基于深度神經網絡與主題模型的文本情感分析
——以上海迪斯尼景區游客滿意度調查為例
2016-02-13 05:57:49何愉衛陳泉陸鈺華
統計科學與實踐 2016年12期
何愉、衛陳泉、陸鈺華
(國家統計局上海調查總隊,上海 200003)
基于深度神經網絡與主題模型的文本情感分析
——以上海迪斯尼景區游客滿意度調查為例
何愉、衛陳泉、陸鈺華
(國家統計局上海調查總隊,上海 200003)
本文嘗試以上海迪斯尼景區的網絡評價數據為例,通過深度神經網絡和主題模型開展文本情感分析。在完成網絡數據爬取、基于隱馬爾可夫(HMM)模型的中文分詞、向量空間(VSM)模型將文本轉向量等一系列數據源和數據預處理工作后,通過機器學習中的多層感知器(MLP)神經網絡進行建模,并構建主題模型。本文將大數據的開發與當前的統計調查有機結合,探索一條對社會各領域評價調查具有可復制可推廣的大數據調查模式。
文本挖掘;神經網絡;主題模型;情感分析;VSM模型
隨著社會和科技的發展,尤其是在當前大數據研究應用的背景下,傳統調查受限于時間和空間,調查效率相對偏低,調查數據質量控制難度和成本不斷增加,調查數據的時效性相對偏弱等不足進一步顯現。大數據時代的來臨,為我們提供了全新的獲取數據的渠道,也為我們創新調查方式,更加快捷、高效、科學地評估用戶滿意度水平提供了一種可能。
本文嘗試以上海迪斯尼景區的網絡文本評價為例,通過深度神經網絡和主題模型開展文本情感分析。當前傳統的滿意度調查主要通過問卷調查的方式開展,通過瀏覽網站不難發現,網絡評價分為定量評價(如打分、標星)和定性評價(如文字描述)兩種。然而面對大數據,我們也會心生疑惑和忐忑,大數據的內部結構難以全面把握甚至不得而知,大數據的數據質量參差不齊也無從考究,大數據的應用結果缺乏驗證和評估,因此如何應用好大數據,挖掘出紛繁復雜,雜亂無章的大數據背后暗藏的規律,如何將大數據的開發與當前的統計調查有機結合,成為有益的補充和替代;探索一條對社會各領域評價調查具有可復制可推廣的大數據調查模式,是我們研究的初衷和出發點。
課題研究將通過完成以下三大目標,實現建模初衷。1.綜合運用HMM分詞模型、VSM模型、MLP神經網絡以及LDA主題模型,創新滿意度調查方式;2.將定性文字轉為定量評價,提高文本數據的挖掘分析能力;3.加深對大數據內部維度結構的認知,更加細化對文本數據的挖掘等方面,開展積極地嘗試和探索。
一、研究路徑
(一)數據獲取
運用網絡爬蟲技術,從攜程網、大眾點評、貓途鷹等旅游網站上獲得游客對香港迪斯尼、上海迪斯尼等景點的網絡評價,包括評論時間、文本評論、滿意度評價及相關用戶信息。
(二)數據預處理
經過文本預處理,建立只有評論內容的文本數據庫;基于隱馬爾可夫模型(HMM),通過公共詞庫、停用詞詞庫和自定義詞庫進行中文分詞,經過多次迭代和詞庫更新,形成最終分詞結果。最后通過向量空間模型(VSM),將分詞完畢的文本,轉化為文本向量,存入文本向量庫。
(三)建模(模型訓練和比較)
首先MLP建模。通過機器學習中的多層感知器神經網絡(MLP)進行建模并評估結果,不斷的調整預測模型,直到預測結果達到預期準確率。基于向量空間模型中的三種轉換方法,運用多層感知器神經網絡中的邏輯回歸(LR)和支持向量機(SVM)兩種算法進行比較分析。其次構建主題模型。通過LDA主題模型,對文本進行潛語義分析,對潛在主題分類的相關特征的分析和甄別,確定相關主題。
