基于隨機森林的加權(quán)特征選擇算法
2018-10-17 08:37:36徐少成李東喜
統(tǒng)計與決策 2018年18期
徐少成,李東喜
(太原理工大學(xué) 數(shù)學(xué)學(xué)院,太原 030024)
0 引言
面對大量的高維數(shù)據(jù),剔除冗余特征進行特征篩選,已成為當(dāng)今信息與科學(xué)技術(shù)面臨的重要問題,也是人們研究努力的方向。特征選擇是從原始特征中根據(jù)一定的評估準(zhǔn)則剔除一些不相關(guān)特征而保留一些最有效特征的過程,且在特征選擇后分類正確率近似比選擇前更高或近似[1]。Davies證明了篩選最優(yōu)特征子集是一個NP完全問題[2]。目前,特征子集的選擇方法上主要有基于信息熵、神經(jīng)網(wǎng)絡(luò)、支持向量機等算法[3-9]。
隨機森林(Random forest,RF)[10]是利用多棵決策樹對樣本進行訓(xùn)練并集成預(yù)測的一種分類器,它采用bootstrap重抽樣技術(shù)從原始樣本中隨機抽取數(shù)據(jù)構(gòu)造多個樣本,然后對每個重抽樣樣本采用節(jié)點的隨機分裂技術(shù)來構(gòu)造多棵決策樹,最后將多棵決策樹組合,并通過投票得出最終預(yù)測結(jié)果。RF對于含有噪聲及含缺失值的數(shù)據(jù)具有很好的預(yù)測精度,并且可以處理大量的輸入變量,具有較快的訓(xùn)練速度,近些年來已被廣泛用于分類、特征選擇等諸多領(lǐng)域。
本文以加權(quán)隨機森林的變量選擇特性來研究特征選擇算法,用WRFFS算法來進行特征的剔除、篩選,以選出最優(yōu)的特征子集,相比于文獻中的IFN[3]、Relief[4]、ABB[5]、CBFS[6]等特征選擇方法,本文算法WRFFS在分類性能(分類準(zhǔn)確率、最優(yōu)特征子集)上均有很大提升。
1 隨機森林
定義1[1]:隨機森林是由一組基本的決策樹分類器合成的集成分類器,其中隨機向量序列獨立同分布,K表示基決策樹的個數(shù)。在給出自變量X情況下,每個基分類器通過投票選出最好的分類結(jié)果,經(jīng)過K輪訓(xùn)練,得到一個分類模型序列:
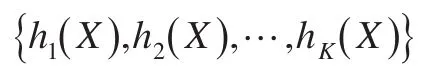
再利用它們構(gòu)造成一個多分類模型系統(tǒng),該系統(tǒng)的最終分類結(jié)果以多數(shù)投票結(jié)果為準(zhǔn)。最終的分類決策結(jié)果:
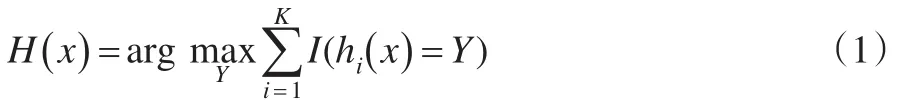
其中H(x) 表示隨機森林的分類結(jié)果,hi(x)表示每個決策樹分類器的預(yù)測分類結(jié)果,Y表示分類目標(biāo),I(·)表示示性函數(shù)。
