數(shù)據(jù)挖掘在大學(xué)英語成績預(yù)測中的應(yīng)用研究
2016-05-16 01:57:05欒紅波文福安
軟件 2016年3期
關(guān)鍵詞:數(shù)據(jù)挖掘大學(xué)英語
欒紅波+文福安


摘要:“數(shù)據(jù)驅(qū)動(dòng)學(xué)校,分析變革教育”的大數(shù)據(jù)時(shí)代已經(jīng)來臨,數(shù)據(jù)挖掘這一技術(shù)在教育行業(yè)隨之誕生。隨著社會(huì)對英語的應(yīng)用日益增加,英語學(xué)習(xí)日益重要,大數(shù)據(jù)及數(shù)據(jù)挖掘技術(shù)在英語教學(xué)與學(xué)習(xí)中的應(yīng)用與研究將成為新的發(fā)展趨勢。本研究是基于大學(xué)英語技能訓(xùn)練系統(tǒng)產(chǎn)生的教學(xué)數(shù)據(jù)進(jìn)行的挖掘分析,選取和學(xué)生成績相關(guān)的數(shù)據(jù)作為特征,以學(xué)生考試成績?yōu)槟繕?biāo),運(yùn)用GBDT模型進(jìn)行模型訓(xùn)練,實(shí)現(xiàn)了學(xué)生成績的預(yù)測,經(jīng)過評估、分析發(fā)現(xiàn)用數(shù)據(jù)挖掘技術(shù)可以比較準(zhǔn)確的預(yù)估學(xué)生成績,驗(yàn)證了數(shù)據(jù)挖掘技術(shù)在大學(xué)英語學(xué)習(xí)中的應(yīng)用,以及GBDT模型對結(jié)果預(yù)測的影響,對學(xué)生學(xué)習(xí)和教師教學(xué)有很大的指導(dǎo)作用和使用價(jià)值。
關(guān)鍵詞:數(shù)據(jù)挖掘;大學(xué)英語;預(yù)測
中圖分類號:TP391.1 文獻(xiàn)標(biāo)識碼:A DOI:10.3969/j.issn.1003-6970.2016.03.017
0引言
近年來,教育改革一直是社會(huì)關(guān)注的重點(diǎn)問題之一。隨著社會(huì)的不斷進(jìn)步,高端科學(xué)技術(shù)、產(chǎn)品在社會(huì)的各個(gè)領(lǐng)域中得到了廣泛應(yīng)用,使得人們生活質(zhì)量在不斷提高。同樣,教育行業(yè)的教學(xué)質(zhì)量也隨之在不斷地提升,教學(xué)方法、手段不斷、教學(xué)環(huán)境等處于更新?lián)Q代過程中。隨著互聯(lián)網(wǎng)的快速發(fā)展,大數(shù)據(jù)隨之而生,使數(shù)據(jù)挖掘技術(shù)在教育領(lǐng)域中不斷地得到應(yīng)用,為學(xué)校、教師、學(xué)生都提供了便利的教學(xué)條件,而對于數(shù)據(jù)挖掘技術(shù)在教育領(lǐng)域的應(yīng)用也受到廣泛的關(guān)注。在英語學(xué)習(xí)過程中,影響學(xué)生學(xué)習(xí)英語的因素很多,需要對各因素進(jìn)行綜合分析。在大數(shù)據(jù)時(shí)代,如何從大量數(shù)據(jù)中找出有價(jià)值的信息并利用這些信息預(yù)測未知的或未來值的過程變得愈加重要,數(shù)據(jù)挖掘技術(shù)就是通過構(gòu)建相關(guān)模型,探索信息之間的相關(guān)關(guān)系。
1數(shù)據(jù)挖掘技術(shù)理論
1.1數(shù)據(jù)挖掘概念
