基于ARIMA-SVM組合模型的中國出口歐盟食品安全風險預測
2020-03-04 12:05:10樓皓曹倩李海生
食品工業 2020年1期
關鍵詞:模型
樓皓,曹倩,李海生
北京工商大學計算機與信息工程學院,食品安全大數據技術北京市重點實驗室(北京 100048)
在經濟全球化背景下,食品的流通貿易變得頻繁,食品安全問題成為世界各國最關注的民生問題之一。由于食品安全受到多種復雜因素影響,中國每年出口歐盟的食品中,會有部分食品因不符合歐盟食品安全標準遭到歐盟食品及飼料快速預警系統(RASFF)通報。因此,加強中國出口食品的安全預測,有助于深度了解中國對外食品貿易走勢,具有重要的長期實踐意義[1-3]。
當前食品安全預測方法眾多,傳統預測方法基于數據是線性變化為前提,代表有差分自動回歸移動平均(ARIMA)[4],但不能準確地描述食品安全與其影響因子間的非線性關系,使用十分受限。近年來出現的神經網絡、支持向量機(SVM)等技術卻非常善于發掘非線性變化規律數據中存在的聯系[5-6]。中國對外出口食品數據不僅具有一定周期性變化特點,同時也有相當一部分隨機性特點。因此,單一模型對食品數據無法準確預測。 為了解決這個問題,提出一種基于ARIMA和SVM的食品安全預測模型。選擇差分自動回歸移動平均模型對食品數據的時間序列進行建模,采用支持向量機對差分自動回歸移動平均的預測殘差進行建模,兩者結果相加以得到最終的食品安全預測結果。試驗表明,基于ARIMA-SVM模型較單一模型有更高的預測精度,為今后食品安全預測問題提供建模工具[7]。
1 研究方法
1.1 差分自回歸移動平均模型(ARIMA)
ARIMA是最典型的時間序列預測方法,擁有簡單、短期預測效果良好的特點。ARIMA(p, d, q)模型由3部分組成,即自回歸模型(Auto regression,AR),其中p為相應的回歸項;單整階數(Integration,I),d為差分階數,用來得到平穩序列;移動平均模型(Moving average,MA),q為相應的移動平均項。