定義2[1]:給定一組基分類模型序列{h1(X),h2(X),…,hk(X)},每個模型的訓(xùn)練集隨機從原始數(shù)據(jù)集(X,Y)中抽取,因此余量函數(shù)為:
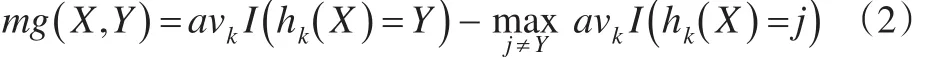
mg(X,Y) 表示余量函數(shù),I(·)表示示性函數(shù),余量函數(shù)值反映了正確分類結(jié)果超過錯誤分類結(jié)果的程度。
定義3[1]:泛化誤差的定義為:

式中,下標(biāo)X,Y表示概率P覆蓋X,Y的空間。
當(dāng)決策樹分類模型足夠多時,hk(X) =h(X,θk) 服從強大數(shù)定律。
性質(zhì)1:隨著分類模型的增多,對于所有序列θ1,θ2,…,PE*幾乎處處收斂于:
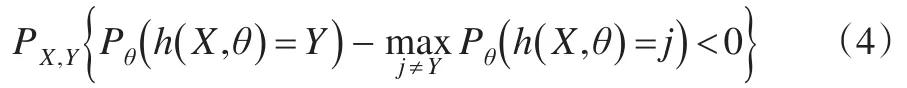
性質(zhì)1說明了隨著決策樹分類模型的增加,隨機森林不會出現(xiàn)模型過度擬合問題,但模型會生成一定程度的泛化誤差。
2 隨機森林的特征選擇算法
本文基于隨機森林來設(shè)計特征選擇算法,采用袋外數(shù)據(jù)(記為OOB)做測試集。本文算法是利用重抽樣技術(shù)構(gòu)造多個數(shù)據(jù)集,分別在每個數(shù)據(jù)集上進行特征重要性度量,然后給每個特征重要性度量加上權(quán)值,最后綜合評估特征重要性度量。
2.1 算法描述
本文的算法WRFFS,利用特征重要性度量值作為特征排序的重要依據(jù),依次從特征中去掉一個重要性最低的特征,并計算每次剔除后的分類正確率,選取最高正確率對應(yīng)的特征變量作為最優(yōu)特征選擇結(jié)果。為了消除數(shù)據(jù)不均衡帶來的大偏差影響,本文采用10折交叉驗證計算分類正確率,取10次分類的平均正確率作為本輪迭代的分類正確率。其中以10次訓(xùn)練中最高正確率對應(yīng)的訓(xùn)練數(shù)據(jù)作為進行特征重要性排序的原始數(shù)據(jù)。
算法的具體過程如下(注:N代表原始數(shù)據(jù)中特征的總數(shù)):
輸入:原始數(shù)據(jù)集S;
最大分類正確率MaxAcc=0
過程:for t=1,2,…,N-1
1:將原始數(shù)據(jù)集S隨機均分成10份;
2:設(shè)置局部的平均分類正確率MeanAcc=0;
3:for i=1,2,…,10
4:初始化每次迭代的正確率為Acc=0;
5:在數(shù)據(jù)集S上運行randomForest創(chuàng)建分類器;
6:在驗證集上進行分類;
7:比較分類結(jié)果,計算每次迭代的分類正確率Acc;
8:計算平均分類正確率,MeanAcc=MeanAcc+Acc/10;
end for
9:對特征按重要性度量進行排序;