數(shù)據(jù)挖掘(data mining)就是從大量的、不完全的、有噪聲的、模糊的、隨機(jī)的實(shí)際應(yīng)用數(shù)據(jù)中提取隱含其中的、事先未知的、但又具有潛在價(jià)值的信息和知識過程。數(shù)據(jù)挖掘是一門由多個(gè)學(xué)科交叉與融合而形成的新興學(xué)科,集成了眾多學(xué)科中成熟的工具和技術(shù),包括數(shù)據(jù)庫技術(shù)、統(tǒng)計(jì)學(xué)、機(jī)器學(xué)習(xí)、模式識別、人工智能和神經(jīng)網(wǎng)絡(luò)等。
數(shù)據(jù)挖掘的技術(shù)有很多種,按照不同的分類有不同的分類法。一般分為有監(jiān)督算法和無監(jiān)督算法,其中有監(jiān)督算法主要有邏輯回歸、決策樹等,無監(jiān)督學(xué)習(xí)主要包括聚類、最鄰近距離、支持向量機(jī)等。從應(yīng)用角度上可以分為分類算法、回歸算法、聚類分析算法、關(guān)聯(lián)規(guī)則、時(shí)序和偏差檢查算法。
1.2 GBDT算法簡介
決策樹是一個(gè)具有樹狀結(jié)構(gòu)的模型,可以看成if-then的規(guī)則結(jié)合,從根節(jié)點(diǎn)開始在每個(gè)節(jié)點(diǎn)上按照給定標(biāo)準(zhǔn)選擇測試屬性,然后按照相應(yīng)屬性的所有可能取值向下建立分枝、劃分訓(xùn)練樣本,直到一個(gè)節(jié)點(diǎn)上的所有樣本都被劃分到同一個(gè)類,或者某一節(jié)點(diǎn)中的樣本數(shù)量低于給定值時(shí)為止,這一階段最關(guān)鍵的操作是在樹的節(jié)點(diǎn)上選擇最佳劃分方式。最佳劃分結(jié)點(diǎn)方法的選擇標(biāo)準(zhǔn)有信息增益、基尼指數(shù)等。
GBDT的全稱是Gradient Boosting Deeision Tree,其中Gradient Boosting和Deeision Tree是兩個(gè)獨(dú)立的概念。Boosting是用一些弱分類器的組合來構(gòu)造一個(gè)強(qiáng)分類器,GBDT即通過迭代多棵樹來共同決策。其核心就在于每一棵樹都是之前所有樹結(jié)論和的殘差,這個(gè)殘差就是一個(gè)加預(yù)測值后能得真實(shí)值的累加量。因此,GBDT是一種迭代的決策樹算法,該算法由多棵決策樹組成,所有樹的結(jié)論累加起來做最終結(jié)果。GBDT是一個(gè)應(yīng)用很廣泛的算法。本文主要應(yīng)用GBDT算法做回歸。
2英語考試成績預(yù)測的實(shí)現(xiàn)
本研究運(yùn)用GBDT算法對大學(xué)英語技能訓(xùn)練系統(tǒng)中學(xué)生成績進(jìn)行預(yù)測,歷經(jīng)了數(shù)據(jù)提取、數(shù)據(jù)預(yù)處理、特征選擇、訓(xùn)練模型、預(yù)測未知數(shù)據(jù)等關(guān)鍵步驟,如圖1。其中,數(shù)據(jù)提取、預(yù)處理及特征選擇是處理訓(xùn)練數(shù)據(jù)集的過程,模型訓(xùn)練階段及參數(shù)調(diào)整是個(gè)不斷優(yōu)化、反復(fù)執(zhí)行的過程,直到得到預(yù)期的結(jié)果。
2.1數(shù)據(jù)提取和預(yù)處理
本研究主要從大學(xué)英語技能訓(xùn)練系統(tǒng)中提取學(xué)生信息,分別選取了2013至2014年春、秋季四個(gè)學(xué)年中一、二年級學(xué)生數(shù)據(jù),最終的數(shù)據(jù)文件類型選擇以純文本形式存儲表格數(shù)據(jù)的CSV格式。
