基于幅度信息的標簽多伯努利濾波算法
2018-12-10 02:55:20彭華甫黃高明
系統工程與電子技術 2018年12期
彭華甫,黃高明,田 威,3,邱 昊
(1.海軍工程大學電子工程學院,湖北 武漢 430033; 2.中國人民解放軍92773部隊,
浙江 溫州 325807; 3.中國人民解放軍91715部隊,廣東 廣州 510450)
0 引 言
多目標跟蹤(multi-target tracking,MTT)的目的是在目標個數時變且未知的條件下,利用傳感器獲取的量測數據估計所有目標的狀態[1-2]。實際應用中,由于傳感器本身的特性,目標檢測存在虛警、漏檢現象,導致量測數據中包含雜波、部分真實目標由于漏檢未能獲取量測[3-4]。跟蹤器需要從雜波污染的量測數據中識別出真實目標量測,利用目標運動模型完成目標跟蹤。
由于地雜波、海雜波、大氣雜波以及人為電子干擾等因素的影響,實際量測數據不可避免會引入雜波,從而降低目標跟蹤效果[5]。在聲納、雷達等應用中,目標量測包括:距離、方位角、多普勒、幅度等信息。通常真實目標回波幅度大于雜波幅度,因此,可利用幅度信息區分目標量測與雜波量測,抑制雜波影響。
針對多目標跟蹤問題,傳統解決方案是一種自下而上的方法,其將多目標跟蹤過程分解為數據關聯和狀態估計兩部分。文獻[6]將目標幅度信息引入到概率數據關聯(probabilistic data association,PDA)濾波器中,改進了跟蹤濾波的性能;隨后文獻[7-8]分別將幅度信息引入到多假設跟蹤(multiple hypothesis tracking,MHT)框架以及Viterbi數據關聯框架下,改進了數據關聯效果。
