基于深度學習網絡的煙葉質量識別
2018-04-10 09:35:51韓東偉王小明王新峰
安徽農業科學 2018年10期
關鍵詞:深度
韓東偉,王小明,王新峰
(河南中煙工業有限責任公司許昌卷煙廠,河南許昌 461000)
煙草的質量識別長期以來主要依賴人工分揀和分類,效率慢且受操作人員的主觀因素影響較大。深度學習網絡作為一種新的機器學習技術,在圖像處理和智能識別領域得到了廣泛應用,并有著優異的性能。隨著近年來深度學習技術的快速發展,以圖像處理和語音識別為主的深度學習技術的應用也得到廣泛展開,在各行各業中都得到了普遍應用,并在農業領域取得了較大的經濟與社會收益[1]。我國的煙葉種植和煙草制品消費量均十分龐大,將深度學習技術與圖像處理相結合并在煙草工業中應用對于煙草行業的現代化建設十分關鍵[2]。筆者利用深度學習網絡構建煙葉的熟成度分類模型,進行智能化的煙葉質量識別,旨在提高煙葉分揀及分類工作的效率和精度。
1 煙葉熟成度分類
煙葉的質量和熟成度檢驗主要分為內部檢測和外部檢測。內部質量檢測指的是煙葉的化學成分、燃燒測試、化學分析和通過人體感官進行的吸煙測試來實現的,而外部質量檢測主要通過人的肉眼對煙葉進行觀察。由于煙葉化學成分復雜,內部質量檢測費用較高,且費時費力[3]。因此,外部質量檢測經常在對時間要求較高的情況下被選擇來代替內部質量檢測,且煙葉的內部質量也與其外部質量密切相關,有經驗的煙廠生產人員往往僅憑肉眼觀察就能分辨煙葉的質量和熟成度。煙葉的外部質量檢驗包括色澤、熟成度、表面紋理、大小和形狀。在通過人類視覺進行煙葉質量檢驗時,不可避免地受到檢驗人員的身體、心理和環境的影響。
烤煙煙葉的具體分級標準可能因國家和地區而異,但煙葉分類的一般方法和考察的外部特征相似。首先,煙葉被分類為正常煙葉和異常煙葉。一般情況下,大部分的煙葉都屬于正常煙葉,因此對異常煙葉暫不進行討論。其次,正常煙葉根據其在煙草植株的莖上生長的位置和顏色不同,分為X下部(lugs)、C中部(cutters)、B上部(leaf)。對生長位置的判斷主要基于顏色、表面紋理、煙葉的形狀和葉脈特征。葉片按顏色分為L檸檬黃色(lemon)、F橘黃色(orange)和R紅棕色(red-brown)。通過生長位置和葉片顏色的組合,得到:下部檸檬黃色(XL)、下部橘黃色(XF)、中部檸檬黃色(CL)、中部橘黃色(CF)、上部檸檬黃色(BL)、上部橘黃色(BF)和上部紅棕色(BR)。
煙葉熟成度分類參照GB2635-1992烤煙的規定。《烤煙》國標中將熟成度分為完熟、成熟、尚熟、欠熟和假熟5個等級。按照國標要求,烤煙煙葉熟成度的判斷依據包括成分、結構、密度、油分、氣味、顏色、斑點、光滑程度和色度等。煙葉熟成度等級及相應外觀特征見表1。其中,結構、顏色、斑點、光滑程度等在一定程度上都可以采用機器視覺技術來進行自動分揀、分類和評級。
表1煙葉熟成度等級及相應外觀特征
Table1Theripeningdegreelevelandappearancecharacteristicsoftobacco

等級Level熟成度Ripeningdegree外觀特征Appearancecharacteristics1完熟結構疏松,顏色多橘黃或淺紅棕色,有明顯的成熟斑,有些伴有赤星病斑2成熟沒有任何的含青或明顯的掛灰和蒸片類的雜色,沒有大面積的光滑葉,色度無異常3尚熟外觀有一定的含青,有較大面積的光滑葉,或有較明顯的掛灰和蒸片等雜色,顏色偏淺淡4欠熟有較大程度的含青,或者有較大面積的僵硬(光滑),有嚴重的掛灰或蒸片等雜色現象5假熟顏色較淺或身份較薄,調制后表現為黃色的煙葉
