云計算技術在交通流量分析系統設計中的應用研究
2017-06-27 19:15:09高秀艷耿興隆
科技傳播 2017年11期
高秀艷+耿興隆
摘 要 當今社會,隨著機動車數量暴增,城市交通擁堵、交通信息管理等問題日益嚴重。研究并設計合適的交通流量分析系統,可以通過采集交通流量的大數據,掌握實時道路情況并有效預測未來某時段的道路交通。采用hadoop分布式文件系統對海量交通大數據進行存儲,使用神經網絡算法對數據進行建模處理,使用MapReduce作為核心算法進行運算,實驗證明,這是良好的解決方案。
關鍵詞 智能交通;大數據;云計算;Hadoop
中圖分類號 TP3 文獻標識碼 A 文章編號 1674-6708(2017)188-0066-02
當今社會,隨著機動車數量暴增,城市交通擁堵、交通信息管理等問題日益嚴重。在城市飛速發展及車輛迅速增加的背景下,研究并設計合適的交通流量分析系統,使其能適時收集交通流量數據并對數據做出合理正確的分析,從而及時掌握實時道路情況并進而有效預測未來某時段的道路交通情況已迫在眉睫。由于交通數據具有大數據的特點,因此使用分布式文件系統進行數據存儲,采用大數據的處理技術對收集到的海量數據建立合適的數據處理模型并進行分析處理,采用MapReduce作為核心算法進行運算,最終實現流量情況預測。
1 大數據主要處理技術
目前,對大數據的處理技術主要有以下
幾種[1-3]:
1)數據挖掘。數據挖掘是對數據進行篩選等有效處理的一種技術,目的是從海量數據中通過去噪、轉換、凈化、挖掘提取等過程篩選出有價值的部分。在處理過程中經常借助多處理階段模型、機器學習、支持向量機等。
2)遺傳算法。遺傳算法的概念來源于達爾文的生物進化論,即從海量的可能結果中獲取最優的個體,在實際應用中常用來獲得最優解。其基本思想是從給定的候選解中,使用根據適應條件計算出的適應度對其進行遞歸淘汰,直至得到最優解。遺傳算法是對大量數據進行篩選提取有用信息的重要手段。
3)神經網絡。神經網絡(Artificial Neural Networks,即ANNs)是模式識別中經常用到的算法,它是模仿動物神經結構及行為特征的分布式并行信息處理的數據處理模型。常用的人工神經網絡模型有BP、RBF、Hopfield等。在眾多的神經網絡工具中, NeuroSolutions憑借其良好的網絡設計界面、優化的遺傳算法以及先進的模型訓練程序,能夠在快速、高效的實現信息獲取方面發揮重要作用。
4)馬爾可夫模型。馬爾可夫模型是一種適合于隨機過程的數據模型,其更為常用的是各種延伸的模型,如隱馬爾可夫模型、灰色馬爾可夫模型等。它在語音識別及圖像識別中應用較為
廣泛。
每一種處理技術都有其特點,但是最關鍵的是對數據的預處理及模型的建立。在模型的建立過程中都需要用大量樣本數據對模型進行訓練,因此樣本的合理性是模型訓練的關鍵,而訓練所需時間則是考慮數據處理算法性能的重要因素。
2 交通流量分析系統設計思想
2.1 系統簡介
本系統通過對交通流量大數據進行分析,充分利用“云計算”及相關技術在交通信息化中的應用,基于“云計算”設計研究了智能交通管理系統設計和解決方案。利用Hadoop系統結構,對3個節點的Hadoop集群進行完全分布式部署,然后在該集群上編寫MapReduce 程序。設計了基于Hadoop的MapReduce模式的交通信息服務系統,并通過仿真系統及模擬數據對該系統進行測試。本系統具有如下特點:
1)所用樣本數據來源具有實際意義。系統在設計及仿真時使用保定市某路口采集到的數據,數據可以反應實際交通流量情況。
2)對數據樣本進行了充分的篩選、降噪處理。
3)對于海量數據采用服務器集群的分布式處理,提高運算速度的同時保證了數據的健壯。
4)平臺搭建使用Linux操作系統,當PC機設備或軟件不能滿足需要時,還可在虛擬機環境下進行仿真。
2.2 系統主要功能
本系統主要通過對采集到的數據進行篩選、降噪等預處理后,使用數據樣本對模型進行訓練,得到能夠反映下一時刻交通流量信息的模型。之后根據給出的當前狀態數據,預測未來時刻的交通情況,進而給出推薦路徑。
2.3 系統模型設計
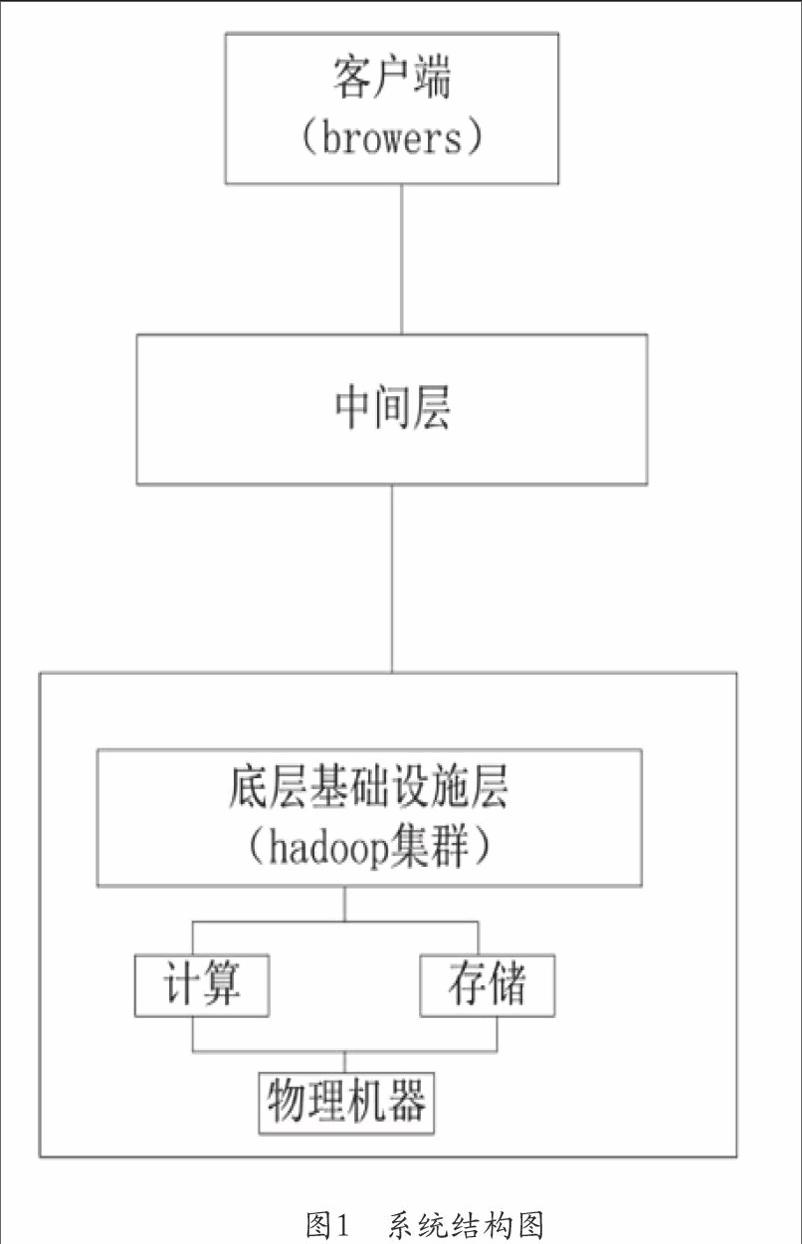
系統模型如圖1所示,系統包括3層,分別為服務器、中間件以及底層。
2.4 系統技術實現
1)數據處理部分:使用神經網絡算法對采集到的樣本進行處理從而得到模型,仿真實驗中使用在保定市某路口采集到的2 000組數據進行,其中1600組用于模型訓練,400組用于流量預測。
2)數據存儲部分:在實驗室中使用PC機,在Linux系統環境下搭建hadoop集群分布式文件系統用于數據的存儲。
3)數據運算:使用MapReduce算法對數據進行統計與分析,分割采集到的交通路徑數據,并輸出最短路徑集。
Map過程實現實現路徑分割的部分代碼如
下[4],其中key值用于表示起點或終點:
對應的Reduce函數實現輸出最短路徑集的部分代碼為:
3 結論
在實驗室環境中利用PC機搭建了“云”平臺,將模擬的代表城市交流流量的大數據信息布到該云上并進行分析調試,仿真完成交通流量信息服務系統的開發和測試。結論如下:
1)Hadoop不是完美的解決方案,由于交通流量數據具有大數據的特點,而且交通情況具有實時性,在對大數據的處理中,神經網絡、優化的遺傳算法等都體現出了各自的優勢。尋找更適合的處理交通流量大數據的算法并用到系統中,將使系統的分析結果更為準確。
2)樣本的采集會對模型的精確產生重要的影響,后續的研究中將更多的考慮其它因素對數據樣本精確性的影響,如:
偶然因素如交通事故對數據造成的不確定性;
天氣原因產生的數據隨機性;
時間對數據樣本的影響,如工作日與非工作日、高峰時段與非高峰時段數據的變化。
參考文獻
[1]甘曉,李國杰.大數據成為信息科技新關注點[N].中國科學報,2012-06-27.
[2]高秀艷,郝艷榮.大數據技術在高校畢業生就業質量評價體系中的應用研究[J].科技傳播,2017,4(7):65-66.
[3]尚光龍,張澤鋒.大數據技術在信息管理中的應用[J].河北北方學院學報,2016,5(5):30-34.
[4]耿興隆,王麗.基于Hadoop的交通流量統計分析系統的應用研究[J].河北軟件職業技術學院學報,2016,3(1):44-47.
基金項目:本文為保定市科技局科學技術研究與發展指導計劃項目(項目編號:16ZG022)。
作者簡介:高秀艷,講師,研究方向計算機軟件教學、模式識別。
耿興隆,講師,研究方向為計算機教學及嵌入式系統開發。
猜你喜歡
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
新聞世界(2016年10期)2016-10-11 20:13:53
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
