大豆賴氨酸合成關鍵酶基因的克隆與定位分析
2019-01-09 07:00:22陳慶山邱紅梅蔣洪蔚李燦東唐敬仙
江蘇農業科學 2018年23期
于 妍, 姜 威, 陳慶山, 邱紅梅, 管 宇, 蔣洪蔚, 李燦東, 唐敬仙
(1.長春科技學院,吉林長春 130600; 2.東北農業大學農學院,黑龍江哈爾濱 150030; 3.吉林省農業科學院大豆研究所,吉林長春 130033;4.黑河出入境檢驗檢疫局綜合技術中心,黑龍江黑河 164300; 5.黑龍江省農業科學院佳木斯分院,黑龍江佳木斯 154007)
大豆(Glycinemax)是重要的油料作物、經濟作物,植物性蛋白質的重要來源之一便是大豆蛋白質,其營養價值較高。大豆中人體必需的氨基酸含量豐富,其中賴氨酸含量遠遠高于谷物。由于賴氨酸能夠促進人體充分吸收和利用其他營養物質,一旦缺乏將直接或間接影響機體的生長和發育,所以進一步提高大豆中的賴氨酸含量十分必要。在植物賴氨酸合成途徑中,二氫吡啶、二羧二氫吡啶、二羧酸先后在2,3-二氫吡啶二羧酸還原酶(DHDPR)、二氨基庚二酸異構酶(DAPE)、N-α-酰基-L,L-二氨基庚二酸脫酰酶(ADPD)的催化下生成賴氨酸[1]。表達序列標簽(expressed sequence tag,簡稱EST)已經成為人類克隆不同物種特異性表達基因以及尋找未知基因的重要手段[2-3]。截至目前,已有多項研究通過電子克隆手段獲得了許多人類功能基因[4-6]。但是由于目標物種序列信息有限,所以在植物基因克隆研究中,大部分試驗方法仍局限于原有的、常規的思路。但是,隨著植物EST數據庫的逐步完善,其信息量快速增加,借助生物信息學技術來電子克隆基因勢必成為基因克隆的一個方便快捷、有效的途徑。另外,在分子標記研究領域,目前的研究多是將標記定位在連鎖群上的,真正的基因定位鮮見報道。如果以基因自身的序列為依據,進而獲得連鎖群的定位,這樣可以實現基因更加準確精細的定位。
本研究利用電子克隆手段,獲得了大豆賴氨酸合成3個關鍵酶基因的全長cDNA序列,同時以已構建的大豆基因組遺傳圖和物理圖的整合圖譜為基礎,完成這些基因的定位,并通過cDNA和gDNA序列的比對,獲得所有基因的結構信息,從而為后續基因功能的研究及分子輔助育種打下良好基礎。
1 材料與方法
1.1 序列信息下載及生物軟件
本研究從美國國立生物技術信息中心(National Center for Biotechnology Information,簡稱NCBI)網站上分別下載了不同外源物種賴氨酸合成3個關鍵酶基因信息(表1),并用phytozome網站(http://www.phytozome.net/soybean.php)進行在線比對。從phytozome網站(http://soybase.org/SequenceIntro.php)下載獲得標記圖譜BARCSOYSSR Potential SSR Database。從NCBI的FTP網站(ftp://ftp.ncbi.nih.gov/blast/executables/release/2.2.16/)下載用于本地比對的blast2.2.16軟件包。利用DNAMan軟件進行EST片段比對,并篩選序列進行拼接。

表1 外源物種賴氨酸合成關鍵酶基因信息
1.2 試驗植物
先將大豆品種東農42的種子在自來水中浸泡過夜,再將吸脹后的種子種在花盆中,于光照培養箱中培養,待長出3出復葉后,將幼嫩的葉片取下用作試驗材料。
1.3 電子克隆
本研究依據不同物種間存在相同基因核苷酸序列同源性較高的特點,借助已構建的本地化大豆EST數據庫,將已獲得的不同物種的賴氨酸合成關鍵酶基因序列利用Blast軟件與其進行比對,從比對出的數條EST序列中選取多條同源性高,且能完全覆蓋整個基因cDNA片段的EST序列才可進行后續拼接工作。利用DNAMan 5.0軟件的Multiple sequence alignment功能將目的基因與其同源序列進行聯配分析,之后運用Sequence Assembly工具對所選EST序列進行進一步拼接組裝完成電子延伸,進而獲得全長基因序列。
1.4 引物設計
以拼接預測的基因序列為模版,利用DNAMan軟件設計引物,引物序列見表2。引物委托生工生物工程(上海)股份有限公司合成。