時間序列模型要建立計量模型,需滿足平穩性序列這一條件,若時間序列是非平穩序列,則要通過差分轉換為平穩性序列。ARIMA(p, d, q)模型是把非平穩時間序列經d階差分后得到平穩時間序列,構成ARMA(p,q),其一般形式為式(1)。
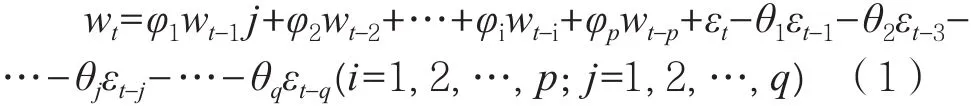
式中:wt表示平穩時間序列;εt表示白噪聲;φi(i=1,2, …, p)表示{wt}的參數;θj(j=1, 2, …, q)表示{εt}的參數。將非平穩時間序列轉化為平穩時間序列后,需要對平穩時間序列分別繪制其自相關系數ACF圖和偏自相關系數PACF圖,通過對圖形的分析,得到最佳自回歸階層p和移動平均階數q,模型參數φi和θj由階數q確定。在最小信息量準則(AIC)和貝葉斯信息量準則(SIC)基礎上進行模型確定。

式中:n表示模型中參數個數;L表示模型的極大似然函數。AIC和BIC準則的提出可有效彌補自相關圖和片自相關圖定階的主觀性,能在有限的階數范圍內更快找到最優擬合模型。
1.2 支持向量機模型(SVM)
支持向量機(SVM)的概念由Cortes和Vapnik于1995年第一次提出,基于統計學VC維理論和結構風險最小原理基礎上提出,最初應用于模式的分類,其核心是通過核函數的引入,將低維空間中的非線性問題通過映射到高維度空間,進而轉化為高維度中的線性凸二次規劃問題。其優點是利用內積核函數代替高維空間的非線性映射,最終結果的決定取決于少數支持向量,計算復雜度只與支持向量的數目相關,與樣本空間維度無關,某種意義上避免“維數災難”,保證了解的唯一性和全局最優性,且算法簡單,魯棒性強。
由于SVM模型是用于線性不可分的預測殘差進行分析,假設給定一個特征空間上的訓練數據集T={(x1, y1), (x2, y2), …, (xN,yN)},其中xi∈Rn,yi∈{+1, -1},i=1, 2, …, N,引入松弛因子ξi≥0,對應的最優化問題如式(4)所示。

