類按照95%概率不成立,原異常數據為具備混沌數據特征;
(2)S<1.50概率分析映射分類成立,原異常數據不是混沌特征數據。
混沌性特征采集的源代碼如下:


3 挖掘算法的設計
3.1 大數據的聚類分區過程
在準確提取了混沌特征后,可將大數據集分成合理的數據分區,增強大數據的異常數據挖掘能力。先從全部序列中采集原始的n個數據序列,將其劃分成n個簇{P1,P2,…,Pn},其中n表示大數據應劃分的區域數,初始化全部簇質心Cj(j=1,2,…,n),運算各項關聯權值,將其序列依次劃分到n個簇內,運算序列Si到各簇質心Cj的相似函數Sim(Si,Cj),將Si分配到Sim(Si,Cj)值最小的簇Pj內,分配后應調整新簇Pj、簇質心Cj和各項的關聯權值。
3.2 異常數據挖掘
對大數據進行分區域和異常數據的混沌相關特征進行提取后,運用優化的BP神經網絡方法,結合遺傳算法設計挖掘模型。該挖掘算法的具體過程如下:
(1)初始化數據集,通過二進制的方法,對大數據分區域的混沌特征進行權值編碼。大數據分區域中的個體混沌特征可以用相應類別的權值表示,設某一原始權值集及其最大進化次數。
(2)設計適應度函數,在該函數中獲取最小值。
(3)解碼混沌特征的權值,獲取混沌特征的權值,如果權值滿足規范要求或者權值等于最大進化次數,則轉向過程(7);否則,轉向過程(4)。
(4)通過遺傳算法的交叉與變異功能,獲取神經網絡的新個體。
(5)標識具有最優適應度的個體,避免這些個體進行交叉與變異操作。
(6)利用優化的BP神經網絡方法對擁有最優適應度的個體進行操作,同時運行步驟(2)。
(7)算法結束,得到神經網絡中擁有最優權值的個體,也就是待挖掘的大數據中的異常數據。源代碼如下[9]:


4 實驗分析
為了對本文方法的性能進行測試,需要進行相關的實驗分析。分別在兩種不同的大數據集上,對本文方法與傳統方法(循環迭代分區挖掘算法)進行對比實驗。下面給出本實驗所涉及到的兩個大數據集,Set是模擬數據集,包括兩個大小為25.2 MB的分區,Cslogs為實際數據集,包括兩個大小為6.22 MB的分區。
當輸入數據量一定時,依據最小支持度的改變量,對本文方法與傳統方法的性能進行比較。隨著支持度的減小,符合條件的頻繁模式逐漸增加,挖掘頻繁模式所耗費的時間也隨之增多,對于頻繁模式挖掘算法而言,支持度的適應能力是一個重要指標。
