基于Python的專業網絡爬蟲的設計與實現
2016-05-30 10:48:04姜杉彪黃凱林盧昱江張俊杰曾志高劉強
企業科技與發展 2016年8期
姜杉彪 黃凱林 盧昱江 張俊杰 曾志高 劉強


【摘 要】網絡爬蟲,又稱網頁蜘蛛、網絡機器人。隨著計算機技術的高速發展,互聯網中的信息量越來越大,搜索引擎應運而生。傳統的搜索引擎會有返回結果不精確等局限性。為了解決傳統搜索引擎的局限性,專用型網絡爬蟲在互聯網中越來越常見。同時,專用型網絡爬蟲具有專用性,可以根據制定的規則和特征,最后只體現和篩選出有用的信息。
【關鍵詞】Python;網絡爬蟲;數據挖掘;搜索引擎
【中圖分類號】TP393 【文獻標識碼】A 【文章編號】1674-0688(2016)08-0017-03
0 引言
在搜索引擎的使用過程中,用戶認為通用搜索引擎都有一個局限性,那就是在搜索結果中附帶太多不必要的信息。用戶在使用搜索引擎后,仍然需要人為地從搜索結果中尋找檢索最終需要的信息。然而,在互聯網飛速發展的狀況下,網絡信息量突發式的暴增,計算機硬件設備的技術不斷進步,網絡的信息容量和帶寬也是日新月異,在互聯網中出現了多媒體和富文本的新技術。隨著這些信息的不斷增加和積累,通用搜索引擎對類似這種多媒體或者富文本的搜索能力越來越差[1-2]。
為了解決部分用戶對信息的檢索要求,專用型網絡爬蟲應運而生,為用戶提供特定的信息抓取,開發出不同特性的專用型網絡爬蟲[3]。本文以網易新聞爬蟲實例為引導,對如何開發出專用型網絡爬蟲及制定不同的爬蟲策略進行了深入的研究。
1 爬蟲系統需求分析與設計
為了保證網絡爬蟲系統的開發過程順利,以及保證最終的開發結果能滿足基本的功能需求,必須在開發系統之前進行分析,并設計出符合該系統的代碼規范及功能模塊等。整個網絡爬蟲系統均使用模塊化設計,一個功能類作為一個功能模塊。這樣做的目的是一方面可以便于代碼的維護,另一方面可以增加代碼的重用性。通過將整個系統進行模塊劃分,每個功能模塊只實現一個功能,最后所有的模塊功能完成后,整個網絡爬蟲系統就能實現當初進行定義的系統功能[4-5]。本系統的需求分析的任務是通過調查特定用戶的上網行為習慣,開發符合一類上網用戶使用的專用型網絡爬蟲,根據用戶的功能需求明確系統需要實現的各個功能。并且,在設計系統的同時,需要考慮系統今后的維護及改進問題。本文以網易新聞爬蟲系統為例,探討專用爬蟲系統的設計與實現。
1.1 功能性需求分析
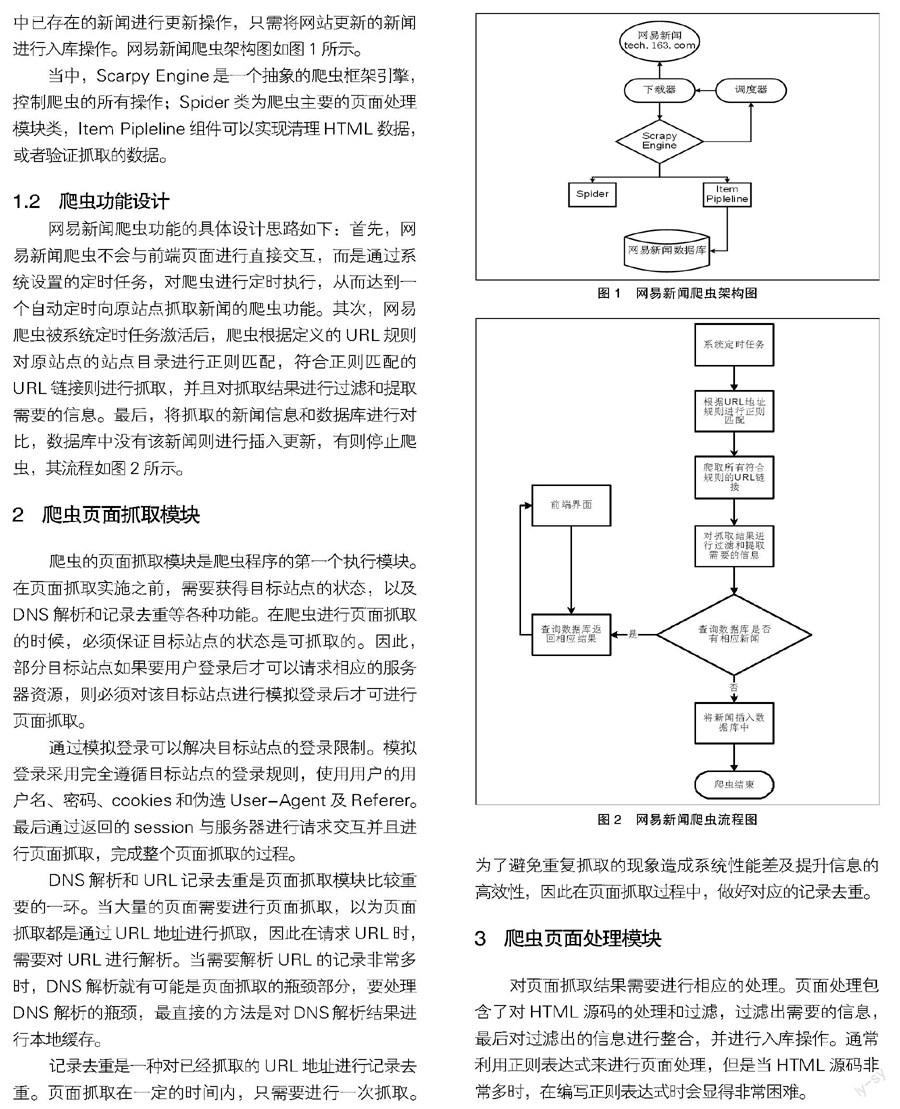
網易新聞爬蟲的具體功能包括對新聞標題、新聞ID、新聞來源等信息進行抓取并存入數據庫中。網易新聞爬蟲需要抓取的URL鏈接是變化的,而不是固定的,因此在爬蟲的URL策略中,需要解決URL鏈接的訪問策略和去重。原站點網易新聞中的各類新聞,根據分析可以看出,所有新聞一旦發布就不會對新聞內容進行二次更新,因此網易新聞爬蟲最終的抓取結果不需要對數據庫中已存在的新聞進行更新操作,只需將網站更新的新聞進行入庫操作。網易新聞爬蟲架構圖如圖1所示。