數(shù)據(jù)預(yù)處理是在數(shù)據(jù)挖掘前的數(shù)據(jù)準(zhǔn)備工作,數(shù)據(jù)的好壞是預(yù)測結(jié)果好壞的前提條件,其目的是去除與目標(biāo)不相關(guān)的數(shù)據(jù)屬性和內(nèi)容,為數(shù)據(jù)挖掘提供干凈、準(zhǔn)確、更有針對性的數(shù)據(jù),減少挖掘算法的數(shù)據(jù)處理量,提高挖掘效率和最終結(jié)果的準(zhǔn)確度。數(shù)據(jù)預(yù)處理的方法有很多,主要有數(shù)據(jù)選取、數(shù)據(jù)清理、數(shù)據(jù)屬性取值一致化、數(shù)據(jù)集成、數(shù)據(jù)轉(zhuǎn)換和數(shù)據(jù)簡化等。
本次實(shí)驗(yàn)按照上面所述的數(shù)據(jù)預(yù)處理規(guī)則進(jìn)行相應(yīng)處理,最終得到8000條數(shù)據(jù)作為訓(xùn)練樣本。
2.2特征選擇
特征選擇是選擇獲得相應(yīng)模型和算法最好性能的特征集,在數(shù)據(jù)挖掘中占有相當(dāng)重要的地位。本次研究通過使用scikit-learn的MINE工具計(jì)算各個(gè)特征與預(yù)測目標(biāo)的相關(guān)性,得到每個(gè)特征的相關(guān)性后對所選特征進(jìn)行排序,經(jīng)過對數(shù)據(jù)各維度進(jìn)行選取,特征主要分為兩種,一種為數(shù)值型特征,如答題時(shí)長、自評分?jǐn)?shù)等,另一種為類別型特征,如性別、題型等。特征確定后,對每個(gè)特征進(jìn)行編碼,將每個(gè)無序特征轉(zhuǎn)化為數(shù)值向量,就是所謂的詞向量模型。變換后的向量長度對于詞典長度,每個(gè)詞對應(yīng)于向量中的一個(gè)元素。
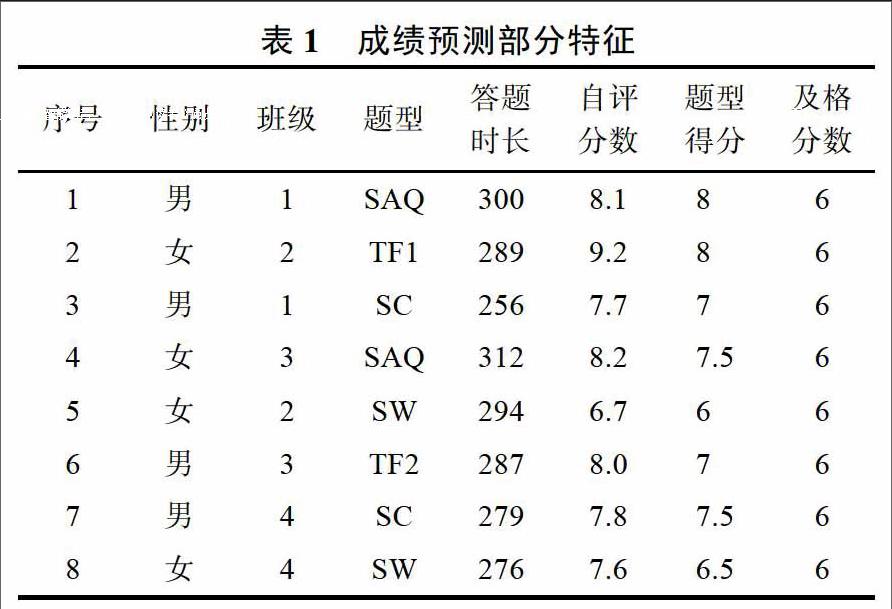
本次實(shí)驗(yàn)通過特征處理,確定了對挖掘?qū)W生成績預(yù)測比較重要的特征,如學(xué)號、姓名、性別、答題時(shí)長、題型等18個(gè)維度。下表1列出了部分特征及數(shù)據(jù)。
2.3模型訓(xùn)練
模型訓(xùn)練是根據(jù)已知數(shù)據(jù)尋找模型參數(shù)的過程,通過給定數(shù)據(jù)和模型假設(shè)空間,可以構(gòu)建出優(yōu)化問題,確定相關(guān)參數(shù)使得預(yù)測目標(biāo)最優(yōu)化,即模型訓(xùn)練的過程是不斷的調(diào)試,直至最優(yōu)。
本次研究使用K-fold交叉驗(yàn)證法,將數(shù)據(jù)訓(xùn)練集隨機(jī)劃分為訓(xùn)練和測試兩部分,通過Python語言、seikit-learn及其它相關(guān)第三方庫進(jìn)行模型訓(xùn)練。
輸入訓(xùn)練集,使用GBDT模型,選擇損失函數(shù)、樹的最大深度、最小葉子節(jié)點(diǎn)個(gè)數(shù)及其它相關(guān)參數(shù),反復(fù)調(diào)整、優(yōu)化參數(shù),使之經(jīng)過數(shù)據(jù)挖掘技術(shù)預(yù)測的目標(biāo)——學(xué)生英語成績最接近真實(shí)的數(shù)據(jù)。
輸入測試數(shù)據(jù),確定預(yù)測的目標(biāo)是否接近真實(shí)英語成績,驗(yàn)證所選模型及相關(guān)參數(shù)的正確性、合理性。
