語言測試效度與公平性研究*
2018-09-11 00:54:50姜秀娟
外語學刊 2018年1期
姜秀娟
(曲阜師范大學,曲阜 276826;北京外國語大學,北京 100089)
提 要:效度是評判一項測試質量的重要指標,而公平性又是效度的重要保證。本文結合測試效度觀及其驗證模式的發展變化,對近50年來語言測試公平性觀念及其研究模式在分類、整體、論證3種效度觀時期的演變進行梳理與思考,發現語言測試公平性研究采取的幾乎是與效度研究一樣的進路,學界對公平性研究的必要性存在爭議。在以上分析的基礎上,本文總結二者之間的關系,并指出未來測試公平性研究應繼續努力的方向。
1 引言
測試公平性研究始于20世紀60年代,80至90年代被廣泛關注(Zieky 2006:360),是測試領域一個新興的熱點話題。長期以來,效度是評判一項測試質量的重要指標,而公平性又是效度的重要保證,二者交織在一起,不可分割(同上:359)。80年代中期以來,有關測試公平的觀點、標準、文件不斷涌現,專門探討測試公平性問題的高層次學術會議也相繼召開,測試公平性的重要性可見一斑。那么,公平性到底是什么,如何研究或檢驗一項測試的公平性?語言測試效度觀及其驗證模式的變化對公平性觀念及其研究模式產生怎樣的影響?語言測試公平性與效度有怎樣的關系?為了回答以上問題,本文結合測試效度觀及其驗證模式的發展變化,對語言測試公平性觀念及其研究模式在分類、整體、論證3種效度觀時期的演變進行梳理與思考,并指出語言測試公平性研究的未來趨勢。
2 效度分類觀與語言測試公平性研究模式
20世紀50年代之前,教育與心理測量學普遍堅持“相關即有效”的效度觀(韓寶成 羅凱洲 2013:412)。但是,要想確定那個“相關”的東西絕非易事,因為一項測試可以與很多種事物相關。于是,不同類型的效度應運而生。1954年,美國心理學會(APA) 在《關于心理測驗和診斷的技術建議》(TechnicalRecommendationsforPsychologicalTestsandDiagnosticTechniques)中,將效度分為4種:預測效度(predictive validity)、共時效度(concurrent validity)、內容效度(content validity)和構念效度(construct validity)。1966年,《教育與心理測驗的標準與指南》(StandardsforEducationalandPsychologicalTestsandManuals) (AERA et al.) 把預測和共時合并為校標關聯效度(criterion-related validity)。
1961年,Lado在現代語言測試的奠基之作《語言測試》(LanguageTesting)中首次將教育與心理測量學領域的效度概念引入語言測試領域,指出“效度本質上是一種關聯。一項測試是否測量到它要測量的東西。如果答案是肯定的,那么它就是有效的”。之后,語言測試領域紛紛效仿Lado 的觀點定義效度(如Valette 1967;Harris 1969; Heaton 1975; Finocchiaro, Sako 1983)。Heaton (1975: 153) 將語言測試效度分為表面效度、內容效度、構念效度和實證效度。這一時期的語言測試效度驗證模式主要采取Lado提出的方法,如選擇、設計與內容相關、與學習問題相關的題目;修改因非語言因素引起難度增加的試題;使用一項有效的測試和自己開發的測試,對一組有代表性的學生樣本進行測試,計算兩次測試成績間的相關系數,從而確定測試效度(Lado 1961:328-329)。分析測試內容、計算校標關聯系數是這一時期進行語言測試效度研究的主要方法(韓寶成 羅凱洲 2013:413)。