圖2描述的是本文方法和傳統方法在Set數據集上運行時間的比較結果,最小支持度從0.03降將至0.01。從運行效率的角度分析,本文方法所需的運行時間明顯低于傳統方法。
圖3描述的是本文方法和傳統方法在Cslogs數據集上運行時間的比較結果,最小支持度從0.1降至0.05。從運行效率的角度分析,本文方法的性能明顯優于傳統方法。實驗結果表明,本文方法可以有效解決傳統方法在大數據集上進行挖掘時出現的內存消耗大的問題。
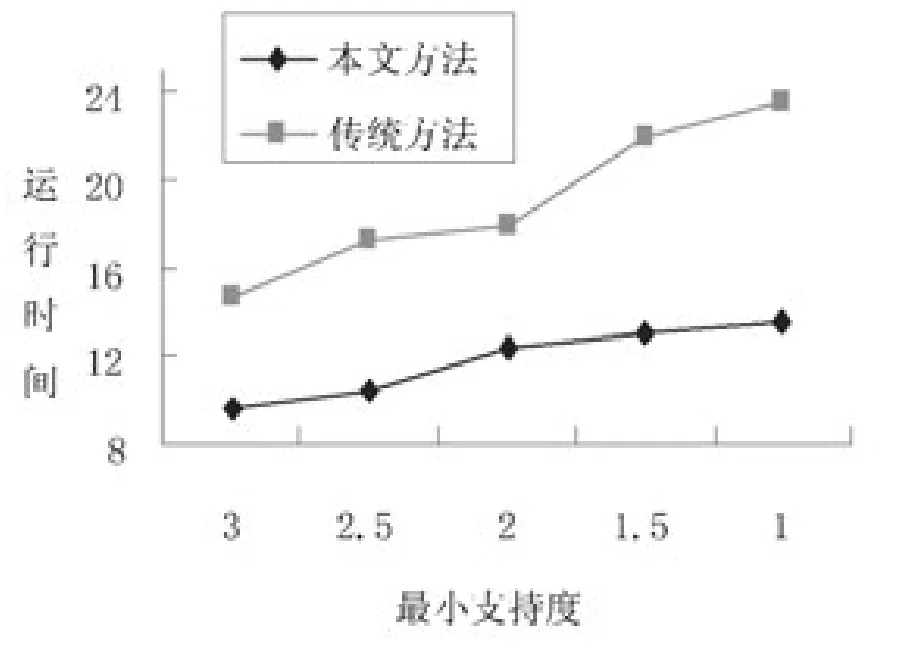
圖2 在Set數據集上兩種方法的運行時間比較
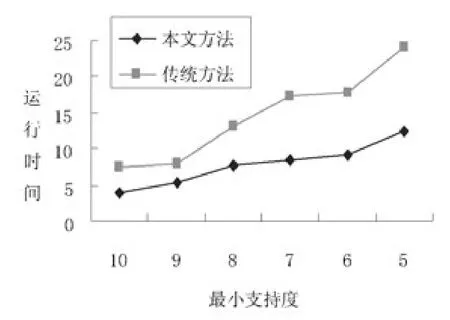
圖3 在Cslogs數據集上兩種方法的運行時間比較
圖4描述的是本文方法和傳統方法在不同數據集大小下測試的結果。分析圖3可知,兩種方法的運行時間曲線均隨數據量的增加逐漸增加,但較傳統方法而言,本文方法的曲線增長較為緩慢,同時隨著數據量逐漸增加,與傳統方法運行曲線之間的距離越來越遠。說明本文方法能夠更好的適應大數據集。
圖5描述的是本文方法和傳統方法在不同維數下的測試結果,當前數據量取6000。分析圖5可知,本文方法運行時間曲線比傳統方法增長緩慢。在低維狀態下,數據點相對集中,通過微單元可高效完成數據的處理;在高維狀態下,數據點相對分散,稀疏單元相對較多,與傳統方法相比,本文方法可更加有效地增強算法的運行效率,更好地適應高維大數據的挖掘。
5 結論
本文提出了一種基于大數據混沌特性的分區域挖掘技術,證明了分區域異常數據挖掘下的大數據混沌特性,對分區域異常數據挖掘下的大數據混沌特性進行分類和采集,獲取大數據在異常早期的數據特征、波動規范和數據內部關聯性,在隨機性數據序列中獲取描述大數據異常特征的混沌數據特征關聯,完成大數據混沌特征的采集,采用聚類分區算法實現大數據的分區劃分,得到可降低局部頻繁序列的大數據分區結果,提高大數據分區效率,通過改進BP神經網絡檢測方法,實現大數據分區域異常數據的準確挖掘。實驗結果說明,所提方法可對不同大數據集進行準確挖掘,具有較高的魯棒性和效率。
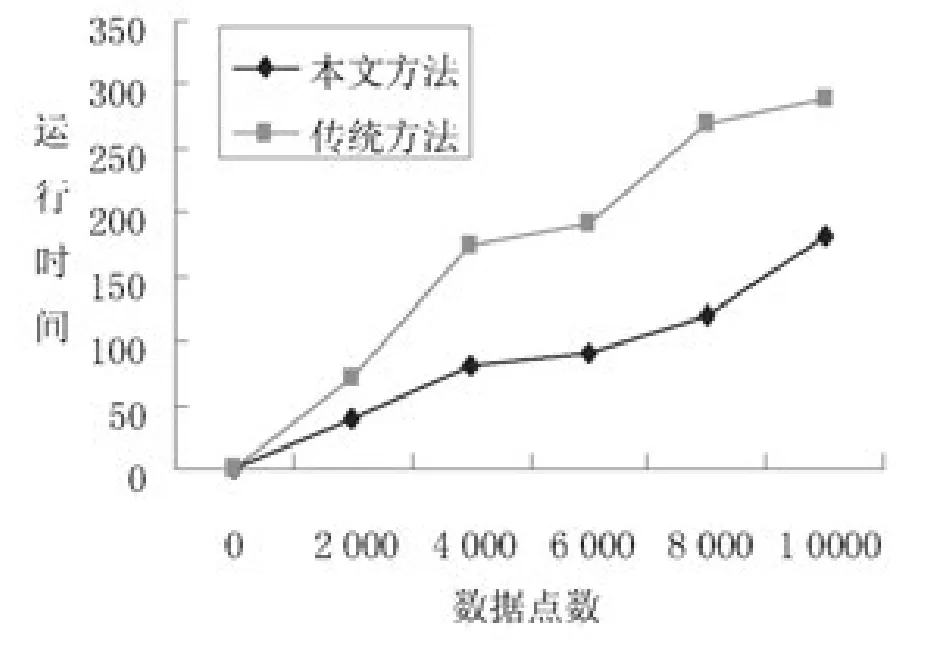
圖4 在不同數據集大小下兩種方法的運行時間比較