(四)知識獲取
以上海迪斯尼景區的網絡評論滿意度為主要研究對象,比對世界各地迪斯尼景區,從整體滿意度水平、二級評價主題差異和分項滿意度差異、滿意度隨時間趨勢變化等多角度進行挖掘,加強對網絡評論文本的深度解讀,從而能夠更有針對性地對評論對象提出意見建議。
二、數據來源和預處理
(一)軟件說明:python語言
本課題運用python語言編寫預處理和建模程序。
(二)數據來源:爬蟲獲取網絡評價
運用網絡爬蟲技術,從攜程網、大眾點評、貓途鷹等旅游網站上成功獲得逾六萬條游客對香港迪斯尼、上海迪斯尼等景點的網絡評價,包括評論時間、文本評論、滿意度評價以及用戶信息。其中部分文本評論用于神經網絡建模的訓練和測試;另外一部分文本評論用于模型機器打分(見表1)。進行文本預處理,純化文本內容,去除HTML標記,形成只有評論內容的純文本,并存入評論文本數據庫。
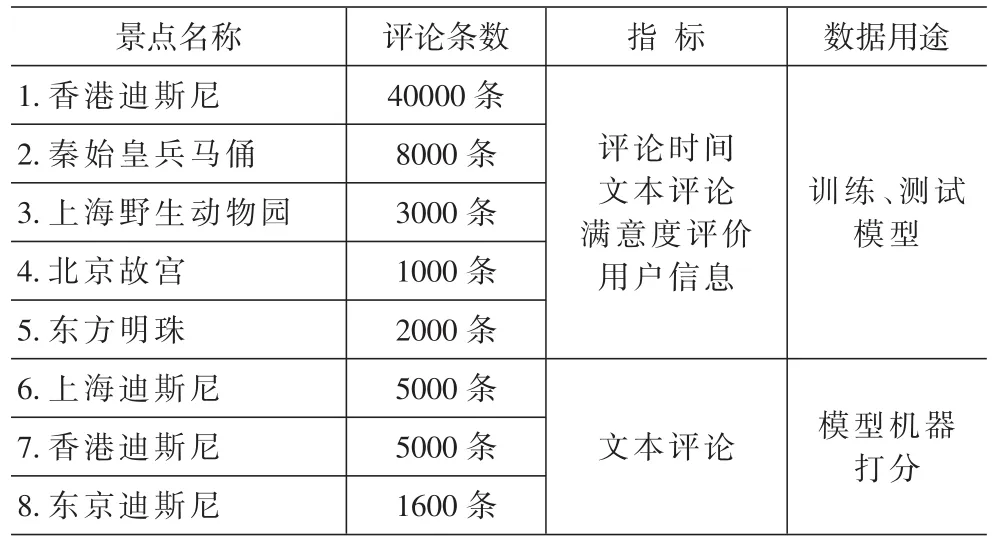
表1 課題數據源信息表
(三)訓練語料評估:德爾菲法確定語料噪音比例
隨機抽樣選取一定比例的訓練語料,進行人工背靠背打分,將打分結果和原始滿意度分值進行比較,確定“噪點”(主客觀偏差較大的數據)比例。若比例過高,則前期需增加對“噪點”語料的篩選和剔除;若比例較低,“噪點”語料不會影響后期機器學習效果,可直接運用于下階段分析使用。通過背靠背打分,發現原始語料噪點比例為0.5%,可直接使用。
(四)文本分詞:運用“隱馬爾可夫模型”對文本評價分詞
第一階段:初步分詞,運用公用詞庫和自定義詞庫對評論文檔進行分詞;
第二階段:去停用詞,停用詞主要為副詞和標點等,去除一些在文本中常用的詞語,比如“的”“嗎”等;合并數字和人名等詞匯;數字或者人名等詞匯在具體的分析過程中一般不會起到非常大的作用,人工將其去除;
第三階段:自定義詞庫更新,將每次分詞發現的新詞不斷加入自定義詞庫。經過多次的迭代和詞庫的更新,形成最終的分詞結果(限于篇幅,此處省略)。
(五)向量空間(VSM):文本轉換為向量
情感分析利用神經網絡,將一條條分詞完畢的文本評價轉換為向量,這樣計算機才能夠讀取和學習。在轉換的過程中,列指標即特征向量。特征提取指選取能夠表征目標結構的一種表示方法,進而擁有分類和判決。本課題運用VSM模型將一條分詞完畢的評論轉換為向量,具體分PVDM(Distributed Memory Model of Paragraph Vectors)和PV-DBOW(Distributed Bag of Words version of Paragraph Vector)兩種算法(見圖1)。相較于CBOW(從上下文推本詞)和skip-gram(從本文推上下文),VSM的方法在前者基礎上加入了段落標志,從而能夠達到更好的分詞效果。DBOW、DM等向量空間模型,分詞中只需解決未登錄詞,無需刪除大量停用詞以及預先導入同義詞庫,大大簡化了分詞的難度。
具體操作:
步驟一:將每條分詞完畢的評論運用PV-DM方法轉換為[1*200]的向量;
