
上市企業貸款違約風險的實證研究
——基于判別分析的Logistic回歸組合法與決策樹模型的分析
2018-12-11 09:23:04張中秋
時代金融 2018年32期
張中秋
(安徽大學,安徽 合肥 230000)
一、引言
一直以來,商業銀行的經營都潛存著違約風險的發生,違約風險率的高低不僅會直接決定銀行的盈利水平與穩健的經營能力,還會影響其對客戶和同業銀行的支付能力,造成整個金融系統的風險變化。李明[1]結合利率市場化條件下,討論了由中國銀行業經營所面臨的違約風險而帶來的一系列挑戰。隨著經濟的快速發展,企業貸款的需求量不斷增加,商業銀行的風險評估技術也需要不斷的創新與發展,這就為商業銀行的風險管理技術提供了嚴峻的考驗。因此,對上市企業的違約風險進行評估一直被金融界所關注。眾多國內外學者對企業的貸款違約風險的研究多采用判別分析或Logistic回歸模型進行實證研究,主要以王春峰[2]為代表的部分學者分別運用多元線性判別法,Logistic回歸法等對商業銀行面臨的違約風險進行評估,并做出了實證對比分析。陳靜[3]以27家ST和27家非ST上市公司1995-1997年報數據建立線性判別模型進行回判率的估計。李長山[4]運用Logistic回歸法構建企業財務風險預警模型,分析其判別效果達到了良好的財務風險預警機制。張初兵[5]等利用隨機模擬方法分別研究判別分析和Logistic回歸分類,并進行回判準確率的比較分析。
可以發現判別分析和Logistic回歸法為實際問題提供了有價值的思考,而這兩種方法的理論基礎并不完全是相同的。本文關于上市企業違約風險的測定,需要將中小企業劃分為兩組:違約組和非違約組,這是屬于二分類問題。判別分析與Logistic法在研究二分類問題上都能夠較好的給出分類算法以及較優的回判正確率,但都存在一些不可忽視的缺點。然而將兩種方法的優勢融合在一起,構造出一種組合模型對上市企業的貸款違約風險進行實證研究的介紹還較少出現。因此,本文采用兩者組合的方法可以降低單一方法所帶來的弊端而集中兩者的優勢大大降低了違約風險測定的誤判率,為商業銀行檢測企業的貸款違約風險提供了新思路。
接下來為了進一步找出影響企業違約的關鍵性因素,我們采用了決策樹模型幫助我們更好的理解整個分類過程。季桂樹,陳沛玲,宋航[6]基于各種決策樹分類算法的基本思想闡述了決策樹技術在分類過程中具有較高的分類精度、結構簡單、可理解性以及分類效率高等優點。徐曉萍[7]分別運用判別分析與決策樹模型對非上市中小企業違約風險進行分析,并將兩種方法進行對比。DaviS等利用決策樹算法成功的解決銀行信用卡違約問題,并將幾種常見的算法進行比較分析[8]。馮俊文[9]在文獻中提出了利用決策樹方法可以幫助我們對屬性進行排序,能夠選擇出最優屬性變量。因此,構造決策樹模型可以使我們更加清楚地了解整個分類過程,找出重要性指標,指導商業銀行對關鍵性指標進行更詳細的調查,提高預測準確度的同時提高了銀行風險管理的工作效率。