那么,如何分析測試內容,如何保證測試題目與測試構念相關,如何確定測試題目中沒有包含與測試構念無關 (construct-irrelevant) 的因素?這些問題是該時期語言測試效度驗證過程中必須解決的,對這些問題的回答也使測試專家學者開始關注測試公平性問題。早期的語言測試文獻只是將測試公平性等同于測試中的題目對不同的考生群體不存在偏頗(bias)(AERA et al. 1985)。測試偏頗(test bias) 指具有相同能力的不同群體的考生在相同題目上的得分不同。換句話說,測試偏頗就是與測試構念無關的考生特征(如性別、種族、社會經濟地位等)對考生的考試成績產生系統性的影響(McNamara, Roever 2006:82)。測試偏頗一般采用項目功能差異(Differential Item Functioning, DIF) 研究。如果研究顯示測試題目存在DIF,就要確定DIF存在的原因是否與測試構念無關因素有關,如果有關,則說明試題存在偏頗,從而影響測試的公平性,必須去除或修改導致偏頗的題目。美國教育測試服務中心 ( Educational Testing Service, ETS) 1986 年規定,在測試開發的過程中,為保證測試較高的效度和公平性,除了對編制的題目進行常規的項目分析外,還必須進行項目功能差異研究。受這一時期效度驗證模式的影響,偏頗研究只是從技術的角度,對試題的心理測量學屬性進行統計分析,控制與測試構念無關的因素,從而為效度驗證提供數據和技術支持。20世紀80年代末,隨著效度分類觀向效度整體觀的轉變,測試領域對公平性的認識也發生變化,公平性研究模式也隨之發生改變。
3 效度整體觀與語言測試公平性研究模式
20世紀80年代,隨著效度研究的不斷深入,教育測量界發現基于分類方法進行測試的效度驗證所得結果太零散,也沒有考慮考試成績的價值含義及考試成績使用的社會后果。基于此,Messick (1988, 1989)提出整體效度概念(unitary concept of validity),認為效度只有一個,即構念效度,而證明效度的證據可來自多方面,并用分層效度框架(又稱效度漸進矩陣 (progressive matrix))進行說明(參見表1)。

構念效度構念效度+相關性/實用性價值含義社會后果
分層效度框架由測試解釋、測試使用、證據基礎和后果基礎4個維度構成。Messick的“一元多維”效度整體觀更新人們的測試效度驗證觀念,自此,效度驗證不僅僅是對測試本身及分數的評價,還包括對測試結果解釋和使用的評價。但是,Messick 的“一元多維”效度理論太抽象,不能有效地指導測試效度驗證。為解決操作性問題,Bachman和Palmer(1996)提出測試的有用性框架(test usefulness framework),通俗易懂地詮釋Messick的效度理論。測試有用性框架包括信度(reliability)、構念效度、真實性(authenticity)、交互性(interactiveness)、影響力(impact)和可行性(practicality)6個要素。信度指一項考試結果的穩定性;構念效度指對考試分數解釋在多大程度上是有意義的、適切的;真實性指考試任務特征與目標語言使用任務特征的一致性程度;交互性指考生完成測試任務時,參與其中的個人特質類型和程度;影響力指考試對個人、教育制度以及整個社會產生的影響;可行性指設計、開發和使用一項測試所需資源與可用資源間的關系。隨后的十幾年中,該框架是語言測試效度驗證的權威模式 (Weigle 2002),在指導語言測試的開發和使用方面發揮重要作用。
