Silicon-Crystal應用的神威OpenACC移植與數據流驅動任務圖并行化
2019-05-22 02:59:48
山東科技大學學報(自然科學版) 2019年3期
(山東科技大學 計算機科學與工程學院,山東 青島 266590)
分子動力學(molecular dynamics,MD)模擬是指使用數值方法,利用計算機模擬原子核和電子所構成的多體系統的運動過程,已被廣泛應用于物理、化學、生物、材料、醫學等多個領域,用來研究系統的結構和性質[1]。在材料領域虛擬過程工程中,Silicon-Crystal應用是研究硅晶體熱傳導性的MD模擬應用,有限的計算能力一直是制約模擬效率的瓶頸[2]。近年來,高性能計算技術的發展為材料領域的虛擬過程工程提供了可能[3]。
“神威·太湖之光”是世界上首臺運行速度超過十億億次的超級計算機,也是我國第一臺全部采用國產處理器SW26010構建的超級計算機[4]。清華大學付昊桓等[5]在“神威·太湖之光”上,利用OpenACC移植大氣模型CAM應用,單核組內實現2倍加速,但未進行移植后優化;上海交通大學王一超等[6]利用OpenACC移植并優化了磁約束聚變領域GTC-P應用,單核組內實現2.5倍加速,但缺少對訪存密集型應用帶寬訪存優化;中國科學院計算應用研究中心張帥等[7]在GPU平臺上對MD模擬進行訪存優化,但未提供模擬中跨時間迭代問題的解決方法。CPU、GPU架構與SW26010架構存在著差異。SW26010采用片上計算陣列群和分布式共享存儲相結合的異構眾核體系架構,使得MD模擬應用的移植具有更大的靈活性,但也使得移植難度加大,目前對MD模擬移植到“神威·太湖之光”超級計算機上的相關研究尚未見到。
本文設計了一種SW26010主從計算并行化方案,實現對Silicon-Crystal應用的神威OpenACC移植與優化;以數據流驅動的任務圖并行化方法解決任務間的峰值訪存、跨時間迭代問題,針對該應用訪存密集型特點進行帶寬訪存優化。
1 背景介紹
1.1 SW26010處理器架構及神威OpenACC執行模型
“神威·太湖之光”是中國自主研發的超級計算機,峰值性能為125.4 PFlops,實測峰值約為93 PFlops。采用新一代的眾核異構處理器SW26010(架構如圖1)。神威OpenACC程序的執行模型是在主核指導下,主從核協同工作,其加速執行模型如圖2所示。
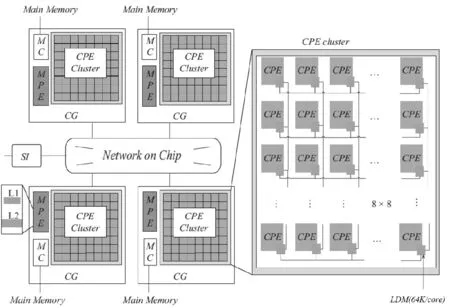
圖1 “SW26010”異構眾核架構Fig.1 Heterogeneous multi-core processor architecture of “SW26010”
SW26010異構眾核架構中,各核組之間采用片上網絡互連,每個核組包含1個主核(management processing element MPE)、1個從核簇(8×8=64個,computing processing element,CPE)、1個協議處理單元和1個內存控制器。核組內采用共享存儲架構,內存與主、從核之間可通過內存控制器傳輸數據,處理器可通過系統接口與外部設備相連[8]。申威眾核處理器旨在用少量具備指令級并行能力的管理核心集成眾多面向計算開發的精簡運算核心高效處理線程級并行,從而大幅提高芯片性能[9]。
程序首先在MPE上啟動,以一個主線程串行執行,計算密集區域則在主線程的控制下作為加速任務被加載到加速設備CPE上執行[10]。任務的執行過程包括:在CPE設備內存上分配所需的數據空間;加載任務代碼至CPE;任務將所需的數據從MPE傳輸至CPE內存;等待數據傳輸完成;CPE進行計算并將計算結果傳送回主存;釋放設備上的數據空間等步驟。