本文的主要思路可以分為以下四個部分:
第一部分:考慮選取經營現金流量/負債合計、總資產周轉率、總資產凈利潤率、每股留存收益和總資產增長率五項財務指標數據作為公司是否具有違約風險的衡量指標。
第二部分:計算出分別使用判別分析和Logistic回歸法對上市公司貸款違約風險進行分類的回判正確率,其中分類結果正確的觀測點占所有觀測點的比例為回判正確率。對于相同的樣本,兩種方法之間的回判正確率是存在差異的。
第三部分:計算基于判別分析的Logistic回歸組合法的回判準確率。將三種方法計算出的回判正確率進行對比分析并利用檢驗樣本組進行回判檢驗。
第四部分:利用決策樹算法將所有屬性的信息增益大小進行排序,幫助我們更好的理解整個分類過程,為商業銀行的風險管理提供有價值的指標參考。
二、樣本與指標的選擇
本文選用滬深兩市的100家上市企業作為研究對象,其中*ST股票是指連續三年虧損或公司經營存在重大的不確定性,資不抵債,隨時可能被摘牌或破產。財務危機是指企業喪失支付能力、無力支付到期債務或費用出現資不抵債的現象,包括商業破產,運營失敗和資不抵債[10]。由信貸風險理論可知:我們可以將*ST公司作為貸款風險違約組處理,具有一定的理論依據。通過國泰安數據庫采集到標有*ST的49家上市公司作為違約組樣本,選取的這些公司不僅被標有特殊處理的記號,而且長期存在財務危機和負盈利的經濟現象,因此作為違約組具有很好的代表性。根據滬深兩市于2017年報評選的前500強上市企業中選擇51家企業作為非違約組樣本,其中選擇的51家企業是起止2017年連續三年評選入圍前500強,財務狀況一直保持良好的穩定發展。確保了選擇的樣本可以準確地劃分為違約組和非違約組。然后,隨機選取樣本數據的70%作為估計樣本組,剩下的30%作為檢驗樣本組,即估計樣本組為70家公司,檢驗樣本組為30家公司,我們所選的上市企業涉及的行業涵蓋范圍較廣,包括服裝、家具、百貨、食品、建筑、電器等方方面面,具有一定的代表性。
本文采用上市企業的財務指標構建違約風險模型的變量,財務指標能力的高低直接反映了企業的經營能力和是否具有財務危機風險,從而幫助我們判斷貸款企業是否可能發生違約風險。根據上市企業的財務特征可以細分為償債能力、經營能力、盈利能力、盈利質量和可持續發展能力五個方向,本文初步從每個財務特征中篩選了2-3個財務比率,總計選取14個變量,但為了排除多重共線性的影響,最終從每個財務特征中篩選了一個具有代表性的財務比率,分別是經營現金流量/負債合計、總資產周轉率、總資產凈利潤率、每股留存收益和總資產增長率,分別記 X1、X2、X3、X4、X5,均可以從國泰安數據庫中進行數據采集。綜合體現了企業的財務能力,可以幫助我們較好地劃分企業是否具有發生違約風險的可能性。