2 深度學習網絡
深度學習網絡是基于大數據信息建立的統計學習方法[4],屬于人工智能領域中的機器學習學科,其目的是通過大量樣本的統計學習,建立針對某種特定問題的專家系統,借助或不借助人類知識自動解決某一領域的特定問題。深度學習網絡的主要思想是:通過建立具有多個層次的神經網絡,實現對輸入數據的深層次表達,從而實現更好的分類與特征抽取。使用深度學習方法,可以讓計算機自動學習到人工方法未必能夠發現的重要特征。
深度學習方法作為人工智能領域和機器學習學科的一種最新的技術,近年來獲得了大量關注和研究[5]。針對深度學習的理論研究、算法設計和應用系統在許多領域廣泛應用[6-7],如語音識別、圖像分類和自然語言處理等[8]。目前最主要的深度學習方法包括深度置信網絡(Deep belief network,DBN)[9]、卷積神經網絡(Convolutional neural network,CNN)[10]、循環神經網絡(Recurrent neural network,RNN)和堆疊自動編碼器(Stacked autoencoders,SAE)等[11]。
AE是3層神經網絡,將輸入表達編碼為一個降維映射,并將該降維映射重新解碼還原為原輸入,在訓練過程中最小化重構誤差。
筆者采用自動編碼器和卷積神經網絡相結合的方法,建立一種采用無監督預訓練,以提高訓練深度的專門網絡,通過對烤煙煙葉的圖像數據識別,自動進行烤煙煙葉檢驗與分級。
2.1稀疏自動編碼器稀疏自動編碼器是神經網絡的一種,其機制是試圖在無監督過程中使其輸出與輸入近似。自動編碼器的基本模型是一個3層網絡(圖1),其隱含層神經元個數往往少于輸入特征數,因此輸入層到隱含層相當于一個編碼過程,而隱含層到輸出層則視為解碼。在編碼過程中,自動編碼器試圖將輸入向量x按一定的映射編碼為xcn,如式(1)所示。
y=f(x)
(1)
當編碼過程完成后,解碼過程是將編碼的特征向量y重構成新的向量x′,并使得x′盡可能地還原x,其過程如式(2)所示。
x′=g(y)
(2)
x′的維數一般小于x,但其可以通過g(y)來還原x,因此可視其為x的特征向量。自動編碼器的作用就是通過特征提取將高維問題轉化為低維問題,從而降低問題的復雜度,以使問題更容易求解。使x′接近于x的過程可以用反向傳播算法來訓練,從而獲得編碼y。該算法邏輯如圖2所示。
輸入層到隱含層的映射即編碼過程,對任何i維向量x∈Rn,經過輸入層到隱含層的映射,獲得該向量對應的低維向量y=f(x),y∈Rd。從隱含層到輸入層的過程,自動編碼器對該向量的對應低維向量y進行“解碼”,得到與x同維度向量x′。通過反向傳播算法訓練網絡,并調整f(x)與g(x)的參數以最小化重構誤差,使存在一個足夠小的正數ζ且|x′-x|<ζ。
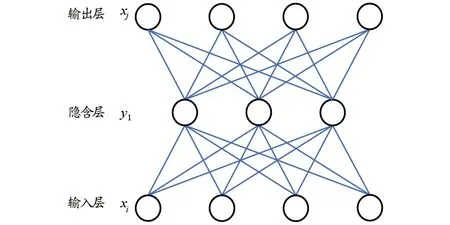
圖1 自動編碼機網絡結構Fig.1 The network structure of automatic coding machine

圖2 自動編碼機算法邏輯Fig.2 The algorithm logic of automatic coding machine
