基于賬戶信用評價的惡意發帖檢測系統研究
2016-05-14 12:41:40陽小蘭劉克剛錢程朱福喜
現代電子技術 2016年6期
關鍵詞:信用評價
陽小蘭 劉克剛 錢程 朱福喜

摘 要: 惡意發帖檢測系統處理的主體是帖子,往往忽略發帖是用戶的主觀行為。針對這一現象,從研究用戶的主觀行為出發,建立賬戶信用模型,設計基于賬戶信用評價的惡意發帖檢測系統。分析賬戶信用模型的主要影響因素,將其離散化,量化賬戶的信用。通過建立賬戶信用模型,對賬戶進行信用評價和分類,有效發現惡意賬戶,預測發帖行為,對惡意賬號進行嚴格監控,并根據賬戶信用影響反饋,動態調整惡意發帖檢測系統。通過實驗,驗證了惡意發帖檢測系統的有效性。
關鍵詞: 賬戶信用; 信用評價; 惡意發帖; 發帖檢測
中圖分類號: TN711?34 文獻標識碼: A 文章編號: 1004?373X(2016)06?0053?05
Research of malicious post detection system based on account credit evaluation
YANG Xiaolan1, LIU Kegang2, QIAN Cheng1, ZHU Fuxi1, 2
(1. School of Information and Engineering, Wuchang University of Technology, Wuhan 430223, China;
2. School of Computer, Wuhan University, Wuhan 430072, China)
Abstract: At present, the malicious posting detection system deals with the post itself, but ignores that the post is the user′s subjective behavior. Proceeding from the research of the user′s subjective behavior, an account credit model was established and a malicious post detection system based on account credit evaluation was designed to eliminate the phenomenon. The main influencing factors of account credit model are analyzed and discretized for account credit quantification. By establishing the model account credit, the accounts' credit standing is evaluated and classified to effectively discover malicious accounts, predict posting behavior, and realize strict monitoring of malicious accounts. The malicious posting detection system is dynamically adjusted according to the credit feedback of the account. The validity of the malicious post detection system was verified through the experiment.
Keywords: account credit; credit evaluation; malicious posting; post detection