3預(yù)測結(jié)果及分析
本研究采用數(shù)據(jù)挖掘回歸方法GBDT模型,以大學(xué)英語技能訓(xùn)練系統(tǒng)中兩個(gè)學(xué)年的學(xué)生英語考試的相關(guān)數(shù)據(jù)為訓(xùn)練數(shù)據(jù),在Python及相關(guān)的學(xué)習(xí)包數(shù)據(jù)挖掘環(huán)境中,通過對相關(guān)屬性的不斷精簡,最終構(gòu)建了大學(xué)英語考試學(xué)生成績的預(yù)測模型,并實(shí)現(xiàn)了學(xué)生成績的預(yù)測,從而得到與學(xué)生真實(shí)成績比較相近的分?jǐn)?shù)。該模型以題型、答題時(shí)間、自評成績等18個(gè)特征最終為GBDT的形成因素,構(gòu)建決策樹6課,最小樣本葉子結(jié)點(diǎn)6個(gè),最大深度為5。下表2為訓(xùn)練數(shù)據(jù)的部分真實(shí)成績與預(yù)測成績,其中滿分為50分。
實(shí)驗(yàn)結(jié)果使用MAE(Mean Absolute Error)進(jìn)行評估,MAE表示預(yù)測值與真實(shí)值之間的差距,其值越小越好,最終得到所有數(shù)據(jù)集的MAE為0.7,其中79.86%的數(shù)據(jù)誤差為0,即預(yù)測的準(zhǔn)確度為79.86%。對比真實(shí)成績與預(yù)測成績曲線圖,發(fā)現(xiàn)兩條曲線很相近,說明預(yù)測的分?jǐn)?shù)很接近真實(shí)分?jǐn)?shù)。
上實(shí)驗(yàn)結(jié)果表明,GBDT模型能夠?qū)Υ髮W(xué)英語考試成績進(jìn)行比較準(zhǔn)確預(yù)測,通過數(shù)據(jù)挖掘技術(shù),對學(xué)生考試成績進(jìn)行分析評估,提取出各個(gè)層次的學(xué)生對教學(xué)過程中英語知識的掌握程度,進(jìn)行有針對性的教學(xué)。
4結(jié)論
本文用大學(xué)英語技能訓(xùn)練系統(tǒng)中和成績相關(guān)特征的數(shù)據(jù),使用GBDT模型實(shí)現(xiàn)了學(xué)生成績的預(yù)測,通過實(shí)驗(yàn)證明數(shù)據(jù)挖掘技術(shù)在英語成績的預(yù)測的準(zhǔn)確性、可行性。數(shù)據(jù)挖掘技術(shù)在教育行業(yè)中得到很好的應(yīng)用,在大數(shù)據(jù)時(shí)代,運(yùn)用數(shù)據(jù)挖掘技術(shù)必將改變教育的傳統(tǒng)面貌。本研究對大學(xué)英語成績的預(yù)測有助于學(xué)生英語學(xué)習(xí),以及教師對考試結(jié)果的深入了解。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
知音勵(lì)志·社科版(2016年8期)2016-11-05 02:29:27
科學(xué)與財(cái)富(2016年28期)2016-10-14 22:11:09
考試周刊(2016年77期)2016-10-09 11:19:12
大學(xué)教育(2016年9期)2016-10-09 08:29:59
科技視界(2016年20期)2016-09-29 12:20:03
科技視界(2016年20期)2016-09-29 12:18:36
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