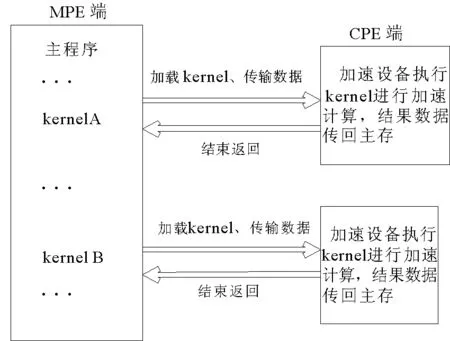
圖2 神威OpenACC執行模型Fig.2 Execution model of the Sunway OpenACC
MPE加載一系列任務到加速設備上同時執行,但這種fork-join模式在訪存帶寬有限的SW26010處理器上易產生峰值訪存問題,使CPE之間相互爭搶帶寬,從而影響計算性能。
1.2 AceMesh編程框架
AceMesh編程框架是面向網格應用[11-12]、以數據為中心,應用于多核、眾核平臺上的數據流驅動并行編程框架。AceMesh并行編程框架通過底層的任務調度系統[13](運行時庫)對網格應用進行任務圖并行,其核心設計思想來源于圖論中的有向無環圖(directed acyclic graph,DAG)。
任務調度系統采用探測-執行(inspector-executor)兩階段執行的并行模式[14],該模式對并行區域進行代碼級調度。探測階段將代碼區域的控制流和數據流信息提交給運行時系統,由運行時系統根據任務間依賴關系建立任務依賴圖。執行階段以構建的任務圖為基礎,依據資源配置及利用率搭配不同的任務調度策略和算法,動態的調度并行任務。

圖3 AceMesh編程框架任務調度系統Fig.3 Task scheduling system ofAceMesh programming framework
AceMesh編程框架任務調度系統結構圖如圖3所示,該調度系統包括四層:
1) 用戶接口層,收集任務粒度[15]的描述、數據流信息、任務構造等信息;
2) 任務構建層,根據上層用戶提供的信息,在系統內部產生任務、建立依賴和進行任務圖管理;
3) 任務調度層,通過靜態調度和動靜結合調度兩種方式提供任務調度支持。靜態調度采用輪詢法按權值將任務分配至線程;動靜結合調度指靜態調度策略與任務竊取調度算法[13,16]相結合,提高任務數據重用率和線程間負載均衡性;
4) 隊列調度層,利用線程庫對線程私有并發任務調度隊列進行任務級調度。
2 Silicon-Crystal應用分析及移植方案設計
2.1 應用算法和模擬過程數據特征分析
MD模擬中,通過差分求解牛頓運動方程可得到系統中原子的一系列位形。由于模擬過程中力的計算工作量很大,常用的龍格-庫塔法已不再適用,Silicon-Crystal應用中的TP(Tersoff Potent)模塊利用leap-frog算法[17]模擬原子在Tersoff勢能作用下的運動軌跡,在所有的線性微分方程的求解器中都有應用。
基于有限差分法leap-frog算法,求解線性常微分方程公式如下:
(1)
(2)
其中,r、V、m、F分別為原子的位置矢量、速度、質量、所受勢能力,Δt為計算時間步長。
2.2 TP模塊并行方案
加速線程庫(athread庫)是針對主從加速編程模型所設計的程序加速庫,旨在使用戶能夠方便、快捷地使用核組內的線程進行控制和調度,從而更好地發揮組內多計算核的性能。本研究使用加速線程庫將TP模塊移植到從核的運算模式如圖4所示。

圖4 TP模塊并行方案設計Fig.4 Parallel scheme design of TP module
TP模塊的移植主要分為:
1) 計算網絡劃分。MPE端沿三維空間x、y和z三個方向將數據區域按比例分成若干矩形體,每一矩形體計算視為一個任務。這樣的劃分方式有兩個好處:其一,CPE端得到的數據在空間上是連續的,數據塊訪問開銷比較小;其二,分塊內中心原子占比相對較高,減少分塊間的原子通信量,提升計算效率。