由最優w*和b*求得分離超平面,見式(5),進而確定分類決策函數,如式(6)所示。

支持向量機回歸是支持向量機的擴展應用,其核心是ε-insensitive誤差函數和核函數,定義松弛變量εi和基于ε不敏感損失函數的支持向量機回歸模型如式(7)所示。
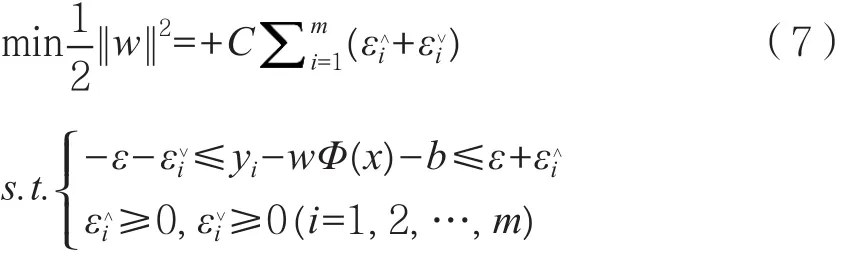
式中:εi和εi表示松弛變量,定義模型的誤差范圍;C表示正則化參數,其主要功能是對松弛變量和置信范圍的度量優化。推導可得最終支持向量機回歸函數。如式(8)所示。
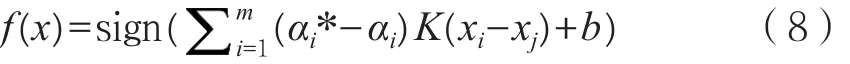
對式(7)轉化為等價的二次規劃問題求解后可得αi*和αi,在KKT準則的基礎上可求得偏差b。式中K(xi, yi)稱為滿足Mercer條件的任意對稱函數,也即核函數,很大程度上決定模型性能的優良。經過分析可知,在采用交叉(CV)和網格尋優算法(GS)驗證基礎上,分別嘗試各種常用的核函數,找出模型擬合效果最好誤差最小的一種,在反復試驗基礎上,確定徑向基函數(RBF)最符合試驗要求[8]。
1.3 ARIMA-SVM組合預測模型基本思路和步驟
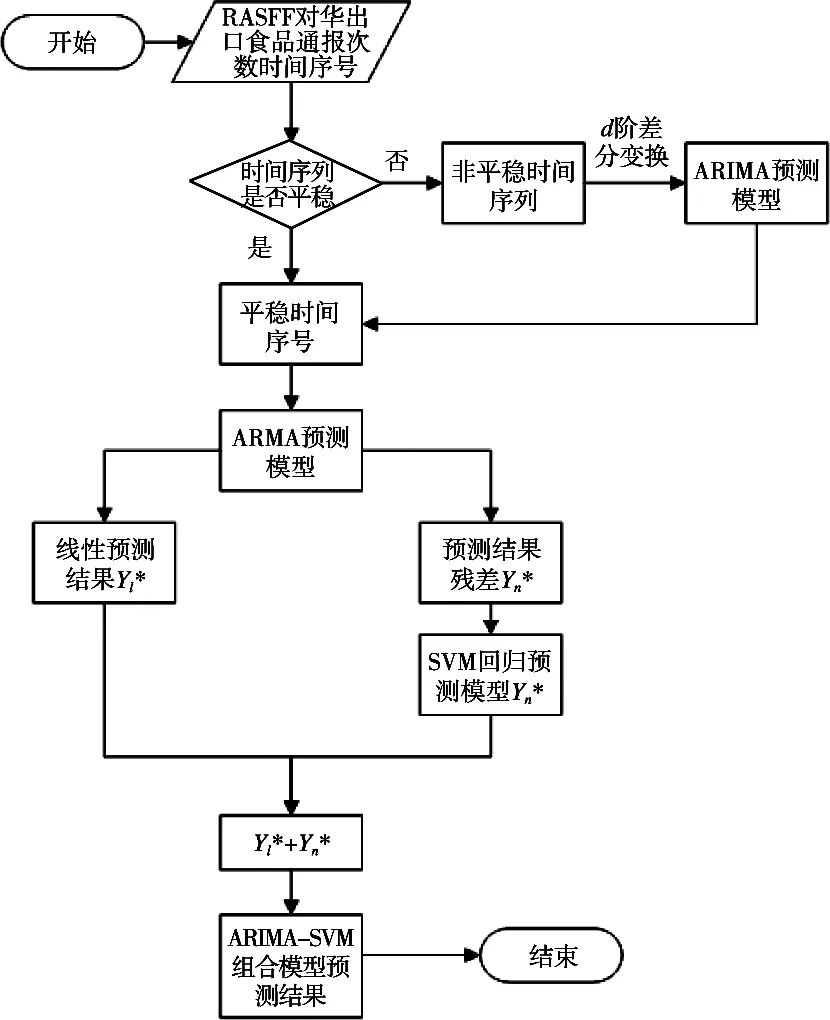
圖1 組合預測模型流程圖
中國出口歐盟食品安全受多種風險源因素的影響,因此,將中國出口歐盟不合格食品通報次數的時間序列Yt以月度分布構建時間序列,作為輸入變量帶入ARIMA模型進行預測,得到符合線性變化規律的結果Yl*,此時預測殘差Yn=Yt-Yl*。因為預測殘差Yn中包含時間序列的非線性部分,故使用SVM模型進行回歸預測,將Yn作為支持向量機模型的輸入變量得到預測結果Yn*。此時,通過單獨的ARIMA模型和SVM模型分別得到預測值Yl*和Yn*,將兩者相加即是ARIMASVM組合預測模型的最終預測結果Yt*=Yl*+Yn*[9-15]。組合預測模型建模步驟如圖1所示。