首先,利用SPSS軟件對這五個變量之間做相關性分析的統計描述,結果如表1所示:
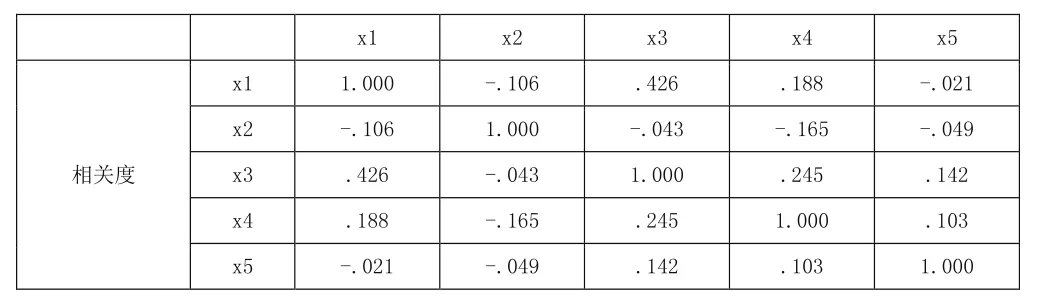
表1 各指標之間的相關性分析
由表1可知,各指標之間的相關性均遠小于0.5,不具有多重共線性,因此所選的五項財務指標具有良好的代表性,能夠較好地衡量公司是否具有貸款違約的風險。
三、利用判別分析與Logistic回歸組合法分析上市企業的違約風險
隨機選取的70個樣本量作為估計樣本組,分別有35家ST企業和35家非ST企業。因變量分為違約組和非違約組,分別記為Y=1和Y=0,而五個財務指標作為自變量分別記為X1,X2,X3,X4,X5。
(一)判別分析
1.距離判別法。由于各變量在各組之間存在異方差,不滿足線性判別分析。繼而采用判別分析中的距離判別法建立的判別函數,它是一種非線性函數,其優點對各類總體的分布沒有特殊要求,范圍較為寬松。
設兩個類別總體G1和G2,任取一個樣品,記為實測指標值X=(x1,x2,x3,x4,x5),分別計算X到G1、G2總體的距離,記為D=(X,G1)和D=(X,G2),按照距離最近準則判別歸類。
設 u(1)、u(2)、E1、E2分別為 G1和G2均值和協方差陣,本文利用馬氏距離定義距離,公式如下:
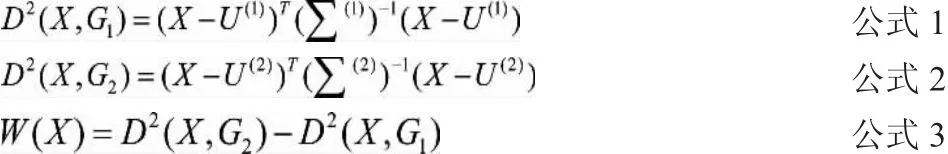
其中W(X)作為判別函數,它是二次函數。
按照距離最近準則,可知當W(X)>0時,樣本歸為總體G1,當W(X)<0時,樣本歸為總體G2。
2.實驗結果。利用R軟件對估計組數據做距離判別法,分類結果如表2所示:
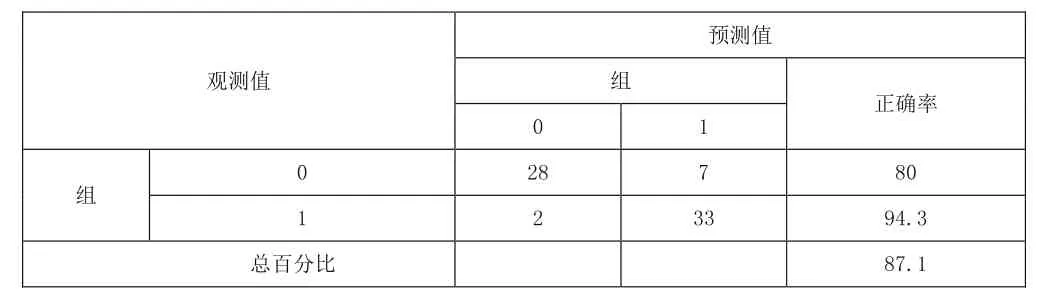
表2 馬氏距離的分類結果
觀察可知利用判別分析得出的結果中違約組(Y=1)存在2個誤判,正確率為94.3%,非違約組(Y=0)存在7個誤判,正確率為80%。綜合而言,判別分析的回判正確率達到87.1%。
(二)Logistic回歸模型
關于因變量是二分類的情況下,同方差、線性和正態性的假設都不能成立,OLS的估計是無效的,因此采用Logistic回歸的最大似然估計法可以解決這一問題,即將Y(1、0)轉化成logit,這樣Logistic回歸模型可以表示為:
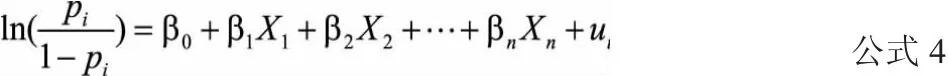