2) 初始化環境。CPE端對劃分后任務內的原子信息進行初始化,初始化信息包括原子的位置矢量、加速度、速度等。
3) 計算參數初始化。初始化MPE端對Tersoff勢能下的離散計算參數。
4) 力場計算。以任務為基本單位將原子信息加載至CPE端進行加速計算,首先進行MPE端至CPE端的數據拷貝,其次利用CPE端的計算陣列群加速核心計算,最后將計算后的各個任務原子信息由CPE端傳回MPE端。
5) 同步力場數據。MPE端按照鄰居關系索引表進行任務間數據更新操作,保證數據全局一致性。
6) 更新殘量和輸出文件信息。CPE端進行每個時間步計算后的殘量更新,MPE端將計算范數值輸出至文件系統。
3 神威OpenACC從核移植
神威OpenACC并行編程模型,用編譯指示的方式把應用中可并行化的計算循環移植到申威處理器從核以加速計算。具體到Silicon-Crystal應用的從核移植,主要分為以下三個步驟:
1) 循環并行化。Silicon-Crystal應用以任務分片存儲的數據為基本單位進行模擬計算,在分塊級的for循環上添加相應的指導語句#pragma acc parallel loop,將計算部署在64個從核上并行執行。
需要注意的是,gang、worker、vecotr是OpenACC2.0中的3層循環設計,由于神威眾核架構在物理上并沒有分層需求,所以神威OpenACC的實現是把gang設置成64,worker設為1。
2) 基于計算數據優先的數據管理。神威眾核架構中存在訪存帶寬較小的問題,故從核移植并行化過程最為關鍵的是將加速計算需要的數據提前拷貝到訪問延遲低的SPM(scratch pad memory)。本研究采用計算數據優先傳輸策略即將所有計算涉及的數據優先傳至SPM。
計算數據優先傳輸過程如下:
i) 按循環索引劃分傳輸。若數組的索引變量與循環索引變量緊耦合時,神威OpenACC編譯器將數組劃分為64份,然后利用DMA的方式將劃分后的數據集中傳輸至各從核SPM中,并將任務內的鄰居關系表、打包后的計算參數順序傳遞給從核。具體使用copy/copyin/cpoyout等指導語句完成(如圖5)。

①#pragma acc parallel loop
圖5 數據管理過程的函數指導語言實現
Fig.5 Implementation of functional instruction language based on data management
ii) 變量局存私有化。對于并行循環索引變量等線程私有變量,既可使用private子句也可使用local子句將變量私有化,考慮到private是線程私有化變量,變量值仍在主存中,而local是線程私有化的局存變量,存儲在SPM中,數據訪問更加高效,故采用local子句進行變量的私有化。
iii) 離散計算參數打包傳輸。Silicon-Crystal應用存在多個離散標量的模擬參數需要傳送至從核,若一一傳輸需要頻繁的使用DMA方式,會大大增加訪存開銷。在此情況下,本文利用pack/packin/packout等神威定制的指導語句將離散數據打包后一次傳遞,以更充分有效地利用有限的訪存帶寬。
綜上,得到 Silion-Crystal應用移植中的數據管理過程的函數指導語言實現如圖5。
3) 加速代碼區約束處理。SWACC編譯器進行OpenACC并行化過程中,對并行區的代碼有一定的要求。如在加速區代碼中存在函數調用時,需在函數定義處添加routine子句指示,否則生成從核代碼將找不到函數的位置。但目前routine子句只適用Fortran程序,C代碼暫不支持。Silicon-Crystal應用程序是C代碼程序,無法利用routine子句修飾從核函數。本研究通過利用宏定義實現力場計算的內聯函數,來解決移植過程中加速區函數返回值異常的問題。