2 仿真試驗及預測分析
2.1 數據來源及模型評價指標
選取歐盟食品及飼料快速預警系統門戶網站(RASFF)上2009年1月至2018年12月共計120個自然月的歐盟對華食品邊境拒絕通報次數的時間序列作為研究對象,以前108個月的數據樣本作為訓練樣本對模型進行構建,后12個月的數據樣本作為測試樣本。圖2為2009年1月至2018年12月歐盟對華邊境通報次數變化圖。
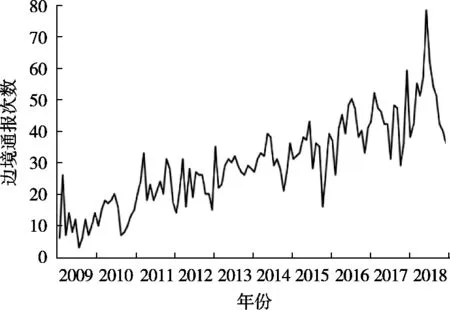
圖2 2009年1月至2018年12月歐盟對華食品出口邊境通報次數變化圖
為更直觀評價ARIMA-SVM組合預測模型的預測效果,采用均方根誤差(Root mean squared error,RMSE)和平均絕對誤差(Mean absolute percent error,MAPE)作為評價指標,對模型的預測效果進行評估,均方根誤差和平均絕對誤差定義。
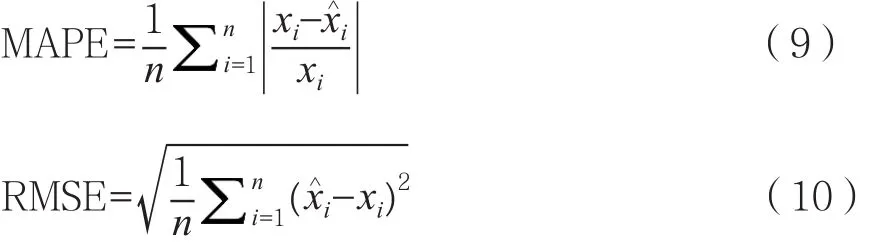
式中:xi表示實際值;表示預測值;n表示預測樣本數量。
2.2 ARIMA模型線性預測
對2009年1月至2018年12月歐盟對華邊境通報次數做月度序列圖分析可知(圖2),其呈緩慢上升的趨勢,屬于明顯的非平穩時間序列,并存在較大波動,整個月度時間序列方差差別顯著。以2017年12月為切點,將整個數據集分為兩部分。以2009年1月至2017年12月的數據作為組合預測模型的建模數據,2018年1月至12月的數據作為驗證數據,對通報次數進行預測進而評估模型的預測可靠性。
對原始數據時間序列進行一階差分,相關試驗的軟硬件環境分別為EVIEWS 10,Windows 10教育版,2.6 GHz CPU、8 GB內存的筆記本電腦。原始時間序列經過一階差分處理后如圖3和圖4所示。由圖3可知,一階差分均值基本維持在0左右,基本可以判斷是穩定的時間序列。由圖4時間序列ADF單位根檢驗可知,p-value小于0.05且檢驗值的絕對值均大于臨界值的絕對值,拒絕原假設。故原始時間序列經一階差分后變成了平穩時間序列。故確定ARIMA(p,d,q)模型中的d=1。