10:比較 if(MaxAcc<=MeanAcc)
則(MaxAcc=MeanAcc);
11:剔除特征重要性排序中最不重要的一個特征,得到新的數(shù)據(jù)集S;
end for
輸出:全局的最高分類正確率MaxAcc;
全局的最高分類正確率對應(yīng)的特征選擇集合
2.2 特征重要性度量
本文基于OOB樣本數(shù)據(jù)來做特征的重要性度量。為了避免OOB數(shù)據(jù)類別嚴(yán)重不均給算法結(jié)果帶來的影響,本文采用K折交叉驗證來計算特征的重要性度量值。本文WRFFS方法在計算特征的重要性度量值時,通過分別在每個特征上添加噪聲然后進行分類正確率的對比,來確定特征的重要性程度(當(dāng)一個特征很重要時,添加噪聲后,預(yù)測正確率則會明顯下降,若此特征是不重要特征時,則添加噪聲后對預(yù)測的準(zhǔn)確率影響微小)。本文K的取值采用簡單的交叉驗證思想,將K取值為5,取5次的平均值作為最終的性能評價標(biāo)準(zhǔn)。
設(shè)原始的數(shù)據(jù)集為D,特征個數(shù)為N,經(jīng)過重抽樣后的數(shù)據(jù)集為Repeated Sampling-D(簡記為RS-D),個數(shù)為M。
隨機森林的Bagging步驟就是對原始數(shù)據(jù)進行Bootstrap取樣,為了保證分類的精度,WRFFS經(jīng)過多次重復(fù)取樣構(gòu)造多個數(shù)據(jù)集。在每個RS-D數(shù)據(jù)集上構(gòu)造一棵決策樹,通過給特征添加噪聲對比分類正確率,得到一個特征的重要性度量。M個RS-D數(shù)據(jù)集可以得到M個特征的重要性度量。但是每個RS-D數(shù)據(jù)所獲得的特征重要性的可信度(權(quán)重)不同。因此WRFFS方法的主要步驟就是計算特征的重要性度量值和權(quán)重的大小。
第j個屬性的特征重要性度量是由R和Rj的差值所決定的,其中R表示的對特征添加噪聲前的分類正確的個數(shù),Rj表示的對特征添加噪聲后的分類正確的個數(shù)。由于采用的是五折交叉驗證,每個RS-D數(shù)據(jù)集分成五份,五份數(shù)據(jù)集交叉作為測試數(shù)據(jù)集,因此在同一RS-D數(shù)據(jù)集上,R和Rj需要分別計算五次,最后第j個特征的重要性度量FMij是由五次產(chǎn)生的平均差值來決定:
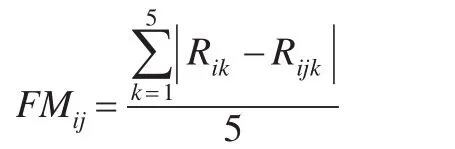
其中i代表第i個RS-D數(shù)據(jù)集,j代表第j個特征,k代表第k層數(shù)據(jù)。
2.3 權(quán)重度量
