基于模糊運算的電商客戶數據挖掘研究
2019-08-14 03:37:10童百利吳曉兵
四川文理學院學報 2019年5期
關鍵詞:方法
李 眩,童百利,吳曉兵
(安徽省銅陵職業技術學院 經管系,安徽 銅陵 244061)
0 引言
互聯網經濟環境下,電子商務快速發展,交易過程產生的客戶數據規模不斷擴大,維度不斷增加,且數據類型變得十分復雜,呈現出大數據特征,但其蘊含的巨大商業價值能否最大限度利用,取決于數據挖掘和分析的方式.因此設計一種高效合理的數據挖掘方法對電商客戶數據進行分析,這已經成為電子商務應用中研究的熱點問題.對電商客戶進行聚類,挖掘客戶購買行為等方面的特征,針對不同客戶群體提供量身定做的服務,進而實現高效精準的個性化服務和差異化營銷.同時,也可為站點結構改進、網頁推薦、發掘潛在價值客戶等提供決策依據.
聚類過程是指將一組物理的或者抽象的對象,根據它們之間的相似程度,分為若干類.其中,特征相似的對象構成一類.[1]傳統的聚類方法是基于經驗或者簡單的統計方法,聚類主觀性強,效果不理想.其聚類方法一般都是硬劃分,將對象進行嚴格區分,分類界限分明.而電子商務客戶群具有多樣性的特點,往往不能用某一嚴格界限對其進行具體類的劃分,采用傳統方法聚類不理想.模糊理論的出現為聚類提供新的思路,聚類思想由硬劃分中的“要么屬于,要么不屬于”變化為“用屬于程度來描述”.[2]客觀事物之間沒有一個截然區別的界限,不是嚴格分明的,是帶有模糊性的,因此用模糊方法解決聚類問題必然更符合實際.模糊聚類結果不是說事物絕對地屬于或不屬于某類,而是指屬于某類的程度有多大,其在聚類分析的基礎上,引入“隸屬度”來度量每個樣本與各類的隸屬程度,聚類結果比較科學合理.
1 模糊聚類算法
1.1 模糊聚類的原理
模糊聚類算法是基于目標函數優化基礎上的一種數據聚類方法,[3]每項數據是哪類是比較模糊的,不能精確斷定,只是在某些方面有相似性,這相似性聚類結果是每個數據對聚類中心的隸屬度來度量得出的,該隸屬程度用一個數值來表示 .[4]
模糊聚類算法執行步驟如下:
模糊聚類分析的目標函數:

其中,uji表示樣本 xj對應第i類中心 vi的隸屬度,m是模糊權重因子(m>1),是樣本 xj到第i類中心 vi的歐氏距離,c為分類數目(1<c<n),是n× c矩 陣 ,V = [ v1, v2…vc]是s×c矩陣,s代表維數.
(1)設定聚類數目c和模糊權重參數m,隨機初始化聚類中心;
(2)計算所有樣本數據的隸屬度矩陣,并且是每列元素之和滿足恒等于1的約束條件;
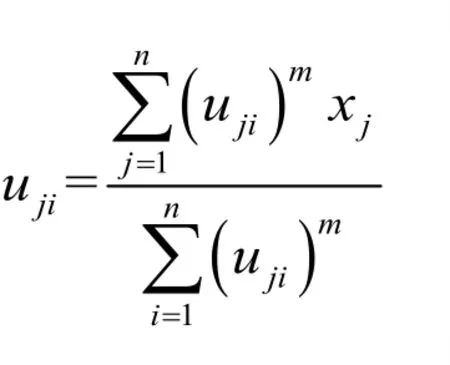
(4)計算 Vk+1,則有:
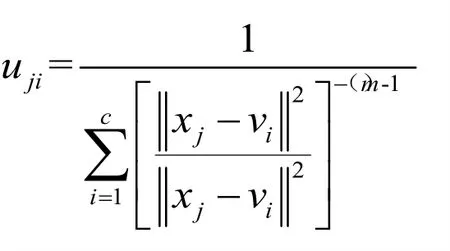
1.2模糊聚類的實現代碼
模糊聚類的MATLAB程序[5]代碼共包括三個函數,通過相互調用能實現聚類的過程和結果輸出,代碼如下:
function[U,V,objFcn]=myfcm(data,c,T,m,epsm)
c=4
if nargin<3
T=100;
end
if nargin<5
epsm=1.0e-6;
end
if nargin<4
m=2;
end
[n,s]=size(data);
U0=rand(c,n);
temp=sum(U0,1);
for i=1:n
U0(:,i)=U0(:,i)./temp(i);
end
iter=0;
V(c,s)=0;U(c,n)=0;distance(c,n)=0;
while(iter<T)
iter=iter+1;
Um=U0.^m;
V=Um*data./(sum(Um,2)*ones(1,s));
for i=1:c
for j=1:n
distance(i,j)=mydist(data(j,:),V(i,:));
end
end
U=1./(distance.^m.*(ones(c,1)*sum(distance.^(-m))));
objFcn(iter) =sum(sum(Um.*distance.^2));
if norm(U-U0,Inf)<epsm
break
end
U0=U;
end
myplot(U,objFcn);
function d=mydist(X,Y)
d=sqrt(sum((X-Y).^2));
end
function myplot(U,objFcn)
figure(1)
subplot(4,1,1);
plot(U(1,:),'-k');
title('隸屬度矩陣值')
ylabel('第一類')
subplot(4,1,2);
plot(U(2,:),'-k');
ylabel('第二類')
subplot(4,1,3);
plot(U(3,:),'-k');
ylabel('第三類')
subplot(4,1,4);
plot(U(4,:),'-k');
xlabel('樣本數')
ylabel('第四類')
figure(2)
grid on
plot(objFcn);
title('目標函數變化值');
xlabel('迭代次數')
ylabel('目標函數值')
2 電商客戶數據模糊聚類
2.1電商客戶模糊聚類的MATLAB實現
本文運用網絡爬蟲軟件獲取某電商網站的歷史交易數據后,采用其中16位客戶數據進行聚類來驗證算法的可行性和有效性.每位用戶數據包含6項指標值:商品購買量、交易總金額、單次交易均額、消費頻率、網站登錄次數、消費商品類目數,上述指標數據均為同段時間內的交易數據,能較全面描述消費者自身及消費行為的特征,[6]16位客戶數據如表一所示.MATLAB程序中,聚類數目設定c=4,n參數為16,data為16位待聚類客戶的6維數據矩陣,模糊度m=2.在MATLAB環境中運行上述程序,得到每位用戶劃類的隸屬度值如表2所示,圖1為隸屬度矩陣值的示意圖,根據隸屬度值的大小和圖1能得知每位客戶的最佳聚類,圖2為目標函數變化值示意圖,經過8次迭代運算,模糊聚類算法收斂,目標函數值已經非常穩定,說明聚類迭代計算已達到要求.

16 100 10000 5000 2 6 2

表2 模糊聚類隸屬度
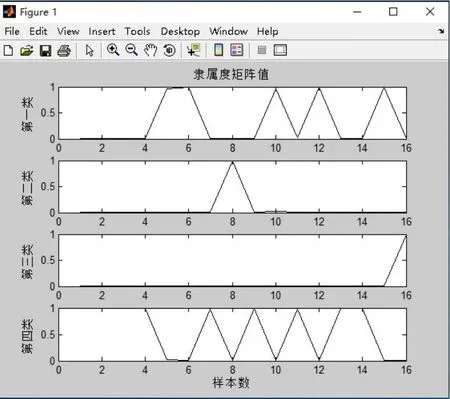
圖1 隸屬度矩陣值
2.2實驗結果及其分析

圖2 目標函數值變化
從MATLAB聚類實驗結果看出:序號為1、2、3、4、7、9、11、13、14的客戶,該類客戶群雖單次消費額不高,企業從這客戶群獲利不大,但他們消費頻率高,交易會持續穩定,是企業穩定生存的基礎客戶;序號為5、6、10、12、15的客戶聚為一類,該類客戶群消費頻率高,交易總額和單次交易均額都較大,且購買數量多,可以從他們的交易中獲得較高利潤,是電商的優質客戶,應重點維護;序號為8的客戶,消費頻率高,交易總額大,但購買商品數量大,平均到每次交易的交易額不高,他們需求量大,極可能為網絡渠道的進貨商,也很在乎價格,他們對電商具有一定價值,應該通過適當的營銷策略轉變優質客戶;序號為16的客戶消費頻率低,但交易額高,單次交易給企業帶來的利潤也高,是電商的潛在客戶,應通過營銷和維護使其轉變為穩定的優質客戶.
結 語
在商業市場中,市場客戶種類和需求日益繁多,如何有效細分、規劃客戶群,并制定針對性的營銷策略,是激烈市場競爭的成功所在.本文提出了基于模糊理論的數據聚類方法,來實現電商客戶聚類特征提取提供了很好的解決思路,實驗結果表明,該算法是可行的合理的.同時,該方法對于其他專業領域如模式識別、模糊控制亦有一定的實際指導意義,為問題的突破提供好的思路.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