中國互聯網發展迅速,據中國互聯網絡信息中心(CNNIC)2015年7月發布的第36次《中國互聯網絡發展狀況統計報告》,截止2015年6月,中國網民規模達6.68億,互聯網普及率達48.8%。目前,虛假信息、造謠誹謗、網絡水軍等現象影響著互聯網的健康發展[1?3],惡意發帖檢測系統旨在為網絡社區發現、剔除惡意發帖,構建優質網絡社區環境,營造健康和諧的網絡社會環境。
目前網絡輿情系統多采用自然語言處理、機器學習、數據分析等手段分析用戶發布的信息內容是否健康,是否符合社區的中心思想。與針對發帖內容的檢測技術相比,基于行為的惡意檢測技術,不再在帖子的汪洋大海中無針對性的尋找惡意帖子,改為有針對性地尋找惡意帖子部落,惡意帖子部落的中心是惡意賬戶。綜合考慮賬戶發帖頻率、發帖時間、賬戶信息維護等多個維度的行為特征,可以有效發現惡意賬戶,對該賬戶的所有發帖進行監控,撤回該賬戶所發的惡意帖子。
賬戶行為挖掘的思想避開了監測惡意文本信息作為主體,轉向檢測發帖的主體行為。其不僅可以有效地檢測惡意文本信息,還可以發現惡意賬戶。對風險度較高的賬戶可以采用嚴格控制技術,降低網絡社區的風險,對優質賬戶給予更多權限,改善網絡社區服務,培養更多優質客戶。本文在賬戶行為挖掘的基礎上,通過構建賬戶信用模型,對賬戶信用進行評價,檢測并發現惡意賬戶和惡意信息。
1 賬戶信用模型
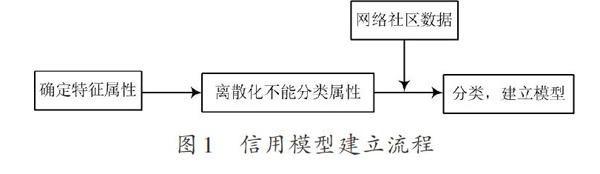
信用模型的建立需要經過如圖1所示的幾個流程,完成分類特征屬性的確定,將不能分類的屬性進行離散化處理,結合網絡社區數據建立分類預測模型。
1.1 信用特征屬性
收集影響賬戶信用的相關屬性,構建賬戶的信用特征向量V={x1,x2,…,xn},xi表示賬戶某一特征屬性離散化值。結合從事網絡社區開發的工作經驗以及查閱相關資料,列出一些基本屬性[4?6]。
(1) 賬戶名:從登錄社區的賬戶中可以預見賬戶的優劣,對于普通或者優質用戶會在意自己的賬戶名稱,一般采用某些有意義的詞或者姓名的變形等。目前,騰訊等互聯網巨頭提供賬戶授權服務,用于解決用戶注冊大量賬戶,使用單一密碼危險,多種密碼困難的問題。
(2) 賬戶詳細信息:一般社區賬戶會要求賬戶提供除登錄用的賬戶名和密碼之外的其他信息。作為社會人一般具有許多社會標簽,某些標簽可以預示用戶的真實信息。例如性別、籍貫、喜好、座右銘、學歷、生活經歷等。對于惡意賬戶在賬戶詳細信息補充完整方面沒有優質賬戶做得好,更多的是隱藏或者偽造。
(3) 認證等級:對于一些安全性要求比較高的社區賬戶,特別是涉及到金錢、隱私,都要求比較嚴格的實名制驗證,驗證賬戶的銀行卡、身份證、手機號等。一般社區賬戶會要求郵箱驗證或者手機號驗證。經過較高等級驗證的賬戶,通常是優質賬戶。
(4) 最近登錄行為:用戶登錄社區的時間段、頻率、IP地址一般情況下是有規律可循。關注登錄行為屬于行為分析領域,對于了解賬戶是否被盜、還是本身是惡意賬戶具有幫助。
(5) 最近發帖行為:分析賬戶發帖行為,可以提取許多有用的價值,是惡意檢測系統主要的關注行為。對于普通用戶使用網絡社區具有一些通用模式。即使是高產的作家,每天發表的博文、日志數量會穩定在一個閾值內,對于同一個問題發表的評論同樣滿足上述觀點。
(6) 社區關系網:網絡社區是社會關系向線上發展的產物。社會關系網預示物以類聚的思想,具有眾多粉絲的賬戶并且粉絲中包含優質粉絲的賬戶應該是比較優秀的賬戶。
賬戶信用模型的主要影響因素如圖2所示,各種因素對于用戶信用特征向量的影響,根據具體情況可以自定義設置。用戶的信用特征向量,根據用戶參與網絡社區的情況,相應地動態調整。經過實名制認證的用戶應該比匿名用戶具有更高的信用度。如果用戶登錄異常,或者用戶發布違規的信息,應該適當的降低用戶的信用度。有些網絡社區允許用戶之間可以建立好友關系,同時會影響用戶的信用度。
1.2 離散化特征屬性
本文選取賬戶社區關系作為研究主要因素,對社區關系進行離散化處理,采用非監督學習算法進行賬戶分類過程,采用PageRank算法對社區關系進行離散化處理。PageRank算法可根據網頁之間的超鏈接,計算網頁排名。PageRank算法也可作為評估網頁優化的結果重要參考因素[7?9]。
