基于爬蟲技術的網(wǎng)購信息獲取與營銷策略分析
2018-09-07 08:32:38胡曉青曹宇
中國儲運 2018年9期
關鍵詞:分析
文/胡曉青 曹宇
1.引言
孤立的數(shù)據(jù),盡管是海量數(shù)據(jù)量也是沒有任何意義的。利用Python進行網(wǎng)絡爬蟲,是通過既定規(guī)則,自動地抓取網(wǎng)頁信息的計算機程序。爬蟲的目地在于將目標網(wǎng)頁數(shù)據(jù)下載至本地計算機,以便進行后續(xù)的數(shù)據(jù)分析。爬蟲技術的興起源于海量網(wǎng)絡數(shù)據(jù)的可用性,通過爬蟲技術,我們能夠較為容易的獲取網(wǎng)絡數(shù)據(jù),并通過對數(shù)據(jù)的分析,得出有價值的結論[1]。
2.Python開發(fā)環(huán)境及技術支持
2.1 Anaconda 下載以及Scrapy安裝
在本項目的實現(xiàn)過程中,選擇 Anaconda集成環(huán)境,Anaconda可以認為是Python的一個集成安裝,平臺安裝完成后就默認搭建好了python、IPython、集成開發(fā)環(huán)境Spyder和眾多的包和模塊,非常智能化。由于開發(fā)工作將在Win7平臺中進行,因此選用Anaconda進行各種Python擴展包的維護也是非常方便和高效的。
Anaconda安裝完畢之后,以管理員身份進入Anaconda Prompt對平臺進行擴展包的安裝。此次開發(fā)過程中使用Scrapy爬蟲框架進行數(shù)據(jù)爬取工作,因此在Anaconda Prompt中進行Scrapy的安裝。
2.4 相關Python包簡介
(1)requests介紹
Request是使用屬性名來得到對應的屬性值,并可以自動地把返回信息Unicode解碼,Request可以自行保存返回內(nèi)容,所以我們可以讀取多次[2]。
發(fā)送請求
導入Requests模塊
>>>import requests
獲取網(wǎng)頁
>>>content = requests.get(url).text
(2)JSON介紹
JSON(JavaScript Object Notation) 是一類輕量級的數(shù)據(jù)交換方法。采用完全獨立于語言的文本格式,運用了和c語言家族相類似的習慣(包含C,C++,C#,JAVA,JavaScript,Python等)。JSON具有的這些特點成為很好的數(shù)據(jù)交換語言。
引用模塊
>>>import json
編碼
>>>json.dumps()把Python對象編碼轉(zhuǎn)換成json字符串
解碼
>>>json.loads()把json格式的字符串解碼轉(zhuǎn)換成Python對象
(3)Scrapy介紹
Scrapy是一種基于Twisted,僅僅使用Python語言實現(xiàn)的爬蟲框架,開發(fā)幾個模塊就能夠比較方便快捷的實現(xiàn)一次爬蟲,抓取網(wǎng)頁中的有效信息用來分析。
Scrapy作為一個包,功能強大,是一個網(wǎng)絡爬蟲的架構,是Python開發(fā)的快速高層次的屏幕抓取框架,也可以用于自動化運維。在本次項目實施中,是一種最優(yōu)的設計方案。
