從解構到重構:結構化新聞的概念承遞、價值與未來*
2019-05-24 09:25:40何德俊
中國出版 2019年9期
□文│胡 兵 何德俊
結構化新聞不管作為一種技術還是一種新聞范式,研究其概念承遞與研究變遷可為當下自動化新聞的縱深發展提供新的思路。然而,目前國內外只有少數學者在進行結構化新聞的研究,且多為新聞數據如何結構化的技術性論文。綜觀這些論文,與本文研究的結構化新聞(新聞的原子化與再利用)在研究對象上有所不同,在研究視角上也存在差異。國內既缺乏結構化新聞的實踐,對結構化新聞的研究也只停留在概念的認知層面,缺乏深度和廣度的研究;而本研究采用“微宏互補”的研究視角,注重思辨性和宏觀性。希望當下新聞生產者能看到結構化新聞對新聞業帶來的深遠影響以及發展機遇。
一、結構化新聞的概念承遞與研究變遷
盡管“structured journalism”在國外也是近幾年才出現的概念,但與其相關的研究已存在十幾年。它的前身是數據庫新聞(database journalism),其也屬于近幾年熱門的自動化新聞(automated journalism)領域。 “structured journalism”在國外發展的脈絡如何?其與同由數據庫新聞演進而來的數據驅動新聞(data-driven journalism)又有何不同?
1.后“數據庫新聞”階段:解構新聞
數據庫新聞,作為計算機輔助報道的同義詞,可以追溯到20世紀50年代。到了20世紀90年代,記者們開始嘗試從一些數據庫中找一些數據集,挖掘新聞專題,這些數據庫既包括政府公開數據庫,也包括媒體自己的數據庫。[1]早期的數據庫新聞沒有以機器可讀的方式將新聞信息保存起來,這些數據的價值沒有被挖掘,無法重新利用或聚合成新的故事。只是在形式上通過新聞鏈接的方式,利用原有的新聞信息資料對已有的新聞報道元素進行深度和廣度描述鏈接。[2]
互聯網的發展給數據庫新聞提供了一個新的定義。傳播學者維貝克·盧森(Wiebke Loosen)將數據庫新聞定義為“通過使用與媒體無關的發布系統將原始資料(文章、照片和其他內容)充實數據庫,并將其提供給不同的設備”。[3]傳統新聞將文章作為最終產品,而數據庫新聞生成不斷維護和改進的事實數據庫。[4]2007年起數據庫新聞迅速發展,包括英國廣播公司(BBC)、《衛報》《紐約時報》和美國國家公共廣播電臺等多家新聞機構在網站上發布應用程序接口(application programming interface,API),開放給用戶提供數據。這些新聞機構將新聞內容視為數據,承認他們活動的核心不是編寫故事,而是數據收集和數據分發。到了2011年,一些項目的數據庫本身就可以被視為新聞網站,讀者可以通過數據庫接口對數據庫進行檢索和分析,從而發現新的“新聞”。至此,數據庫新聞演變成一種由結構化數據碎片組成新聞內容的信息管理準則,重在對新聞故事的解構,將新聞信息碎片化后存入數據庫以備后用。
2.結構化新聞階段:原子化新聞
由于業界逐漸發現非結構化數據(不可以用行列表格呈現的數據)在新聞生產過程中的重要性,希望找到一種自動化的方式去“解構”這些新聞故事中的元素,并將這些元素保存起來進行再利用,繼而自動生成結構化的“新”報道。結構化新聞的概念亦隨之出現。隨后,“structured journalism”一詞見諸于一些記者的博客中;BBC新聞實驗室、《紐約時報》研發中心、《華盛頓郵報》、尼曼實驗室、杜克大學記者實驗室、密蘇里新聞學院雷諾茲新聞研究所等也相繼開展了以“structured journalism”標識的研究項目或實踐項目,例如“政治事實(PolitiFact)”項目對政府或非政府人員在公開場合發表的政治陳述文本進行處理,并將每一個個案呈現出來供用戶查詢。結構化新聞就是將日常的非結構化新聞文本處理成結構化數據并再次利用在新的報道中或者將其可視化。[5]新聞故事拆分得越小,獲得的價值越大,所有的故事都是在一個不斷擴張的網絡當中相互關聯的。[6]因此也有學者把結構化新聞稱為“原子化新聞”。