步驟二:將每條分詞完畢的評論運用PV-DBOW方法轉換為[1*200]的向量;
步驟三:將上述兩種轉換方法得到的向量合并,構造得出[1*400]的向量。

圖1 DM和DBOW的說明
三、機器學習建模與模型比較分析
(一)思路框架
在建立模型的時候,本課題選用監督式機器學習的算法。將模型預測結果與“訓練數據”的實際結果進行比較,不斷的調整模型,直到模型的預測結果達到一個預期的準確率。本課題嘗試探索應用多層感知器神經網絡,并使用多種目標函數(邏輯回歸和支持向量機等)開展比較研究。
(二)主要步驟
1.數據建模
在前期文本轉換為向量的基礎上(dov2vec),運用機器學習神經網絡(MLP)算法,構建模型。在評分標準方面,二分法雖較簡化,機器學習的判別也更簡單,但也損失了部分信息。基于此,課題組通過五分法,使機器學習能夠獲取更多信息,文本情緒層次進一步得到細化,輸出結果可解讀性更強。
2.模型驗證
采用隨機交叉驗證。在所有用于訓練神經網絡的評論中,80%用于建模(含訓練和評估),20%用來測試模型效果。在80%用于建模的評論中,采用隨機交叉驗證法,其中80%用于訓練模型,20%用于評估模型每一次迭代訓練的收斂效果。
3.運用兩種目標函數(邏輯回歸和支持向量機)
神經網絡的目標函數,選擇邏輯回歸(categorical crossentropy)和支持向量機(hinge loss)進行比較分析。
(三)神經網絡建模的結果
在建模中分別使用邏輯回歸和支持向量機輸出的總體滿意度得分和預測準確率見表2。兩種目標函數分別對應分布詞袋模型(DBOW)、分布記憶模型(DM)以及兩種方式的結合(DBOW+DM)等三種向量空間模型,進行建模。從整體滿意度看,兩種方法得到的評分水平比較相近;在預測準確率方面,邏輯回歸略高于支持向量機,其中基于分布詞袋模型(DBOW)的邏輯回歸的準確率最高,達0.489。

表2 兩種目標函數建模結果比較
四、LDA主題模型
(一)LDA原理
由于神經網絡模型輸出結果僅能反映整體評價情況,不能提供細致的深入發現和認知,因此進一步引入LDA主題模型,挖掘文檔集合中的重要主題。
LDA是一種非監督機器學習技術,可以用來識別大規模文檔集(document collection)或語料庫(corpus)中潛藏的主題信息。LDA可以找到產生文本的最佳主題和詞匯,最大程度地表示文本中所蘊含的含義,信息丟失較少,能夠較好地解決詞匯、主題和文本之間的語義關聯問題。
該模型假設:每個文本包含一定數量的隱含主題,每個主題包含特定的詞;文本和詞匯間的關系通過隱含主題體現;文本到主題服從狄利克雷(Dirichlet)分布,主題到詞服從多項式分布。
(二)建模過程
對上海迪斯尼的評價文本按照標點符號進行分句,再進行分詞處理,將得到的文檔輸入LDA模型。模型共設置20個分類,并在各分類中選取20個出現概率最高的關鍵詞,自迭代500次(限于篇幅,此處省略LDA主題分類和關鍵詞提取的輸出結果表)。
(三)建模結果
通過關鍵詞的解讀,分析該項分類的具體特征,確定相對應的主題分類。在20個分類中,最終確定了15個分類,歸入餐飲、排隊時間、游玩設施、服務管理、游玩項目、交通、趣味性、園內演出和購物等9個主題;另外5個分類沒有明顯的含義,故未歸入任何主題。并通過神經網絡對上述9個主題進行文本情緒分析,即獲得相應的滿意度水平(見圖2)。