其中P是借款企業的違約風險率,β是待估系數,X是自變量,Ui是隨機誤差項。
采用SPSS軟件進行二項Logistic回歸分析,回歸分類的結果如表3所示:
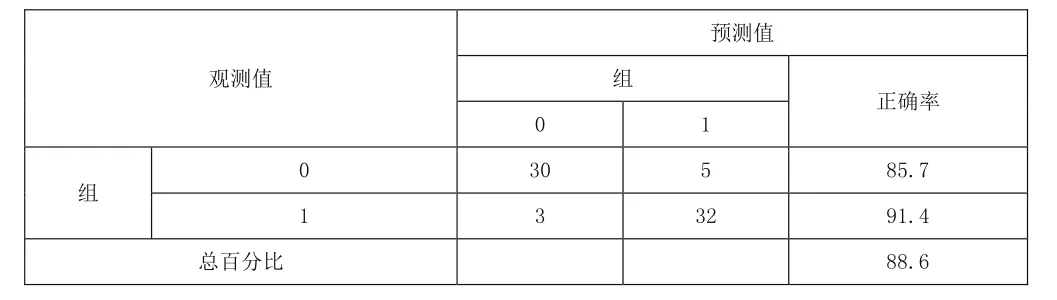
表3 Logistic回歸分類的結果
從表3可以發現,Logistic回歸分析的歸類結果相比于判別分析效果更佳,總體的回判正確率達到88.6%。
(三)判別分析與Logistic回歸組合法
關于商業銀行信貸風險模型的發展,存在較多的分類方法是Logistic回歸模型與判別分析,相比而言,Logistic回歸法更加穩健,但沒有理論證實該方法的回判正確率一定高于判別分析。為此,有學者提出了判別分析與Logistic回歸的組合模型,并通過大量實驗證實了組合模型的優越性,為本文利用組合模型嘗試對上市企業的違約風險進行測定提供了思路。尹劍、陸程敏、楊貴軍[11]在文獻中提出了判別分析與Logistic回歸組合法的理論框架,通過隨機模擬實驗證實了基于判別分析的Logistic回歸組合法相比于單個任何一種方法在二分類問題方面都有較高的回判準確率以及更高的穩健性。張闊,李桂華,李燕飛[12]通過建立我國城市消費者壽險購買行為的預測模型提出了將判別分析與Logistic回歸模型聯合應用,能夠取得更好的預測效果。
1.基本原理。判別分析與Logistic回歸組合法主要依托于提高兩種模型在進行歸類過程中的可信度,通過組合模型將兩種方法的優勢集中在一起。針對判別分析進行分類,W(X)的絕對值越大誤判的可能性會越小,而Logistic回歸則是要求條件概率值與0.5之間的差值絕對值越大可靠度越高,張初兵,高康,楊貴軍[5]指出判別函數值越大,條件概率與0.5之間的差值也就越大,反之亦然。因此可以利用判別分析的結果改進Logistic回歸的分類結果。基本思路分為三部分:第一部分,利用R軟件對樣本數據做距離判別分析,計算出判別函數值W(X)。第二部分,將W(X)從小到大進行排序,計算出函數值的15%分位數和85%分位數。第三部分,針對W(X)大于85%或小于15%分位數的樣本數據,判別函數的絕對值偏大,即兩者的分類結果相同且分類的正確率較高,因此不需要修正。定義函數為:

當W(X)的值大于85%或小于15%分位數時,不需要修正,因此d(x)記為0,同時還可以減少極端值對Logistic回歸的影響。對于在15%與85%分位數之間的樣本數據,可以將d(x)=W(x)作為新增解釋變量對樣本數據進行修正,然后建立Logistic回歸模型,最終得到判別分析與Logistic回歸組合模型。
