基于Adaboost模型的江蘇省冬小麥產(chǎn)量預(yù)測(cè)
2019-08-07 01:04:27張順航張鳳航李金澤
現(xiàn)代農(nóng)業(yè)科技 2019年12期
關(guān)鍵詞:機(jī)器學(xué)習(xí)
張順航 張鳳航 李金澤


摘要? ? 農(nóng)作物產(chǎn)量預(yù)測(cè)是農(nóng)業(yè)科學(xué)的一個(gè)重要問題,而氣象特征的變化將對(duì)農(nóng)作物的產(chǎn)量產(chǎn)生影響。本文根據(jù)1981—2016年江蘇省的氣象數(shù)據(jù),研究影響農(nóng)作物產(chǎn)量的關(guān)鍵氣象特征,并利用機(jī)器學(xué)習(xí)中的Adaboost算法,對(duì)江蘇省近幾年的小麥產(chǎn)量進(jìn)行預(yù)測(cè)。結(jié)果表明Adaboost模型預(yù)測(cè)準(zhǔn)確率較高,從而為農(nóng)業(yè)生產(chǎn)中的正確決策提供參考。
關(guān)鍵詞? ? 冬小麥產(chǎn)量預(yù)測(cè);氣象特征;機(jī)器學(xué)習(xí);Adaboost模型;江蘇省
中圖分類號(hào)? ? S127? ? ? ? 文獻(xiàn)標(biāo)識(shí)碼? ? A? ? ? ? 文章編號(hào)? ?1007-5739(2019)12-0248-02
我國(guó)是農(nóng)業(yè)大國(guó),糧食產(chǎn)量連年增長(zhǎng),農(nóng)業(yè)生產(chǎn)量和生產(chǎn)方式都進(jìn)入到了新的階段,農(nóng)業(yè)生產(chǎn)新要求也隨之產(chǎn)生。在農(nóng)業(yè)生產(chǎn)中,注重農(nóng)產(chǎn)品品質(zhì)、關(guān)注農(nóng)業(yè)災(zāi)害預(yù)警能力等已迫在眉睫[1-3]。2009年曾有專家在聯(lián)合國(guó)做出預(yù)測(cè),到2050年世界糧食產(chǎn)量可能需要翻一倍才足以養(yǎng)活全球人口。而在眾多影響農(nóng)作物產(chǎn)量的因素中,氣候變化對(duì)農(nóng)業(yè)產(chǎn)生直接影響[4]。因此,通過氣象因素預(yù)測(cè)農(nóng)作物產(chǎn)量尤為關(guān)鍵。但由于農(nóng)作物在不同生長(zhǎng)階段對(duì)氣象因素有著不同的要求,使得建立氣象因素與農(nóng)作物產(chǎn)量的關(guān)系模型較為困難[5]。此外,雖然目前已有較多時(shí)間序列模型,如灰色模型預(yù)測(cè)、最小二乘法、BP神經(jīng)網(wǎng)絡(luò)、高斯過程,但在面對(duì)實(shí)際而復(fù)雜的分類問題時(shí)效果并不理想[6]。
1? ? Adaboost模型
Adaboost算法是boosting算法的一種,屬于一種迭代算法。它的核心思想是用同一個(gè)訓(xùn)練集訓(xùn)練不同的弱分類器,然后把這些弱分類器聯(lián)合起來形成強(qiáng)分類器,有效地解決了單個(gè)分類器面對(duì)復(fù)雜問題時(shí)精度不足的問題。通過江蘇省歷年冬小麥的產(chǎn)量和江蘇省歷年的氣象因素構(gòu)建Adaboost模型,以平均溫度、降水量、平均濕度、日照時(shí)數(shù)、有效積溫等氣象因素作為輸入,通過特征提取篩選出對(duì)產(chǎn)量影響較大的特征向量,利用交叉驗(yàn)證方法評(píng)估模型,然后進(jìn)行參數(shù)調(diào)優(yōu),最終實(shí)現(xiàn)較高精度的冬小麥產(chǎn)量預(yù)測(cè)[7],總流程見圖1。