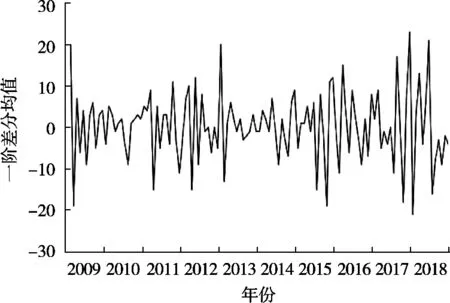
圖3 一階差分時間序列圖

圖4 一階差分時間序列ADF檢驗圖
一階差分后殘差自相關系數(ACF)和偏自相關系數(PACF)如圖5所示,可知lag=12(滯后值)時,自相關系數滯后2階后開始有衰減的趨勢且系數都不為0,可視為2階拖尾;偏自相關系數滯后2階后也開始衰減且系數不為0,視為2階拖尾。自相關和偏自相關均為拖尾,故適用AR(2)模型。
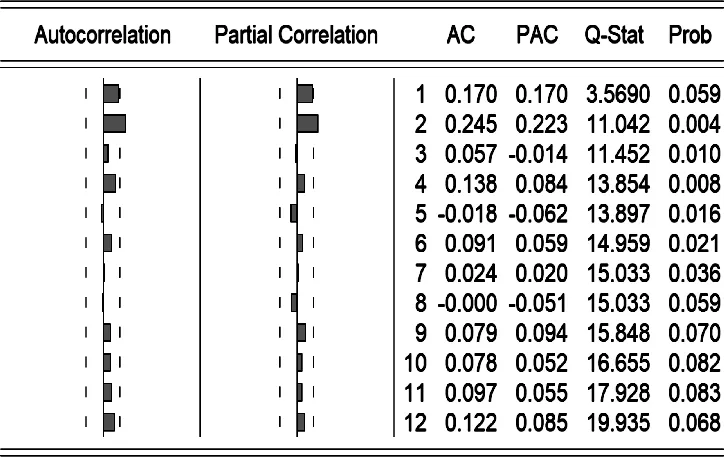
圖5 殘差自相關和偏自相關系數圖
因此ARIMA模型階數可初步定為ARIMA(1, 1,0),ARIMA(2, 1, 0),ARIMA(1, 1, 1)和ARIMA(2, 1,1),利用Eviews軟件分別對4個模型進行計算,根據最小信息量原則,最終確定最優模型為ARIMA(2, 1,1),各ARIMA模型的AIC和SIC檢驗值如表1所示。

表1 差分自移動回歸平均模型相關信息量檢驗值
預測結果及RASFF對華出口食品邊境通報次數的殘差值、觀測值及擬合值的對比分別如圖6和圖7所示。ARIMA模型對RASFF對華食品邊境通報次數1月至10月的預測趨勢與實際值的趨勢是非常接近的,但預測值只有在3,5,8和9月的預測值與實際值非常接近,其余各月預測值與實際值相差很大擬合效果不是很理想,仍有待進一步優化。
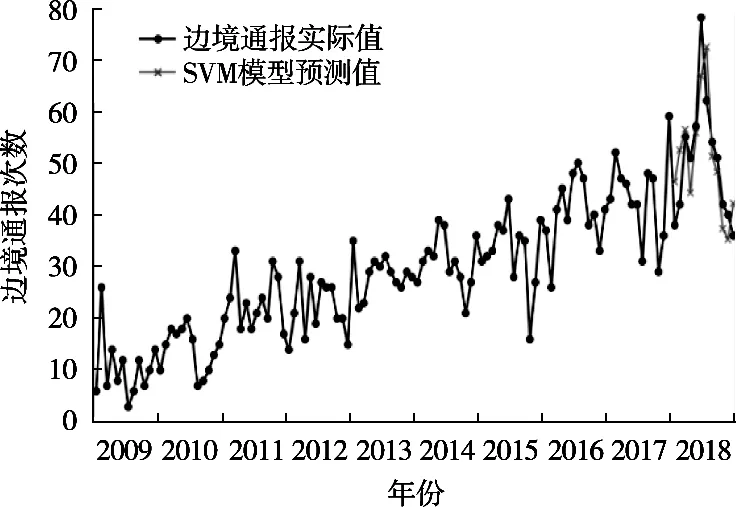
圖6 差分自回歸移動平均模型ARIMA(2, 1, 1)預測結果
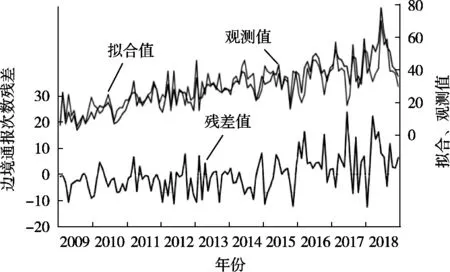
圖7 我國出口歐盟食品邊境通報次數的殘差值、觀測值及擬合值的對比圖