在具體訓練過程中,將電能計量器具的運行條件矩陣X作為自動編碼器的輸入矩陣,xi∈Rn×l是矩陣X中的第i條測試數據對應的條件向量,將xi作為自動編碼器的第i個輸入向量,編碼層的神經元數量為d,通過式(3)得到編碼hi∈Rd×l。
yi=sf(Wxi+b)
(3)
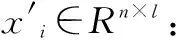
(4)


(5)
2.2卷積神經網絡卷積神經網絡是由用于特征提取的卷積層和用于特征處理的亞采樣層交疊組成的多層神經網絡。網絡輸入是一個圖像的數字矩陣,輸出則是其識別結果。輸入圖像經過若干個“卷積”和“采樣”加工后,在全連接層網絡實現與輸出目標之間的映射。卷積神經網絡是Hubel、Wiesel等通過對貓科動物視覺系統的研究中受到啟發而設計的。

(6)
池化層作用是基于局部相關性原理進行池化采樣,從而在減少數據量的同時保留有用信息。采樣過程可以表示為:
(7)
式中,down()表示采樣函數。卷積神經網絡在卷積層和采樣層后,通常會連接一個或多個全連接層。全連接層的結構和全連接神經網絡的隱層結構相同,全連接層的每個神經元都會與下一層的每個神經元相連。對多類別圖像分類任務而言,在輸出層需要采用Softmax分類器將任務類別進行獨立編碼,并采用最小化交叉熵作為損失函數。Softmax歸一化概率函數定義如下:
zi=zi-max(z1,z2,…,zm)
(8)
(9)
式中,zi是每一個類別線性預測的結果,由于網絡最終需做歸一化處理,因此減去一個最大值并不會改變最終結果,而會起到保持計算時的數值穩定性的作用。同時,根據σi(z)來預測輸入zi屬于每個類別的概率。這樣,損失函數定義為:
L(zi)=-logσi(z)
(10)
在訓練過程中,卷積神經網絡仍采用輸入正向傳播和誤差反向傳播算法進行訓練,最小化分類或回歸誤差。
3 卷積自動編碼器網絡結構
卷積神經網絡采用權值共享和卷積操作代替了傳統神經網絡層與層之間的矩陣內積運算,有效加深了網絡深度并提高了網絡的訓練效果。但對于深度網絡而言,反向傳播算法的梯度消失問題仍然沒有徹底解決。對于更加復雜的處理對象而言,網絡深度的增加依然會導致網絡的學習效能降低。
自動編碼器采用最小化重構誤差進行無監督訓練,在堆疊自動編碼器中,這個訓練過程實際上成為一種預訓練(pre-training)。預訓練是一種廣泛使用的深度網絡訓練方法,通過預先將網絡權值調整到較為有利的位置,可以有效增加訓練深度,提高網絡效能。筆者以此重構一種新的網絡結構,網絡層間運算采用卷積操作,并在卷積操縱之后使用反卷積操作作為解碼,利用最小化重構誤差預調整網絡權值。在預訓練結束后,再采用反向傳播算法微調網絡參數,獲得更好的訓練效果。網絡結構如圖3所示,此外,為自動編碼器加入基于Kullback-Leibler(KL)散度的稀疏性限制,以在訓模型練過程中盡量避免過擬合,其限制如式(11)所示。
(11)

(12)
則構建的自動編碼器重構誤差的損失函數(loss function)歸納式如式(13)所示。式中,α為控制稀疏限制的權重因子。
(13)
4 訓練試驗、對比和結果