PageRank算法為了解決部分“沒有出鏈的頁面”帶來的陷阱問題,增加隨機跳出瀏覽的策略,即隨機地打開某一頁面,隨機地點擊其中某一鏈接。頁面的PageRank值決定了頁面被隨機訪問的可能性大小。假設持續點擊網頁上的鏈接,最后抵達一個沒有出鏈的頁面,此時隨機選擇一個頁面開始新的瀏覽。e=0.85表示在任意時刻,用戶瀏覽某頁面后會繼續瀏覽的概率。[1-e=0.15]表示在任意時刻,用戶停止繼續向前瀏覽,改為隨機選擇所有頁面中的某一頁面開始瀏覽的概率。完整的PageRank算法如下式所示:
[PageRank(pi)=1-eN+epj∈M(pi)PageRank(pj)L(pj)]
式中:p1,p2,…,pn是待計算頁面;M(pi)是鏈入pi頁面的集合;L(pj)是鏈出pj的集合;N是所有頁面總量。
主要特征屬性中登錄行為特征屬性的離散化采用單位時間段的頻次來表示:[vi=sid],其中si表示在時間段d內的行為頻次,例如賬戶i在一個月內的登錄的次數為n,該賬戶的登錄行為屬性離散化為[vi=n30]。
發帖行為特征屬性的離散值與賬戶在一段時間d內的發帖情況有關。假設賬戶的每一個發帖最終檢測結果有一個惡意程度wi,則賬戶的發帖行為的特征屬性離散值[W=wi]。在構建惡意檢測系統后,賬戶的發帖行為通過影響發帖行為特征屬性來更新信用模型,保持惡意檢測系統的自適應。
并非所有的特征屬性都需要離散化處理,由于認證等級一般包含有限狀態集,可以直接作為分類符號。本文未給出的離散化操作,可以根據前面給出的方法進行簡單的仿效,離散化科學合理即可。完成所有的屬性離散化處理后,將進入下一階段完成賬戶的分類。
1.3 賬戶分類
賬戶信用特征屬性的采集,對于部分不能分類的屬性進行離散化,最后需要的工作就是構建賬戶分類模型。賬戶信用特征向量V={x1,x2,…,xn},具有n個特征屬性,用于構建賬戶信用模型。賬戶的信用特征向量,反映了賬戶某一時刻的信用狀態。本文在實驗部分采用K?means算法[10?12]對賬戶進行分類建模。
2 惡意發帖檢測模型
在基于賬戶信用模型中,對于賬戶信用度的影響因素中登錄行為和用戶發帖行為是一個基于時間狀態的影響因子。每一個賬戶可能在任何時間違反網絡社區核心價值觀,即使是當前網絡社區中具有最高信用度的賬戶。所以構建的惡意發帖檢測模塊是基于對于所有賬戶的不信任,建立在概率模型之上。所以采用的基本策略是對于信用度高的賬戶采用比較簡單、約束條件比較寬泛的檢測,允許部分系統疏漏。對于信用度低的賬戶,首先鼓勵其提高信用度;其次對于其發帖增加發帖成本(要求嚴格的發帖驗證,發帖頻次、數量限制等);最后發帖內容經過嚴格的審核。
如果信用模型采用靜態模型,即首次構建模型后保持不變,只能體現網絡社區在某個時刻的賬戶信用狀態,模型只能具有紀念意義而沒有實際價值。如果信用模型中信用屬性值是單調非遞減的,如同QQ等級一樣,惡意賬戶可能增加一個潛伏階段。惡意發帖檢測模型中賬戶的信用特征向量根據特征屬性動態調整,其中主要發帖行為特征屬性,會對賬戶的信用特征向量起到重要影響,長期未登錄賬戶或惡意發帖,賬戶信用受到負極影響;賬戶存在惡意行為,根據惡意的嚴重性不同程度影響賬戶的信用度。
本文設計的基于用戶信用度的檢測模型,該檢測模型帶有反饋鏈,根據用戶發帖是否屬于惡意發帖,以及信息的惡意程度,動態調整用戶的信用特征向量,同時賬戶信用模型也決定了惡意發帖的檢測流程,如圖3所示。系統的初始化模塊主要完成的工作是賬戶信用模型建立,首先完成系統的一個賬戶信用快照。在之后的賬戶行為中動態調整信用模型的某一特征屬性值,圖3中主要是根據賬戶的發帖行為進行分析。賬戶在完成發帖的過程中,首先獲取自己的賬戶信用標記,確定發帖檢測的具體流程,即每一個信用標記映射一個發帖檢測流程。惡意特征庫同樣滿足基于信用標記映射不同的庫大小、內容等。完成發帖檢測之后,通過檢測模型中的反饋鏈,更新信用模型中的發帖行為屬性的值。