2.3 SVM模型非線性預測
模型ARIMA(2, 1, 1)殘差包含非線性部分,故使用SVM模型對殘差進行訓練。試驗采用MATLAB R2014b版本,調用Libsvm 3.23工具箱實現。SVM模型的2個重要參數分別為核函數和特征空間向量,經過多次試驗分析,確定核函數選擇徑向基核函數(RBF),定義為:
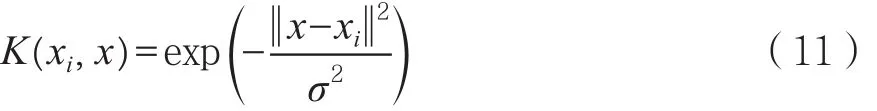
確定SVM模型核函數使用徑向基函數,在反復多次試驗的基礎上確定模型參數分別為C=53,σ=3.6,ε=0.01。根據參數對2018年1月至2018年12月RASFF對華出口食品邊境通報次數進行預測,預測結果與實際結果對比圖見圖8。
SVM模型預測趨勢在1-3,4-5,7-9及10-12月是符合實際值趨勢的,與ARIMA模型相比略有不足。在預測值精準度上,SVM模型的預測值與實際值的差別幅度要大于ARIMA模型,仍有待優化。
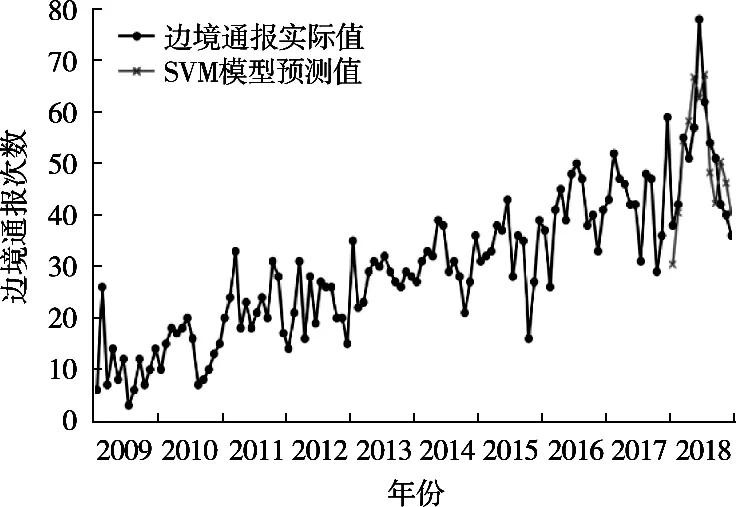
圖8 支持向量機模型預測值與實際值結果對比圖
2.4 ARIMA-SVM組合模型預測及結果分析
在ARIMA(2, 1, 1)模型的預測值及殘差部分SVM模型的預測值的基礎上進行求和,得到ARIMA-SVM組合預測模型的預測值,將各模型對2018年1-12月RASFF對華食品出口邊境通報次數的預測值進行對比,結果如圖9所示。
由圖9可知,ARIMA模型預測值在5-9月期間的預測值與實際值變化趨勢相同,預測值與實際值相差不大。SVM模型在1-5月期間的預測值與實際值變化趨勢相同,但預測值與實際值誤差要大于ARIMA模型。單模型預測的情況下,ARIMA模型擬合精度要高于SVM模型。而ARIMA-SVM組合模型不論是數據變化趨勢或是數據誤差方面,均要優于任一單模型。因此單模型只適用于短期預測,長期預測使用組合預測模型效果更佳[16-19]。各模型預測結果及預測精度分別如表2和表3所示。
