基于關系數據庫的《說文》部首數據庫的構建
2018-09-24 11:43:18霍寧宇殷冬曹陽
神州·上旬刊 2018年9期
關鍵詞:數據庫
霍寧宇 殷冬 曹陽


摘要:作為信息化技術與傳統學科的結合點,運用新技術對傳統學科材料進行處理和分析已成為一種趨勢。本文從字形、字音、字義等方面對《說文》部首及相關材料進行梳理,以Microsoft Access 2010 為系統運行平臺試制數據庫,采用關系型數據庫模式,并簡要論述了數據庫技術在傳統學科研究的價值與意義。
關鍵詞:《說文》;部首;數據庫
隨著數據化的進一步發展,傳統學科與信息技術的結合已經成為必然的趨勢。《說文》作為傳統文字學的重要典籍之一,如何對其進行數據化是一項很有意義的研究,但在已有的一些查詢網站和相關數據庫仍存在一定的不足。本文通過對《說文》部首及相關數據的處理并對數據庫的建構進行嘗試,希望能夠對相關研究提供幫助。
1《說文》部首數據庫的建構意義
數據庫是按照一定結構組織,可以長期存儲在計算機內的、具有某些內在含義的、在邏輯上保持一致的、可共享的大量數據集合。數據庫技術是目前使用計算機進行數據處理的主要方式,在以大批量數據的存儲、組織和使用為基本特征的領域里,數據庫有著廣泛的應用。
對《說文》部首進行數據庫化,其必要性主要體現在以下幾個方面:
1.1 部首全面梳理的需要
無論是《說文》中部與部、部與字的關系還是具體到字中形音義之間的關系,都不是單純的平面化單線性的材料堆疊,而是具有內在邏輯的多層次關系。因此,在對《說文》進行的研究中,限于原有的材料處理方式,無法便捷高效的將其中關系直觀展現出來,需要借助計算機數據庫技術的介入,才能對對象材料進行立體化的處理并以二維表格的形式展示出來。
1.2 部首對比分析的需要
《說文》首創“部首”這一概念,其后的歷代字書在編纂中大多仿說文這一體例編排,但會根據文字形體的不同加以增刪改變,由此可以一窺漢字部首在不同時期的演變規律,這要求對不同時期不同字書的部首進行對比分析的能力。
1.3 便利教學與研究的需要
在條件允許的情況下引入數據庫技術,對文獻材料的處理(如語料的分類等)既可以提高效率,避免不必要的資源浪費,也符合當下文獻數據化的發展趨勢,在傳統學科研究方式的革新方向提供探索的經驗。
2《說文》部首數據庫的設計
《說文》部首數據庫的構架,首先需要選定依據的文獻版本以及實現數據庫的數據庫管理系統。為了保證盡量高的質量,在文獻版本的選擇上,《說文》采用大徐本(中華書局1963),并參考了臧克和、王平、劉志基開發的“《說文解字》全文檢索系統”(南方日報出版社2004);在補充數據的選擇上,字形部分選擇了由陳彭年等校定的《大廣益會玉篇》(中華書局1987);字音部分反切以大徐本為主,現代漢語注音則參考王彤偉《說文解字五百四十部疏講》(巴蜀書社2012);字義部分仍以《說文》大徐本為主,參考徐鍇《說文解字系傳》(中華書局1987);在數據庫管理系統的選擇上,采用目前占據主流地位的關系型數據庫。
按照關系型數據庫的設計理念及建模方式,《說文》部首數據庫的構建分成以下幾個部分:
2.1 概念結構設計
概念結構設計,指的是使用實體關系圖(ER圖)對《說文》部首的組織結構進行概念結構分析,辨明其中的實體、屬性與聯系,從而構建出《說文》部首的概念結構模型,完成從現實世界到信息世界的第一層抽象。
分析《說文》部首,首先要了解把握《說文》整體的組織結構。《說文》的內部組織結構從實質上來說是一種層級結構:全書分若干卷,每卷分若干部,每部分若干字,每字分若干形。在這一結構下,說解、注音等內容依層歸附,形成整體。
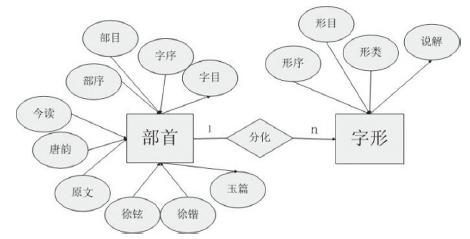
《說文》部首結構主要體現在部、字與形三者之間。且部首是部的代表,也是部中具體的一個字,可以將部與字歸并為“部首”一層,也即把《說文》部首的內在結構劃分為“部首”與“字形”兩級。在此基礎上抽象其概念并結合補充材料,用ER圖表現如下:
《說文》部首各實體及其屬性說明如下:
《說文》部首“部首”實體,有10個屬性:“部序”是“部”層面的數字序號,“部目”是各部首的名稱,“字序”是“字”層面的數字序號,“字目”是充當部首的具體字頭,“原文”是《說文》對字頭的說解,“徐鉉”是徐鉉對字頭的解釋,“徐鍇”是徐鍇對字頭的解釋,“今讀”是對字頭的現代漢語注音,“唐韻”是徐鉉所加的《唐韻》反切,“玉篇”是確認該部首在《玉篇》中是否仍為部首。
《說文》部首“字形”實體,有4個屬性:“形序”是“字形”的數字序號,“形目”是與字頭對應的各類字形,“形類”是《說文》及補充材料中對字形的歸類,“說解”是《說文》及其他材料中對字形的說明。