3 惡意發帖檢測系統
經典的惡意檢測系統的設計,主要是針對某一發帖文本進行統一路徑的惡意性檢測,如圖4所示。沒有區分不同賬戶的特性,采用一致的處理模式,沒有實現計算資源優化配置。
惡意發帖的源頭是用戶行為,而不是永無止境的帖子。本文構建的惡意發帖檢測系統模型如圖5所示,系統構建在以賬戶信用模型為核心的惡意發帖檢測系統,鼓勵用戶文明發帖,打擊惡意發帖,維護網絡社區的健康可持續發展。用戶發帖的檢測流程為:
(1) 查詢當前賬戶的信用特征屬性向量;
(2) 根據賬戶的信用標記設置發帖前置控制條件。前置控制條件決定了賬戶不一樣的發帖交互情景,如賬戶當日的發帖額度、發帖頻率、確認發帖的驗證碼等。
(3) 發帖檢測過程,后置控制條件的設定,根據當前賬戶信用標記映射的檢測流程,進行惡意檢測。
(4) 反饋檢測結果,更新賬戶信用度。一份帖子會對賬戶的信用度產生影響,影響大小和正負有區別。應根據帖子的檢測結果進行反饋,更新賬戶的特征屬性向量。
(5) 如果是惡意發帖,提取惡意帖特征,加入惡意發帖庫,為惡意發帖的深入學習采集樣本。賬戶信用標記的不是實時更新,采取間隔時間段重建方式。
本系統模型在用戶發帖的流程中把用戶發帖行為分為發帖前置控制、發帖、發帖后置控制、發帖結果4個階段。賬戶的信用模型是根據數據分析理論創建,充分利用了網絡社區在發展中積累的歷史數據。根據模型預測當前發帖行為的惡意程度,調控發帖的前置控制條件,減少網絡社區面臨的風險。模型的自身成長是和網絡社區的成長必然緊密相聯,根據賬戶在社區的每一次操作行為去更新模型,保證模型的自適應性。
4 實驗分析
本實驗采用網絡爬蟲[13?15]抓取網絡社區的賬戶、發帖等數據信息,對賬戶信用特征屬性進行離散化處理,采用分類算法對賬戶分類。抽取不同簇賬戶的發帖信息,采用惡意檢測算法檢測,分析不同簇賬戶發帖的惡意發帖量和發帖惡意復雜度,驗證分類有效性。
4.1 實驗說明
本實驗基于Python語言設計網絡爬蟲,抓取國內知名網絡社區博客園的賬戶、發帖等信息,爬蟲抓取的主要數據字段為賬戶名、賬戶簡介、關注者、粉絲、發帖信息和賬戶在社區的最近發帖活動記錄。目前博客園用戶超過了17萬,以本人賬戶主頁為爬蟲種子,最終爬到的賬戶信息為13萬左右,還剩4萬多的用戶沒有爬取到,分析這部分賬戶是既沒有粉絲也不關注其他用戶的孤島,整個數據集不采用數據庫存儲,采用文本文件保存,每一行采用賬戶作為關鍵字,之后為具體采集屬性的數據,主要原因是賬戶數據量在可控范圍內,文本可以直觀查閱、驗證數據。實驗部分采用PageRank算法離散化的社區關系,采用K?means分類算法進行賬戶信用分類。
4.2 信用計算
本實驗主要通過賬戶信用主要影響因子——賬戶信息、社區關系、最近發帖行為,實現對賬戶信用模型的建立,其他沒能考慮的因子是因為實驗數據的不完整(不能獲取賬戶的登錄行為以及認證等級)以及當前社區的條件下不是特征屬性(例如博客園不支持其他社區號登錄)。
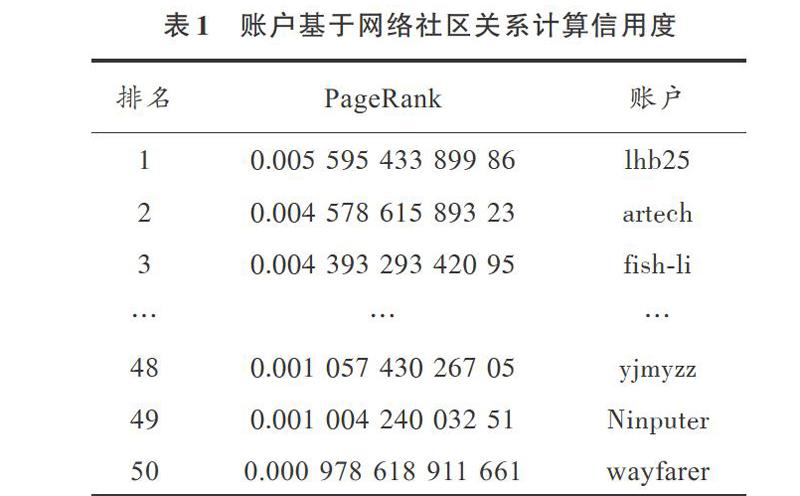
本實驗將根據PageRank算法進行實驗。提取數據集中每個賬戶的關注者,對于爬取的賬戶網絡社區關系數據采用PageRank算法進行計算,直到轉移矩陣的收斂,得到如表1所示的排名前50的賬戶信用度值。
采用網絡社區關系構建的賬戶信用模型,對其計算的結果進行分析,可以發現信用度比較高的賬戶,其信用度影響因素比信用度比較低的賬戶具有突出表現。如圖6所示為最佳賬戶的賬戶信息,可以看出其賬戶簡介信息十分飽滿,而且信息的真實度比較高,其對社區貢獻和忠誠度比較高。
如圖7所示為非高信用度賬戶的賬戶信息,賬戶信息非常匱乏,只包含系統提供的默認信息,并且網絡社區的參與不活躍。如圖8所示為高信用用戶的最近發帖行為,一般高信用賬戶會持續性地活躍在網絡社區中,并且對自己的發帖負責而且具有比較好的發帖質量。在基于網絡社區關系的信用模型中沒有考慮到賬戶的最近發帖行為方式,可能信用低的賬戶在社區同樣比較活躍,很可能是最近加入社區的潛在優質賬戶。所以對于低信用度賬戶的正常發帖采用鼓勵手段,出現惡意發帖采取重罰手段。