然而傳統多目標跟蹤算法存在“組合爆炸”所導致的計算瓶頸。基于隨機有限集(random finite set,RFS)理論[9]的多目標跟蹤方法,能夠將單目標貝葉斯濾波框架直接擴展至多目標情形,避免了傳統方法復雜的數據關聯過程,成為目前多目標跟蹤領域的研究熱點[10-11]。為簡化計算,先后提出了概率假設密度(probability hypothesis density,PHD)、勢概率假設密度(cardinalized probability hypothesis density,CPHD)濾波器、多目標多伯努利(multi-target multi-Bernoulli,MeMBer)濾波器。為提高雜波環境適應能力,文獻[12-13]引入幅度信息,提出了幅度信息概率假設密度(amplitude information-PHD,AI-PHD)濾波算法,以增加少量計算復雜度為代價,有效改進了僅基于方位量測的跟蹤算法。由于PHD及CPHD均為多目標后驗概率密度函數的矩近似,其目標跟蹤精度有限,且序貫蒙特卡羅(sequential Monte-Carlo,SMC)實現時狀態提取需要復雜的聚類過程。MeMBer濾波器基于數值近似,具有更高的精度,且狀態提取簡單。文獻[14]通過引入幅度信息,提出了基于隨機有限集的幅度信息輔助多伯努利濾波(amplitude information assistant multi-bernoulli filter,AIA-MBerF)算法,提高了目標跟蹤精度。這些算法雖然在雜波環境下性能有一定的改善,但囿于PHD及MeMBer濾波器本身的缺陷,仍需要較高的信噪比,且無法直接估計航跡。
近年來,B Ngu Vo等提出了一種廣義標簽多伯努利(generalized labeled multi-Bernoulli,GLMB)濾波器[15-16]。同PHD、CPHD、MeMBer濾波器相比,GLMB無需共軛近似處理,具有更高的精度,抗干擾性能良好且可直接估計目標航跡。為降低計算量,文獻[17]基于量測分組并行處理,提出了LMB濾波算法;文獻[18-20]結合吉布斯采樣裁剪以及預測更新合并,提出了一種GLMB快速實現算法;文獻[21]基于矩近似,提出了τ-LPHD/LCPHD濾波器。