當中,Scarpy Engine是一個抽象的爬蟲框架引擎,控制爬蟲的所有操作;Spider類為爬蟲主要的頁面處理模塊類,Item Pipleline組件可以實現清理HTML數據,或者驗證抓取的數據。
1.2 爬蟲功能設計
網易新聞爬蟲功能的具體設計思路如下:首先,網易新聞爬蟲不會與前端頁面進行直接交互,而是通過系統設置的定時任務,對爬蟲進行定時執行,從而達到一個自動定時向原站點抓取新聞的爬蟲功能。其次,網易爬蟲被系統定時任務激活后,爬蟲根據定義的URL規則對原站點的站點目錄進行正則匹配,符合正則匹配的URL鏈接則進行抓取,并且對抓取結果進行過濾和提取需要的信息。最后,將抓取的新聞信息和數據庫進行對比,數據庫中沒有該新聞則進行插入更新,有則停止爬蟲,其流程如圖2所示。
2 爬蟲頁面抓取模塊
爬蟲的頁面抓取模塊是爬蟲程序的第一個執行模塊。在頁面抓取實施之前,需要獲得目標站點的狀態,以及DNS解析和記錄去重等各種功能。在爬蟲進行頁面抓取的時候,必須保證目標站點的狀態是可抓取的。因此,部分目標站點如果要用戶登錄后才可以請求相應的服務器資源,則必須對該目標站點進行模擬登錄后才可進行頁面抓取。
通過模擬登錄可以解決目標站點的登錄限制。模擬登錄采用完全遵循目標站點的登錄規則,使用用戶的用戶名、密碼、cookies和偽造User-Agent及Referer。最后通過返回的session與服務器進行請求交互并且進行頁面抓取,完成整個頁面抓取的過程。
DNS解析和URL記錄去重是頁面抓取模塊比較重要的一環。當大量的頁面需要進行頁面抓取,以為頁面抓取都是通過URL地址進行抓取,因此在請求URL時,需要對URL進行解析。當需要解析URL的記錄非常多時,DNS解析就有可能是頁面抓取的瓶頸部分,要處理DNS解析的瓶頸,最直接的方法是對DNS解析結果進行本地緩存。
記錄去重是一種對已經抓取的URL地址進行記錄去重。頁面抓取在一定的時間內,只需要進行一次抓取。為了避免重復抓取的現象造成系統性能差及提升信息的高效性,因此在頁面抓取過程中,做好對應的記錄去重。
3 爬蟲頁面處理模塊
對頁面抓取結果需要進行相應的處理。頁面處理包含了對HTML源碼的處理和過濾,過濾出需要的信息,最后對過濾出的信息進行整合,并進行入庫操作。通常利用正則表達式來進行頁面處理,但是當HTML源碼非常多時,在編寫正則表達式時會顯得非常困難。
接下來利用XPath對HTML源碼進行過濾操作,通常不同的處理需求,定義不同的XPath語法。例如,get_title方法的XPath語法如下所示:title=response.xpath("/ html/head/
title/text ()").extract()。僅需通過該XPath語法,就能過濾出新聞的標題,而不需要編寫復雜的正則表達式對象。再如,get_source方法的XPath語法如下所示:source=response.xpath("http://div[@class='ep-time-sourec-