測試效度觀念及其驗證模式的改變,使人們意識到偏頗研究只是屬于Messick (1989)分層效度框架中的證據基礎維度,公平性應該包括更廣闊的研究內容,比如測試的社會價值與影響。而且,1999年版的《教育與心理測量標準》(以下簡稱《標準》)專設一個部分討論測試公平性,將公平性定義為無偏頗、考試過程公平、基于考試結果的決策公平以及學習機會均等。具體來講,無偏頗就是控制構念代表性不足(construct under-representation)及與構念無關的因素(construct-irrelevant variance),消除影響構念效度的偏頗。比如,要保證內容樣本的覆蓋面、所有考生都熟悉答題形式等。考試過程公平指在施考過程中平等對待所有考生,考生要有相同的機會展示自己的能力。基于考試結果的決策公平指不同考生群體的考試結果具有可比性,能力相同的考生應享有同等的選拔機會。學習機會均等主要指在標準參照考試中,考生有相同的機會學習考試內容和接觸復習資料,尤其是考試成績用于決定是否留級或頒發證書時,學習機會均等更顯重要。因此,測試專家學者開始構建更為全面的公平性研究框架。
2000年,Kunnan在Messick整體效度觀的指導下,以社會正義理論(Jensen 1980) 和《教育公平測試行為準則》(JCTP 1988)為基礎,參考1999年版的《標準》中關于測試使用、考生權利和責任、考生語言多樣化以及殘疾考生等涉及公平性話題的論述,進一步擴展傳統的測試公平性研究范圍,提出新的公平性研究框架。該框架包括效度、機會均等和公正性3個組成部分。其中,效度關注構念效度、考試內容與形式的偏頗、試題的差異效應、考試材料中語言使用的恰當性以及哪些考生群體處于不利地位;機會均等關注考試費用、考場選址、考試設備和條件是否有利于所有考生,考生受教育機會是否均等則關注對殘疾考生是否有特殊待遇;公正性關注社會公正及法律挑戰。可以看出,Kunnan的測試公平性研究框架不再局限于心理測量學屬性,已經擴展至社會、道德、法律和哲學層面(Kunnan 2000:5)。2004年,Kunnan對其2000年的公平性研究框架進行修改和完善,增加施考條件和社會后果兩個部分。至此,測試公平性研究框架更加全面、更加深入,由原來的3個組成部分擴展到5個,形成由效度、機會均等、公正性、施考條件和社會后果構成的新框架,完全契合整體效度觀的精神及其效驗模式。該框架成為近年來語言測試公平性研究的主要依據。2009年,Kunnan又提出測試環境框架(the Test Context Framework),該框架試圖從政治、教育、文化、社會、經濟、法律和歷史等諸多方面審視一項測試,同年,Kunnan用美國公民入籍考試(the Naturalization Test)為例從3個方面對測試的公平性進行探討:(1)測試的要求和目的:該考試的要求和目的是否有意義;(2)測試的理論基礎、內容和操作:該考試是否能夠測出英語語言能力以及關于美國歷史與政府的知識;(3)測試后果:該考試是否能夠帶來民族主義或社會融合。通過分析以上3個方面,Kunnan發現,此項美國公民入籍考試是20世紀50年代美國特定歷史時期的產物,已經不符合時代要求,也不符合美國法律規定,因此,該考試的實施和分數的使用無意義。另外,該考試也測不出考生是否具有“民族主義”或“社會融合”能力,也就是說,該考試的內容和理論基礎與預測構念不相關。可見,該考試對考生而言不公平。
但是,隨著測試效度及其驗證模式研究的深入,人們發現Bachman和Palmer (1996) 測試有用性框架的6大要素間缺少關聯,效度驗證只是證據的簡單羅列,而且無從知曉證據收集從哪兒開始,到哪兒結束。對測試有用性框架“重操作性、輕連貫性”缺陷的認識,也使人們意識到Kunnan (2004)測試公平性框架存在同樣問題,該框架的5個組成部分沒有形成一個連貫的令人信服的測試公平性論證(Bachman 2005)。Kunnan (2009) 框架也沒有解決這一問題,無法為測試公平性的評估和實證研究提供切實有效的指導(Xi 2010)。如何明確語言測試公平性各要素間的關系;如何整合各類證據,使它們成為一個連貫的相互聯系的整體?人們期待新觀點新模式的出現。
4 效度論證觀與語言測試公平性研究模式