為擴展算法的應用范圍,文獻[22-23]通過引入多模型(multi model,MM),提出了多模型標簽多伯努利(multi-model labeled multi-Bernoulli,MM-LMB)濾波算法,提高了對多機動目標跟蹤的適用性;文獻[24-26]將其應用于多傳感器多目標跟蹤領域。
本文通過結合幅度信息的雜波抑制能力及GLMB的抗干擾特性,提出了一種基于幅度信息的GLMB濾波(amplitude information-GLMB,AI-GLMB)算法,進一步提高雜波環境下的適應能力,并可直接估計目標航跡,具有更高的跟蹤精度。
1 GLMB濾波器及目標模型
1.1 GLMB濾波器
假設Xk和Zk分別為k時刻多目標狀態集合和量測集合,Z0:k=Z0,Z1,…,Zk為觀測集合序列,πk-1(·|Z0:k-1)、πk|k-1(·|Z0:k-1)和πk(·|Z0:k)分別為多目標先驗分布、預測分布及后驗分布。則多目標貝葉斯預測和更新方程分別為
πk|k-1(Xk|Z0:k-1)=
(1)
(2)
式中,fk|k-1(·|·)為多目標狀態轉移函數;gk(·|·)為多目標觀測函數。
GLMB通過引入標簽信息擴展目標屬性,標簽RFS狀態可表示為
X={(x,l)i}i=1,2,…,N
(3)
式中,x為單個目標狀態向量;l為其對應的標簽;X∈Xs×L,Xs為目標狀態空間,Ls為離散標簽空間。則GLMB分布可描述為
(4)
Δ(X)=δ|X|(|L(X)|)
(5)
(6)
式中,C為離散的索引空間;wc(·)為權值函數;pc(·)為單目標狀態分布;L為X×L→L的映射函數,即L((x,l))=l,L(X)={L(x):x∈X}為X的標簽值集合;|·|為取勢計算。
為便于處理,可將GLMB分布簡化為δ擴展GLMB(δ-GLMB)分布為
(7)