隨著數據挖掘技術的發展,新聞數據庫中的數據價值被挖掘出來,“數據新聞”(data journalism)或稱為“數據驅動新聞”(data-driven journalism)是“數據庫新聞”的另一個演進方向。結構化新聞與數據驅動新聞都與“數據”有著密切的聯系,但兩者的本質卻并不相同。數據驅動新聞強調從數據當中去挖掘新聞故事,是一個“數據—新聞”的過程。而結構化新聞則是對新聞文本及內容的解構和重構,強調構造和維護基于新聞內容的知識庫,并最終生成更多新聞故事,是一個“新聞—數據—新聞+”的循環增值過程。
3.自動化新聞2.0:重構新聞
2016年,第三次人工智能浪潮席卷各行業,自動化寫作系統的開發與應用也風生水起,“自動化新聞(automated journalism)”一詞逐漸普及。而“structured journalism”一詞卻在國外媒體和文獻中少有出現,僅有一些“結構化故事(structured stories)”“結構化敘事(structured narratives)”表述。媒體和學術機構開放的以“structured journalism”標識的項目大多都沒有更新。由此可見,從2017年起國外已逐步用“automated journalism”“算法新聞(algorithmic journalism)”或“機器人新聞(robot journalism)”等詞代替“structured journalism”。結構化新聞表述的變化也預示著對結構化新聞研究重點的變遷:其一,結構化新聞不像數據庫新聞只關注對新聞信息解構成“原子”存入數據庫,同時也強調將這些“原子”重構成新的更有價值的新聞報道,也就是說“解構”與“重構”同樣重要。其二,新聞記者逐漸將注意力集中到蘊含價值更大的非結構化數據之上,不僅對結構化的新聞信息進行解構,更關注非結構化新聞信息的解構。
二、結構化新聞的技術框架:I-T-O模式
結構化新聞主要涉及自然語言處理(natural language processing,NLP)和自然語言生成(natural language generation,NLG)技術,其核心在于知識庫的構建。賴特(Reiter)等人曾使用“I-T-O模式”去解釋NLG技術在新聞生產上的應用。[7]筆者借用這個“I-T-O模式”分析結構化新聞的技術架構。“I-T-O模式”分別對應輸入層(Input)、處理層(Throughput)以及輸出層(Output),如圖1所示。
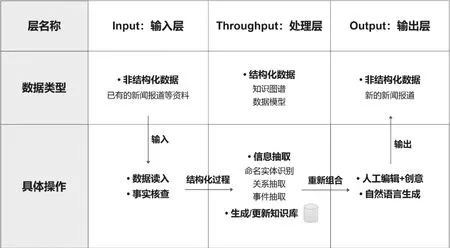
圖1 “I-T-O模式”下的結構化新聞技術框架圖
1.輸入層
所有自動化新聞都需要先讀入大量的數據。輸入層主要有數據讀入和事實核查兩個環節。
數據讀入(data ingestion)。與一般的機器寫作不同,結構化新聞的輸入并不只是諸如體育比賽、金融股市等高度結構化的數據,傳統的非結構化新聞文本才是結構化新聞的主要輸入源之一。媒體的歷史新聞數據庫以及社交媒體的公開API也是結構化新聞數據輸入的主要來源。隨著技術的成熟,圖像、視頻等也在逐漸成為結構化新聞的輸入數據。