3.項目實施過程
本次項目中,我們使用Scrapy創(chuàng)建一個爬蟲對象Item的相關類,對該類中各個靜態(tài)變量進行定義。在通過requests模塊對相應網(wǎng)頁進行請求,獲得網(wǎng)頁對應的源碼,對得到的源碼格式進行整合,再通過json模塊對整合好的源碼進行分析,將分析結果逐個賦值給Item類中的靜態(tài)變量。
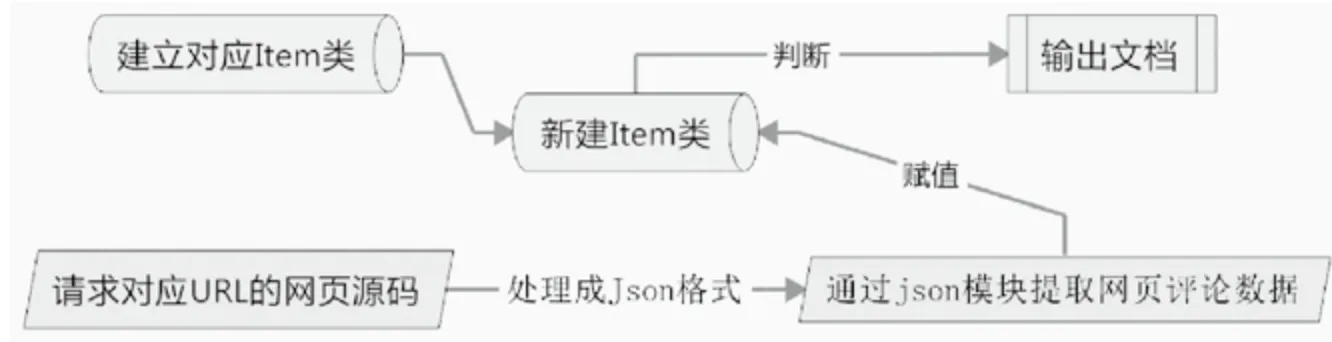
圖1 項目整體實現(xiàn)流程圖
以京東商城為例,需要先構建一個商品評論的Item類,Item類中包含了評論中所出現(xiàn)的必要信息,比如:買家ID、買家所在省份、評論具體內(nèi)容、評論時間、打分等。建立好Item類之后,我們通過對該商品評論url的請求獲取相應的網(wǎng)頁源碼,進行簡單處理轉(zhuǎn)換為json數(shù)據(jù)格式,通過json.loads模塊進行解析,得到每條評論的具體相關內(nèi)容,項目主要流程如圖1所示。
3.1 選擇合適的電商平臺
考慮大型電商平臺,在淘寶官網(wǎng)的用戶評論區(qū),沒有發(fā)現(xiàn)很多與客戶地理信息有關的數(shù)據(jù),而且淘寶網(wǎng)站設計中有反爬蟲程序,僅僅獲取評論中最近99頁的內(nèi)容,因此在做地理信息相關的物流指導過程中,我們選擇京東作為目標網(wǎng)站。
另外,在商品的購買人數(shù)方面,京東商品評論數(shù)能夠達到6萬+,數(shù)據(jù)量足夠用來實驗分析。本次實驗結果可以為京東提供一些銷售方案,實驗數(shù)據(jù)真實準確,試驗方法科學有效且具有可行性。
3.3 方案規(guī)劃
3.3.1 項目節(jié)點問題分析
(1)找到爬蟲的網(wǎng)頁地址
確定對京東平臺的商品信息進行爬蟲,所以通過分析網(wǎng)站,得到URL的格式。
這是京東上vivox9手機的網(wǎng)址https://item.jd.com/10941037480.html對這個網(wǎng)址進一步分析得到評論區(qū)真正的網(wǎng)址如下:
http://sclub.jd.com/productpage/p-10941037480-s-0-t-3-p-1.html?callback=fetchJSON_comment98vv341
(2)關鍵代碼分析
將爬蟲程序中需要用到的模塊導入,requests、json、scrapy。 sys是關于系統(tǒng)的模塊,包含很多函數(shù),本次程序中使用到reload(sys),重置系統(tǒng),將系統(tǒng)編碼設置為utf-8,sys.setdefaultencoding(‘utf-8’)。re是關于正則的模塊,本次程序中使用re.findall()函數(shù)將以迭代方式返回匹配的字符串,使用re的一般步驟是先使用re.compile()函數(shù)編譯成實例再使用findall()函數(shù)。time是關于時間的模塊,本次程序中使用time.sleep()函數(shù)使程序暫停一段時間。threading是關于多線程的模塊,本次程序中使用threading.Lock()函數(shù)創(chuàng)建鎖。(見圖2)