2.實驗結果。利用SPSS對估計組樣本進行基于判別分析的Logistic回歸組合法的軟件操作,即對增設d(x)為解釋變量后,重新對70個樣本進行二元Logistic回歸分析,其分類匯總結果如表4所示:
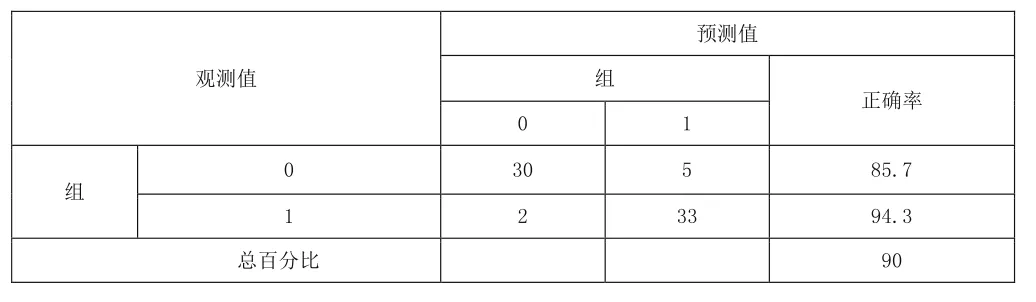
表4 組合法的分類結果
可以發現違約組(Y=1)存在2個誤判,正確率達到94.3%,非違約組(Y=0)存在5個誤判,正確率為85.7%,總體的回判正確率高達了90%。模型的預測精度分別提高了3.3%和1.6%,相比單一的判別分析或Logistic回歸法的預測結果都要好。同時,無論單從非違約組還是違約組中的正確率大小的角度分析,這種組合模型也優于單一任何一種方法的測定,由此可知通過組合法可以極大地提高關于二分類問題中的回判正確率。
3.檢驗樣本組的分類情況。為了進一步檢驗組合模型的適用性和有效性,接下來我們對剩余30%的樣本量作為檢驗樣本組,進行組合模型的回判檢驗。判斷統計結果如表5所示:
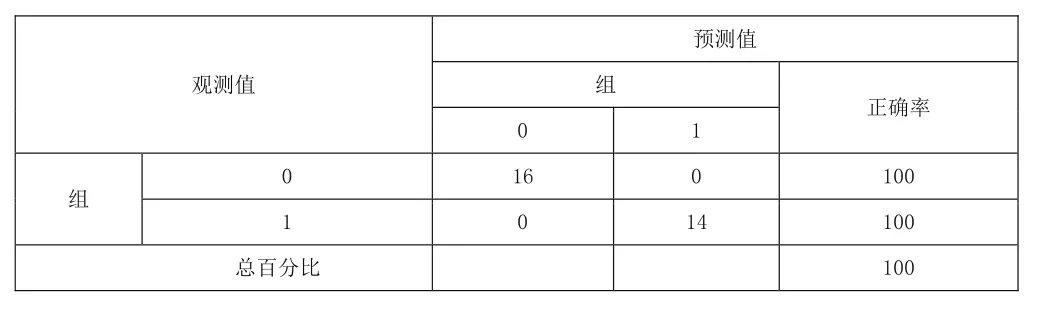
表5 違約判斷統計結果(組合模型)
表5可以發現,將判別分析與Logistic回歸組合法延伸對檢測樣本組進行回判檢驗,其中違約組(Y=1)和非違約組(Y=0)均沒有判錯,回判正確率為100%。也就是說明組合模型同樣達到了很好的預測結果,具有良好的延伸性與有效性。
四、決策樹模型
(一)決策樹算法
決策樹是一種比較常用的分類方法。其基本思想是對預測變量進行二元分離,從而構造一棵可用于預測新樣本單元所屬類別的樹。同時,決策樹還能夠按照屬性的最大信息增益對屬性進行排序進而生成決策樹,直觀地了解整個分類過程以及找出影響分類的關鍵性因素。
(二)實驗結果
同樣需要將100個樣本數據隨機劃分訓練集與測試集,其中訓練集樣本占70%,測試集樣本占30%。利用訓練樣本集產生初步規則生成決策樹,然后利用測試樣本集進行剪枝,通過R軟件得到最終的測試樣本集的判斷結果如表6所示和決策樹圖形如圖1所示:
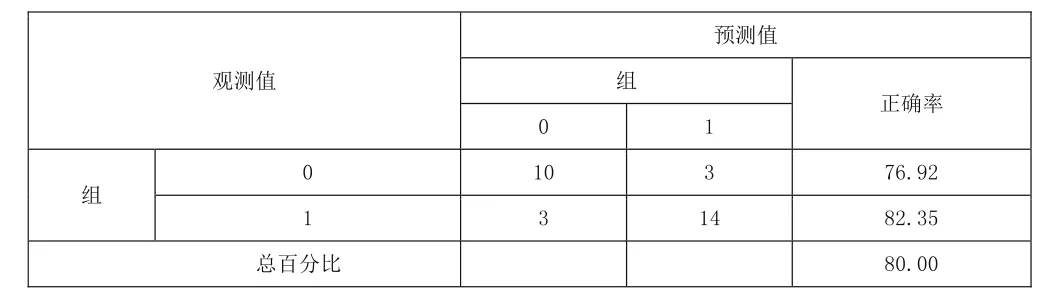
表6 違約判斷統計結果(決策樹模型)
表6可知:統計結果中違約組(Y=1)的判斷正確率為82.35%,非違約組(Y=0)的判斷正確率為76.92%,總的回判正確率為80%,判斷結果較優。雖然相比上述的組合模型的統計判斷結果而言,決策樹模型判斷的效果不太理想,可能由于決策樹算法在產生規則時采用局部的貪婪法,無法保障全局最優,其次分類器過于復雜,會產生一定的噪聲,從而發生過度擬合的問題等。但是它同時具有處理數據的速度快,能夠直接體現數據特點且易于理解與實現等優點,仍成為一種常見的分類方法。