4.3 賬戶分類
完成對賬戶的信用度采取非遞增排序,然后對信用度取10的對數,繪制如圖9所示的賬戶信用度的分布曲線。分析圖9可知社區處于成長期,大部分的賬戶信用度較低,信用度高的用戶較少。
采用K?means算法對賬戶進行聚類分析,結果如表2所示,本實驗將賬戶分為3類,映射為優、良、差。根據對重心觀察,可見劃分結果滿足要求。表2展示了不同簇中的賬戶在整個社區的規模程度,為惡意發帖檢測提供了決策意見。
5 結 語
本文提出并實現了基于賬戶信用模型的惡意發帖檢測系統,該系統建立在以賬戶信用為核心模型基礎上,量化每個賬戶的信用,對賬戶進行分級,識別惡意賬戶,并將每一個惡意發帖都反饋至賬戶信用模型中,實現惡意發帖檢測系統自動調整。本文建立的信用模型,在選取信用的影響因素方面,主要依靠實踐經驗,需要在后續研究中建立數學模型加以改進。本文的實驗部分未能完成所有屬性特征的離散化處理,選取了代表性的屬性,后續研究中需要完成不能分類的屬性離散化處理。
表2 分類結果
參考文獻
[1] 莫倩,楊珂.網絡水軍識別研究[J].軟件學報,2014(7):1505?1526.
[2] 王永剛,蔡飛志,LUA E K,等.一種社交網絡虛假信息傳播控制方法[J].計算機研究與發展,2012(z2):131?137.
[3] 楊長春,徐小松,葉施仁,等.基于文本相似度的微博網絡水軍發現算法[J].微電子學與計算機,2014,31(3):82?85.
[4] 楊清龍.基于網絡日志的互聯網用戶行為分析[D].武漢:華中科技大學,2013.
[5] 李向華,杜鵑.社交網絡用戶信用評價指標體系研究[J].標準科學,2015(1):76?78.
[6] 徐昕虹,張保穩,孔凌宇,等.一種論壇的網絡用戶信用評價體系[J].信息安全與通信保密,2013(1):60?62.
[7] 舒琰,向陽,張騏,等.基于PageRank的微博排名MapReduce算法研究[J].計算機技術與發展,2013(2):73?76.
[8] 李稚楹,楊武,謝治軍.PageRank算法研究綜述[J].計算機科學,2011,38(10A):185?188.
[9] 王德廣,周志剛,梁旭.PageRank算法的分析及其改進[J].計算機工程,2010,36(22):291?292.
[10] 吳夙慧,成穎,鄭彥寧,等.K?means算法研究綜述[J].現代圖書情報技術,2011(5):28?35.
[11] 馮超.K?means聚類算法的研究[D].大連:大連理工大學,2007.
[12] 黃韜,劉勝輝,譚艷娜.基于K?means聚類算法的研究[J].計算機技術與發展,2011,21(7):54?57.
[13] 喬峰.基于模板化網絡爬蟲技術的Web網頁信息抽取[D].成都:電子科技大學,2012.
[14] 李俊麗.基于Linux的python多線程爬蟲程序設計[J].計算機與數字工程,2015,43(5):861?863.
[15] 段兵營.搜索引擎中網絡爬蟲的研究與實現[D].西安:西安電子科技大學,2014.
猜你喜歡
現代管理科學(2017年4期)2017-04-06 16:58:48
時代金融(2017年6期)2017-03-25 11:42:18
時代金融(2017年6期)2017-03-25 11:30:07
商場現代化(2016年26期)2016-11-21 22:12:27
商場現代化(2016年24期)2016-11-02 19:33:11
商(2016年25期)2016-07-29 21:07:14
電腦知識與技術(2016年16期)2016-07-22 18:50:34
商場現代化(2015年17期)2015-08-18 15:26:57
中國經貿導刊(2015年5期)2015-03-31 12:49:46
中國高新技術企業(2014年24期)2014-12-23 19:34:07