2? ? 實(shí)例分析
2.1? ? 數(shù)據(jù)準(zhǔn)備
預(yù)測(cè)農(nóng)作物產(chǎn)量是實(shí)現(xiàn)精細(xì)農(nóng)業(yè)的重要措施之一,而影響冬小麥產(chǎn)量的主要?dú)庀笠蛩赜袦囟取穸取⒔邓俊⑷照諘r(shí)數(shù)、有效積溫等因素。
為了獲得江蘇省歷年氣象數(shù)據(jù),收集了包括江蘇省南京、無錫、淮安、常州等在內(nèi)的23個(gè)站點(diǎn)1981—2016年共36年每天的氣象數(shù)據(jù),包括平均溫度、降水量、輻射量、日照、平均濕度、平均風(fēng)速等數(shù)據(jù)。然后將這些站點(diǎn)的各類氣象數(shù)據(jù)取月平均值,再取所有站點(diǎn)的月平均值為江蘇省每類氣象數(shù)據(jù)的月平均值。根據(jù)相關(guān)資料可知,江蘇省冬小麥從10月開始播種,翌年5月收獲[8-11],所以選取這幾個(gè)月份的氣象數(shù)據(jù)作為訓(xùn)練集的輸入集。
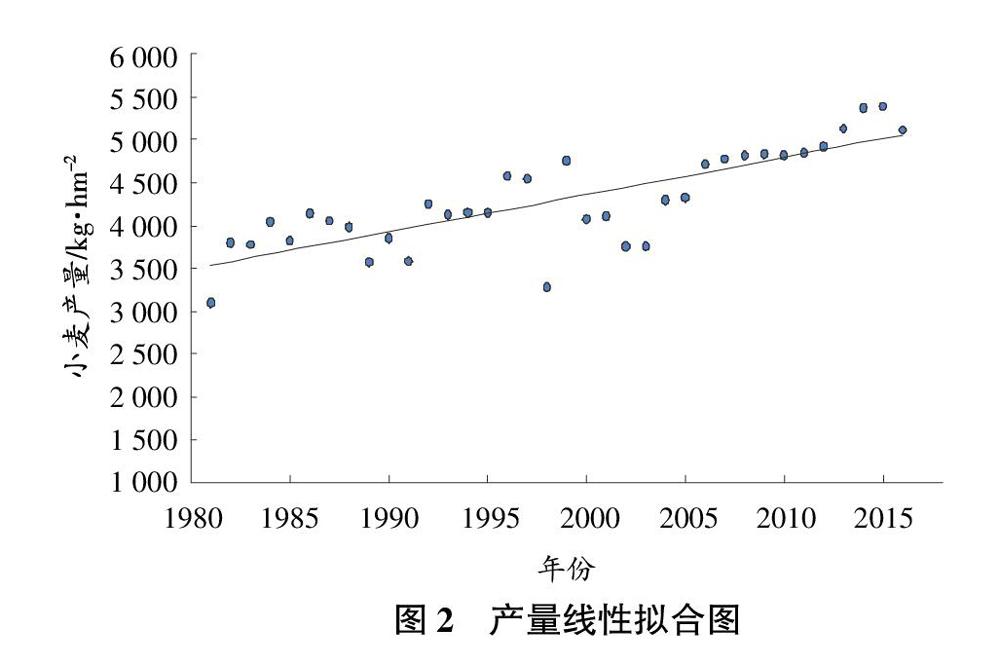
從國(guó)家統(tǒng)計(jì)局官網(wǎng)上查找江蘇省冬小麥近30年的產(chǎn)量數(shù)據(jù)作線性擬合。從圖2可以看出,圓點(diǎn)表示實(shí)際產(chǎn)量值,實(shí)線為擬合曲線。用(實(shí)際產(chǎn)量-擬合結(jié)果)/擬合結(jié)果,如果結(jié)果大于0表示這一年增產(chǎn)(用1表示),如果結(jié)果小于0則表示這一年減產(chǎn)(用0表示),據(jù)此得到訓(xùn)練集的因變量。
2.2? ? 建立Adaboost模型
AdaBoost是基于加性模型的算法,即基學(xué)習(xí)器的線性組合H(x)=Σαtht(x),其中,αt為每個(gè)基學(xué)習(xí)器的權(quán)值,ht(x)為每個(gè)基學(xué)習(xí)器的預(yù)測(cè)結(jié)果。建立過程主要分為3個(gè)部分:指數(shù)損失函數(shù)lexp(H|D)的降低、基學(xué)習(xí)器的權(quán)值αt的更新和訓(xùn)練集樣本分布的更新和訓(xùn)練集樣本分布的更新和訓(xùn)練集樣本分布Dt(x)的更新。
2.2.1? ? 指數(shù)損失函數(shù)。若為樣本的實(shí)際標(biāo)簽值,H(x)為樣本的預(yù)測(cè)標(biāo)簽值,設(shè)Ex~D[e-f(x)H(x)]為樣本服從數(shù)據(jù)集分布D時(shí),e-f(x)H(x)的期望值,則可以表示出指數(shù)損失函數(shù),若存在H(x)使得損失函數(shù)可以最小化,其中y?綴{-1,1},則可以求出
2.2.2? ? 基學(xué)習(xí)器權(quán)值αt的更新。ht和αt當(dāng)基學(xué)習(xí)器ht(x)基于分布Dt產(chǎn)生后,可求得基學(xué)習(xí)器的權(quán)重αt應(yīng)使得αtht最小化指數(shù)損失函數(shù),進(jìn)行偏導(dǎo)數(shù)并置零,得到這樣就得到了基學(xué)習(xí)器的權(quán)值更新公式。
