基于支持向量機的短時交通流預測方法建模
2018-06-11 06:52:49楊鑫趙靜孫雨晴
發明與創新·職業教育
2018年8期
楊鑫 趙靜 孫雨晴


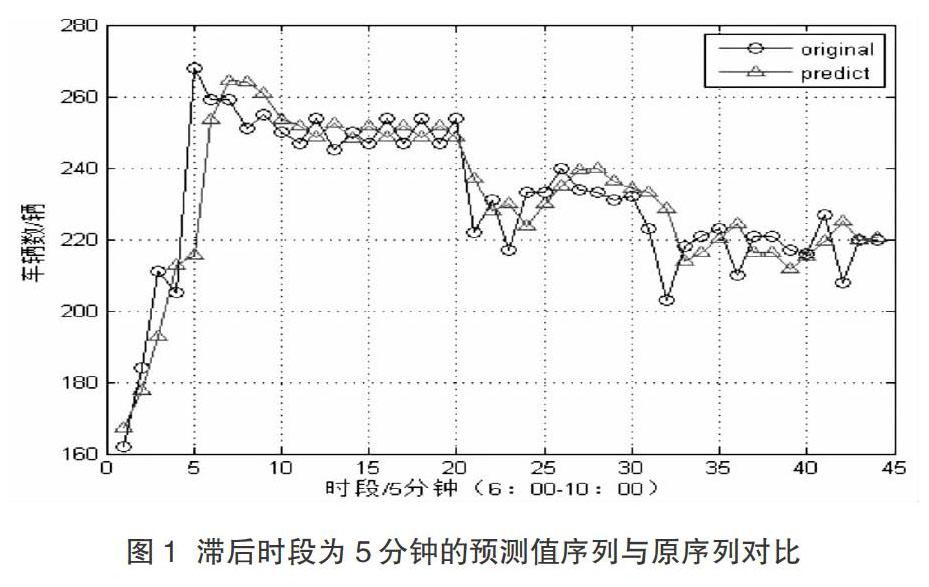
摘要:文章根據交通流特性對采集到的交通流數據進行錯誤數據的鑒別、缺失數據的補充、以及遴選數據的歸一化等預處理操作,構建基于支持向量機的短時交通流預測模型。通過對數據進行預測,并與實際測試數據進行對比發現,支持向量機回歸模型在短時交通流預測方面是可行的。
關鍵詞:交通流;數據預測;支持向量機
一、交通流基本特征參數
研究交通流狀態需對實時交通流進行評價,即選取一些定性和定量指標,對交通流的基本特征參數進行比較全面的描述。
(一)速度
速度是指單位時間內所行駛的距離,通常用 v表示,單位是距離/單位時間。在交通流的狀態描述中,速度通常有兩種方法:一種是指在特定觀測地點的速度,一般使用地點平均車速;另一種是指特定路段的車速情況,用于表現空間運行狀態的為路段的區間平均車速。地點平均車速是指具體道路上的某一個特定斷面在單位時間段內所通過的所有車輛的瞬時速度的平均值;路段的區間平均車速是指該路段的長度與在該路段所通過所有車輛的平均行駛時間之比
(二)密度
密度是指在單位長度的道路上某一時間瞬時所行駛的車輛的總數,通常用k表示,單位是輛/單位長度。由于密度是瞬時值,使用電子檢測相關設備并不容易獲得,同時也存在許多檢測困難。因此,密度一般會用車輛道路占有率替換。車輛道路占有率主要包括空間上的占有率與時間上的占有率。……
登錄APP查看全文