1999年版的《標準》把效度定義為“證據及理論對測試分數解釋與使用的支持程度”,指出效度驗證就是對“分數的預期解釋與使用的論證” (AERA et al. 1999:9)。但是,在效度驗證中如何組織證據,該版《標準》沒有給出一個可供參考的論證模式,效度驗證基本上采取證據羅列模式。當然,教育測量界并沒有停止探索效度驗證中的證據組織方法(如Kane 1992, 2002, 2004, 2006;Kane et al. 1999; Mislevy et al. 2002, 2003),最終將Toulmin (2003) 的實用推理模型(practical reasoning model)(參見圖1)用于效度驗證,提出基于論證的驗證模式(argument-based approach to validation)。該模式明確收集證據的類別與數量,效度證據的組織也不再是簡單的羅列,而是形成一個環環相扣的證據鏈,使效度驗證成為一個有始有終、邏輯嚴密的論證過程。
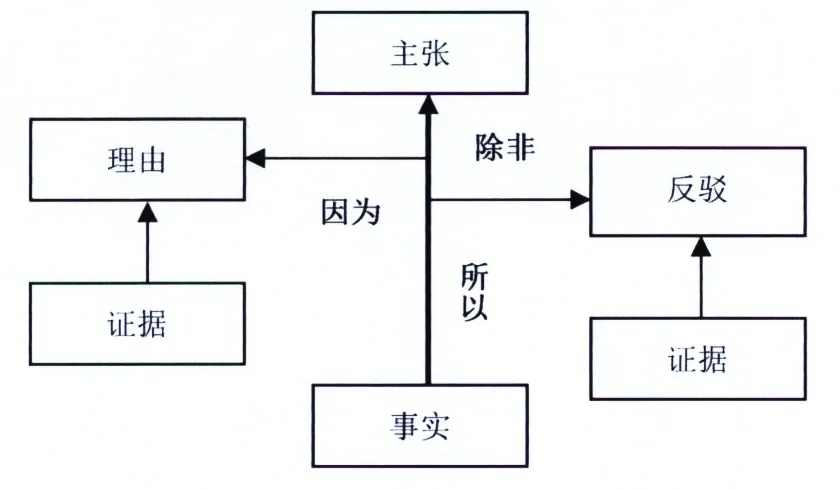
圖1 Toulmin的實用推理模型(改自Toulmin 2003:97)
典型的基于論證的效度驗證模式有兩個,一個是Kane (2006)的解釋性論證(interpretive argument)與效度論證(validity argument)。該模式分兩步:第一步,搭建理論框架(解釋性論證)(參見圖2);第二步,檢驗理論框架(效度論證)。另一個是Bachman和Palmer(2010) 的測試使用論證(Assessment Use Argument, 簡稱AUA)(參見圖3)。
近年來,隨著測試效度論證觀的出現及其驗證模式轉變,測試學界也紛紛從論證的角度對語言測試公平性進行研究,提出基于論證的公平性研究模式,如Xi (2010)的公平性論證框架(Fairness Argument Framework)。Xi認為,測試公平性指測試所有環節對所有的相關考生群體具有相同的有效性,即對于所有相關考生群體而言,與構念無關因素、構念代表性不足、不一致的施測行為以及不恰當的決策程序或測試結果的使用,對考試分數及其解釋以及基于分數所作的決定與后果不會產生系統性的影響(Xi 2010:154)。基于該定義,Xi提出研究公平性的框架——公平性論證框架,該框架內嵌于效度論證框架,稱作“效度論證中的公平性論證”,并用TOEFL iBT 為例進行說明(同上:155)。Xi的效度論證包含6個分論證(sub-argument):(1)證據表明目標語言使用域能夠提供對考生測試表現進行觀察的有意義的基礎;(2)證據表明觀察分是考生目標語言使用的反映,而不是構念無關因素的反映;(3)證據表明觀察分具有概推性,即考生在類似的其他考試中得分相同;(4)證據表明觀察分的概推性是有理論基礎的,即是基于構念的推論;(5)證據表明構念能夠解釋非測試環境下的目標語言使用;(6)證據表明基于考試結果對考生語言能力水平的判斷具有相關性,對決策具有有用性與充足性(同上:156-157)。可見,Xi(2010)的效度論證框架經過目標域的界定(Domain definition)、評價(Evaluation)、概化(Generalization)、解釋(Explanation)、外推(Extrapolation)與使用(Utilization)6次推論,從考生的測試表現到基于測試結果對考生語言能力的判斷與使用形成一個嚴密而連貫的推論鏈,從而明確證據收集的起點、終點、數量與種類,在此過程中也完成測試的公平性論證,每次效度論證和公平性論證都采用Toulmin (2003) 的實用推理模型,由事實、主張、理由、證據、假設以及反駁構成。其中,反駁有兩類,一類是對所有考生來說,由于缺乏相應的反面證據(counter-evidence)而使結論的說服力減弱;另一類是指對特定考生群體而言,結論是無效的或是站不住腳的(Xi 2010: 158-164)。Xi就效度論證中外推環節的公平性論證以TOEFL iBT為例進行說明(參見圖4)(Xi 2010:165)。

