基于深度學習的光場加密圖像恢復技術
2019-02-21 09:32:10朱震豪韓思敏張薇
光學儀器 2019年4期
關鍵詞:深度學習
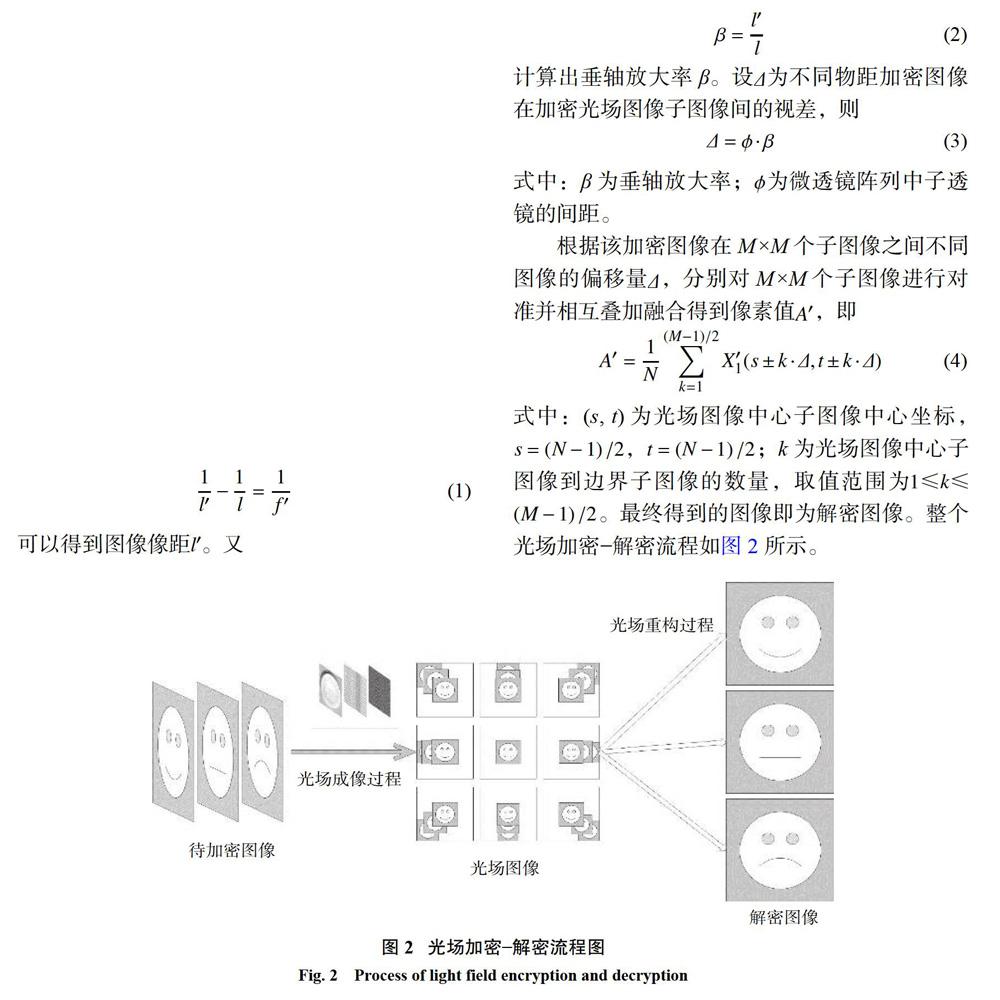
朱震豪 韓思敏 張薇
摘要:光場技術可以將圖像加密從二維提升到三維,加強加密的安全性。采用重聚焦算法實現圖像解密時會引入圖像間的干擾。以深度學習技術為框架,分析圖像干擾的規律性,構造模擬光場數據集,創建了一個7層的全卷積神經網絡,以模擬光場數據集作為輸入,原圖作為標簽,訓練一個全卷積神經網絡,將真實光場解密圖像輸入得到結果。實驗結果表明,利用全卷積神經網絡可以有效改善光場解密圖像的干擾問題,改善解密后的圖像質量。
關鍵詞:光場技術;深度學習;圖像加密;全卷積神經網絡;圖像處理
中圖分類號:TP183 文獻標志碼:A
引言
現代社會每時每刻都有大量的信息被傳輸、儲存,因此,信息安全也越來越被人們所關注。為了加強傳統二維圖像加密的安全陛,提出了基于光場成像技術的多幅圖像加密技術。相比于傳統加密技術,光場加密利用圖像的空間信息,將信息的維度提高到了三維,加強了安全性。三維信息加密可以同時加密多幅圖像,提高了效率。此外,光場加密還具有信息冗余度高,抗攻擊能力強的特點。
目前,光場解密的圖像在最后解密的過程中仍然會殘留部分多余的信息,影響解密圖像的質量。人工去除這些缺陷,將會消耗大量的人力物力。由于這些缺陷都有一定的規律性,且修復邏輯簡單,本文提出利用深度學習方法,讓人工神經網絡學習如何分辨去除光場解密圖像中的缺陷,以達到自動修復圖像的目的。
深度學習的概念源于人工神經網絡的研究,旨在研究如何自動地從數據中提取分析目標問題的特征,是新興的機器學習研究領域。全卷積神經網絡就是一種深度學習結構,其核心思想是通過數據驅動的方式,采用一系列的非線性變換,從原始數據中提取多層次、多角度低層特征,通過組合低層特征形成更高層次的特征或類別,從而通過這些特征完成給定任務。得益于近年來計算機性能的巨大提升,深度學習能處理的數據量得到極大的提升,從而使獲得的特征具有更強的泛化能力和表達能力,這恰好滿足高效圖像處理的需求。為滿足圖像處理問題的各類需求,以卷積神經網絡為代表的深度學習理論近年來不斷取得突破。
1光場加密原理
1.1加密過程