《說文》部首數據庫的所收材料除了來自《說文》本身的材料以外補充的內容,在數據分析中作為“部首”以及“字形”的屬性表現(如今讀,楷字等)。
2.2 邏輯結構設計
邏輯結構設計是依據關系數據理論的轉換規則,將《說文》部首ER圖中的實體、屬性以及實體之間的聯系轉換為相關的關系模式,從而構建出其中的邏輯結構模型,完成從信息世界到數據世界的二級抽象。
《說文》部首ER圖中包括“部首”和“字形”2個實體,相應可以轉化為2組關系,其中實體的屬性表現為關系的屬性;各實體之間都是1:n聯系,通過將實體1端(即“部首”)的主鍵納入實體n端(即“字形”)中作為外鍵,從而建立起關系之間的聯系。通過轉換,《說文》部首的邏輯關系表示如下(加下劃線的屬性為主鍵):
部首(部序、部目、字序、字目、原文、徐鉉、徐鍇、今讀、唐韻、玉篇)
字形(形序、形目、形類、說解、部序)
2.3 規范化分析
規范化分析,是根據關系規范化理論,對《說文》部首邏輯結構中的關系模式進行分析,確定各關系模式中屬性之間的函數依賴關系和達到的范式等級,從而檢測系統設計的優劣程度。
運用規范化理論,可以看出,在《說文》部首的各個關系模式中,主鍵都是本模式的唯一決定因素,所以這2個關系模式都屬于BC范式,在函數依賴的范疇內,規范化程度已經達到了最高。
2.4 表結構創建
表結構的創建即是根據關系數據庫管理系統的要求,將《說文》部首邏輯結構中的關系模式轉換為相應的數據表形式,并對數據表中的屬性名稱、數據類型、長度大小、取值范圍等問題做出規定與說明,以建立存儲數據的基表結構,也是對整個設計流程的全面總結和最終表示。
綜前所述,建立《說文》部首的表結構如表1、表2、表3:
以上為《說文》部首數據庫的表結構設計。
需要作出說明的是,對于表1的部首表,因為在材料的選取中每個部首所對應的讀音與釋義是可以區分且沒有重復數據的,在實際的建構中與設計完全符合;但表2的字形表由于本身類別歸屬的復雜性(《說文》本身的分類與補充材料合計12種),以及同一類別的數據較多的重復(古文有三種重復,或體有兩種,籀文有兩種等),且不同類別的字體間有不同的對應關系(相當的古文、篆文、籀文都有對應的楷字形態),如果統合表現在一個表中,不可避免會造成數據冗余。因此需要對每種字形建立數據表,其具體的結構如表3。
至此,基于關系數據庫理論的“《說文》部首數據庫”設計完成。
3《說文》部首數據庫的效用
根據上述設計方案,現已完成對《說文》部首及其相關材料數據的錄入和校對工作。該數據庫的具體效用可以從以下兩個方面進行說明:
3.1 對《說文》部首及相關材料進行系統整理
通過《說文》部首數據庫能夠實現對《說文》部首小篆、諸重文以及對應楷字的形體,讀若讀如到《唐韻》反切、現代漢語注音的字音,以及徐鉉、徐鍇的說解字義等內容嚴格意義的數據梳理和查詢設計,在此基礎上能夠形成詳細到各字頭各項信息的數據報表,這些都是傳統的訓詁疏證式的分析方法不能比擬的。
3.2 對相關研究提供便捷準確的數據支持
《說文》部首數據庫最主要的作用還是對數據進行梳理,為研究提供便利。相較于原來的材料分析方法,《說文》部首數據庫能將所有的數據從具體需求的角度提供,在數據范圍能夠包含的情況下減少大量的重復勞動,且依靠計算機的處理能力,也可以盡量的避免失誤的出現。
在傳統語言文字研究中引入數據庫技術,不僅能在文獻語料的統計處理上更為方便準確,而且還能通過建模設計過程與量化分析方式,充分展現出研究對象內在的本質特征和外在的表現特點,真正實現了研究手段的科學化和表達形式的精確化。
參考文獻:
[1]許慎.說文解字[M].北京:中華書局,1963.
[2]顧野王.大廣益會玉篇[M].北京:中華書局,1987.
[3]臧克和,王平,劉志基.《說文解字》全文檢索[M].廣州:南方日報出版社,2004.
[4]劉志嫵,張煥君,馬秀麗.基于VB和SQL的數據庫編程技術[M].北京:清華大學出版社,2008.
[5]宋繼華,王寧.基于超文本環境的《說文解字》知識庫的建立[J].語言文字應用,1999(3):90-96.
[6]李恩江.說文部首的成因及構成[J].鄭州大學學報,2002(5):20-24.
[7]宋繼華,李桂芳.數字化《說文解字》教學系統的設計[J].現代教育技術,2007(3):25-31.
[8]王晴.說文解字五百四十部研究[D].江西師范大學,碩士,2007.
[9]胡佳佳.《說文》內在系統的數字化模型研究[D].北京師范大學,博士,2010.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