圖6 神威OpenACC移植性能數據Fig.6 Performance data of the Sunway OpenACC transplant
將運行在1個主核上的Silicon-Crystal作為測試基準,分別與循環并行化、基于計算數據優先的訪存和離散計算參數打包傳輸3個方面在單核組上進行性能測試(圖6)。測試問題規模:回環中存在131 072個粒子,迭代計算次數為1 000次。
可以看出,對于訪存密集型的應用,僅進行循環并行化將計算過程移至CPE端,性能反而會降低;按照計算數據優先方式通過DMA方式放入從核SPM中,性能開始超越主核;通過pack子句對離散計算參數打包后再傳輸,性能進一步提升,整體應用較主核版實現了2.26倍的加速。
4 數據流驅動的任務圖并行化
AceMesh任務調度系統的設計思想來源于數據結構中的有向無環圖,即任務依賴圖。任務依賴圖在圖論中是指:如果一個有向圖無法從某個頂點出發經過若干條邊回到該點,則這個圖是一個任務依賴圖。任務依賴圖中的頂點代表任務,圖中的邊代表任務間的依賴關系。根據任務依賴圖的特點,將并行計算中的大規模計算問題劃分為N(N≥1)個任務,并根據各個任務的依賴關系建立任務依賴圖,圖中所有沒有后繼的頂點都執行完后,任務依賴圖的執行完成。
在神威眾核處理器上任務圖并行化過程分為任務構圖期和任務執行期。構圖期是任務構建的探測過程,旨在根據注冊的數據地址去建立任務間的依賴關系,在不改變串行序結果的情況下以數據流調整執行序列;執行期是指按照構圖期間構建的DAG圖,搭配任務調度系統的不同調度策略執行任務的過程。故任務圖并行化總時間等于構圖時間(graph time)加執行時間(execution time)。
Silicon-Crystal應用在太湖之光上使用任務圖并行化主要分為以下3個步驟:
1)主核構建任務依賴圖。根據不同并行區內劃分的任務按照對內部訪問的數據依賴關系進行地址注冊,構建出任務執行序DAG圖。
圖7為Silicon-Crystal應用2線程4任務依賴圖。其中,每個橢圓代表包裝后的一個任務,橢圓中第一個數字為并行區編號,第二個數字為任務編號;箭頭代表任務間的數據訪問先后的依賴關系;陰影、非陰影圓圈代表執行時不同的線程;實線邊是任務垂直后繼依賴邊,虛線邊是普通后繼依賴邊。在任務執行期間,采用的調度策略使垂直后繼任務優先于普通后繼任務執行,旨在使任務間的數據重用得到最大化。此外,截斷并行區間任務執行的依賴關系,按照與神威OpenACC相同的控制流驅動的fork-join執行模式,稱為任務圖單步執行。
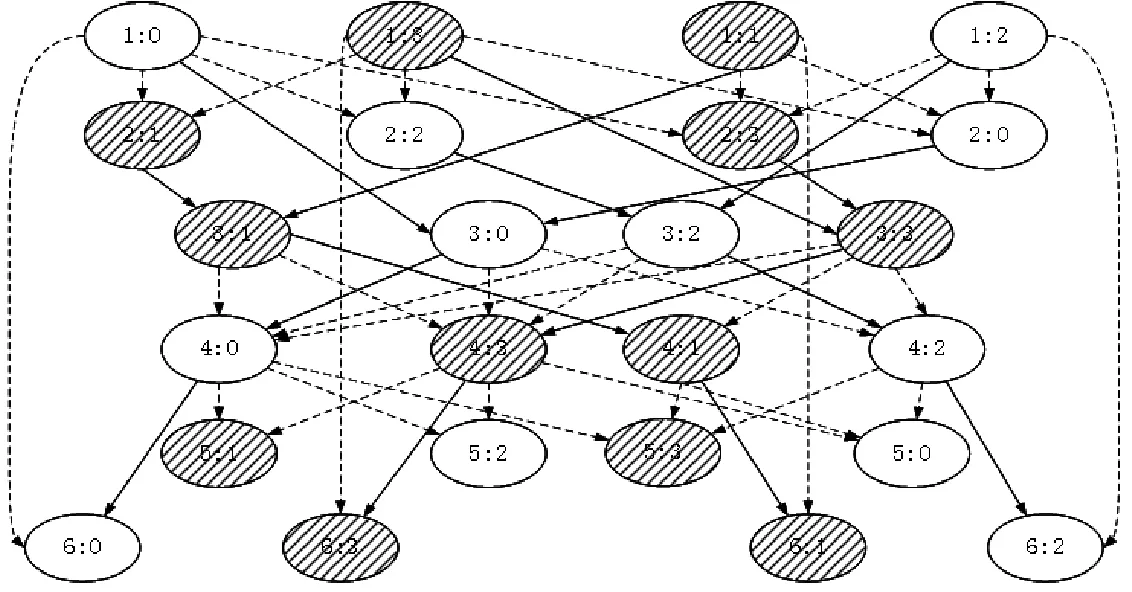
圖7 2線程4任務時TP模塊任務依賴圖Fig.7 Task dependency graph of TP module under 2 threads 4 tasks

圖8 神威OpenACC與任務圖并行化性能Fig.8 Performance of the Sunway Open ACC andtask graph parallelization
2)從核包裝任務函數,將應用主要的計算代碼包裝成任務函數。從核任務函數根據構圖期分配的函數參數、循環劃分尺寸、數據區劃分尺寸等信息,包裝任務函數,放入從核陣列并行計算。