4.1網絡結構通過使用同樣數據集對最小二乘支持向量機(Least squares support vector machine,LS-SVM)、全連接多層感知機(Full-connection perceptions,FCP)和采用深度訓練自編碼器(Stacked sparse autoencoder,DRSSA)進行試驗,觀察其訓練效果。各網絡結構如圖4所示。
圖4a為全連接多層感知機網絡結構圖,該模型共含有4個隱含層,每個隱含層含有5個感知機單元,層與層之間的感知機單元采用全連接方式。圖4b為堆疊自動編碼器網絡結構圖,共含有4個自動編碼器,編碼器所含單元數分別為6、5、4、3,每2層采用無監督預訓練編碼器輸入與輸出,并將上一層編碼器的中間層作為下一層編碼器的輸入。輸出層為全連接層。在訓練時將樣本數據的1/3作為預訓練集(pre-training datasets)、其余2/3作為微調訓練集(fine-tuning datasets)。
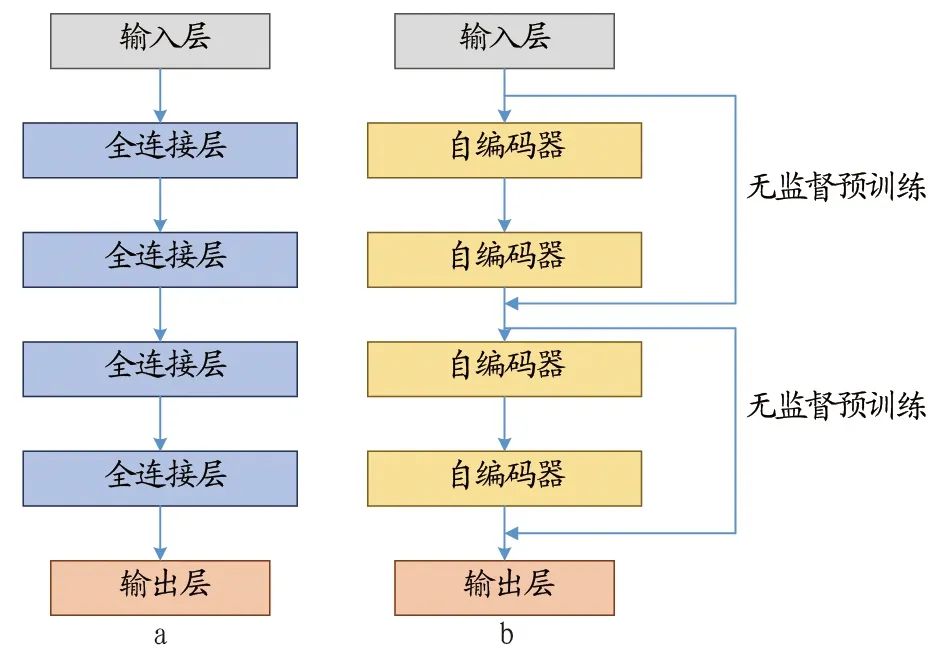
圖4 全連接多層感知機與堆疊稀疏自編碼器網絡結構Fig.4 Network structure of fully connected multi-layer perception machine and stack sparse self-encoder
訓練學習率η=-0.001,采用隨機梯度下降法(Stochastic gradient descent)進行訓練,batch size=50。損失函數(loss function)采用均方誤差(mean squared error, MSE):
(14)
對于給定樣例集合D={(x1,y1),(x2,y2),…,(xm,ym)},xi∈Rdd,yi∈Rld,其中yi為示例xi的真實標記,m為樣本數據量,學習器預測結果為f(x)。
4.2仿真試驗試驗采用我國云南某煙草產地收集的煙草圖像數據集,數據集樣本數為3 000,格式均為240×240像素的RGB圖像。
通過對該數據分別采用最小二乘支持向量機(Least squares support vector machine)、全連接多層感知機(Full-connection perceptions,FCP)和重構的堆疊稀疏自編碼器(Stacked sparse autoencoder,SSA)進行試驗,觀察其訓練效果。
從圖5可以看出,LS-SVM在最初幾次迭代中效果優于FCP和SSA模型,這是由于SVM在針對小樣本空間的學習能力比神經網絡算法要強。但隨著訓練樣本和迭代次數的增加,神經網絡的學習潛力開始展現,最終FCP和SSA的模型誤差都要小于LS-SVM,說明在樣本數量足夠的情況下,神經網絡算法對大數據的適應能力更強。此外,SSA模型學習的收斂速度更快,最終誤差更小,說明SSA模型在針對煙葉熟成度識別這一特定的問題求解上具有更好的性能。
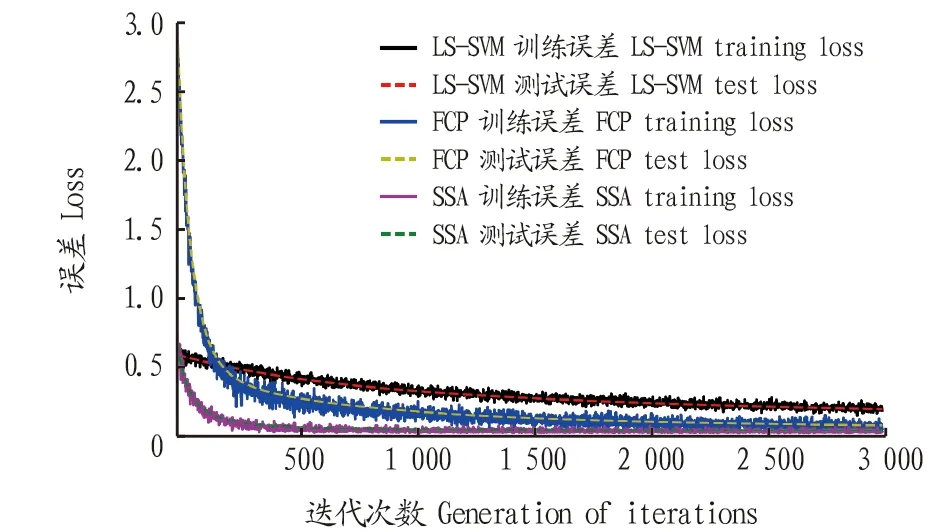
圖5 LS-SVM、FCP與SSA訓練效果對比 Fig.5 The training effect comparison among LS-SVM,FCP and SSA
5 結論