式中,I∈F(L)為標簽集合,F(L)表示L中所有有限子集空間;ε∈Θ為關聯索引,Θ為關聯空間;每對(I,ε)表示一種關聯假設,ω(I;ε)為相應權值;p(x,l;ε)為單目標概率分布。
1.2 目標模型
1.2.1 擴展幅度信息的目標模型
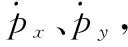
為引入幅度信息,分別對目標狀態及量測模型進行擴展,得到相應的擴展形式
(8)
(9)
式中,1+S為回波信號信噪比(signal-to-noise ratio,SNR);a為回波信號幅度,且有
SNR(dB)=10lg(1+S)
(10)
1.2.2 幅度模型
雷達系統中,目標回波信號的SNR往往是隨機變化的,依據文獻[6]將回波信號幅度建模為瑞利分布,則目標幅度及雜波幅度的概率密度分別表示為
(11)
(12)
假設檢測門限為τ,則經過門限檢測后,目標及雜波幅度的概率密度可表示為
(13)
(14)
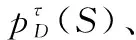
(15)
(16)
2 基于幅度信息的GLMB濾波器
由于目標的幅度信息僅與回波SNR有關,實際中SNR估計困難,可進行簡化處理,即

(17)
2.1 基于幅度信息的似然函數建模
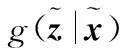
(18)
(19)
式中,ga(a|S)、ca(a)分別為檢波后目標幅度似然函數及雜波幅度似然函數,有
(20)
(21)
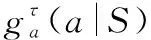
(22)
(23)
實際中,在監視區域內,各目標回波信號的SNR各不同且非固定。假設SNR在dB域[dB1,dB2]范圍內為均勻分布,其對應參數S的取值范圍為[S1,S2],則目標幅度似然函數可簡化表示[6]為
(24)
2.2 AI-GLMB濾波器