2.2.3? ? 訓(xùn)練集樣本分布Dt(x)的更新。獲得基學(xué)習(xí)器ht-1(x)后,樣本分布將進(jìn)行調(diào)整,可以得到理想的基學(xué)習(xí)器,其中ht(x)將在分布Dt(x)下最小化分類誤差,因而ht(x)應(yīng)該基于分布Dt(x)來訓(xùn)練。
2.3? ? 特征選擇與參數(shù)調(diào)節(jié)
用訓(xùn)練集進(jìn)行特征選擇,選擇6個(gè)對(duì)江蘇省冬小麥產(chǎn)量影響最大的氣象因素,分別為3月份降水量、1月份平均濕度、3月份平均濕度、1月份平均溫度、5月份平均溫度和3月份日照時(shí)數(shù)。然后是參數(shù)調(diào)節(jié),Adaboost的參數(shù)主要有3個(gè),基分類器循環(huán)次數(shù)n_estimators、學(xué)習(xí)速度learning_rate和模型提升準(zhǔn)則algorithm。基分類器循環(huán)次數(shù)過多,模型容易過擬合;循環(huán)次數(shù)過少,模型容易欠擬合。學(xué)習(xí)速度如果過大,則容易錯(cuò)過最優(yōu)值;如果過小,則收斂速度會(huì)很慢。模型提升準(zhǔn)則有2種方式SAMME和SAMME.R,前者是對(duì)樣本集預(yù)測(cè)錯(cuò)誤的概率進(jìn)行劃分,后者是對(duì)樣本集的錯(cuò)分率進(jìn)行劃分。先用模型的默認(rèn)參數(shù)對(duì)冬小麥產(chǎn)量進(jìn)行預(yù)測(cè),評(píng)估預(yù)測(cè)效果,然后采用網(wǎng)格搜索法對(duì)模型進(jìn)行調(diào)參。最終調(diào)整的參數(shù)為n_estimators=40,learning_rate=0.8,algorithm=′SAMME.R′。
2.4? ? 結(jié)果分析
采用留一檢驗(yàn)法訓(xùn)練模型并得到最終的預(yù)測(cè)結(jié)果,36年中預(yù)測(cè)正確的年份多達(dá)30年,正確率為83.3%。根據(jù)表1可知,在2005—2016年的12年時(shí)間里,預(yù)測(cè)錯(cuò)誤的年份僅有2年,且2010年之后的預(yù)測(cè)值全部正確,說明該Adaboost模型對(duì)冬小麥的產(chǎn)量預(yù)測(cè)精度較高,尤其是對(duì)近幾年小麥的增產(chǎn)減產(chǎn)情況全部預(yù)測(cè)正確。
3? ? 結(jié)語
近幾年,雖然機(jī)器學(xué)習(xí)成為了最熱門的技術(shù)之一,但實(shí)際上由于機(jī)器學(xué)習(xí)需要大規(guī)模的訓(xùn)練集訓(xùn)練,所以實(shí)際應(yīng)用范圍有限。尤其是對(duì)于農(nóng)業(yè)領(lǐng)域來說,可供使用的數(shù)據(jù)非常有限,只能用小數(shù)據(jù)集進(jìn)行研究。常規(guī)的方法在用小數(shù)據(jù)集做預(yù)測(cè)與分類時(shí)精度低且結(jié)果不穩(wěn)定,而本文所用的Adaboost算法將弱分類器聯(lián)合起來形成強(qiáng)分類器,有效地解決了單個(gè)分類器面對(duì)復(fù)雜問題時(shí)精度不足的問題,在實(shí)際應(yīng)用中可行度較高。
4? ? 參考文獻(xiàn)
[1] 江顯群,陳武奮.BP神經(jīng)網(wǎng)絡(luò)與GA-BP農(nóng)作物需水量預(yù)測(cè)模型對(duì)比[J].排灌機(jī)械工程學(xué)報(bào),2018,36(8):762-766.
