
PM2.5的相關因素時間序列分析模型
2017-10-30 22:32:51王來斌
大經貿 2017年9期
王來斌


一、引言
我國華北的部分城市每年冬天都會遭遇霧霾的多次襲擊。許多人的日常上班,學習都受到影響,當霧霾天氣中細微顆粒物濃度很高時,環境污染會對人體造成嚴重的不良影響,比如呼吸道感染,心腦血管疾病,心肺疾病等發生比率上升。PM2.5也被稱為細微顆粒物,是指大氣中直徑小于等于2.5微米的懸浮顆粒物。PM2.5粒子直徑小,易于富集空氣中的有毒有害物質。
由上文所述背景,本文就是對PM2.5濃度的氣象影響因素進行分析建模,并預測未來一段時間的PM2.5濃度,盡可能準確地做出預報,為人們的日常工作學習提供參考和依據,降低PM2.5帶來的空氣污染所造成的損失。本文基于UCI上記載的北京市2010-2015年每日12時的PM2.5監測值,運用機器學習相關算法預測未來一段時間的PM2.5預測值。
二、ARIMA模型的建立
(一)建立ARIMA模型
1.時間序列圖
時間序列圖分析模型能進行精度比較高的短期預測,因此針對北京市東四2015.1.1-2015.12.21共355天的數據用R軟件進行建模預測。由結果圖可知,北京東四在2015.1.1-2015.12.21的PM2.5值并不平穩,故要進行變換或者差分處理。
對原始數據進行一階差分,差分后的值顯示平穩但是還需要進行單位根檢驗。一階差分圖如圖1
2.單位根檢驗
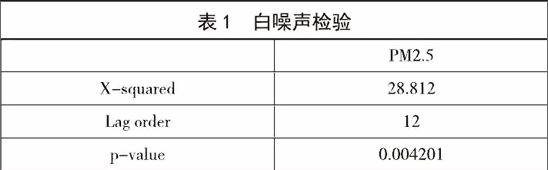
單位根檢驗的P值小于0.05,故拒絕原假設,為平穩序列。接下來進行一階差分后的白噪聲檢驗
滯后12階指標相關統計量如下表所示。
我們可以看出,兩個指標取對之后進行差分過后均顯著,是非白噪聲序列,我們可以進行接下來的模型識別和模型選擇。
3.模型識別及定階
通過R軟件中的自動定階,得出最合適的模型是ARMA(1,4),因為進行了一階差分,故最終模型為ARIMA(1,1,4),如下:
ARIMA(1,0,4) with zero mean : 4052.331
Best model: ARIMA(1,0,4) with zero mean
Series: X3
ARIMA(1,0,4) with zero mean
Coefficients:
ar1 ma1 ma2 ma3 ma4
-0.1322 -0.3429 -0.3689 -0.1963 -0.0667
s.e. 0.5663 0.5635 0.2787 0.1864 0.1110
sigma^2 estimated as 5687: log likelihood=-2020.04
AIC=4052.09 AICc=4052.33 BIC=4075.27
5.模型的診斷
Q-Q圖來檢驗殘差的正態性:
Q—Q圖是一種有效平谷正態性的工具,由圖可知整體趨勢接近一條直線,但是也存在異常值。但總體上是正態的。
6.模型的預測
建立好模型之后,我們需要對于模型進行預測,R軟件的時間序列功能能幫助我們針對有效的模型進行良好預測。根據PM2.5初始值,我們對于2015.12.22.-2015.12.31共10天數據預測,預測值分別是:168.3501 126.8469 110.9921 109.3322 110.1681 109.7472 109.9591 109.8524 109.9061 109.8791 而實際值分別為:138.00 127.00 106.00 102.63 106.00 116.00 111.00 102.00 115.00 110.00
可以看出與實際值差別不大,說明預測的較為準確。
五、總結
本文綜合運用了多元回歸分析、主成分分析對PM2.5的相關因素進行了統計上的分析,又利用ARIMA時間序列分析對PM2.5質量濃度進行預測。ARIMA模型較好的解決了大氣中PM2.5的時間分布問題,具有良好的預測效果。endprint
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
環境保護與循環經濟(2017年2期)2017-09-26 11:52:22
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
化工進展(2015年3期)2015-11-11 09:18:15
浙江大學學報(工學版)(2015年1期)2015-03-01 01:17:28