假設k-1時刻,多目標后驗密度為
πk-1(X)=Δ(X)·
(25)
新生目標概率密度可表示為
(26)
式中
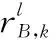
(27)
式中
ωk|k-1(I;ε)=ωP,k(I∩Lk-1;ε)ωB,k(I∩Bk)
ρε,k(l)=<1-pS,k(·,l),pk-1(·,l;ε)>
pk|k-1(x,l;ε)=
1Bk(l)pB,k(x,l)
式中,pS,k(·)為目標存活概率;Lk|k-1=Lk-1∪Bk;1I(·)為定義于集合空間的指示函數
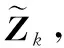
(28)
式中
式中,Lk=Lk|k-1;pD,k(·)為目標探測概率;對于k時刻每組預測假設(I,ε),ζk代表目標到量測的關聯映射{l1,l2,…,l|I|}→{0,1,…,|Zk|},當ζk(l)>0時,目標與空量測關聯,即該目標漏檢;當ζ(l)>0時關聯具有唯一性,即ζk(l)=ζk(l′)>0時l=l′。
2.3 AI-GLMB濾波器SMC實現
假設k-1時刻多目標后驗分布粒子描述為
(29)
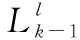
(30)
其中

更新過程中,粒子狀態保持不變。k時刻后驗分布粒子集為
(31)
其中
3 仿真實驗
3.1 參數設置
考慮二維非線性運動場景,目標狀態轉移矩陣及過程噪聲協方差矩陣分別為
式中,σv=0.1 m/s為噪聲標準差;Ts=1 s為傳感器掃描間隔。
傳感器量測包含直角坐標位置和幅度,量測范圍為[-1 000,1 000]×[-1 000,1 000],觀測矩陣及觀測噪聲協方差矩陣分別為
式中,σw=5 m為量測噪聲標準差。
3.2 仿真實驗分析
目標新生、消亡、漏檢、虛警等均依相應的概率發生,觀測場景中最多同時有8個目標,單次實驗目標真實航跡及量測如圖1所示。