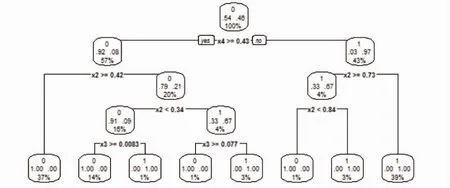
圖1 決策樹圖形
從圖1可以看出,根據測試樣本集對決策樹進行剪枝后降低了葉子節點,得到了關于測試樣本集進行預測的最佳決策樹模型。可以發現經過剪枝后決策樹中只存在三個關鍵性指標,分別是每股留存收益(X4)、總資產周轉率(X2)和總資產凈利潤率(X3)。說明這三個財務指標對上市企業的貸款違約風險的測定是至關重要的。其中每股留存收益的信息增益最大,可以判斷該指標相比其他指標具有最高區分度屬性,無論是針對違約組還是非違約組,每股留存收益的財務指標都可以很大程度的進行準確分類,是判斷企業是否可能違約的最關鍵性因素。該方法可以幫助商業銀行提高貸前審查效率,減少不必要資源的浪費,加強銀行對高風險企業的甄別能力。
五、結論
關于上市企業貸款違約的測定,對于商業銀行來說是一項復雜且重要的工作內容。本文的研究內容摒棄了常用的判別分析法或者Logistic回歸模型進行上市企業的違約風險測定,而嘗試采用一種基于判別分析的Logistic回歸組合法。關于判別分析與Logistic回歸組合模型測定上市企業貸款違約風險的方法可以極大地提高回判正確率,加強風險評估管理,為商業銀行違約風險的甄別提供一種新思路。
雖然相比而言,利用決策樹模型對上市企業的違約風險進行甄別,得到的回判正確率較低,但是對于大量數據的前提下,決策樹仍然具有有效構造模型的能力即可伸縮性較強,還可以使決策者更清晰明了的看清整個分類過程以及找出影響上市企業違約的關鍵性指標,提高商業銀行貸前審查效率。尤其針對經營所涉及的覆蓋范圍較大的上市企業,對其數據進行審核時會造成數據采集量大而復雜,審核較為困難時,決策樹可以很好的幫助商業銀行降低審查難度,提高工作效率的同時保證風險排查的準確性。
如果商業銀行進行風險審查時,同時考慮兼用基于判別分析的Logistic回歸組合法模型和決策樹模型,進行上市企業違約風險的測定,將保證較高的回判正確率的同時大大提高審查效率,降低審查難度,使優良的中小企業及時得到貸款,促進商業銀行的金融業發展,同時也可以為投資者、金融機構和市場監管層提供一種有效的財務預警分析工具。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
大眾投資指南(2020年10期)2020-07-24 08:03:40
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
消費導刊(2017年20期)2018-01-03 06:27:21
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