表2 賴氨酸合成關鍵酶基因引物信息
1.5 大豆葉片總RNA提取及第一鏈cDNA的合成
依據TRIzol說明書提供的方法進行大豆葉片總RNA的提取。參照M-MLV使用說明書反轉錄合成cDNA的第一鏈,直接用作模板用于PCR擴增。
1.6 基因的克隆及測序
以東農42大豆品種cDNA作為模板,利用已設計的大豆DAPD、DAPE和DHDP3個酶基因特異引物,借助PCR擴增全長基因片段。反應條件如下:94 ℃ 5 min;94 ℃ 35 s,60 ℃ 35 s,72 ℃ 2 min,28個循環;72 ℃ 7 min。待反應結束后,分別取10 μL PCR產物于10 g/L瓊脂糖凝膠中進行電泳檢測。回收目的片段并連接到pGEM T-easy載體上,轉化大腸桿菌(Escherichiacoli) DH5α感受態細胞,在氨芐青霉素(Amp)抗性X-gal/IPTG LB培養基平板上將白色克隆挑出,并送交生工生物工程(上海)股份有限公司進行測序。
1.7 基因的電子定位
將已獲得的3個大豆賴氨酸合成關鍵酶基因序列與本地數據庫進行比對,將獲得的序列與從phytozome網站下載的數據庫再一次進行比對分析,由此便可準確地將基因定位在遺傳圖譜上。結合Song等已構建的圖譜[7],進而確定這些基因定位的連鎖群以及距基因較近的兩側標記信息。
1.8 基因結構分析
根據比對分析結果,進一步確定基因的內含子與外顯子數量,從而獲得基因的精細結構。
2 結果與分析
2.1 大豆賴氨酸合成關鍵酶基因的電子克隆
2.1.1 基因的電子預測 本試驗將獲得的不同外源基因序列與已構建的大豆本地化EST數據庫進行比對,從比對結果中選取多條同源性高的序列,并進行拼接,進而獲得全長基因,從而預測出目的基因的全長序列。經比對、拼接,大豆賴氨酸合成3個關鍵酶基因的全長序列預測信息見表3。

表3 大豆賴氨酸合成關鍵酶基因的預測信息
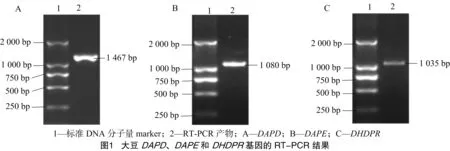
2.1.2 基因的RT-PCR鑒定與測序結果分析 以大豆品種東農42葉片總RNA反轉錄的cDNA為模板,通過RT-PCR擴增,獲得大豆DAPD、DAPE和DHDPR3個關鍵酶基因PCR產物,經10 g/L瓊脂糖凝膠電泳檢測,結果顯示泳道均出現單一條帶,DAPD、DAPE、DHDPR3個關鍵酶基因大小分別約為1 460、1 080、1 030 bp,全部與預測的基因長度相符(圖1)。將3個PCR產物分別與pGEM-T easy載體連接,進而獲得對應的重組質粒。最后將重組質粒進行PCR擴增,經電泳檢測,證實結果均與預測基因長度相符。
借助DNAMan軟件,將大豆賴氨酸合成DAPD、DAPE和DHDPR3個關鍵酶基因重組質粒的測序結果與之前的預測結果進行比對分析,結果顯示,在核苷酸水平上,所獲得的3個基因cDNA序列與預測序列的同源性分別為99.66%、99.17%、95.94%。利用EBI→InterProScan分別對DAPD、DAPE和DHDPR3個酶基因編碼的蛋白保守結構域進行預測。由表4可以看出,DAPD、DAPE、DHDPR3個關鍵酶基因含有的保守結構域分別具有2,6-二氨基庚二酸脫羧酶、二氨基庚二酸異構酶和2,3-二氫吡啶二羧酸還原酶功能。通過以上分析,進一步驗證了通過電子克隆獲得的這3個全長基因序列是正確的。
2.2 大豆賴氨酸合成關鍵酶基因的電子定位與結構分析
2.2.1 基因的物理圖定位 借助大豆基因組數據庫,將已獲得的基因序列片段與之進行比對,進而完成物理圖定位分析。如果與基因組進行比對時出現多個片段同時匹配的情況,是由于該基因具有內含子。表5中顯示了基因以及與基因組匹