假設(shè)存在一個樣本數(shù)為T的測試數(shù)據(jù)集,有M個不同的RS-D數(shù)據(jù)集產(chǎn)生M棵決策樹。根據(jù)決策樹的預(yù)測結(jié)果可以獲得一個T×( )M+2 的矩陣,矩陣的每行代表著要預(yù)測的樣本,矩陣的前M列分別表示M棵決策樹對每個樣本的預(yù)測結(jié)果,第M+1列代表前M棵決策樹對每個樣本綜合投票的結(jié)果(前M列中每行中占多數(shù)的樣本分類結(jié)果判定為該樣本的最終分類結(jié)果放在第M+1列),第M+2列代表測試數(shù)據(jù)的真實分類結(jié)果。則第i棵決策樹的可信度(權(quán)重)可由下列公式得到:
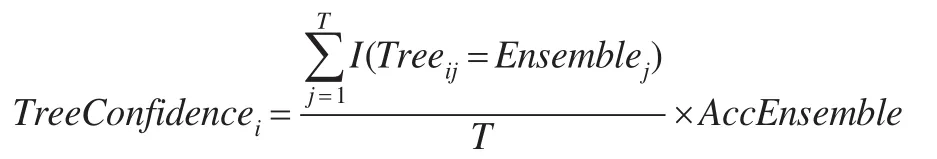
其中TreeConfidencei表示第i棵決策樹的權(quán)重,Treeij表示第i棵決策樹對第j個樣本的預(yù)測結(jié)果,Ensemblej表示所有決策樹對第j個樣本的集成預(yù)測結(jié)果。AccEnsemble表示集成預(yù)測的準(zhǔn)確率,即Ensemble與Original的相符程度。由于每棵決策樹的AccEnsemble值都是一樣的,因此是否考慮AccEnsemble的作用對排序結(jié)果沒有影響,但本文在計算權(quán)重時加入這個因素,其目的是盡量縮小各決策樹間權(quán)重的相對差距。
表1(見下頁)是一個M=7,T=5的一致性度量矩陣。
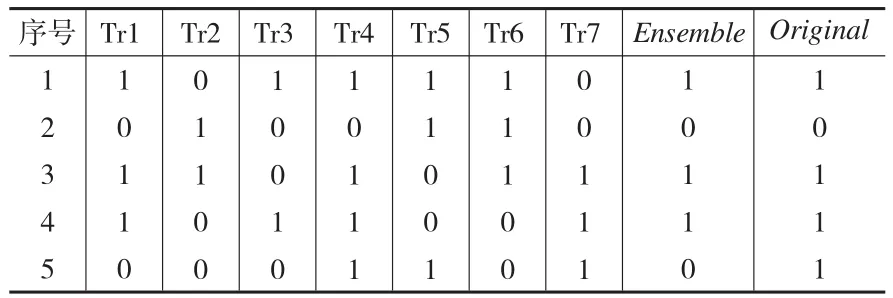
表1 M=7,T=5的一致性度量矩陣
表1列出了7棵決策樹分別對5組數(shù)據(jù)的分類結(jié)果,Ensemble對應(yīng)那一列為7棵決策樹分別對5組數(shù)據(jù)的集成結(jié)果,以超過半數(shù)的結(jié)果作為最終的集成結(jié)果,Original對應(yīng)那一列分別為5組數(shù)據(jù)的真實分類標(biāo)簽。
若不考慮AccEnsemble因素,根據(jù)可信度公式分別計算出來Tri的可信度:
TreeConfidence1=1,TreeConfidence2=0.4,TreeConfidence3=0.8,TreeConfidence4=0.8,TreeConfidence5=0.2,TreeConfidence6=0.6,TreeConfidence7=0.6
若考慮AccEnsemble因素,根據(jù)可信度公式分別計算出來Tri的可信度:
AccEnsemble=0.8
TreeConfidence1=0.8,TreeConfidence2=0.32,TreeConfidence3=0.64,TreeConfidence4=0.64,TreeConfidence5=0.16,TreeConfidence6=0.48,TreeConfidence7=0.48