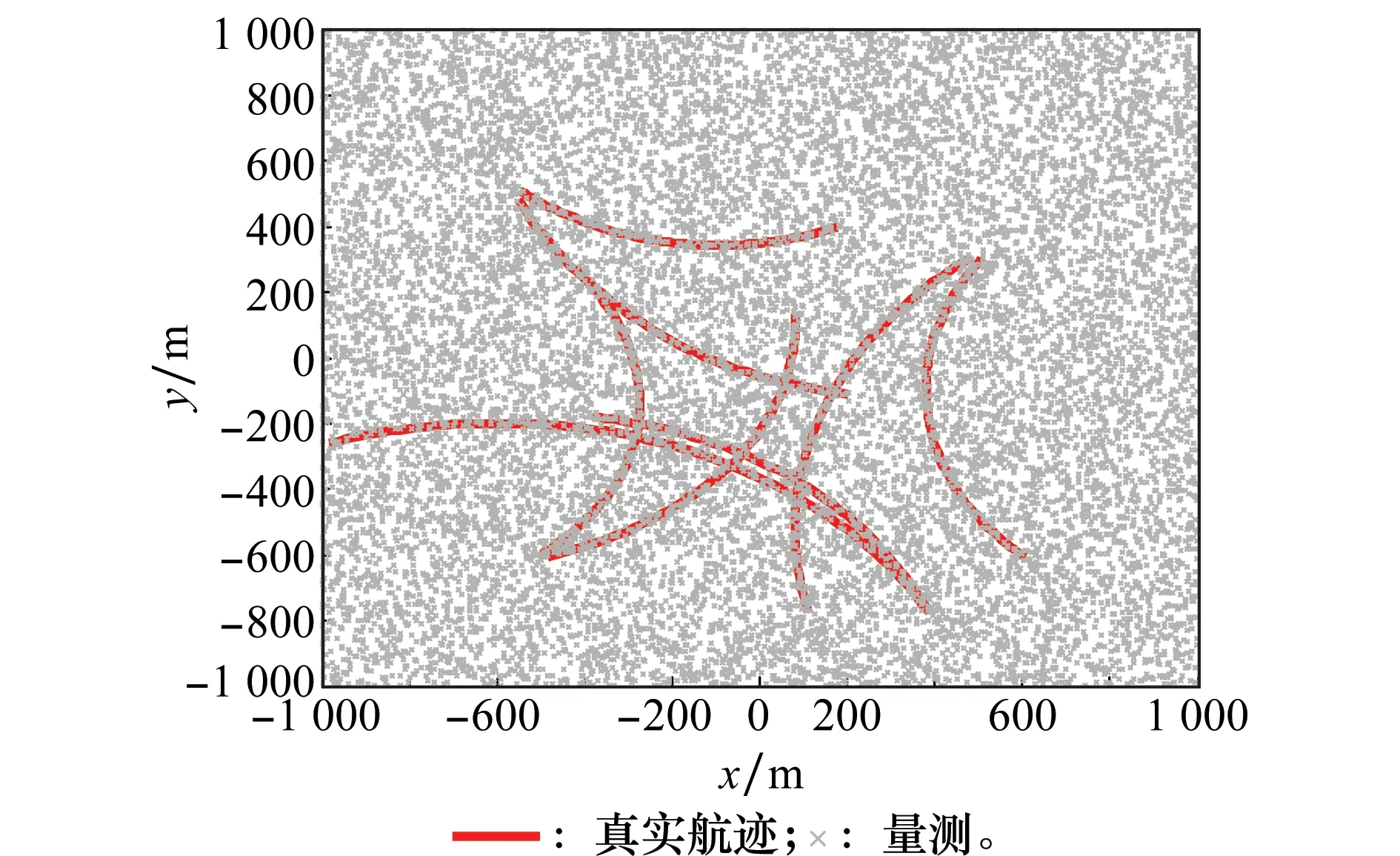
圖1 單次實驗目標真實航跡與量測Fig.1 True trafectories and measurements of a sigle trial
為直觀驗證本文算法的跟蹤效果,在相同條件下分別采用AI-PHD、GLMB、AI-GLMB算法進行跟蹤實驗。圖2為各算法單次實驗結果。可以看出,在高雜波環境下(λ=150),AI-PHD及傳統的GLMB算法跟蹤性能會衰減,出現目標丟失;而AI-GLMB算法仍能有效跟蹤目標。其原因為:PHD基于泊松假設,受雜波影響大,在雜波環境下,AI-PHD雖然采用幅度信息能抑制低幅度雜波的影響,但高幅度雜波仍會影響PHD跟蹤性能;GLMB算法基于多假設思想,利用多幀量測信息具有較好的抗干擾性能,但高雜波環境會削弱真實目標權重,導致目標丟失,降低跟蹤性能;AI-GLMB算法通過引入幅度信息,改進了似然函數,從而降低了雜波分量的權重,進一步增強雜波抑制能力,相比GLMB算法具有更好的跟蹤性能優勢。
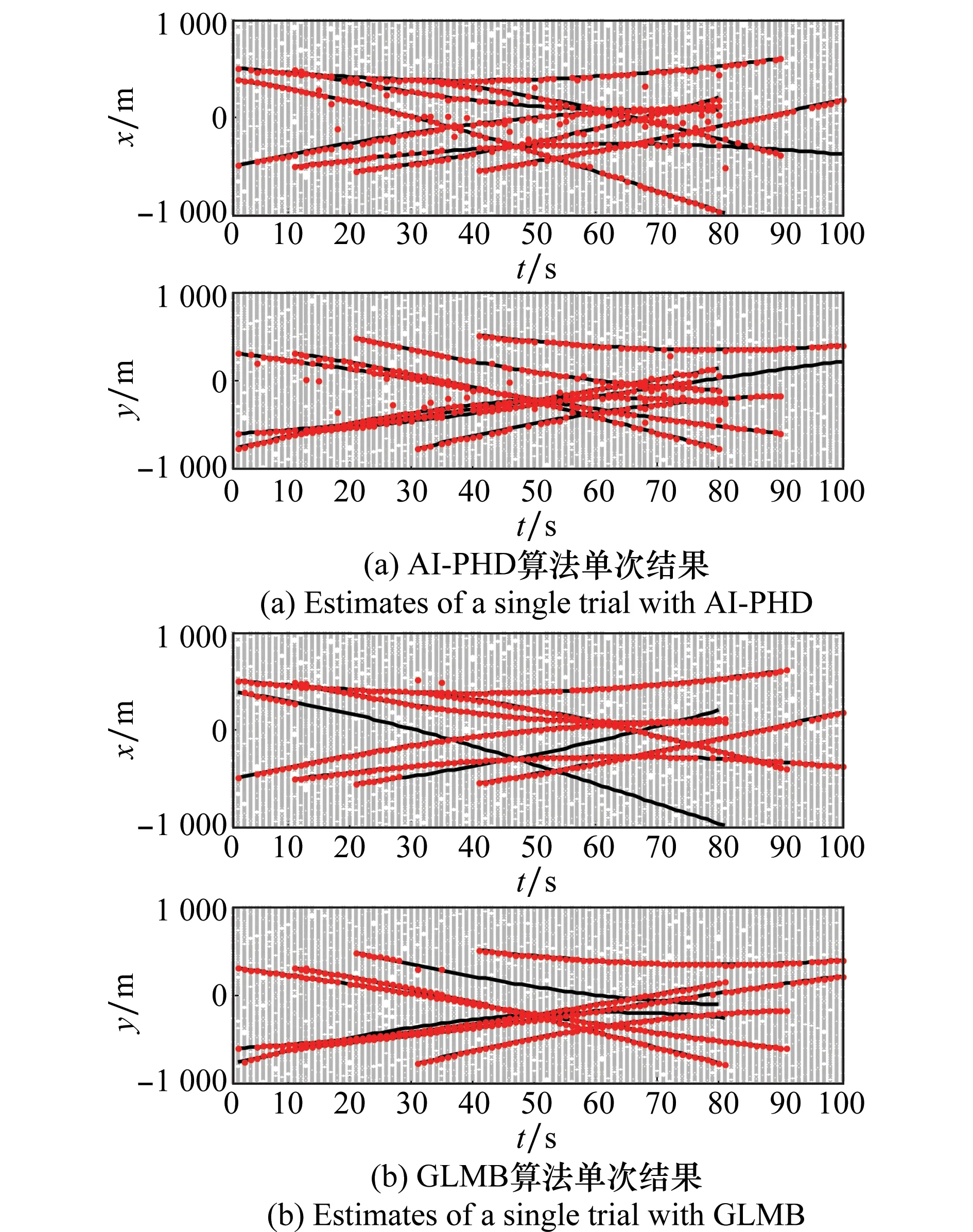
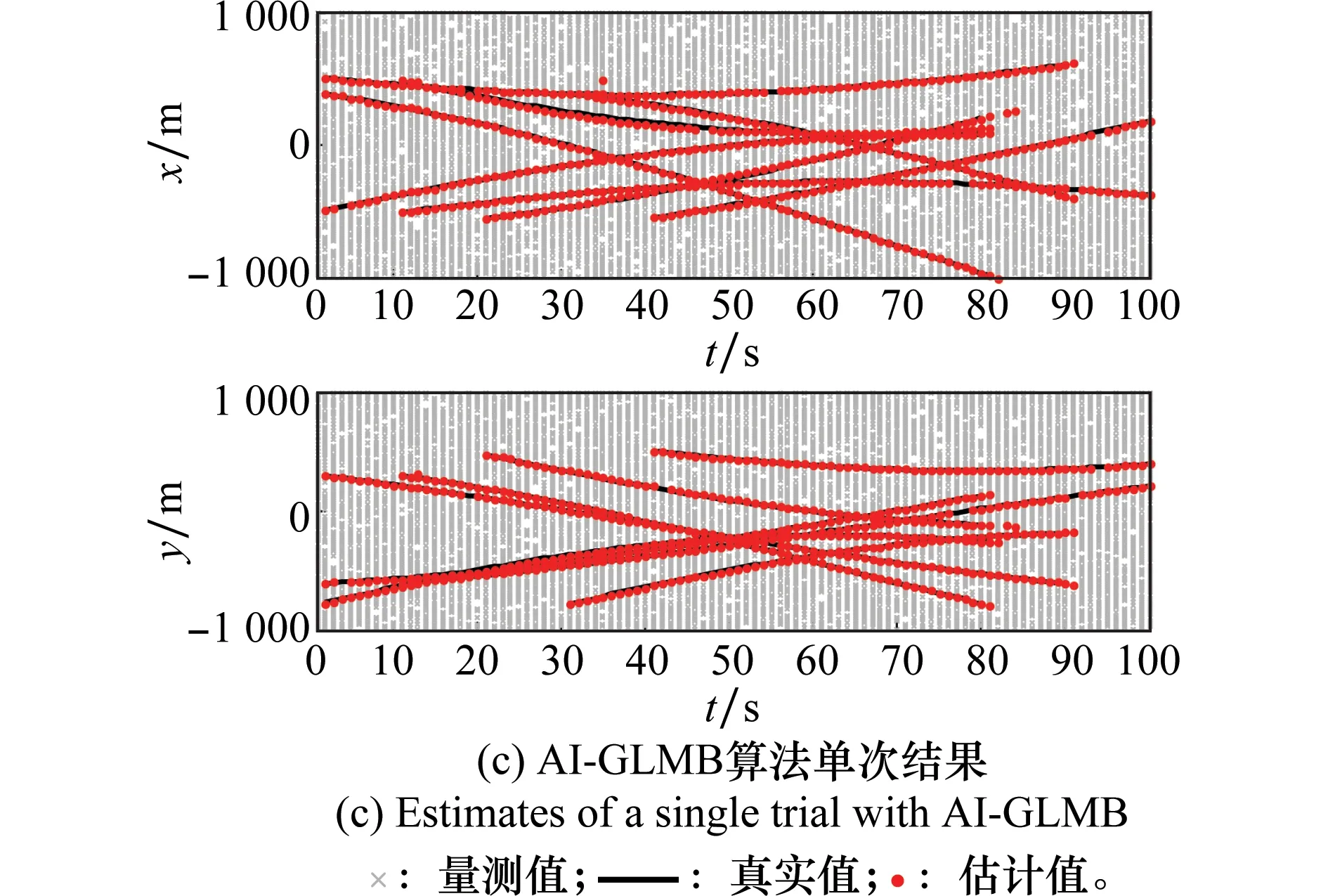
圖2 單次實驗結果Fig.2 Estimates of a single trial
為比較不同算法的估計性能,分別對AI-PHD、GLMB、AI-CBMeMBer、AI-GLMB算法進行100次蒙特卡羅實驗。圖3為不同算法勢估計方差結果。
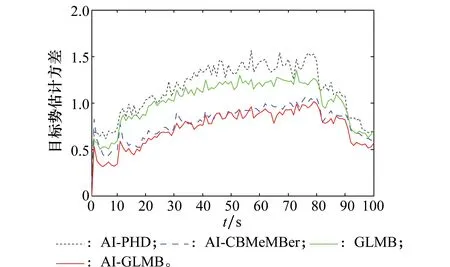
圖3 勢估計方差Fig.3 Variance of cardinality estimates
可以看出:AI-GLMB算法與AI-CBMeMBer算法勢估計方差相當,相比AI-PHD及GLMB跟蹤算法,方差更小,說明其勢估計更穩定。圖4為對應的平均最優子模式分配(optimal swb-pattern assignment,OSPA)距離如圖4所示。