事實核查。為確保新聞報道的真實性,對于已讀入的文本數據,必須要進行報道真實性、發布媒體權威性以及數據精確性等事實核查操作。目前,依靠機器已經能實現大部分的核查操作,但涉及倫理道德等問題的審核依舊需要人工干預。
2.處理層
該層主要負責新聞文本的“結構化”。
信息抽取(information extraction)。采用NLP技術和文本挖掘方法的信息抽取就是將非結構化數據“結構化”,將新聞文本拆分成零散的“信息碎片”,從中發現新知識并將其轉換為可理解的有用信息,然后對這些碎片進行語義標注(tag)并存儲起來。簡單說,NLP的工作就是“讀”新聞,將文本置于上下文中理解。信息抽取具體包括三種關鍵技術:命名實體識別、關系抽取和事件抽取。
命名實體識別。日常的新聞文本中通常包含著大量的人物、地點、組織等要素。在NLP技術中,這些要素被稱作命名實體(name entity)。在對文本數據進行預處理后(包括分詞、詞性標注),就要發現命名實體并確定其類別。關系抽取。關系抽取的作用是獲取文本中實體之間存在的語法或語義上的聯系。例如,從“馬云是阿里集團的首席執行官(CEO)”這個句子中可以抽取出:“馬云”和“阿里集團”的關系。事件抽取。事件是新聞語義特征構建的中心。結構化新聞中的事件抽取主要指從大量的新聞文本中抽取出相關的事件,該過程一般分成“元事件抽取”和“主題事件抽取”。前者著重對單一事件的時間、地點、人物的抽取。而后者主要是抽取某一主題下的系列事件。
知識庫的構建與更新。隨著大量的新聞文本等非結構化數據不斷輸入,處理層將構建一個龐大的“知識庫”(knowledge base)。這是結構化新聞生產過程的核心步驟。知識庫實際上是對數據庫的擴充與升級。知識庫系統利用知識庫對輸入的數據信息進行推理之后,提供給系統使用者的是判斷分析后的結果,而不僅僅是向用戶提供可檢索的信息。在知識庫平臺后面實則是語義網的建設。
3.輸出層
“數據庫新聞”側重于強調將新聞“解構”后存入數據庫,以備再利用。而隨著NLG技術的發展,結構化新聞逐漸強調“解構-重構”這一完整過程,“重構”可以是人工完成,也可以是機器自動完成。輸出的文本可以是非結構化的也可以是結構化的。
人工編輯。從輸入層到處理層,文本數據已經實現了“結構化”并構成了一個知識庫。可以說,這個龐大的知識庫就是記者大腦的延伸,其中所儲存的數據和關聯規則能夠提供大量的人物關系和背景材料,從而有效地提高記者寫作的效率和質量。
自然語言生成(NLG)。NLG技術是機器實現自動化寫作的核心技術。簡言之,NLG的工作類似于填字游戲,是“寫”新聞,把結構化、模塊化的數據組裝成易理解的書面敘事。在結構化新聞的輸出層,機器將自動從知識庫中讀取相應的“原子”,根據原本的關聯規則和特定的語言模板將這些“新聞原子”取出并重新組合成新的自然語言形式的新聞報道。
三、結構化新聞的價值
結構化新聞是一種信息表現機制,為新聞提供了另一種范式。[8]正如電視時代要求新聞是可視化的,結構化新聞則能更好地適合數字時代,更容易被讀者理解。結構化新聞將為新聞消費者、新聞生產者、新聞編輯室以及不斷變化的媒體環境提供一個可持續的前進方向。
1.新聞消費者:個性化閱讀和填補“記憶漏洞”
尼葛洛龐帝曾提到“超媒體(hypermedia)”的概念。他認為:數字世界的信息空間可以通過一組多維指針來進一步引申或辨明。整個文檔結構仿佛一個復雜的分子模型,大塊信息可以被重新組合,句子可以擴張,字詞則可以當場定義,這些連接可以由作者或讀者在出版前后自行嵌入。[9]“結構化故事”網站(www.structuredstories.com)是一個新聞數據庫,它不僅允許每個人對某個新聞事件進行持續收集、使用和改進;而且受眾閱讀新聞時可以選擇多種新聞呈現形式,包括“要點”“時間線”“圖片集”“結構化故事”(內容中標注動詞、名詞,并可連接至維基百科)、“新聞5W卡片”等形式,受眾還可根據對事件的感興趣程度選擇新聞呈現的詳略,讓消費者對報道產生“流連忘返”的反復閱讀的欲望,從而實現個性化閱讀。