傳統相機的成像只是將光線的強度在探測器像元上進行累加,只考慮了物體在像平面上的空間分布,丟棄了光線傳播方向的信息,而光場則是用一個七維全光函數來完整地表達光線。從測量的角度來講,光場成像能同時探測到七維光場經離散化和縮減維度后的近似,即四維光場,從而可以實現對光線本身的某些操縱。
利用光場成像的原理,提出一種新的多圖像加密方法——光場圖像加密法。該方法可以對多幅圖像同時進行加密,且多圖像間可以起到相互干擾和保護的作用,從而有效提高多圖像加密的效率,并提高密文的多樣性、復雜性及抗攻擊能力。
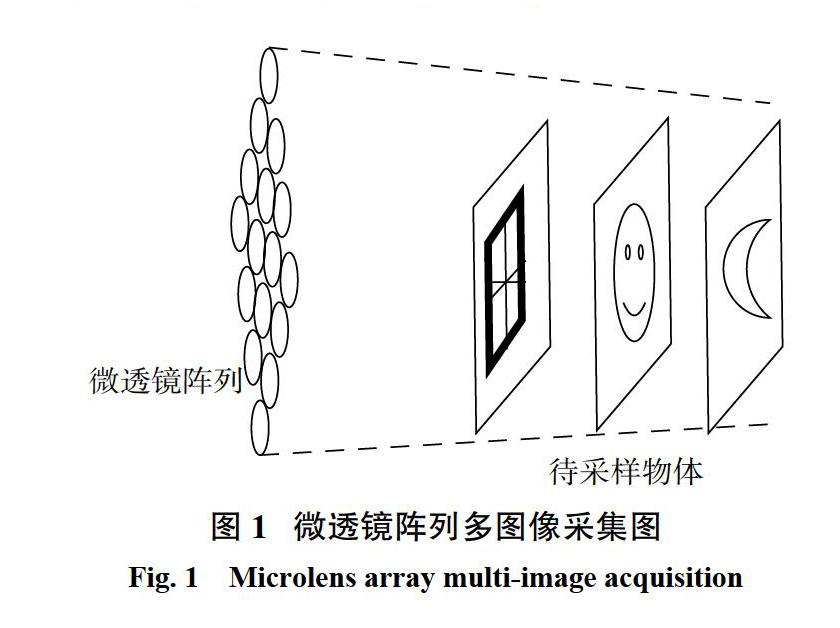
根據光場成像的原理,如圖1所示,多個微透鏡分布于一個平面上組成微透鏡陣列,對多個目標物進行光場采集。不同位置的微透鏡采樣之間相似并且相互偏移,這是由于每個微透鏡所對應的物方視場范圍不重合造成的。
如果圖中的光場信息能夠通過單個微透鏡來獲得,那么微透鏡的孔徑大小應等效于光場在方向維度上的區間范圍,由此等效出的孔徑就為合成孔徑。利用成像積分公式,將光場沿不同角度進行投影積分,能夠實現目標場景的數字重聚焦。
基于光場成像的原理,將被加密圖像視為不同景深下的物,由其可以構建出1幅光場圖像來實現加密。因此,在光場加密過程中,首先,要構建出光場成像系統,然后,分別將不同的被加密圖像放置在不同的物方距離處,按照光場成像的原理,對多幅圖像同時處理,生成光場加密圖像。在生成光場圖像過程中的各項參數,包括微透鏡焦距、孔徑、個數、宏像素數以及物距等,都可作為密鑰。
1.2解密過程
每個微透鏡所成的圖像像素為N×N,完整的光場圖像由M×M個微透鏡所成的像排列而成。當物方是由3幅圖像相隔一定距離疊加,光場圖像中物方信息被光場成像所拆散,完成對物方信息加密的過程。重聚焦算法可以將被光場拆散的圖像重新拼接起來,獲得被光場成像技術加密過的信息,因此,將其用于解密過程。
由于加密圖像所發出的光線在各個方向應具有近似相同的輻射強度,空間中的光場分布在方向維度具有強烈的相關眭,因此,當加密圖像在透鏡陣列中成像時,在每個子圖像中應具有相似的灰度值。在光場圖像中,由于透鏡之間存在一定間隔,位置采樣下互相位置會存在偏移。設l為加密圖像在光學系統中的物距,l'為加密圖像經過微透鏡陣列所成的像距,f'為微透鏡焦距,通過高斯公式
基于光場解密的原理,解密圖像由各個光場微透鏡圖像根據計算的偏移量疊加而來。因此,在光場圖像解密過程中,多余的圖像信息也被保留了下來,使得解密后的圖像存在多余圖像殘留的問題。