圖2 邏輯回歸(DBOW)分項主題評分結果
五、實證結論
(一)模型選擇
比較分別采用支持向量機和邏輯回歸作為目標函數的神經網絡模型輸出結果,分析其總體滿意度和分項主題滿意度打分的匹配度,我們可以發現,采用邏輯回歸(DBOW)的方法得到的總體滿意度為3.83分,而分項主題的加權平均滿意度為3.96分,兩者差異(0.13分)最小。其他5種方法的各分項滿意度加權值均高于總體滿意度,差異介于0.19-0.47分之間,相對較大(見表3)。由此可見,在神經網絡建模過程中采用DBOW向量空間模型和邏輯回歸目標函數,輸出結果中總體和分項的匹配度更高,輸出結果更為合理。
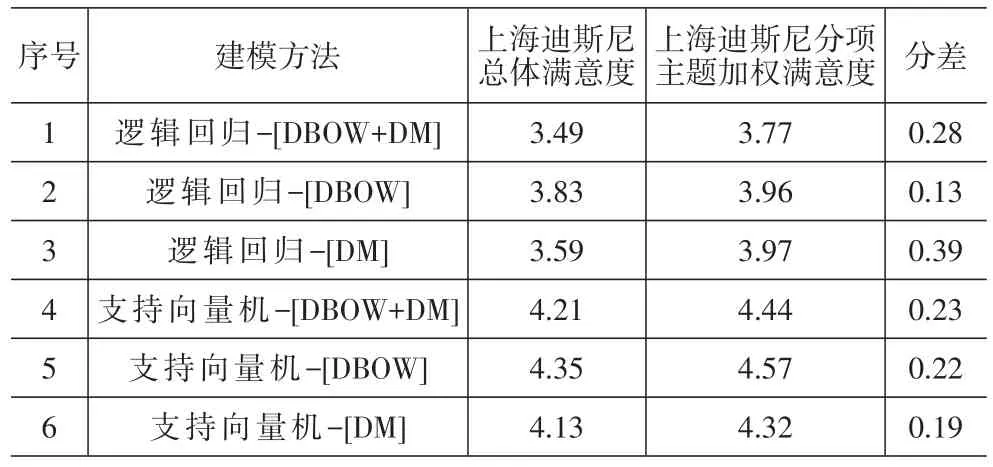
表3 兩種目標函數建模結果比較
(二)主題模型實證結論
通過主題模型和神經網絡模型,分別對上海、香港、東京等迪士尼樂園的相關主題分項進行滿意度打分(見表4)。

表4 分項主題滿意度評分結果
三大迪斯尼景區的游客對“趣味性”的滿意度水平較高,均列前三位;而游客對“餐飲”的滿意度水平普遍較低,上海和東京墊底,香港倒數第二。與香港和東京迪斯尼橫向比較,上海迪斯尼盡管在“交通”、“趣味性”和“游樂項目”等方面的滿意度水平較高,但仍存在以下薄弱環節:一是“餐飲”,游客對園區餐飲的價格、菜品以及用餐環境等方面的滿意度較低;二是“排隊時間”,入園排隊以及項目排隊時間較長對游客滿意度影響較大;三是“游玩設施”,尤其是在園區試運行和開園次月中,游客對游玩設施的頻繁故障維修、設備檢修未及時告知等問題產生一定的不滿情緒。因此,園區可集中針對上述當前較為突出的三方面問題,進一步加以重視和改善,從而更有針對性、更快速地提升游客滿意度。
六、課題研究創新之處
(一)可量化:將定性文字轉為滿意度定量評價
多層神經網絡建模能夠對景點的文本評論進行情緒分析,從而客觀打分。通過不斷地加入新增的文字評論(即語料),機器學習的能力將不斷增強,建模效果將不斷提升。機器學習將定性文字評價轉變為定量評估,從而更易于縱向和橫向比較,不斷深化數據挖掘和分析。以迪斯尼為例,基于大眾點評、攜程網等旅游網站關于香港迪斯尼樂園和上海迪斯尼樂園的文本評價,得到上海迪斯尼的滿意度得分為3.83分,香港迪斯尼的滿意度得分為4.23分。
(二)可洞察:運用主題模型認知對象維度結構
為了挖掘文檔集合中的重要主題,LDA主題模型被引入進來。將5000多條有關上海迪斯尼的文本評價構建出9大主題,并獲得相對應的滿意度水平。課題研究分析表明,市民對游玩項目的關注度最高;對園區交通、趣味性的整體滿意度較高;對餐飲、排隊時間和游玩設施的滿意度相對偏低,有待改善。
(三)可時點化:突破調查時間和空間上的局限
課題研究除了能同時掌握上海、香港和東京等不同地區迪斯尼同一時間段內的滿意度水平,還能掌握景區在不同時間段內的滿意度水平變化。以上海迪斯尼為例,保留了評論時間這一數據標簽,課題組以“周”作為時間劃分段,計算上海迪斯尼一段時間內的時點數據。通過數據發現,上海迪斯尼在試運行期間的滿意度呈現下降態勢;隨著園區正式開園,滿意度呈波動上行態勢;但開園次月后,滿意度呈現下降走勢。