所以最終的特征重要性度量值FinalMetric可通過下式計算:

其中j表示第j個特征。
3 實驗結(jié)果及分析
3.1 實驗數(shù)據(jù)
為了方便比較和分析,在UCI數(shù)據(jù)集文獻[11]中挑選了8個具有代表性的數(shù)據(jù)集。表2列出了這些數(shù)據(jù)集的特征。
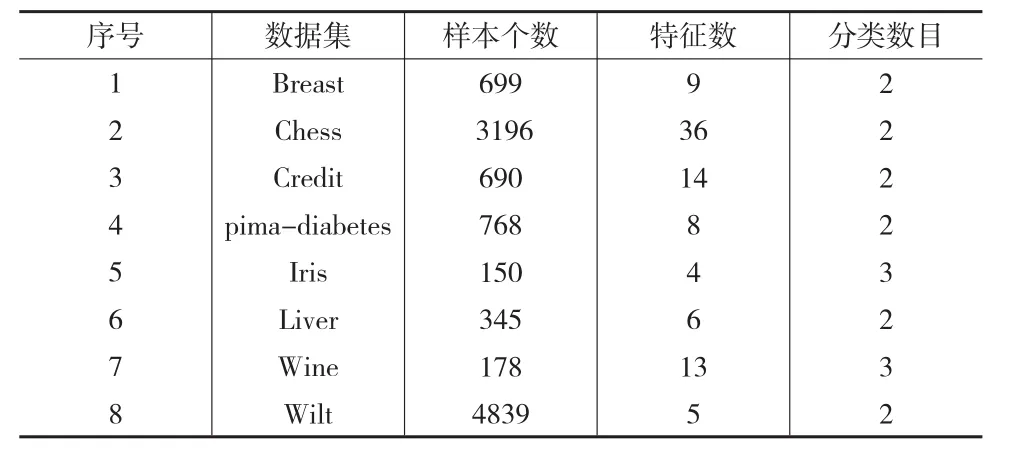
表2 取自UCI的實驗數(shù)據(jù)匯總
3.2 實驗結(jié)果
在每個數(shù)據(jù)集上,運行本文的特征選擇算法WRFFS,記錄在每個數(shù)據(jù)集上進行特征選擇后挑選出的最優(yōu)特征子集及對應(yīng)的分類正確率。表3和表4分別給出了這些數(shù)據(jù)總特征數(shù)及在 IFN、Relief、ABB、CBFS、WRFFS算法下進行特征重要性排序而得到的最優(yōu)特征集的大小。表中最后一列給出了本文WRFFS算法選出的最優(yōu)特征子集。為了驗證WRFFS在選擇特征時的穩(wěn)定性,表3的WRFFS方法在計算特征重要性度量時進行特征值干擾的方式是添加高斯噪聲,表4的WRFFS方法在計算特征重要性度量時進行特征值干擾的方式是擾亂特征值。
表5列出了隨機森林在IFN、Relief、ABB、CBFS、WRFFS算法下進行特征選擇后的分類錯誤率,最后兩列列出了本文方法WRFFS在兩種不同的噪聲干擾下經(jīng)過特征選擇后的分類錯誤率。表中第一列為本文方法在數(shù)據(jù)集上進行特征選擇前的分類錯誤率。
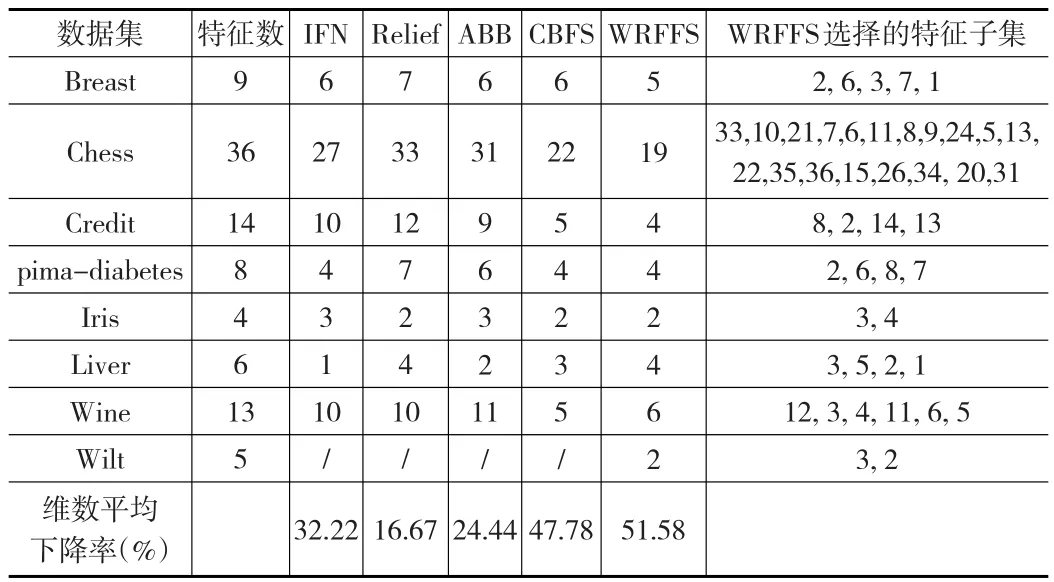
表3 各個算法得到的特征子集的大小(添加高斯噪聲)
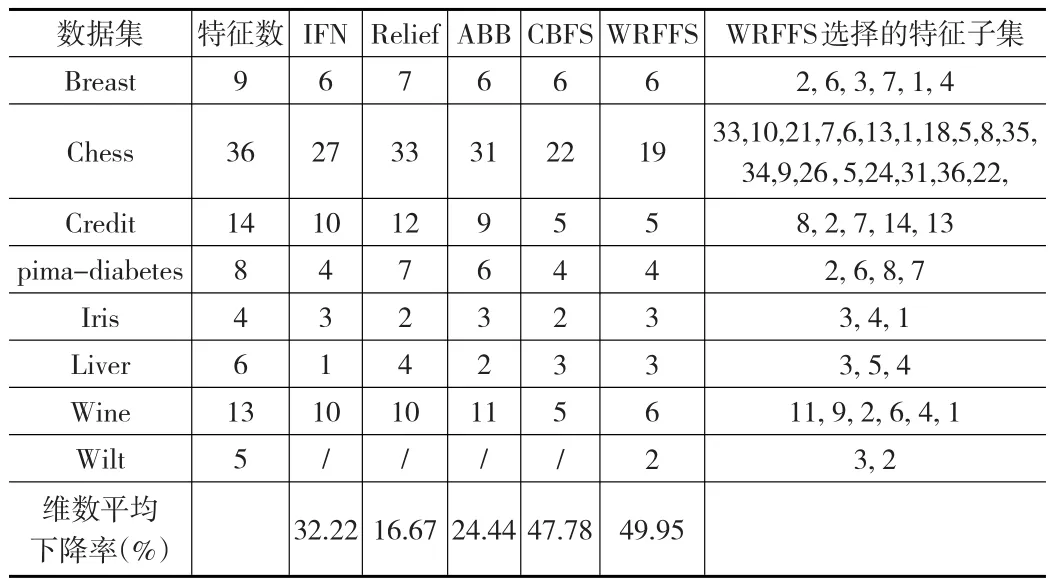
表4 各個算法得到的特征子集的大小(擾亂特征值)
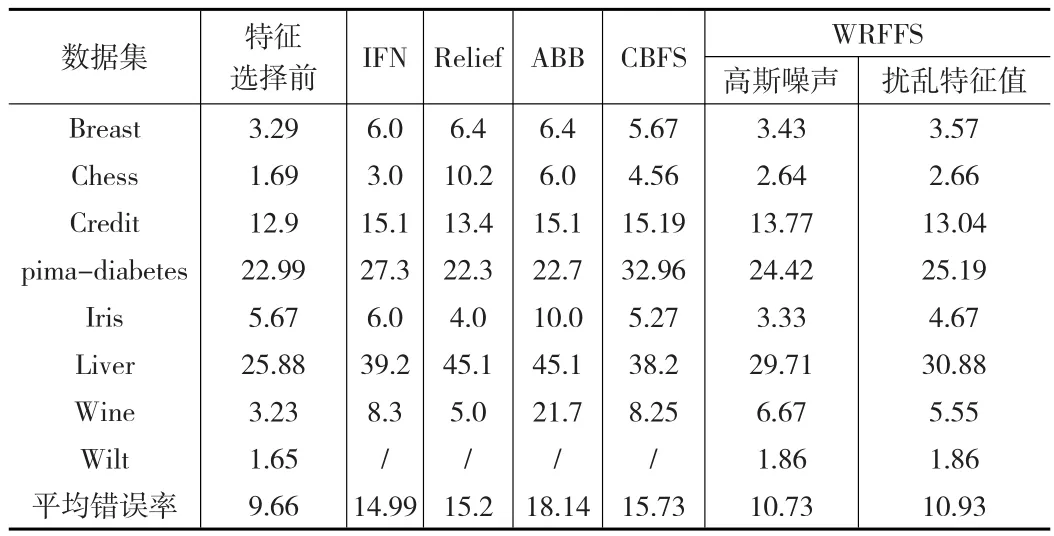
表5 隨機森林在全部特征及進行特征后的特征子集上的分類錯誤率(%)對比
通過對表3、表4的特征選擇結(jié)果和表5的分類錯誤率分析,盡管用不同類型的噪聲來擾動特征屬性值,但他們最終選擇的特征子集和分類錯誤率卻是幾乎一致的,這也說明了本文的方法WRFFS在特征選擇上是穩(wěn)定的。再對比本文的WRFFS和IFN、Relief、ABB、CBFS在最終選擇出的子集特征維數(shù)看,IFN、Relief、ABB選擇出的特征維數(shù)平均下降了大約30%以下,CBFS選擇出的特征維數(shù)平均下降了大約48%,而WRFFS選擇出的特征維數(shù)平均下降了大約50%。除了CBFS和WRFFS選出的特征子集維數(shù)相差不多外,IFN、Relief、ABB選擇出的特征子集維數(shù)下降率明顯低于WRFFS方法,說明本文的WRFFS在特征選擇數(shù)目上具有一定的優(yōu)勢。