為了追求時效性,網絡媒體的新聞報道往往只能“管中窺豹”,無法對包括事件背景在內的各個方面進行詳細敘述,受眾難以對事件進行全面了解和把握。類似地,曾經關注過該事件的讀者也可能因為時間間隔太長而忘記事件的前因或背景,這就是讀者的“記憶漏洞”,而且每個讀者的“記憶漏洞”是不一致的。《華盛頓郵報》有一個實驗項目“知識地圖”(Knowledge Map),該項目在文章中使用大量的注釋文本(如姓名、主題和事件),當讀者點擊摘要、圖片或其他輔助材料時,這些注釋會出現在側邊欄中,使讀者的“記憶漏洞”得到填補。
2.新聞生產者:信息再加工和深加工創造新聞價值
美國文學教授杰·戴維·波爾特提出了“寫作空間”(writing space)的概念,他問:是不是可以設想一種寫作空間的存在,使得作者可以同時思考和呈現幾條不同的敘述線?[10]結構化新聞背后龐大的知識庫提供了一種新型的“寫作空間”。它將散落在互聯網中的離散的碎片信息重新整合到一張龐大的知識網絡當中,碎片之間的關系和邏輯依舊保留下來。根據需要,這些碎片將以特定方式混合和重組,從而實現當天新聞與歷史資料的無縫聚合,發揮傳播的長尾效應。記者在尋找新的報道角度、創造新聞價值的同時,還應植入產品邏輯,將自己定位為“做產品”而非“寫文章”,將文本生產從靜態的、完成式的工作,變成動態的、始終進行式的生產過程。
3.新聞編輯室:數據財富和分散共治
知識庫是新聞編輯室的“數據中心”,也是“信息聯結中心”。數據的每一次“流動”都會“自我增值”,能夠為使用者帶來更豐富的內容或更多元的角度。套用梅特卡夫法則(Metcalfe's Law),網絡價值以用戶數量的平方速度增長,知識庫的價值則以新聞報道數量的平方速度增長。同時,新聞也有不言而喻的市場價值,各個新聞編輯室所擁有的結構化的知識庫是不可復制的,是新聞編輯室的一個新的經濟基礎。“買新聞”可以發揮成本效能,新聞素材在媒體內部實現市場化流通,形成媒體融合的觀念和思維。
戴維·溫伯格提出了“三階秩序”的概念,他認為:照片放進相冊是“一階組織”,圖片資料庫的目錄卡是“二階物件”,它指向的是一階圖片所在的位置。而內容被數字化,該內容的相關信息也由數位組成——這就是三階秩序。[11]在二階世界中,我們需要專家來逐個檢查信息、思想和知識,然后將其整整齊齊放好,過去我們的報業等許多產業和機構都是基于這一事實之上。傳統的新聞故事生產方式并不允許人們做過多的組合和修改,而結構化新聞(三階秩序)則是萬物皆可被重構。結構化新聞的生產蘊含了新聞編輯室文化和思維的轉型,“無序中的有序”一種責任共擔的自治管理文化正在新聞編輯室興起,它能讓新聞編輯室內的個人和團隊直接對內容負責,不僅可以提升內容的生產效率,內容本身的地位也會大大提升。
四、機遇與挑戰
雖然結構化新聞蘊含著豐富的價值,但結構化新聞并沒有像數據新聞那樣逐漸成為一種特色鮮明的新聞范式,反而其概念還有弱化的趨勢。現階段結構化新聞存在許多挑戰,同時我們也應看到人工智能技術的發展給其帶來的發展機遇。
1.機遇一:“事件驅動”的自動化新聞的發展