DGray']/text()").extract()。經過get_title和get_source這幾種方法后,頁面處理模塊最終可以得到一條新聞中例如新聞編號、新聞標題、新聞來源等這些信息。得到這些原始數據后,將這些數據整合為一個列表,傳遞到爬蟲入庫模塊中。流程如圖3所示。
4 爬蟲系統功能實現
網易新聞的功能界面中,由于網易新聞的不定期更新,為了節約服務器的資源利用,設置網易爬蟲的工作時間是每一個小時自動執行一次。在網易新聞的功能界面中,顯示的是當天所有的新聞,點擊新聞的標題,就可以跳轉到原網站網易新聞的對應新聞界面中(如圖4所示)。
爬蟲程序根據定義的URL規則,可以對原站點所有符合正則匹配的URL鏈接進行抓取處理。
day = time.strftime('%m%d')
name = "news"
allowed_domains = ["tech.163.com"]
start_urls = ['http://tech.163.com']
rules = [
Rule(LinkExtractor(allow=r"/15/" + day + "/\d+/*"),
callback="parse_news",follow=True)]
5 結論
本文通過使用Python語言的庫的調用,實現了一個簡單的網絡爬蟲系統。頁面抓取的效率及結果也是對爬蟲性能的一個考驗。整個互聯網的站點數量龐大,所有站點的開發過程中遵循的原則不一致,代碼風格不一致。因此對整個爬蟲的頁面抓取模塊是非常大的挑戰,需要對不同的代碼風格做不同的處理,但是最終得到的結果需要是一樣的。在將來的工作中,我們將進一步提高爬蟲的速度。
參 考 文 獻
[1]李勇,韓亮.主題搜索引擎中網絡爬蟲的搜索策略研究[J].計算機與數字工程,2008,228(10):50-53.
[2]羅剛,王振東.自己動手寫網絡爬蟲[M].北京:清華大學出版社,2010.
[3](美)Miguel Grinberg.Flask Web開發[M].安道,譯.北京:人民郵電出版社,2015.
[4]Magnus Lie Hetland.Python基礎教程(第二版)[M].司維,曾軍崴,譚穎華,等,譯.北京:人民郵電出版社,2010.
[5]葉允明,于水,馬范援,等.分布式Web Crawler的研究:結構、算法和策略[J].電子學報,2002,30(12):2008-2011.
[責任編輯:鐘聲賢]
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
信息通信技術(2015年6期)2015-12-26 01:16:46
中國衛生(2015年12期)2015-11-10 05:13:38
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
電子設計工程(2014年18期)2014-02-27 12:00:13
計算機應用文摘(2009年17期)2009-04-29 00:44:03