近年來,得益于計算性能的發展,深度學習由于其可塑性強,得到了廣泛的應用,特別是在圖像處理領域。深度學習可以利用計算機學習識別和去除符合某些特征的圖像缺陷,目前在圖像識別和邊緣檢測領域都有了廣泛的應用,將其應用于光場解密圖像的恢復中,具有自動化、效率高的優點。
2深度學習應用于光場解密圖像的恢復
為獲得更好的光場解密圖像,去除圖像間的干擾模糊效應,采用深度學習的方法對解密后的圖像進行處理。該方法由三部分組成:第一部分為全卷積網絡的模型設計,主要工作是根據光場解密圖像缺陷的特點,設計相符合的模型;第二部分為設計和創建合理的數據集,主要目的是提高模型的泛化能力;第三部分為訓練和測試模型,主要用來檢驗模型的效果。
2.1全卷積神經網絡與模型設計
通常的卷積神經網絡在圖片輸入了幾組卷積層之后將結果輸入到全連接層,最后輸出分類結果。以AlexNet為代表的經典CNN結構適合于圖像級的分類和回歸任務,因為它們最后都期望得到整個輸入圖像的一個數值描述(概率),比如AlexNet的ImageNet模型輸出一個1000維的向量,向量的每一維的數值表示了輸入圖像屬于每一類的概率。
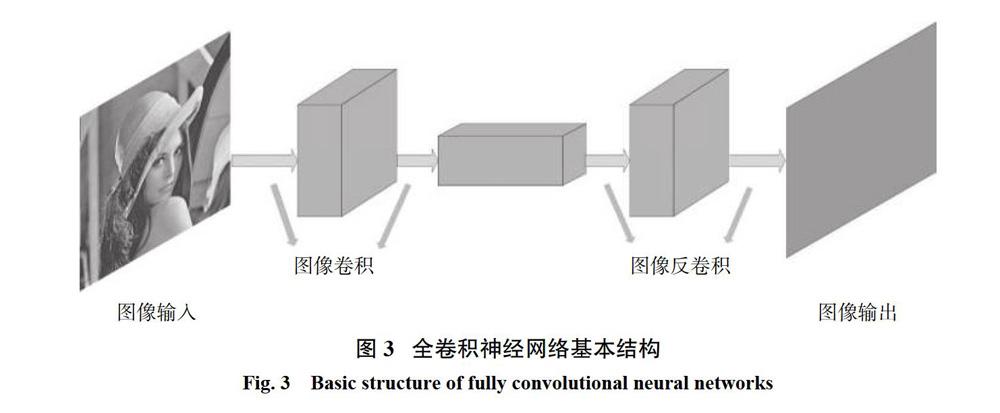
全卷積網絡(fully convolutional networks,FCN)將通常CNN中的全連接層替換為反卷積層,對神經網絡的卷積操作的輸出進行反卷積操作,這一個關鍵的改變能使得FCN輸出一個與輸入相同尺寸的圖片而不僅僅是一個圖像分類的概率。圖3表示一個全卷積神經網絡的結構。
卷積神經網絡工作過程分前向傳播和反向傳播兩個步驟。前向傳播對輸入的圖像數據進行多層卷積運算,利用設計的損失函數對卷積結果進行計算獲得損失值;基于損失值沿卷積方向進行反向傳播,主要為更新卷積核權值的過程。
根據光場解密圖像的特點,設計的神經網絡共由7個卷積層和7個池化層構成。第1層卷積有64個3x3的卷積核,第2層卷積有64個3x3的卷積核,第3層卷積有32個3x3的卷積核,第4層卷積有32個3x3的卷積核,第5層卷積有64個3x3的卷積核,第6層卷積有64個3x3的卷積核,第7層卷積有1個3x3的卷積核,其中第4層、第5層、第6層為反卷積操作。第1到6層的卷積或反卷積層后都進行步長為2,窗口大小為2x2的池化操作,第7層進行步長為1,窗口大小為1×1的池化操作。每層卷積操作后都利用ReLU函數進行激活,以加快模型收斂。