圖2 解釋性論證的推理鏈(改自Kane 2006, Bachman 2005)
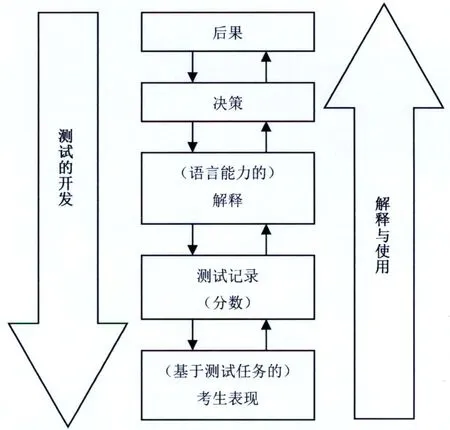
圖3 AUA框架(Bachman, Palmer 2010:91)

圖4 效度論證外推環節中的公平性論證舉例(改自Xi 2010:165)
5 語言測試效度與公平性的關系
通過以上分析可以看出,語言測試公平性及其研究模式隨著語言測試效度及其驗證模式的變化而變化,二者之間的關系較復雜,學界存在3種觀點:二者是并列的、效度包含在公平性之中以及公平性包含在效度之中。
語言測試效度與公平性是并列的,即二者分別是一個獨立的概念。首先,1999版的《標準》對二者分別給出定義(見前文)。從兩個定義來看,二者沒有直接聯系且各有側重:前者偏重檢驗分數解釋和使用是否有意義,后者著重衡量考生在考試的設計、開發和使用過程中是否享受平等待遇。再者,《教育公平測試實踐規范》(CodeofFairTestingPracticesinEducation2004)也明確規定測試開發者與使用者對整個測試過程進行獨立的公平性研究,具體包括試卷的編制與題目的選擇、考試的實施與評分、分數的報道與解釋以及考試信息的反饋4個環節。
效度包含在公平性之中,即效度被看成是公平性的一部分。比如Kunnan(2000) 的公平性研究框架包括效度、機會均等和公正性3個組成部分,很明顯,效度是衡量公平性的重要指標。Kunnan (2004) 公平性研究框架由3個組成部分擴展到5個后,效度依然被認為是公平性的一部分。
公平性包含在效度之中,即公平性是測試效度的重要方面,甚至把公平性稱作可比性效度(comparable validity) (Willingham, Cole 1997:6-7),是效度的一個種類。可比性效度指在一項公平的測試中,測量誤差與基于測試結果對考生能力的推論對所有考生來說具有可比性。可比性效度貫穿測試的整個過程,涉及考試內容的選取、施考困難的避免、相同的評分過程等方面,無非是盡量避免與構念無關因素的影響與構念代表性不足,這兩者也是效度研究的重要方面。
簡單來講,語言測試效度與公平性的關系問題其實就是如何看待二者重要性的問題。如果研究者把效度和公平性看成是測試同等重要的兩個方面,就會把二者當做兩個并列的獨立的概念進行研究;如果認為效度更重要些,就會把公平性看成是效度的一部分;反之,亦然。
6 結束語
效度是評價一項測試質量的重要指標,一直是測試界的研究主題。近些年來,隨著測試領域由重視技術向重視測試結果的使用及決策的社會影響的轉變,公平性研究也成為測試界熱議的話題。但是,學界在某些問題上還沒有達成共識,比如,什么是公平性,如何處理效度與公平性之間的關系,公平性研究是否有必要,對最后一個問題的爭論尤為激烈。2010年,Davies曾撰文回應“How do we go about investigating test fairness”(Xi 2010) 一文,認為沒有必要進行測試公平性研究,因為公平性研究與效度研究如出一轍,而且根本不可能有測試公平,測試公平只是一種幻想(Davies 2010:173-175)。因此,今后的研究應多關注此類問題,深入探究測試公平性的性質、研究內容與方法,設計出令人信服的研究框架,從而擺脫與效度研究如出一轍的套路。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
文苑(2020年4期)2020-05-30 12:35:30
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
汽車工程學報(2017年2期)2017-07-05 08:13:02
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