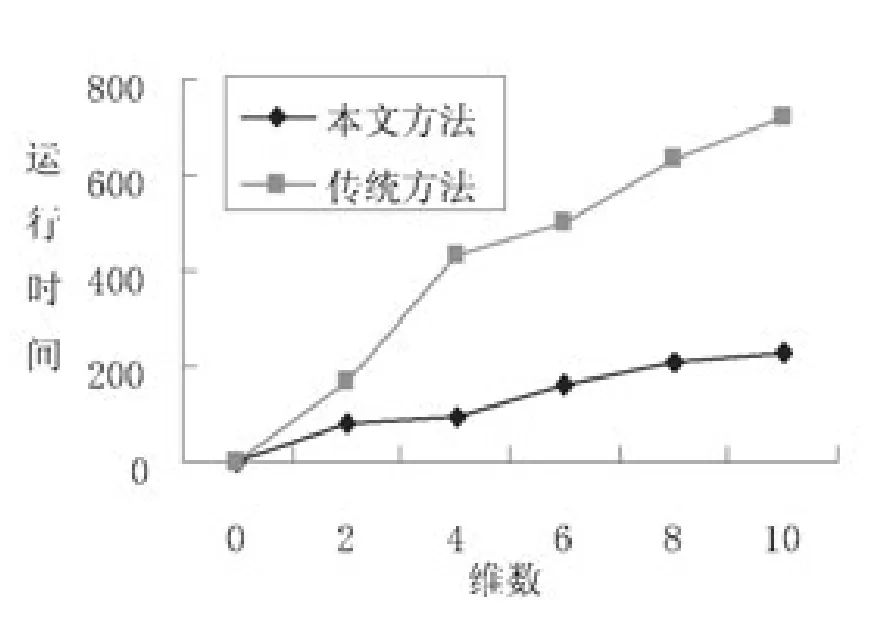
圖5 在不同維數下兩種方法的運行時間比較
[1]李志云,周國祥.一種基于MFP樹的快速關聯規則挖掘算法[J].計算機技術與發展,2007,17(6):94-96.
[2]相征,張太鎰,孫建成.基于混沌吸引子的快衰落信道預測算法[J].西安電子科技大學學報,2006,33(1):145-149.
[3]劉芳.基于離散反饋控制的TCP-RED網絡混沌特性研究[J].西安電子科技大學學報,2005,32(6):977-981.
[4]劉興濤,石冰,解英文.挖掘關聯規則中Apriori算法的一種改進[J].山東大學學報(理學版),2008,43(11):67-71.
[5]羅赟騫,夏靖波,陳天平.網絡性能評估中客觀權重確定方法比較[J].計算機應用,2009,29(10):2624-2626.
[6]劉曲明,顧桔.網絡性能分析評價方法及其計算機仿真方法討論[J].計算機仿真,2000,17(1):53-57.
[7]周水庚,周傲英,曹晶.基于數據分區的DBSCAN算法[J].計算機研究與發展,2000,37(10):1153-1159.
[8]Yang Jingrong.ZhaoChunyu.Study on the Data Mining Algorithm Based on Positive and Negative Association Rules[J].Computer and Information Science,2009,2(2):103 -106.
[9]趙鵬.海量高維數據下的頻繁項目集挖掘算法研究[J].計算機應用與軟件,2012,29(7):150-153.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
電力與能源(2017年6期)2017-05-14 06:19:37
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
信息通信技術(2015年6期)2015-12-26 01:16:46
電測與儀表(2015年5期)2015-04-09 11:30:52
河南科技(2014年23期)2014-02-27 14:19:15