[2] 王曉喆,延軍平,張立偉.河南省氣候生產(chǎn)力時(shí)空分布及糧食產(chǎn)量預(yù)測(cè)[J].農(nóng)業(yè)現(xiàn)代化研究,2011,32(2):213-216.
[3] 高蕾.基于ARIMA模型的安徽省糧食產(chǎn)量預(yù)測(cè)研究[J].合肥學(xué)院學(xué)報(bào)(社會(huì)科學(xué)版),2015,32(5):17-18.
[4] 朱新國(guó),張展羽,祝卓.基于改進(jìn)型BP神經(jīng)網(wǎng)絡(luò)馬爾科夫模型的區(qū)域需水量預(yù)測(cè)[J].水資源保護(hù),2010,26(2):28-31.
[5] 林紹森,唐永金.幾種作物產(chǎn)量預(yù)測(cè)模型及其特點(diǎn)分析[J].西南科技大學(xué)學(xué)報(bào)(自然科學(xué)版),2005,20(3):55-60.
[6] 王興,劉晶晶,闞苗苗,等.我國(guó)主要糧食作物產(chǎn)量預(yù)測(cè)模型及分布特征分析[J].長(zhǎng)江大學(xué)學(xué)報(bào)(自科版),2014,11(4):76-79.
[7] 宰松梅,郭冬冬,溫季,等.作物產(chǎn)量預(yù)測(cè)的BP神經(jīng)網(wǎng)絡(luò)模型研究[J].人民黃河,2010,32(9):71-72.
[8] 商兆堂,張旭暉,商舜,等.江蘇省冬小麥生產(chǎn)潛力氣候變化趨勢(shì)評(píng)估[J].江蘇農(nóng)業(yè)科學(xué),2018,46(12):245-249.
[9] 陳夏.江蘇省冬小麥模型模擬優(yōu)化研究及應(yīng)用[D].南京:南京信息工程大學(xué),2017.
[10] 姚金保,馬鴻翔,張鵬,等.小麥寧麥26豐產(chǎn)性、穩(wěn)產(chǎn)性及適應(yīng)性分析[J].浙江農(nóng)業(yè)學(xué),2018,59(11):1966-1968.
[11] 王瑞崢,江洪,金佳鑫,等.黃淮海地區(qū)冬小麥物候?qū)夂蜃兓捻憫?yīng)及對(duì)產(chǎn)量的影響[J].江蘇農(nóng)業(yè)科學(xué),2018,46(22):71-75.
猜你喜歡
電子技術(shù)與軟件工程(2016年22期)2016-12-26 21:36:42
時(shí)代金融(2016年27期)2016-11-25 17:51:36
科教導(dǎo)刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學(xué)與財(cái)富(2016年28期)2016-10-14 21:19:17
電腦知識(shí)與技術(shù)(2016年20期)2016-08-19 18:49:49
電腦知識(shí)與技術(shù)(2016年12期)2016-06-14 00:45:31
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 19:17:03
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識(shí)與技術(shù)(2016年3期)2016-04-07 16:12:55