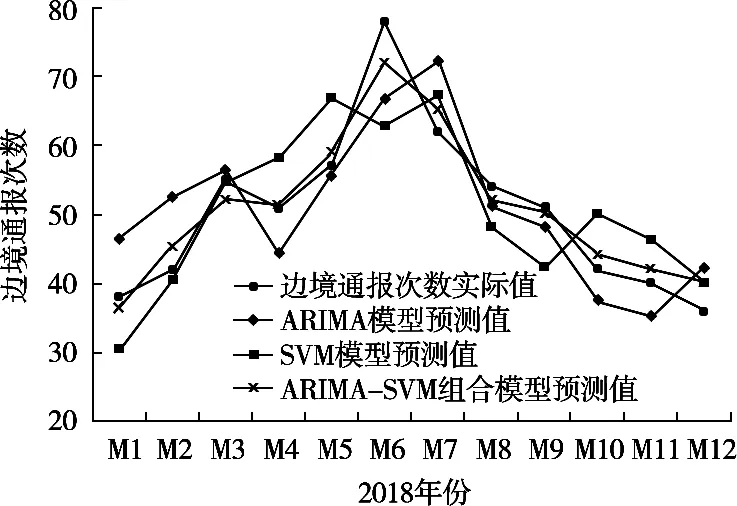
圖9 2018年1-12月我國出口歐盟食品出口邊境通報次數各模型預測結果對比圖
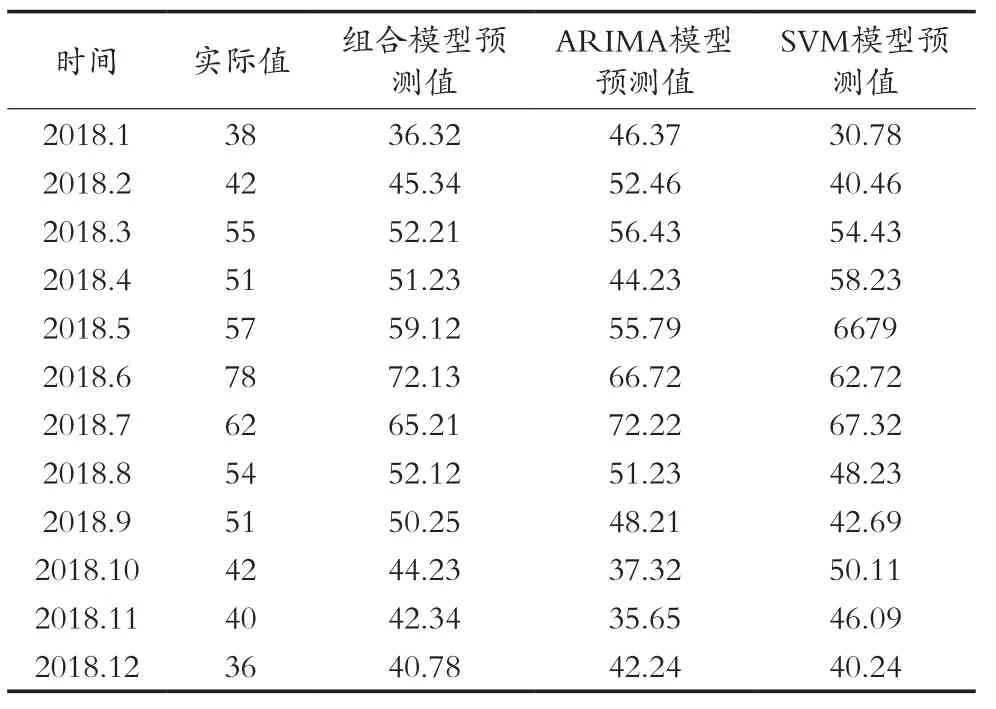
表2 各模型預測結果

表3 各模型預測精度
不論是單獨的ARIMA模型或是SVM模型,都不能兼顧捕捉到數據中存在的線性特征和非線性特征。組合模型的優勢就在于分別保留ARIMA模型和SVM模型的優勢部分,利用ARIMA模型對數據線性特征進行建模,利用SVM模型對數據的非線性特征進行建模,從而有效避免ARIMA模型對數據非線性特征處理的短板。表2和表3數據顯示出組合模型相比較單一模型在預測結果和預測精度上有較為明顯的優勢,說明ARIMA-SVM組合預測模型對原始數據中隱藏的數據關系的認知上要比單一模型表現更佳,有效克服單一模型的局限性[20]。同時,試驗結果驗證組合預測模型對中國出口歐盟食品質量安全的預測結果是可靠的,對今后中國出口歐盟食品的質量起到有效監管作用。
3 結論
1) 一定時間節點內RASFF對華出口食品通報次數的時間序列是食品安全和數據關系的一種直觀反映。基于挖掘食品安全相關數據的時間序列自身隱含信息的角度出發,建立ARIMA-SVM的時間序列組合預測模型。實證研究表明,基于2009年至2018年RASFF對華食品出口邊境通報次數的數據,利用2018年1-12月的數據進行驗證,結果表明不論是預測值或是預測精度,組合模型均優于單一模型。
2) ARIMA-SVM預測模型較單一預測模型短期內能夠較為準確反映出中國出口歐盟食品的質量安全,對中國食品出口安全風險起到一個有效評估,但模型參數的選擇、數據噪聲等影響因子仍然會對組合模型的預測精度產生影響。此外,影響食品安全的不確定因素遠頗多,也會在一定程度上影響預測的精度,導致預測精度下降。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
