大數據和云計算環境下的Hadoop技術研究
2017-07-20 14:55:45張子妍
中國管理信息化 2017年13期
張子妍

[摘 要] 大數據與云計算技術都已經成為信息社會最重要的技術之一, Hadoop是大數據與云計算時代背景下最熱門的技術之一, Hadoop的相關技術對學術研究有重要影響。本文主要對Hadoop技術進行了研究,首先介紹了大數據和云計算的概念,其次介紹了Hadoop的概況以及相關技術的原理,比如核心技術HDFS和MapReduce;再次分析了目前Hadoop所面臨的安全問題,然后描述了Hadoop的發展瓶頸并提出改進方案;最后進行了總結并展望Hadoop、Spark和Storm三者相互結合,混合架構將是未來發展的方向。
[關鍵詞] 大數據;云計算;Hadoop
doi : 10 . 3969 / j . issn . 1673 - 0194 . 2017. 13. 076
[中圖分類號] TP311.13;TP333 [文獻標識碼] A [文章編號] 1673 - 0194(2017)13- 0177- 03
1 概 述
大數據是指通過新的信息處理技術和方式,對數據進行收集、存儲、分析以及處理等,并且能夠利用全新的數據處理技術和方式產生相關聯的預測效應,協助決策,發揮海量快速增長數據的價值。
云計算是指一種特殊的計算模式,它將計算任務分布在資源池中,池中的資源包括計算服務器、存儲服務器、寬帶資源,使用戶能夠按需獲取各種服務。
大數據與云計算之間相得益彰,相輔相成,因為云計算本質上是數據處理技術,其核心是業務模型,大數據是云計算的延伸,是云計算的資產。
目前,海量非結構化的數據分析處理需一種高效并行的編程模型,此時Apache項目基金會研發的Hadoop迅速崛起,Hadoop主要用來進行大數據分析處理。Hadoop的出現解決了大數據并行計算、存儲、管理等關鍵問題,這樣用戶即使對分布式底層細節不了解,也可以開發分布式程序。Hadoop得到了廣泛認可,其優點是不容忽視的,主要有:高擴展性、低成本、高效率、高可靠性。
2 Hadoop相關的技術
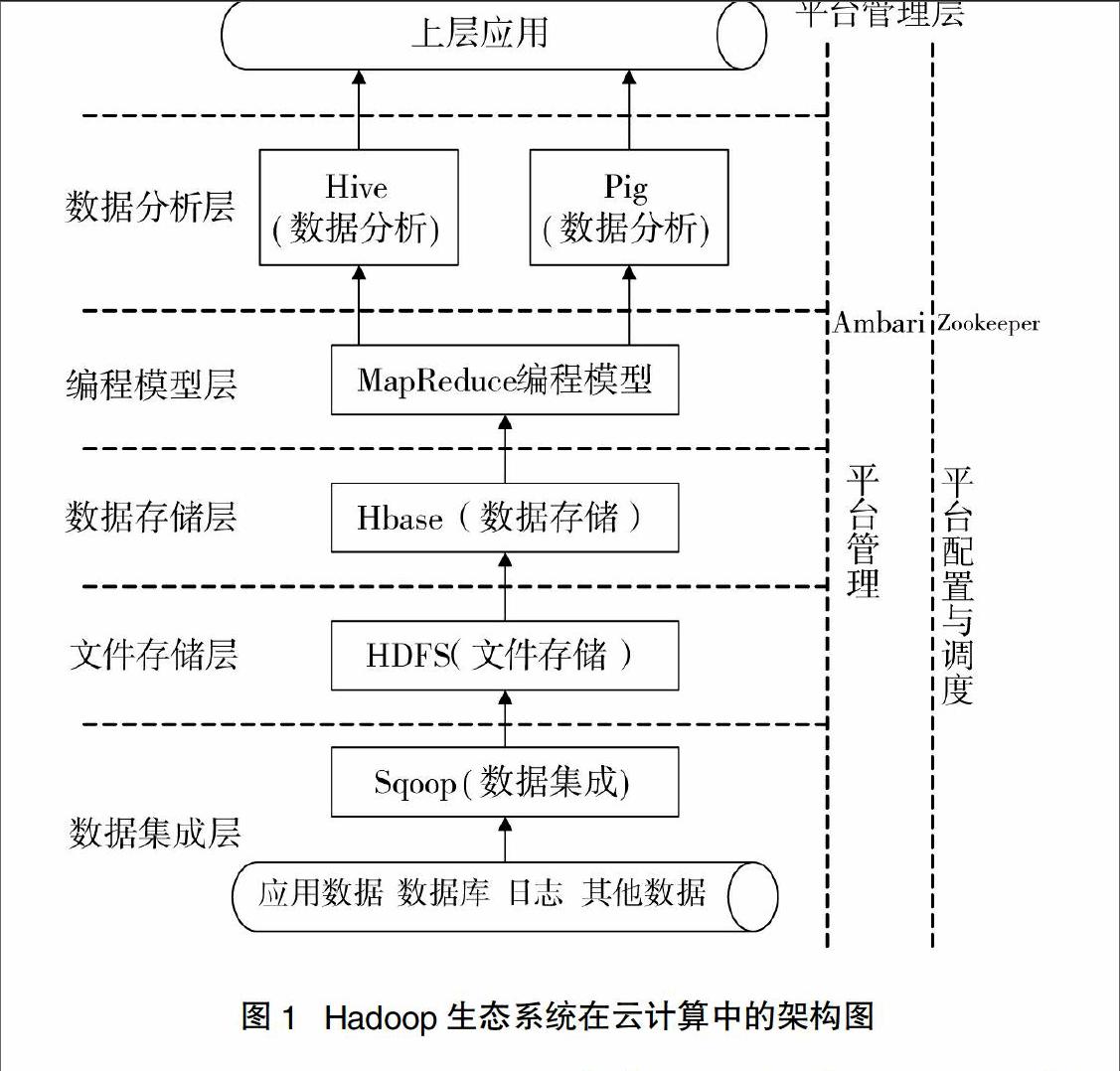
Hadoop可以部署在廉價機器上的處理海量文件存儲與并行計算的云計算開發平臺。Hadoop由HDFS、MapReduce、HBase、Hive、Zookeeper、Pig、Ambari、Sqoop等組成,其中主要部分是HDFS和MapReduce。
2.1 HDFS
HDFS是構建在PC服務器上的高度容錯的分布式文件系統,目的是用于海量數據的處理。HDFS的架構形式是主從架構,HDFS的元數據服務器和數據塊服務器命名為NameNode和DataNode。
NameNode是一個中心服務器,是HDFS的核心結構,負責客戶端對文件的訪問以及管理文件系統的名字空間,存儲HDFS分布式文件系統的元數據信息, NameNode可判斷DataNode是否處在工作狀態,并管理著DataNode上的分塊信息。