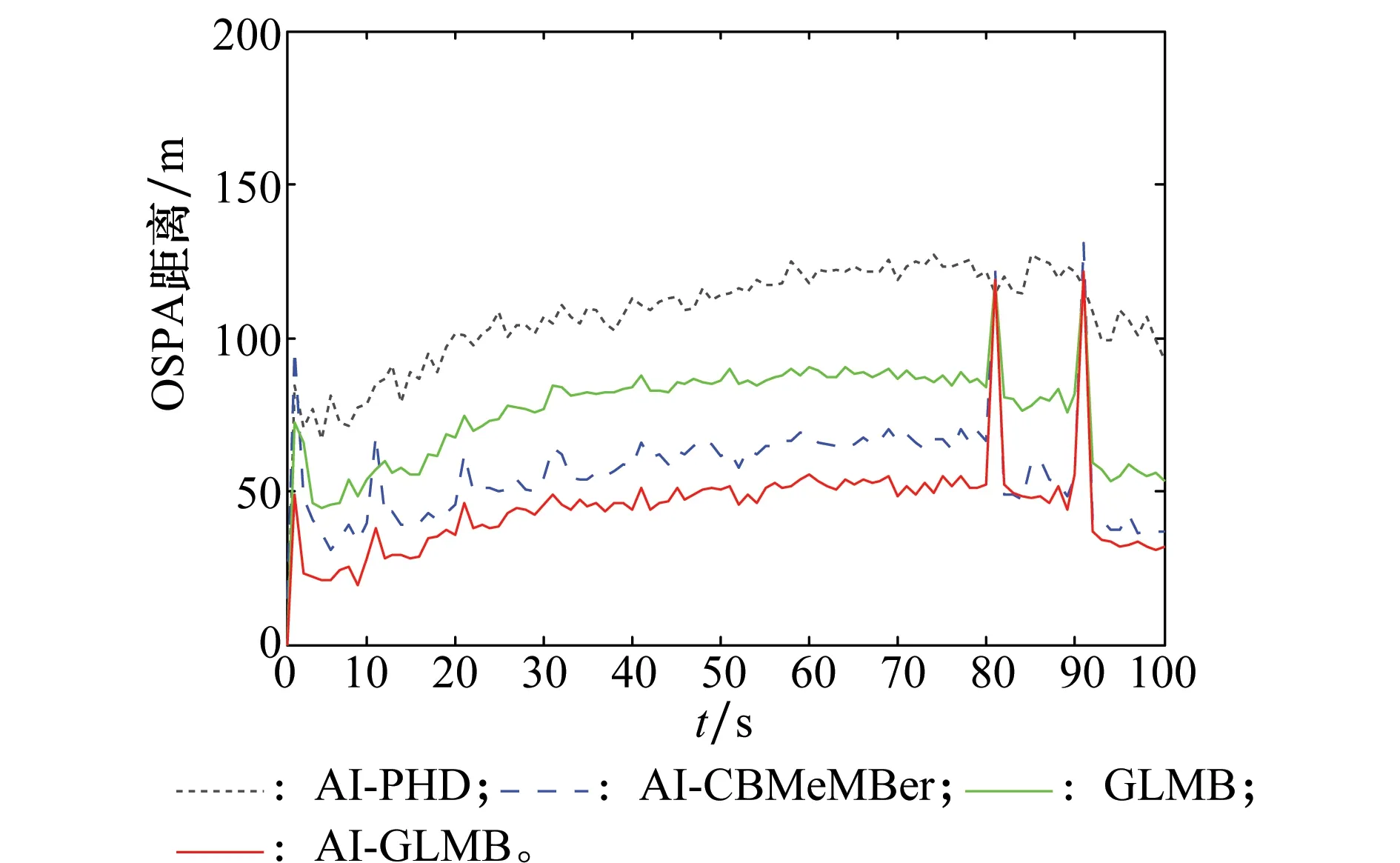
圖4 OSPA距離Fig.4 OSPA distance
可知:相比其他3種算法,AI-GLMB算法估計精度最高,這是由于PHD及CBMeMBer濾波器為保證共軛分布,均采用各種近似技術,從而降低了跟蹤精度。當目標消失時,同AI-CBMeMBer、GLMB算法類似,AI-GLMB算法會存在目標過估,從而導致其OSPA出現尖峰,對目標消失反應速度較慢。
4 結 論
通常,目標具有較為穩定的AI,而雜波幅度無此特征,因此利用AI可弱化雜波影響,提高跟蹤性能。本文通過結合AI的雜波抑制能力及GLMB的抗干擾特性,提出了AI-GLMB濾波器,增強了雜波環境適應性。通過引入AI擴展目標狀態,建立幅度似然函數,推導了新的更新方程。針對非線性運動模型,給出了算法的SMC實現方法。仿真結果表明,在強雜波環境下,相比AI-PHD、AI-CBMeMBer及傳統的GLMB濾波器,本文算法跟蹤精度更高。
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
當代陜西(2019年15期)2019-09-02 01:52:00
學苑創造·A版(2018年11期)2018-02-01 06:29:20
中華手工(2017年2期)2017-06-06 23:00:31
讀者(2017年5期)2017-02-15 18:04:18
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2011年2期)2011-01-23 06:39:12
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