在實現發稿快、產量高之后,自動化新聞將向深度內容、寫作風格等縱深領域發展。美國“結構化故事(Structured Stories)”項目的目的就是為了讓記者和機器以結構化的方式解構新聞事件而并非輸入傳統的非結構化文本,以便讓機器找到新聞的中心語義特征——事件,完成復雜的寫作。卡斯韋爾(Caswell,2017)發表的論文首次使用了“Automated Journalism 2.0”一詞,[12]強調以“事件驅動”的敘事報道不同于目前大多數機器生成的簡單描述性新聞,其能夠解釋、放大和闡述重大事件及其內在價值,幫助受眾更豐富、更微妙地去理解敘事信息,滿足受眾的情感需求。從簡單故事到復雜敘事的自動化寫作需求,將推動結構化新聞的發展。
2.機遇二:媒體“中央廚房”的發展
從某種意義上講,結構化新聞的知識庫類似于“中央廚房”的新聞稿庫。雖然“中央廚房”也是以內容的生產與傳播為主線的公共平臺,但是,結構化新聞所依托的知識庫比目前“中央廚房”的新聞稿庫更有價值。其一,建設“中央廚房”的目的是為了融媒體的發展,實現稿件共享。但實際上,在傳統媒體上發布的新聞稿件并不適合直接在新媒體平臺上發布,在標題、報道風格、新聞用語等方面傳統媒體和新媒體平臺有著本質不同。而結構化新聞是將新聞故事拆分后使用,拆分得越小獲得的價值越大,越有利于新媒體平臺創新組合使用。其二,“中央廚房”的新聞數據庫雖然積累和共享新聞報道中的事實、理論和背景材料,但它并不能有效地對事件間彼此的關系和邏輯進行識別和保存。結構化新聞的發展將促進媒體的“中央廚房”發揮更大的作用,兩者相輔相成,共同發展。
3.挑戰一:技術和編輯
盡管在技術上捕獲和存儲新聞的結構化事件和故事數據的能力在不斷提高,但有些問題仍未完全解決。例如目前對新聞事件的分詞系統切割文本的“碎片”還不夠細;以事件驅動的結構化新聞的文本碎片構造和NLG模版邏輯的設計比目前流行的機器人寫作所使用的NLG模版要復雜得多。[13]來自編輯層面的挑戰可能更大。結構化新聞在生成過程中離不開人的干預,新聞生產應從數字泰勒主義到人機共生。[14]一方面,新聞的素材是在網絡上自動抓取的,因此最終生成的新聞在事實性、合法性上都需要經過編輯的二次核查才能被分解再重新利用。[15]另一方面,目前人工對新聞的“結構化”,即對結構化事件和故事數據的碎片化,比程序對新聞自動“結構化”的效果要好,準確率更高。
4.挑戰二:人才結構和培養
結構化新聞的發展必然要求“媒體+科技”。雖然科技具有無窮無盡的迷人力量,但媒體要擁抱科技,借助科技力量探索新的內容生產方式,就必須要有技術人才。然而,媒體不是同時擁有了記者編輯和技術人員就算大功告成了。技術人員不了解新聞生產,傳統媒體人不了解如何用技術呈現內容。因此,我們的媒體要擔負起復合型媒體人才培養職責,一方面,對技術人員既要培訓新聞生產流程,也要培養他們的新聞敏感性;另一方面,要培養記者的計算性思維,讓記者能以軟件開發者思考代碼那樣的方式思考新聞。
五、結語
不管結構化新聞未來發展如何,把非結構化的文本、聲音和圖像等進行結構化,形成知識庫,卻是一件非常有意義的事情。凱文·凱利認為,被抓住的每一個機遇都會引發至少兩個新的機遇。[16]自動化新聞只是這些結構化數據的應用之一,其他的應用,如智能語音聊天、智能商業、政府智能應用等,都可能驅動這些結構化數據平臺的發展。例如在智能醫療中,通過對病歷信息結構化后所獲得的數據進行分析,可以發現病情與食物之間的相關性。“重組”(remixing)產生價值。圣塔菲研究所的經濟學家布萊恩·亞瑟(Brain Arthur)認為“所有的新技術都源自于已有技術的組合”。適用于經濟增長和技術增長的事實同樣也適用于媒介發展。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