分析表5中的數(shù)據(jù)發(fā)現(xiàn),IFN、Relief、ABB、CBFS經(jīng)過特征選擇后的平均分類錯誤率大約在15%左右,而本文的WRFFS經(jīng)過特征選擇后的分類錯誤率卻只有10%左右,相比其他方法的分類錯誤率下降了30%多。盡管CBFS選擇的特征子集維數(shù)和WRFFS方法幾乎一致,但WRFFS在特征選擇后的分類錯誤率比CBFS降低了30%多。WRFFS相比特征選擇前分類精度有些許下降,是因為特征選擇盡管去掉了一些不重要的特征,但也去掉了這些特征所包含的分類信息,所以分類精度稍許有些下降也是正常的。
綜合以上兩方面,本文的WRFFS不管在特征選擇的數(shù)目上還是在分類精度方面,WRFFS都較其他方法有很大的優(yōu)勢。由于選取的數(shù)據(jù)具有廣泛的代表性,所以說WRFFS在特征選擇上具有更強的適用性。
4 結(jié)束語
為了對大量高維數(shù)據(jù)進行降維以篩選出最優(yōu)特征子集,本文提出了基于隨機森林的加權(quán)特征選擇算法WRFFS。加權(quán)的思想主要體現(xiàn)在進行特征的重要性度量時,以往方法只對一個數(shù)據(jù)集利用決策樹進行一次特征重要性度量,本文方法通過對原始數(shù)據(jù)集重抽樣構(gòu)造多個小數(shù)據(jù)集,在每個小數(shù)據(jù)集上分別作一次特征重要性度量,然后對所有子數(shù)據(jù)集上的特征重要性度量值加權(quán)求和得到最終的特征重要性度量值。該算法以特征重要性度量為標(biāo)準(zhǔn)對特征按重要性程度進行排序,然后采用SBS法依次剔除排在最后一位的最不重要的特征,最后基于分類正確率挑選出最優(yōu)特征子集。實驗結(jié)果表明WRFFS具有很好的性能(特征選擇子集少,分類精度高),與文獻中的方法[3-6]相比具有很大的優(yōu)勢。所以WRFFS在特征選擇上具有更強的適用性。
由于WRFFS采用后向序列搜索法依次剔除排在最后一位的一個最不重要的特征,在面對高維或者超高維的大數(shù)據(jù)時,本文方法WRFFS效率不是很高。所以在后續(xù)的研究中可以從每次過濾掉不重要特征的數(shù)量上來提高算法整體的效率和性能。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:02
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年4期)2021-01-18 02:58:26
甘肅教育(2020年21期)2020-04-13 08:09:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