如圖4所示,輸入為光場解密的結果,經過7層的卷積,再減去原圖,最小化卷積結果和原圖差值,通過反向傳播算法調整整個神經網絡的權值,最后將待處理圖片輸入訓練好的模型,就能產生消除光場干擾的圖片。
2.2實驗數據集
本文采取模擬光場加密圖像的的方法,以現有的開源數據集為基礎,對數據集進行模擬光場加密的處理,訓練深度學習模型,再將真實光場加密圖像通過模型驗證其可行性。
如圖5所示,CIFAR-10是一個開源數據集,它由10個類別60 000幅圖像組成,總共有50 000幅訓練圖像和10 000幅測試圖像,大小和圖像內容與光場加密的結果比較符合。
本文所采用的光場成像微透鏡尺寸為15~15,所以在最后的解密結果中,每1幅解密圖像都是由225幅圖像疊加而成。為了模擬光場成像,所以在數據集中每1幅圖片上都將疊加1個圖層,這個圖層是通過淡化疊加行列各1 5幅圖像得到的。將疊加圖像中心的25%替換成原圖,以疊加圖像作為輸入,原圖中心25%作為標簽,完成了數據集的制作。
2.3實驗結果
構建的光場成像系統參數為:微透鏡陣列個數為15×15,像素為200×200,3幅圖片分別放置在15mm、35mm和60 mm處。生成的光場加強圖像如圖6所示。
在實驗階段,將數據以每組256幅圖分為234組輸入FCN,重復迭代次數為25次。訓練開始后,原圖與輸出圖像的損失值Loss初始值為0.250 6,前6輪迭代快速下降,隨后下降速度放緩,從19次之后逐漸趨于0.015,下降趨勢如圖7所示。
完成訓練之后,將光場解密圖像輸入全卷積神經網絡模型。圖7顯示了模型輸出結果。
圖8對原圖、光場解密圖像和FcN改善圖像進行了簡要對比。光場解密圖像中的干擾像素來自圖像的多次不對齊的重疊,產生類似模糊的像,干擾了光場解密的結果。全卷積神經網絡對原有的光場解密圖像改善效果顯著。
3結論
基于光場技術的多幅圖像加密技術利用數字重聚焦算法,可以對空間中多幅圖像進行重構,達到加密一解密圖像的目的。由于重聚焦技術的局限,解密的結果殘留了部分圖像間模糊干擾。本文提出利用全卷積神經網絡改善光場解密圖像的算法,通過對開源數據集CIFAR-10進行處理,模擬光場解密的圖像效果,以此為基礎去訓練一個全卷積神經網絡模型。將光場解密圖像輸入訓練好的模型后能明顯消除大部分的圖像干擾。實驗證明,采用全卷積神經網絡來處理光場解密結果是有效的,本文可以為光場加密技術的改進提供參考。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