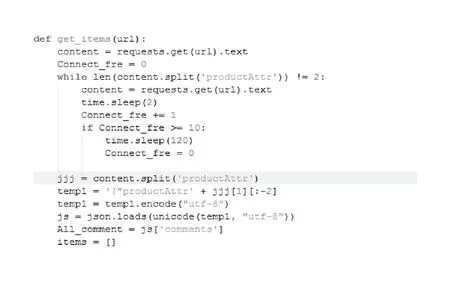

圖2
爬取相關信息并對所獲取的信息進行json文本處理,實例化一個commentItem,則可以得到每一個字段的值。本次實驗中,由于需要分析商品在不同地區(qū)的購買情況所以過濾掉了userProvince為空的數(shù)據(jù)信息。
user_name和user_ID分別記錄用戶名和用戶ID,只是為了記錄一條數(shù)據(jù)。
userProvince記錄用戶所在省份,將來可以統(tǒng)計該商品在不同地區(qū)的銷售情況,也可以對比不同商品在同一地區(qū)的銷售情況,甚至可以指導京東倉儲在各個地區(qū)的物流壓力。
Content記錄用戶評價,對一種商品的全部評價將來可以進行分詞,計算詞頻,就可以得到對本商品的詞云。
Date記錄用戶創(chuàng)建評論的時間,將來可以分析某段時間內(nèi)商品在不同地區(qū)的銷售情況,也可以分析在某地區(qū)不同季度該商品的銷售情況。(見圖3)
Score記錄用戶評分,userlevelname記錄用戶等級,將來二者可以結合起來對該商品進行一個加權的評分,用戶等級比較高的評分占比較重,這樣對該商品的評分更客觀。
Ismobile記錄用戶使用工具是手機還是電腦,如果是手機則為true,否則為false,將來可以分析不同地區(qū)網(wǎng)購時使用手機和電腦的占比情況。
write_comm()是一個自定義函數(shù),作用是請求指定的URL,在這個URL中固定好商品ID,頁碼數(shù),完成后寫入指定文本中。URL是通過分析原網(wǎng)站得到的一個固定格式,格式中只有商品ID和頁碼可以改變,其余部分的格式不能改變。在這個函數(shù)中調(diào)用get_items()函數(shù)。將得到的所有內(nèi)容存儲在指定的文本文檔中。(見圖4)
這是程序的主函數(shù),邏輯大致如下:首先固定好商品ID、開始頁碼、得到整個URL的格式,調(diào)用max_page()函
數(shù)分析評論頁第一頁得到最大頁碼數(shù)并賦值給page_max,設置開始頁page_begin=0,京東評論頁碼起始頁碼從0開始。打開寫入文件f_open,將來存儲爬取的所有數(shù)據(jù)。在這個程序中,設置了多線程,爬取速度與帶寬有關,為了加快速度,我們可以使用多線程來參與爬取。在開始頁到最大頁之中循環(huán),調(diào)用write_comm()函數(shù),使用多線程就可以快速獲得所有的數(shù)據(jù)。
(3)數(shù)據(jù)處理
通過爬蟲程序獲得對應商品的文本數(shù)據(jù),經(jīng)過格式轉(zhuǎn)換,提取各條評論對應的信息,再通過 Office Excel進行數(shù)據(jù)格式調(diào)整、處理分類、數(shù)據(jù)交集數(shù)量統(tǒng)計、繪制相應的圖表。

圖3
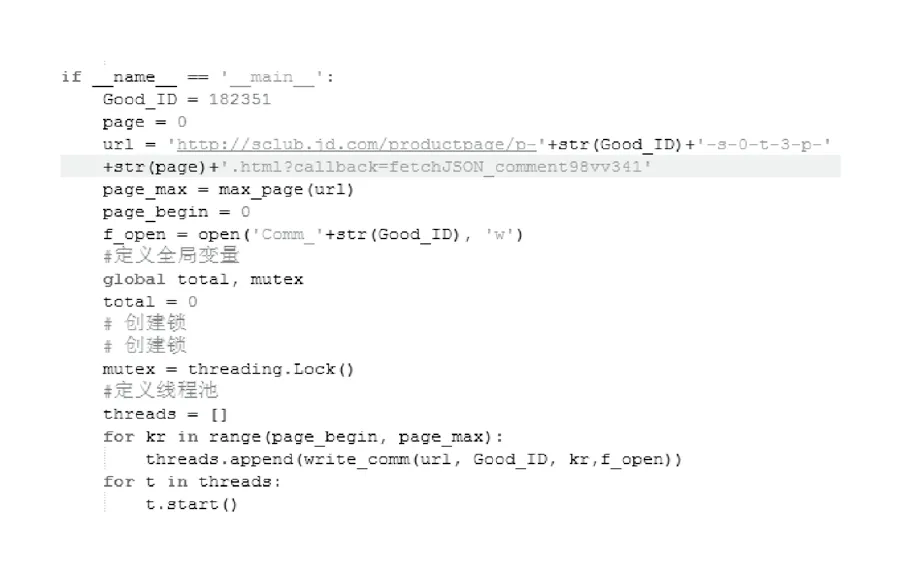
圖4