3)從核數據管理。SW26010主從核間的數據傳輸通過DMA實現,DMA只能由從核發起,主核被動進行數據傳輸。從核制定傳輸的模式時,數據傳輸依據數據在主存數據區內存儲地址的連續性和從核計算實際需要的數據尺寸進行傳輸。DMA數據傳輸方式分為跨步式數據傳輸和非跨步式數據傳輸。兩種傳輸模式下,軟件開銷主要體現在傳輸的啟動和對DMA傳輸回答字的處理。本研究采用數據分片存儲的數據結構,將任務訪問的數據進行分片存儲,并以數據塊編號為索引劃定數據區,通過athread_get/athread_put接口進行非跨步傳輸;對于離散數據訪問,在主核代碼中對離散數據打包后,使用DMA方式進行數據傳輸,最后在從核代碼中對數據進行解包,提高離散數據的訪問效率。
本節將第3節中OpenACC優化后的版本(ACC)作為基礎版,同等的優化條件下,與任務圖單步版(single step of DAG)、任務圖亂序版(Unordered DAG)進行實驗對比。迭代時間步長為1時,Silicon-Crystal應用性能如圖8所示。
可以看出,由于任務圖單步版和OpenACC采用相同的fork-join模式,即并行區開始spawn線程,并行區結束wait所有線程,故二者的執行時間一致,說明兩者具有計算一致性。任務圖亂序版比任務單步版提升27%,驗證了任務間的亂序執行,可以錯開峰值帶寬競爭,充分的利用從核訪存帶寬。但是,由于神威OpenACC采用fork-join模式,其執行時間即為總時間;數據流驅動的任務圖并行需要在構圖期構建任務執行的依賴關系,故其總時間為構圖時間與執行時間之和。實驗結果表明,Silicon-Crystal應用的任務圖并行化存在相對總時間8%的構圖時間,加上此部分構圖開銷,總時間上任務圖并行比ACC性能提升11.5%。
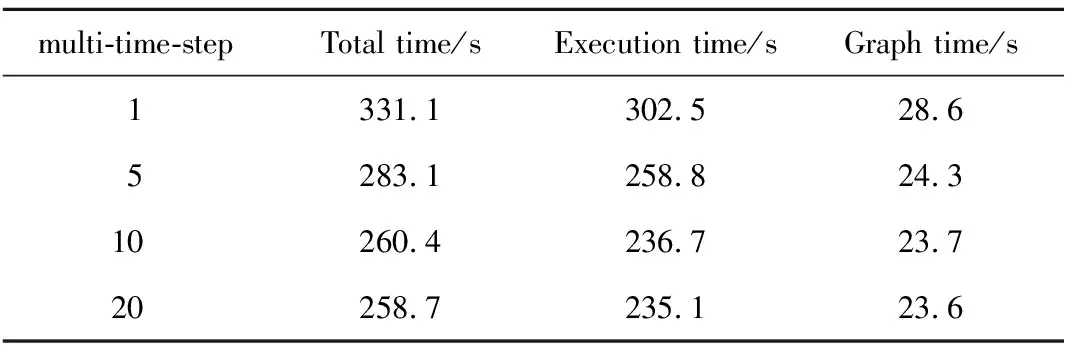
表1 多時間步擴展下任務圖并行化構時間Tab.1 Times of task graph parallelization based on multiple time steps

圖9 多時間步下任務圖并行化加速比Fig.9 Acceleration ratio of task graph parallelizationunder multiple time steps
傳統的fork-join模式無法擴展多時間步的迭代計算,任務圖卻可打通迭代時間步間的并行區域,即在構圖期依據多個時間步下任務的數據流構建出任務依賴圖,執行期按多時間步下任務亂序調度方式執行任務,從而將迭代時間步由單時間步擴展至多時間步,如表1所示,隨著任務圖并行在多時間步的擴展,執行時間進一步降低,構圖時間逐漸降低,使得任務圖并行性能進一步提升。
多時間步下任務圖并行化加速比如圖9所示,以主核版作為基準版,使用神威OpenACC移植利用從核加速,實現2.26倍加速比;時間步為1時任務圖并行加速比為2.52;隨著時間步的擴展,任務圖規模隨之增加,任務的亂序使錯峰訪存的優勢進一步擴大,時間步擴展至20時趨于平穩,加速比達到3.2。
5 總結與未來工作
本研究為Silicon-Crystal應用設計了一套在SW26010上實現主從計算的并行化方案,利用OpenACC完成了向目標平臺“神威·太湖之光”上的移植,在單核組內實現了2.52倍加速;針對該應用訪存密集的行為特點,以數據流驅動的任務圖并行化方法解決任務間的峰值訪存和跨時間迭代問題,結果表明,Silicon-Crystal應用在數據流驅動的任務圖并行在單時間步下性能提升11.5%,多時間步下性能提升42%,總體較主核實現3.2倍加速。
數據流驅動的任務圖并行編程模型采用AceMesh任務調度系統中的低級接口對程序源碼進行優化,隨著本課題組數據驅動的并行調度系統自動轉譯器的完善,未來將使用指導語言的高級形式對代碼進行自動源源變換,從而實現通過指導語言方式對應用任務圖并行的自動化過程。