隨著煙草行業的發展,對行業整體的自動化和智能化需求的上升,深度學習技術作為人工智能領域的前沿技術,在煙草行業中的應用還有很大的拓展空間。重構的堆疊稀疏自編碼器(Stacked sparse autoencoder,SSA)模型在訓練深度提高時可以有效保持訓練效果,一定程度上避免誤差消失,并在煙葉熟成度識別試驗中表現出良好的識別性能。結果表明,重構的堆疊稀疏自編碼器(Stacked sparse autoencoder,SSA)性能優于最小二乘支持向量機(Least square support vector machine)、全連接多層感知機(Full-connection perceptions,FCP)。
[1] 張帆,張新紅,張彤.模糊數學在煙葉分級中的應用[J].中國煙草學報,2002,8(3):45-49.
[2] 劉朝營,許自成,閆鐵軍.機器視覺技術在煙草行業的應用狀況[J].中國農業科技導報,2011,13(4):79-84.
[3] 王亞平.煙葉分級存在問題及改進措施[J].寧夏農林科技,2013,54(1):112-113.
[4] 焦李成,楊淑媛,劉芳,等. 神經網絡七十年:回顧與展望[J].計算機學報,2016,39(8):1697-1716.
[5] BENGIO Y.Learning deep architectures for AI(Foundations and trends(r) in machine learning)[M].Hanover,MA:Now Publishers Inc.,2009:1-127.
[6] SCHMIDHUBER J.Deep learning in neural networks:An overview[J].Neural networks, 2015,61:85-117.
[7] 周飛燕,金林鵬,董軍.卷積神經網絡研究綜述[J].計算機學報,2017,40(6):1229-1251.
[8] BENGIO Y,COURVILLE A,VINCENT P.Representation learning: A review and new perspectives[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013,35(8):1798-1828.
[9] DENG L.A tutorial survey of architectures, algorithms, and applications for deep learning.APSIPA Transactions on Signal and Information Processing[M].Cambridge:Cambridge University Press,2014.
[10] ZHANG X Z, GAO Y S.Face recognition across pose: A review[J].Pattern recognition, 2009,42(11):2876-2896.
[11] LE Q V, NGIAM J, COATES A, et al.On optimization methods for deep learning[C]//Proceedings of the 28th International Conference on Machine Learning.Bellevue,Washing,USA:ICML,2011:265-272.
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