4.數(shù)據(jù)挖掘和數(shù)據(jù)分析
Python基礎教程、花式營養(yǎng)早餐、協(xié)和媽媽圈備孕書籍,這是三本看似沒有聯(lián)系的書籍。
《花式營養(yǎng)早餐》的數(shù)據(jù),有效數(shù)據(jù)大概30000條。信息有效。
《Python基礎教程》的數(shù)據(jù),有效數(shù)據(jù)大約15000條。信息準確。
《育兒教程》的數(shù)據(jù),有效數(shù)據(jù)大約12000條。信息準確。
做出折線圖:(見圖5)
本次項目中將三種數(shù)據(jù)的對比做成折線圖,對數(shù)據(jù)進行對比分析:
(1)觀察三種不同類別書籍的銷售情況,可以看出,購買力前幾名的城市都是北京、廣東、江蘇、上海等地,原因可能有幾種。這些城市發(fā)展比較好,思想更加解放,對知識更加渴求。這些城市不管銷售什么都不會太差。
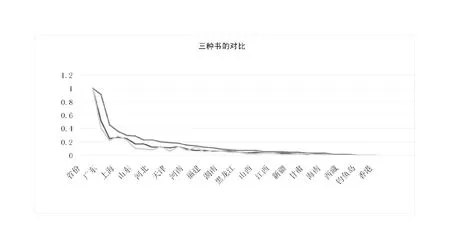
圖5 三種不同類型書籍在全國各地區(qū)的銷售量對比圖
(2)對于菜譜類的書籍,可以看出,折線圖的變化相對比較平緩,這類工具書很多省份的人都有需求,沒有專業(yè)限制。但是對于Python這類的專業(yè)性書籍,在特定的地區(qū)需求量比較大,比如北京、上海、廣東,這些城市計算機技術發(fā)展相對迅速,對新技術的學習人數(shù)多。但是通過折線圖可以看出,折線圖的走勢直上直下,在山東、遼寧、河北等地銷量一般,說明Python這一技術在這些地區(qū)并沒有達到很高的發(fā)展,使用這門開發(fā)語言的人比較少。
(3)備孕類的書籍和Python類的書籍折線圖走勢基本相近,我們可以大膽推測,學習Python的人一般都是二三十歲的年輕人,這些人同樣也需要備孕類和媽媽幫這類的書籍,所以這兩類書籍在各個省份的銷量基本一致。如果書店中銷售Python等技術類書籍,那么店主不妨可以銷售備孕類書籍。
5.總結
本次項目的結果,成功驗證了不同種類書籍之間的關系,為以后的研究提供了思路。
不管是電子商務平臺還是搜索引擎在相關方面的合理布局和優(yōu)化規(guī)則,都需要研究人員利用海量數(shù)據(jù)找出不同事物之間千絲萬縷的聯(lián)系,本文使用Python開發(fā)程序,以京東商品為例,得出消費者的一些購物習慣,為商家提供了一種銷售策略,為以后的研究作了鋪墊。
猜你喜歡
現(xiàn)代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業(yè)技術(2016年15期)2016-12-01 05:31:22
當代經(jīng)濟研究(2016年5期)2016-12-01 03:12:05
現(xiàn)代農(nóng)業(yè)(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫(yī)藥現(xiàn)代遠程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學學報(社會科學版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