表4 大豆賴氨酸合成關鍵酶基因編碼蛋白保守結構域信息

表5 大豆賴氨酸合成關鍵酶基因的物理圖定位
配區段的信息,此外還可以看出,E值均趨近于0,平均匹配率均在99%以上。這些數據足以說明,這些基因與基因組序列的匹配是真實且可信的。
2.2.2 基因的遺傳圖定位 根據賴氨酸合成3個關鍵酶基因與基因組匹配區段,同時參考標記圖譜BARCSOYSSR Potential SSR Database,DAPD、DAPE和DHDPR3個基因分別定位在L、N、J 3個連鎖群上,獲得了基因的兩側標記以及定位區間。由表6、圖2可以看出,DAPD基因被定位在L連鎖群Super40的314 760~319 421之間,且BARC-014655-01607-BARC-028787-06014是分別位于此區間兩側最近的標記,距離是1.1 cM;DAPE基因被定位在N連鎖群Super62的2 825 711~2 829 438之間,且BARC-024329-04849-BARC-028205-05792是分別位于此區間兩側最近的標記,距離是0.6 cM;DHDPR基因被定位在J連鎖群Super154的1 521 652~1 524 809之間,BARC-022453-04332-BARC-014459-01381是分別位于此區間兩側最近的標記,且定位于連鎖群的同一位置,定位距離是3個基因中最近的。

表6 大豆賴氨酸合成關鍵酶基因遺傳圖基因定位
2.2.3 基因結構分析 通過對大豆賴氨酸合成3個關鍵酶基因進行cDNA和gDNA序列的比對,進一步確定各個基因長度以及外顯子、內含子的數量。表7結果顯示,DAPD、DAPE、DHDPR3個酶基因cDNA長度分別為1 467、1 080、1 035 bp;gDNA的長度分別為4 662、3 728、3 158 bp;外顯子數量分別為8、9、8個;內含子的數量分別為7、8、7個。

表7 賴氨酸合成關鍵酶基因結構比對信息
3 討論與結論
3.1 大豆賴氨酸合成關鍵酶基因的電子克隆
目前,電子克隆方法已經被廣泛應用于很多領域,例如在人[8]、甘藍[9]和牛[10]的研究中均有報道。但大部分研究僅局限于利用外源物種核苷酸或氨基酸序列與GenBank網站上提供的EST數據庫進行比對,且由于EST數據庫中的信息包含多個物種,所以造成信息量過大,因而比對起來必然存在以下問題:(1)時效性差;(2)會將許多不需要的物種信息同時比對出來,所以不僅須要比對多次,另外還須對結果進行細致篩選,為序列拼接帶來不必要的麻煩。本研究在成功構建大豆EST數據庫的基礎上進行本地比對,這樣針對性更強,結果更準確。由此可見,以本地化EST數據庫為基礎進行基因電子克隆,既準確又快捷。
3.2 大豆賴氨酸合成關鍵酶基因的電子定位
目前,針對大豆脂肪酸含量[11]、種子油分和蛋白[12]、大豆花葉病毒抗性[13]及胞囊線蟲抗性[14]等性狀的基因定位均有報道,但關于基因方面的研究并不多見。本研究借助已有的大豆基因信息,構建了本地化EST數據庫。同時利用生物學軟件,完成了基因準確、快速的定位。而傳統的分子標記,需要一定的群體以及大量人力、物力,既耗時又費力。基因電子定位是借助生物信息學相關軟件并建立在測序基礎之上的另一種用于基因定位的手段,其獲得的基因兩側標記與基因位點之間的物理距離非常近,可為今后基于基因分子標記的開發奠定良好基礎,從而真正完成基因準確精細的定位。
由本試驗結果還可以看出,通過基因的電子定位,不僅能夠更加快速、準確地相互找到對應標記,同時還能獲得相鄰序列的信息,這樣就可以挖掘更多未知的功能性基因,進而完成QTL到QTG更深入的轉換,同時也很好地將挖掘基因與遺傳作圖二者密切地聯系在一起。除此之外,電子定位還可將基因cDNA序列和gDNA序列進行比對,同時對精細的基因結構,即內含子與外顯子信息進行分析,為后續進一步研究基因提供了必要條件。目前基于基因序列的研究大部分仍然局限于cDNA水平, 卻忽視了基于gDNA水平上基因結構的分析,本研究對這方面內容進行了有效的補充。

猜你喜歡
今日農業(2022年16期)2022-11-09 23:18:44
今日農業(2021年20期)2021-11-26 01:23:56
今日農業(2021年14期)2021-10-14 08:35:34
中學生數理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
NBA特刊(2014年7期)2014-04-29 00:44:03
中國商人(2013年1期)2013-12-04 08:52:52