進一步分析分項主題滿意度的走勢(見圖3),可以發現游客對“交通”、“趣味性”等的滿意度評價較好且呈不斷上升趨勢,對“餐飲”等的滿意度較低且基本呈下降趨勢。對于“排隊時間”、“購物”的滿意度雖然較低,但是開園次月的滿意度比試運行期和開園首月已有明顯改善;對“游玩項目”的滿意度雖較高,但開園次月的滿意度卻有一定下降。通過分項主題滿意度走勢分析,園區能夠更為精準地發現影響整體滿意度水平變化的主要因素、對某方面的改進措施是否起效、仍有待改進的方面在何處等問題。

圖3 上海迪斯尼分項主題游客滿意度水平走勢圖
七、課題研究價值與改進方向
(一)課題研究價值
1.在調查時間和空間上突破傳統調查局限性
傳統調查時,需要在一段時期中開展不間斷調查,往往耗費大量的人財物,所以往往在有限的經費預算情況下,采取抽樣調查的方法,了解在這個時點上的調查結果。本課題突破了這種局限性,能在連續的時間并且在不同的空間中完成調查任務,達成傳統調查難以完成的效果。
2.成為傳統統計調查的有益補充甚至替代
通過機器學習加強對大數據的挖掘,尤其是對文本數據的挖掘和開發,是對傳統的入戶調查、攔截調查、電話調查等調查方式的一種有效補充,能夠相互驗證和評估。簡而言之,大數據的數據導向方式與問卷調研的立論導向方式能夠更好地配合,從而協助我們對研究問題更客觀的理解和對研究結果更科學的評估。不斷加深對機器學習技術的掌握,不但是提高統計效能的“利器”,甚至可成為傳統統計調查的有益補充和替代。
3.對社會各領域的評價調查具有可復制、可推廣性
本課題對文本數據的挖掘與開發模式,可進一步在其他旅游景點評價調查中加以復制推廣,并可以延伸至公共服務評價、輿情監測、政策反饋等社會各領域中,尤其是同時涉及用戶文字評價和打分的相關調查和研究。課題組在后續的研究中已將課題成果應用于上海市A級旅游景點調查和創建國家食品安全城市滿意度評價調查,并將網絡文本挖掘結果與傳統調查結果進行比較分析。
(二)課題改進方向
一是數據源有待進一步拓展豐富,除了專門的評分類網站數據之外,可考慮納入微信、微博等各類個人社交網絡的評論、新聞評論、論壇帖子等相關文本。二是建模的效果受VSM、MLP等機器學習算法的參數值影響,如向量大小、神經網絡各層的節點數、訓練速率、迭代次數等。三是對文本情緒進行判別時,本文采用了神經網絡+邏輯函數和神經網絡+支持向量機兩種方法,可考慮采用隨機森林等其他模型進一步進行驗證和優化。
(責任編輯:曹家樂)
猜你喜歡
工會博覽(2023年3期)2023-04-06 15:52:34
石油瀝青(2021年4期)2021-10-14 08:50:44
小康(2021年7期)2021-03-15 05:29:03
活力(2019年19期)2020-01-06 07:34:38
制造技術與機床(2019年10期)2019-10-26 02:48:08
雜文月刊(2019年15期)2019-09-26 00:53:54
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
語文知識(2014年1期)2014-02-28 21:59:13