DataNode負責管理其所在的節點上的所有數據,能夠根據用戶的請求來查詢數據,周期性地與NameNode通信來告知自己保存的數據塊信息。
2.2 MapReduce
MapReduce設計之初是為了處理一些互聯網數據,MapReduce有簡單的接口和透明的編程環境,極大地節省了開發周期。MapReduce通過處理大量數據來精簡和優化數據集,以便將數據集載入到數據庫管理系統中。
MapReduce也采用了主從架構,將數據處理任務分為兩大過程,分別為:Map過程和Reduce過程。Map過程的任務主要為數據的過濾處理,Reduce過程的任務主要為數據的聚集處理。在Map過程中,第一,要將輸入的數據集分成若干數據塊,再為每一個數據塊分配一個Map小任務;第二,將這些任務分配到集群中的各個節點上,此時在計算過程中會出現一個數據集合(中間結果);第三,將這些數據集合進行排序再產生一個新的數據集合,此時新的數據集合中的數據都具有相同的鍵值;第四,進入Reduce過程,產生最終結果,并輸出到HDFS中。
2.3 Hadoop中的其他技術
Hadoop生態系統除了有HDFS、MapReduce之外還有其他相關技術:
(1)HBase
HBase是用于服務海量數據的存儲以及快速讀寫,它可以通過添加節點來進行線性的擴展,但是卻不支持向后擴。
(2)Hive
Hive是構建在Hadoop之上的數據倉庫基礎架構。可實現數據的提取、轉化、加載等功能。
(3)Zookeeper
Zookeeper分布式協調服務是由許多服務器節點組成的,其目的是對Hadoop集群的運維進行管理。
(4)Pig
Pig可為用戶提供多種接口,用于查詢大型半結構化的數據集,為大型數據提供了一個高層次的抽象,是大數據分析平臺。
(5)Ambari
Ambari是一個基于Web的管理工具,可快速部署、監控以及管理集群。
(6)Sqoop
Sqoop是在Hadoop系統與傳統的數據庫間進行數據交換的工具,它是基于MapReduce來對數據進行操作和處理的。
Hadoop中各個子項目在云計算大數據處理中扮演著不同的角色,以保證底層海量數據可以為頂層應用發揮最大作用,具體架構如下所示。
3 Hadoop的安全問題
Hadoop項目是近期較流行的云計算和大數據分析框架,其安全問題也受到越來越廣泛的重視。
3.1 缺乏安全授權機制
當用戶掌握數據塊的Block ID后就可不通過NameNode的服務權限和身份認證,訪問相應的DataNode,也可以隨意啟動假的DataNode和TaskTracker,對于JobTracker,用戶可以任意修改其他作業,并不受限制。
3.2 缺乏用戶以及服務器的安全認證機制
在缺乏安全認證的情況下,惡意用戶都可以冒充其他用戶,并非法訪問集群、修改JobTracker狀態、任意提交作業,惡意用戶可以冒充合法服務器接受JobTracker和NameNode發布的任務或數據。
4 Hadoop的瓶頸與改進
4.1 實時性處理
Hadoop采用的主要思想是“分而治之”,對大數據的計算進行分解,接下來交由眾多的計算機節點分別完成,最后統一匯總計算結果。然而Hadoop結構在處理實時性要求較高的業務時,卻產生了瓶頸。
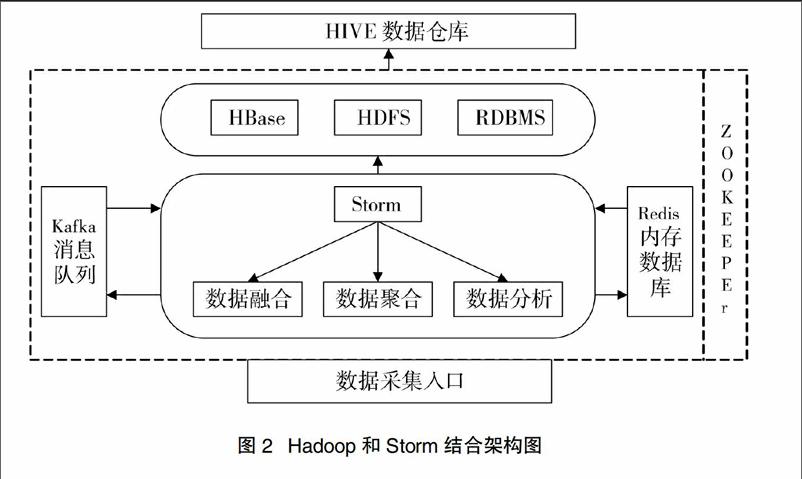
Storm是由Twitter公司開發的,是一個開源分布式的,容錯的實時計算系統,提供良好的實時性。將Storm的實時流處理和Hadoop的批處理進行融合集成,會提高集群的處理性能、及穩定性和擴展性。既可以支撐增量的實時流處理,也可以實現批量處理的方式,通過擴展數據存儲層以及增強高可用性,進一步擴展大數據業務場景。文獻[3]中提出一種基于Storm和Hadoop的新型大數據處理方案,將Storm的實時流處理與Hadoop的批處理進行融合集成,提高集群的性能。
4.2 MapReduce算法
MapReduce的缺陷主要有三點,第一,僅支持數據密集型運算,不支持任務密集型計算;第二,不支持顯示的迭代計算;第三,處理緊耦合數據效率低。Spark的使用可以很好地改善上述不足。
Spark是2009年美國加州大學伯克利分校研發的,立足于內存計算,增強了多迭代批量處理能力,提高了大數據處理的時效性。其核心技術是彈性分布式數據集(RDD),該框架包括內存計算、迭代計算、流式計算批處理計算,數據查詢分析計算以及圖計算,是MapReduce模型的代替模型。Spark支持單節點和多節點集群,可以在Hadoop文件系統中并行運行,通過Mersos第三方集群框架可以支持。
5 結 語
大數據和云計算的快速發展,作為應用平臺的Hadoop起到了至關重要的作用,但是Hadoop的缺陷也是不容忽視的。Hadoop今后的發展方向可能著重和Spark、Storm三者完美結合,混合架構,各顯神通。由于Hadoop的兼容性很好,可以很容易地同Spark和Storm相結合,以改進Hadoop在時效性、流處理、圖處理迭代式計算上的不足。
主要參考文獻
[1]胡俊,胡賢德,程家興.基于Spark的大數據混合計算模型[J].計算機系統應用,2015,24(4):214-218
[2]付東華. 基于HDFS的海量分布式文件系統的研究與優化[D].北京:北京郵電大學,2012.
[3]繆璐瑤. Hadoop安全機制研究[D].南京:南京郵電大學,2015.
猜你喜歡
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
新聞世界(2016年10期)2016-10-11 20:13:53
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
